
Fundamentals of Table Expressions, Part 13 – Inline Table-Valued Functions, Continued
This is the thirteenth and last installment in a series about table expressions. This month I continue the discussion I started last month about inline table-valued functions (iTVFs).
Last month I explained that when SQL Server inlines iTVFs that are queried with constants as inputs, it applies parameter embedding optimization by default. Parameter embedding means that SQL Server replaces parameter references in the query with the literal constant values from the current execution, and then the code with the constants gets optimized. This process enables simplifications that can result in more optimal query plans. This month I elaborate on the topic, covering specific cases for such simplifications such as constant folding and dynamic filtering and ordering. If you need a refresher on parameter embedding optimization, go over last month’s article as well as Paul White’s excellent article Parameter Sniffing, Embedding, and the RECOMPILE Options.
In my examples, I’ll use a sample database called TSQLV5. You can find the script that creates and populates it here and its ER diagram here.
Constant Folding
During early stages of query processing, SQL Server evaluates certain expressions involving constants, folding those to the result constants. For example, the expression 40 + 2 can be folded to the constant 42. You can find the rules for foldable and nonfoldable expressions here under “Constant Folding and Expression Evaluation.”
What’s interesting with regards to iTVFs is that thanks to parameter embedding optimization, queries involving iTVFs where you pass constants as inputs can, in the right circumstances, benefit from constant folding. Knowing the rules for foldable and nonfoldable expressions can affect the way you implement your iTVFs. In some cases, by applying very subtle changes to your expressions, you can enable more optimal plans with better utilization of indexing.
As an example, consider the following implementation of an iTVF called Sales.MyOrders:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GOIssue the following query involving the iTVF (I’ll refer to this as Query 1):
SELECT myorderid, orderdate, custid, empid
FROM Sales.MyOrders(1, 10248)
ORDER BY myorderid;The plan for Query 1 is shown in Figure 1.
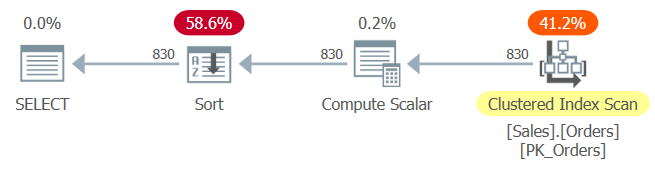 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
The clustered index PK_Orders is defined with orderid as the key. Had constant folding taken place here after parameter embedding, the ordering expression orderid + 1 – 10248 would have been folded to orderid – 10247. This expression would have been considered an order-preserving expression with respect to orderid, and as such would have enabled the optimizer to rely on index order. Alas, that’s not the case, as is evident by the explicit Sort operator in the plan. So, what happened?
Constant folding rules are finicky. The expression column1 + constant1 – constant2 is evaluated from left to right for constant folding purposes. The first part, column1 + constant1 is not folded. Let’s call this expression1. The next part that’s evaluated is treated as expression1 – constant2, which is not folded either. Without folding, an expression in the form column1 + constant1 – constant2 is not considered order preserving with respect to column1, and therefore cannot rely on index ordering even if you have a supporting index on column1. Similarly, the expression constant1 + column1 – constant2 is not constant foldable. However, the expression constant1 – constant2 + column1 is foldable. More specifically, the first part constant1 – constant2 is folded into a single constant (let’s call it constant3), resulting in the expression constant3 + column1. This expression is considered an order-preserving expression with respect to column1. So as long as you make sure to write your expression using the last form, you can enable the optimizer to rely on index ordering.
Consider the following queries (I’ll refer to them as Query 2, Query 3 and Query 4), and before looking at the query plans, see if you can tell which will involve explicit sorting in the plan and which won’t:
-- Query 2
SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY myorderid;
-- Query 3
SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY myorderid;
-- Query 4
SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY myorderid;Now examine the plans for these queries as shown in Figure 2.
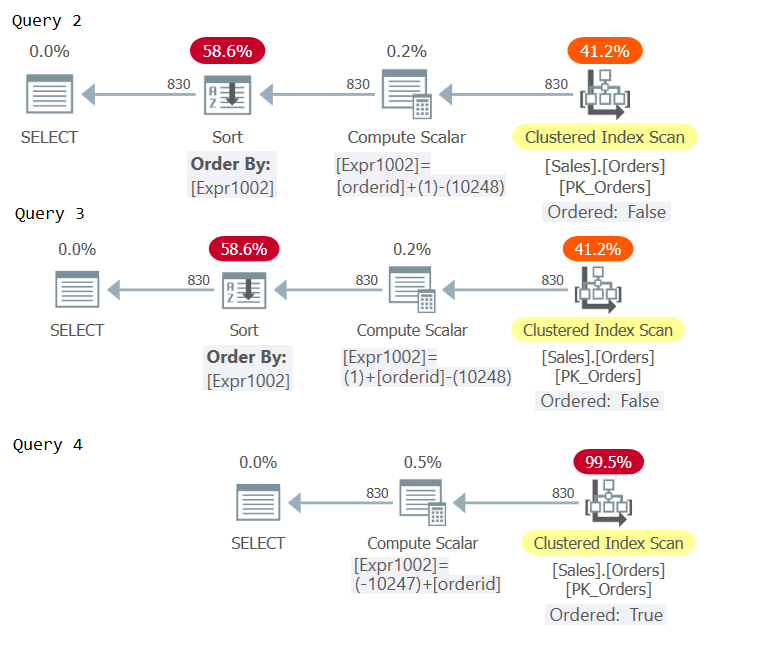 Figure 2: Plans for Query 2, Query 3, and Query 4
Figure 2: Plans for Query 2, Query 3, and Query 4
Examine the Compute Scalar operators in the three plans. Only the plan for Query 4 incurred constant folding, resulting in an ordering expression that’s considered order-preserving with respect to orderid, avoiding explicit sorting.
Understanding this aspect of constant folding, you can easily fix the iTVF by changing the expression orderid + @add – @subtract to @add – @subtract + orderid, like so:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GOQuery the function again (I’ll refer to this as Query 5):
SELECT myorderid, orderdate, custid, empid
FROM Sales.MyOrders(1, 10248)
ORDER BY myorderid;The plan for this query is shown in Figure 3.
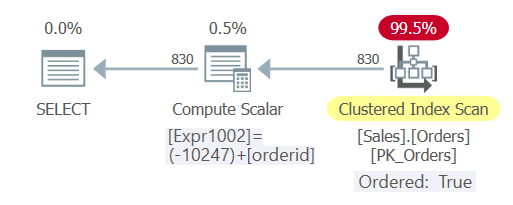 Figure 3: Plan for Query 5
Figure 3: Plan for Query 5
As you can see, this time the query experienced constant folding and the optimizer was able to rely on index ordering, avoiding explicit sorting.
I used a simple example to demonstrate this optimization technique, and as such it might seem a bit contrived. You can find a practical application of this technique in the article Number series generator challenge solutions – Part 1.
Dynamic Filtering/Ordering
Last month I covered the difference between the way SQL Server optimizes a query in an iTVF versus the same query in a stored procedure. SQL Server will typically apply parameter-embedding optimization by default for a query involving an iTVF with constants as inputs, but optimize the parameterized form of a query in a stored procedure. However, if you add OPTION(RECOMPILE) to the query in the stored procedure, SQL Server will typically apply parameter-embedding optimization in this case as well. The benefits in the iTVF case include the fact that you can involve it in a query, and as long as you pass repeating constant inputs, there’s the potential to reuse a previously cached plan. With a stored procedure, you cannot involve it in a query, and if you add OPTION(RECOMPILE) to get parameter-embedding optimization, there’s no plan reuse possibility. The stored procedure allows much more flexibility in terms of the code elements you can use.
Let’s see how all this plays out in a classic parameter embedding and ordering task. Following is a simplified stored procedure that applies dynamic filtering and sorting similar to the one Paul used in his article:
CREATE OR ALTER PROCEDURE HR.GetEmpsP
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
AS
SET NOCOUNT ON;
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GONotice the current implementation of the stored procedure doesn’t include OPTION(RECOMPILE) in the query.
Consider the following execution of the stored procedure:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;The plan for this execution is shown in Figure 4.
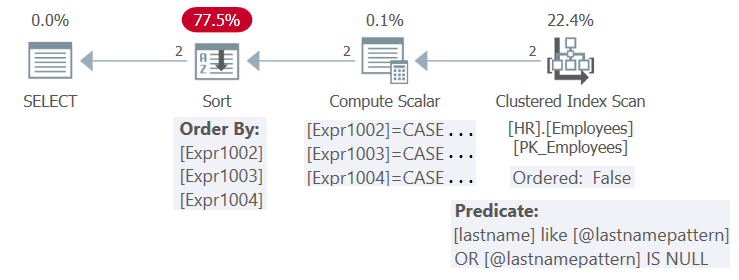 Figure 4: Plan for Procedure HR.GetEmpsP
Figure 4: Plan for Procedure HR.GetEmpsP
There’s an index defined on the lastname column. Theoretically, with the current inputs, the index could be beneficial both for the filtering (with a seek) and the ordering (with an ordered: true range scan) needs of the query. However, since by default SQL Server optimizes the parameterized form of the query and doesn’t apply parameter-embedding, it doesn’t apply the simplifications required to be able to benefit from the index for both filtering and ordering purposes. So, the plan is reusable, but it’s not optimal.
To see how things change with parameter embedding optimization, alter the stored procedure query by adding OPTION(RECOMPILE), like so:
CREATE OR ALTER PROCEDURE HR.GetEmpsP
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
AS
SET NOCOUNT ON;
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END
OPTION(RECOMPILE);
GOExecute the stored procedure again with the same inputs you used before:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;The plan for this execution is shown in Figure 5.
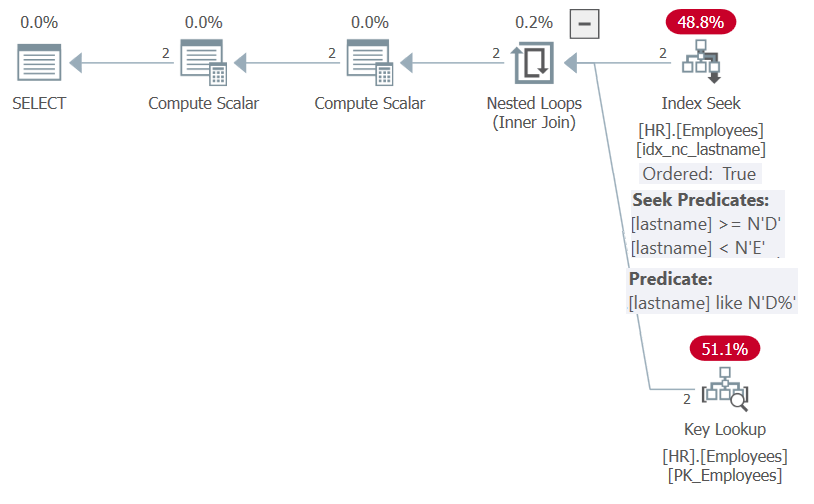 Figure 5: Plan for Procedure HR.GetEmpsP With OPTION(RECOMPILE)
Figure 5: Plan for Procedure HR.GetEmpsP With OPTION(RECOMPILE)
As you can see, thanks to parameter-embedding optimization, SQL Server was able to simplify the filter predicate to the sargable predicate lastname LIKE N'D%', and the ordering list to NULL, NULL, lastname. Both elements could benefit from the index on lastname, and therefore the plan shows a seek in the index and no explicit sorting.
Theoretically, you expect to be able to get similar simplification if you implement the query in an iTVF, and hence similar optimization benefits, but with the ability to reuse cached plans when the same input values are reused. So, let’s try…
Here’s an attempt to implement the same query in an iTVF (don’t run this code yet):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GOBefore you attempt to execute this code, can you see a problem with this implementation? Remember that early on in this series I explained a table expression is a table. A table’s body is a set (or multiset) of rows, and as such has no order. Therefore, normally, a query used as a table expression cannot have an ORDER BY clause. Indeed, if you try running this code, you get the following error:
The ORDER BY clause is invalid in views, inline functions, derived tables, subqueries, and common table expressions, unless TOP, OFFSET or FOR XML is also specified.
Sure, like the error says, SQL Server will make an exception if you use a filtering element like TOP or OFFSET-FETCH, which relies on the ORDER BY clause to define the ordering aspect of the filter. But even if you do include an ORDER BY clause in the inner query thanks to this exception, you still don’t get a guarantee for the order of the result in an outer query against the table expression, unless it has its own ORDER BY clause.
If you still want to implement the query in an iTVF, you can have the inner query handle the dynamic filtering part, but not the dynamic ordering, like so:
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50)
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL;
GOOf course, you can have the outer query handle any specific ordering need, like in the following code (I’ll refer to this as Query 6):
SELECT empid, firstname, lastname
FROM HR.GetEmpsF(N'D%')
ORDER BY lastname;The plan for this query is shown in Figure 6.
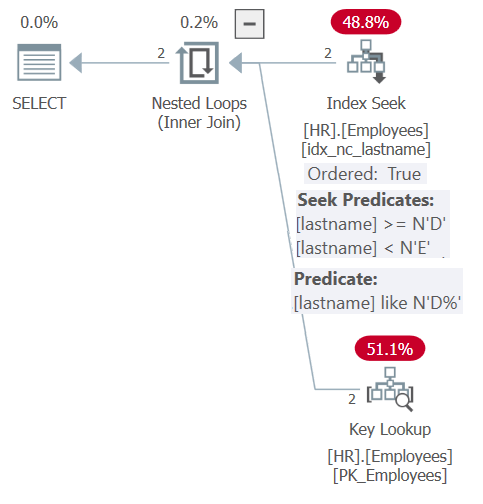 Figure 6: Plan for Query 6
Figure 6: Plan for Query 6
Thanks to inlining and parameter embedding, the plan is similar to the one shown earlier for the stored procedure query in Figure 5. The plan efficiently relies on the index for both the filtering and the ordering purposes. However, you don’t get the flexibility of the dynamic ordering input like you had with the stored procedure. You have to be explicit with the ordering in the ORDER BY clause in the query against the function.
The following example has a query against the function with no filtering and no ordering requirements (I’ll refer to this as Query 7):
SELECT empid, firstname, lastname
FROM HR.GetEmpsF(NULL);The plan for this query is shown in Figure 7.
 Figure 7: Plan for Query 7
Figure 7: Plan for Query 7
After inlining and parameter embedding, the query is simplified to have no filter predicate and no ordering, and gets optimized with a full unordered scan of the clustered index.
Finally, query the function with N'D%' as the input last name filtering pattern and order the result by the firstname column (I’ll refer to this as Query 8):
SELECT empid, firstname, lastname
FROM HR.GetEmpsF(N'D%')
ORDER BY firstname;The plan for this query is shown in Figure 8.
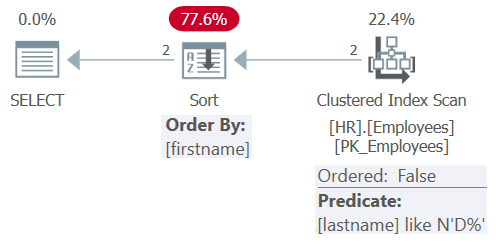 Figure 8: Plan for Query 8
Figure 8: Plan for Query 8
After simplification, the query involves only the filtering predicate lastname LIKE N'D%' and the ordering element firstname. This time the optimizer choses to apply an unordered scan of the clustered index, with the residual predicate lastname LIKE N'D%', followed by explicit sorting. It chose not to apply a seek in the index on lastname because the index isn’t a covering one, the table is so small, and the index ordering isn’t beneficial for the current query ordering needs. Also, there’s no index defined on the firstname column, so an explicit sort has to be applied anyway.
Conclusion
The default parameter-embedding optimization of iTVFs can also result in constant folding, enabling more optimal plans. However, you need to be mindful of constant folding rules to determine how to best formulate your expressions.
Implementing logic in an iTVF has advantages and disadvantages compared to implementing logic in a stored procedure. If you’re not interested in parameter-embedding optimization, the default parameterized query optimization of stored procedures can result in more optimal plan caching and reuse behavior. In cases where you are interested in parameter-embedding optimization, you typically get it by default with iTVFs. To get this optimization with stored procedures, you need to add the RECOMPILE query option, but then you won’t get plan reuse. At least with iTVFs, you can get plan reuse provided the same parameter values are repeated. Then again, you have less flexibility with the query elements you can use in an iTVF; for example, you’re not allowed to have a presentation ORDER BY clause.
Back to the entire series on table expressions, I find the topic to be super important for database practitioners. The more complete series includes the subseries on the number series generator, which is implemented as an iTVF. In total the series includes the following 19 parts:
- Fundamentals of table expressions, Part 1
- Fundamentals of table expressions, Part 2 – Derived tables, logical considerations
- Fundamentals of table expressions, Part 3 – Derived tables, optimization considerations
- Fundamentals of table expressions, Part 4 – Derived tables, optimization considerations, continued
- Fundamentals of table expressions, Part 5 – CTEs, logical considerations
- Fundamentals of table expressions, Part 6 – Recursive CTEs
- Fundamentals of table expressions, Part 7 – CTEs, optimization considerations
- Fundamentals of table expressions, Part 8 – CTEs, optimization considerations continued
- Fundamentals of table expressions, Part 9 – Views, compared with derived tables and CTEs
- Fundamentals of table expressions, Part 10 – Views, SELECT *, and DDL changes
- Fundamentals of Table Expressions, Part 11 – Views, Modification Considerations
- Fundamentals of Table Expressions, Part 12 – Inline Table-Valued Functions
- Fundamentals of Table Expressions, Part 13 – Inline Table-Valued Functions, continued
- The challenge is on! Community call for creating the fastest number series generator
- Number series generator challenge solutions – Part 1
- Number series generator challenge solutions – Part 2
- Number series generator challenge solutions – Part 3
- Number series generator challenge solutions – Part 4
- Number series generator challenge solutions – Part 5
Instead of reordering the expression, you could also employ parenthesis, which has the same effect of reordering operator precedence.
SELECT orderid + (@add – @subtract) AS myorderid,
See fiddle
https://dbfiddle.uk/?rdbms=sqlserver_2019&sample=adventureworks&fiddle=47fd1fb4fd2650b47590d9304a53559e
Hi Charlie,
It is a pretty neat trick; thanks for pointing it out!