
Fundamentals of table expressions, Part 3 – Derived tables, optimization considerations
In Part 1 and Part 2 of this series, I covered the logical, or conceptual, aspects of named table expressions in general, and derived tables specifically. This month and the next I’m going to cover the physical processing aspects of derived tables. Recall from Part 1 the physical data independence principle of relational theory. The relational model and the standard querying language that is based on it are supposed to deal only with the conceptual aspects of the data and leave the physical implementation details like storage, optimization, access and processing of the data to the database platform (the implementation). Unlike the conceptual treatment of the data which is based on a mathematical model and a standard language, and hence is very similar in the various relational database management systems out there, the physical treatment of the data is not based on any standard, and hence tends to be very platform-specific. In my coverage of the physical treatment of named table expressions in the series I focus on the treatment in Microsoft SQL Server and Azure SQL Database. The physical treatment in other database platforms can be quite different.
Recall that what triggered this series is some confusion that exists in the SQL Server community around named table expressions. Both in terms of terminology and in terms of optimization. I addressed some terminology considerations in the first two parts of the series, and will address more in future articles when discussing CTEs, views and inline TVFs. As for optimization of named table expressions, there’s confusion around the following items (I mention derived tables here since that’s the focus of this article):
- Persistency: Is a derived table persisted anywhere? Does it get persisted on disk, and how does SQL Server handle memory for it?
- Column projection: How does index matching work with derived tables? For example, if a derived table projects a certain subset of columns from some underlying table, and the outermost query projects a subset of the columns from the derived table, is SQL Server smart enough to figure out optimal indexing based on the final subset of columns that is actually needed? And what about permissions; does the user need permissions to all columns that are referenced in the inner queries, or only to the final ones that are actually needed?
- Multiple references to column aliases: If the derived table has a result column that is based on a nondeterministic computation, e.g., a call to the function SYSDATETIME, and the outer query has multiple references to that column, will the computation be done only once, or separately for each outer reference?
- Unnesting/substitution/inlining: Does SQL Server unnest, or inline, the derived table query? That is, does SQL Server perform a substitution process whereby it converts the original nested code into one query that goes directly against the base tables? And if so, is there a way to instruct SQL Server to avoid this unnesting process?
These are all important questions and the answers to these questions have significant performance implications, so it’s a good idea to have a clear understanding of how these items are handled in SQL Server. This month I’m going to address the first three items. There’s quite a lot to say about the fourth item so I’ll dedicate a separate article to it next month (Part 4).
In my examples I’ll use a sample database called TSQLV5. You can find the script that creates and populates TSQLV5 here, and its ER diagram here.
Persistency
Some people intuitively assume that SQL Server persists the result of the table expression part of the derived table (the inner query’s result) in a worktable. At the date of this writing that’s not the case; however, since persistency considerations are a vendor’s choice, Microsoft could decide to change this in the future. Indeed, SQL Server is able to persist intermediate query results in worktables (typically in tempdb) as part of the query processing. If it chooses to do so, you see some form of a spool operator in the plan (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). However, SQL Server’s choice of whether to spool something in a worktable or not currently has nothing to do with your use of named table expressions in the query. SQL Server sometimes spools intermediate results for performance reasons, such as avoiding repeated work (though currently unrelated to the use of named table expressions), and sometimes for other reasons, such as Halloween protection.
As mentioned, next month I’ll get to the details of unnesting of derived tables. For now, suffice to say that SQL Server normally does apply an unnesting/inlining process to derived tables, where it substitutes the nested queries with a query against the underlying base tables. Well, I’m oversimplifying a bit. It’s not like SQL Server literally converts the original T-SQL query string with the derived tables to a new query string without those; rather SQL Server applies transformations to an internal logical tree of operators, and the outcome is that effectively the derived tables typically get unnested. When you look at an execution plan for a query involving derived tables, you don’t see any mention of those because for most optimization purposes they don’t exist. You see access to the physical structures that hold the data for the underlying base tables (heap, B-tree rowstore indexes and columnstore indexes for disk-based tables and tree and hash indexes for memory optimized tables).
There are cases that prevent SQL Server from unnesting a derived table, but even in those cases SQL Server doesn’t persist the table expression’s result in a worktable. I’ll provide the details along with examples next month.
Since SQL Server doesn’t persist derived tables, rather interacts straight with the physical structures that hold the data for the underlying base tables, the question regarding how memory is handled for derived tables is moot. If the underlying base tables are disk-based ones, their relevant pages need to be processed in the buffer pool. If the underlying tables are memory-optimized ones, their relevant in-memory rows need to be processed. But that’s no different than when you query the underlying tables directly yourself without using derived tables. So there’s nothing special here. When you use derived tables, SQL Server doesn’t need to apply any special memory considerations for those. For most query optimization purposes, they don’t exist.
If you have a case where you need to persist some intermediate step’s result in a worktable, you need to be using temporary tables or table variables—not named table expressions.
Column projection and a word on SELECT *
Projection is one of the original operators of relational algebra. Suppose you have a relation R1 with attributes x, y and z. The projection of R1 on some subset of its attributes, e.g., x and z, is a new relation R2, whose heading is the subset of projected attributes from R1 (x and z in our case), and whose body is the set of tuples formed from the original combination of projected attribute values from R1’s tuples.
Recall that a relation’s body—being a set of tuples—by definition has no duplicates. So it goes without saying that the result relation’s tuples are the distinct combination of attribute values projected from the original relation. However, remember that the body of a table in SQL is a multiset of rows and not a set, and normally, SQL will not eliminate duplicate rows unless you instruct it to. Given a table R1 with columns x, y and z, the following query can potentially return duplicate rows, and therefore doesn’t follow relational algebra’s projection operator’s semantics of returning a set:
SELECT x, z
FROM R1;By adding a DISTINCT clause, you eliminate duplicate rows, and more closely follow the semantics of relational projection:
SELECT DISTINCT x, z
FROM R1;Of course, there are some cases where you know that the result of your query has distinct rows without the need for a DISTINCT clause, e.g., when a subset of the columns that you’re returning includes a key from the queried table. For example, if x is a key in R1, the above two queries are logically equivalent.
At any rate, recall the questions I mentioned earlier surrounding the optimization of queries involving derived tables and column projection. How does index matching work? If a derived table projects a certain subset of columns from some underlying table, and the outermost query projects a subset of the columns from the derived table, is SQL Server smart enough to figure out optimal indexing based on the final subset of columns that is actually needed? And what about permissions; does the user need permissions to all columns that are referenced in the inner queries, or only to the final ones that are actually needed? Also, suppose that the table expression query defines a result column that is based on a computation, but the outer query doesn’t project that column. Is the computation evaluated at all?
Starting with the last question, let’s try it. Consider the following query:
USE TSQLV5;
GO
SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers;As you would expect, this query fails with a divide by zero error:
Divide by zero error encountered.
Next, define a derived table called D based on the above query, and in the outer query project D on only custid and city, like so:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D;As mentioned, SQL Server normally applies unnesting/substitution, and since there’s nothing in this query that inhibits unnesting (more on this next month), the above query is equivalent to the following query:
SELECT custid, city
FROM Sales.Customers;Again, I’m oversimplifying a bit here. The reality is a little bit more complex than these two queries being considered as truly identical, but I’ll get to those complexities next month. The point being, the expression 1/0 doesn’t even show up in the query’s execution plan, and doesn’t get evaluated at all, so the above query runs successfully with no errors.
Still, the table expression needs to be valid. For example, consider the following query:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D;Even though the outer query projects only a column from the inner query’s grouping set, the inner query isn’t valid since it attempts to return columns that are neither part of the grouping set nor contained in an aggregate function. This query fails with the following error:
Column 'Sales.Customers.custid' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
Next, let’s tackle the index matching question. If the outer query projects only a subset of the columns from the derived table, will SQL Server be smart enough to do index matching based on only the returned columns (and of course any other columns that play a meaningful role otherwise, such as filtering, grouping and so on)? But before we tackle this question, you might wonder why we’re even bothering with it. Why would you have the inner query return columns that the outer query doesn’t need?
The answer is simple, to shorten the code by having the inner query use the infamous SELECT *. We all know that using SELECT * is a bad practice, but that’s the case primarily when it’s used in the outermost query. What if you query a table with a certain heading, and later that heading is altered? The application could end up with bugs. Even if you don’t end up with bugs, you could end up generating unnecessary network traffic by returning columns that the application doesn’t really need. Plus, you utilize indexing less optimally in such a case since you reduce the chances for matching covering indexes that are based on the truly needed columns.
That said, I actually feel quite comfortable using SELECT * in a table expression, knowing that I’m anyway going to project only the truly needed columns in the outermost query. From a logical standpoint, that’s pretty safe with some minor caveats which I’ll get to shortly. That’s so long as index matching is done optimally in such a case, and the good news, it is.
To demonstrate this, suppose that you need to query the Sales.Orders table, returning the three most recent orders for each customer. You’re planning to define a derived table called D based on a query that compute row numbers (result column rownum) that are partitioned by custid and ordered by orderdate DESC, orderid DESC. The outer query will filter from D (relational restriction) only the rows where rownum is less than or equal to 3, and project D on custid, orderdate, orderid and rownum. Now, Sales.Orders has more columns than the ones that you need to project, but for brevity, you want the inner query to use SELECT *, plus the row number computation. That’s safe and will get handled optimally in terms of index matching.
Use to following code to create the optimal covering index to support your query:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);Here’s the query that archives the task at hand (we’ll call it Query 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3;Notice the inner query’s SELECT *, and the outer query’s explicit column list.
The plan for this query, as rendered by SentryOne Plan Explorer, is shown in Figure 1.
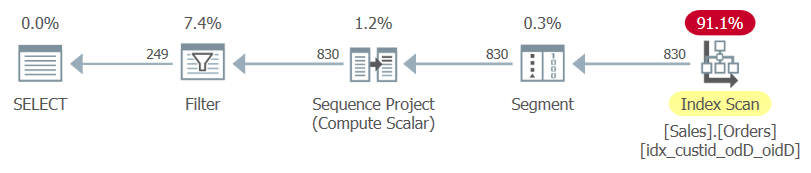 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
Observe that the only index used in this plan is the optimal covering index that you just created.
If you highlight only the inner query and examine its execution plan, you will see the table’s clustered index used followed by a sort operation.
So that’s good news.
As for permissions, that’s a different story. Unlike with index matching, where you don’t need the index to include columns that are referenced by the inner queries so long as they are ultimately not needed, you are required to have permissions to all referenced columns.
To demonstrate this, use the following code to create a user called user1 and assign some permissions (SELECT permissions on all columns from Sales.Customers, and on only the three columns from Sales.Orders that are ultimately relevant in the above query):
CREATE USER user1 WITHOUT LOGIN;
GRANT SHOWPLAN TO user1;
GRANT SELECT ON Sales.Customers TO user1;
GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;Run the following code to impersonate user1:
EXECUTE AS USER = 'user1';Try to select all columns from Sales.Orders:
SELECT * FROM Sales.Orders;As expected, you get the following errors due to the lack of permissions on some of the columns:
The SELECT permission was denied on the column 'empid' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'requireddate' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shippeddate' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipperid' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'freight' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipname' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipaddress' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipcity' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipregion' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shippostalcode' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipcountry' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Try the following query, projecting and interacting with only columns for which user1 has permissions:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3;Still, you get column permission errors due to the lack of permissions on some of the columns that are referenced by the inner query via its SELECT *:
The SELECT permission was denied on the column 'empid' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'requireddate' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shippeddate' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipperid' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'freight' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipname' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipaddress' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipcity' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipregion' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shippostalcode' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT permission was denied on the column 'shipcountry' of the object 'Orders', database 'TSQLV5', schema 'Sales'.
If indeed in your company it’s a practice to assign users permissions on only relevant columns that they need to interact with, it would make sense to use a little bit lengthier code, and be explicit about the column list in both the inner and outer queries, like so:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3;This time, the query runs without errors.
Another variation that requires the user to have permissions only on the relevant columns is to be explicit about the column names in the inner query’s SELECT list, and use SELECT * in the outer query, like so:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3;This query also runs without errors. However, I see this version as one that is prone to bugs in case later on some changes are made in some inner level of nesting. As mentioned earlier, to me, the best practice is to be explicit about the column list in the outermost query. So as long as you don’t have any concerns about lack of permission on some of the columns, I feel comfortable with SELECT * in inner queries, but an explicit column list in the outermost query. If applying specific column permissions is a common practice in the company, then it’s best to simply be explicit about column names in all levels of nesting. Mind you, being explicit about column names in all levels of nesting is actually mandatory if your query is used in a schema bound object, since schema binding disallows the use of SELECT * anywhere in the query.
At this point, run the following code to remove the index you created earlier on Sales.Orders:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;There’s another case with a similar dilemma concerning the legitimacy of using SELECT *; in the inner query of the EXISTS predicate.
Consider the following query (we’ll call it Query 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid);The plan for this query is shown in Figure 2.
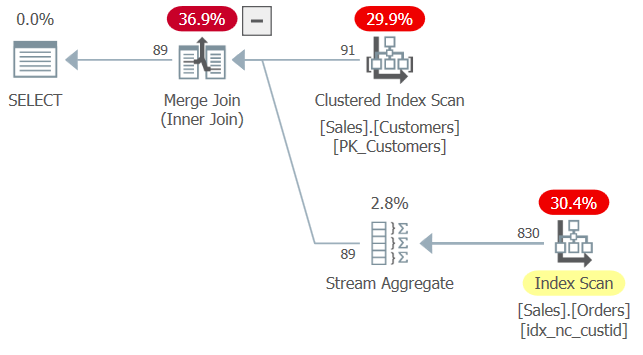 Figure 2: Plan for Query 2
Figure 2: Plan for Query 2
When applying index matching, the optimizer figured that the index idx_nc_custid is a covering index on Sales.Orders since it contains the custid column—the only true relevant column in this query. That’s despite the fact that this index does not contain any other column besides custid, and that the inner query in the EXISTS predicate says SELECT *. So far, the behavior seems similar to the use of SELECT * in derived tables.
What’s different with this query is that it runs without errors, despite the fact that user1 doesn’t have permissions on some of the columns from Sales.Orders. There’s an argument to justify not requiring permissions on all columns here. After all, the EXISTS predicate only needs to check for existence of matching rows, so the inner query’s SELECT list is really meaningless. It would have probably been best if SQL didn’t require a SELECT list at all in such a case, but that ship has sailed already. The good news is that the SELECT list is effectively ignored—both in terms of index matching and in terms of required permissions.
It would also appear that there’s another difference between derived tables and EXISTS when using SELECT * in the inner query. Remember this query from earlier in the article:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D;If you recall, this code generated an error since the inner query is invalid.
Try the same inner query, only this time in the EXISTS predicate (we’ll call this Statement 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!';Oddly, SQL Server considers this code as valid, and it runs successfully. The plan for this code is shown in Figure 3.
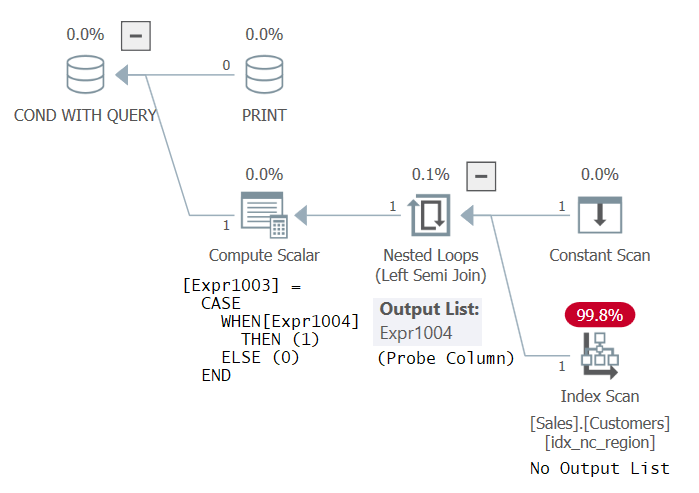 Figure 3: Plan for Statement 3
Figure 3: Plan for Statement 3
This plan is identical to the plan you would get if the inner query was just SELECT * FROM Sales.Customers (without the GROUP BY). After all, you’re checking for existence of groups, and if there are rows, there are naturally groups. Anyway, I think that the fact that SQL Server considers this query as valid is a bug. Surely, the SQL code should be valid! But I can see why some could argue that the SELECT list in the EXISTS query is supposed to be ignored. At any rate, the plan uses a probed left semi join, which doesn’t need to return any columns, rather just probe a table to check for existence of any rows. The index on Customers could be any index.
At this point you can run the following code to stop impersonating user1 and to drop it:
REVERT;
DROP USER IF EXISTS user1;Back to the fact that I find it to be a convenient practice to use SELECT * in inner levels of nesting, the more levels you have, the more this practice shortens and simplifies your code. Here’s an example with two nesting levels:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear;There are cases where this practice cannot be used. For example, when the inner query joins tables with common column names, like in the following example:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3;Both Sales.Customers and Sales.Orders have a column called custid. You’re using a table expression that is based on a join between the two tables to define the derived table D. Remember that a table’s heading is a set of columns, and as a set, you cannot have duplicate column names. Therefore, this query fails with the following error:
The column 'custid' was specified multiple times for 'D'.
Here, you need to be explicit about column names in the inner query, and make sure that you either return custid from only one of the tables, or assign unique column names to the result columns in case you want to return both. More often you would use the former approach, like so:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3;Again, you could be explicit with the column names in the inner query and use SELECT * in outer query, like so:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3;But as I mentioned earlier, I consider it to be a bad practice not to be explicit about column names in the outermost query.
Multiple references to column aliases
Let’s proceed to the next item—multiple references to derived table columns. If the derived table has a result column that is based on a nondeterministic computation, and the outer query has multiple references to that column, will the computation be evaluated only once or separately for each reference?
Let’s start with the fact that multiple references to the same nondeterministic function in a query are supposed to be evaluated independently. Consider the following query as an example:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;This code generates the following output showing two different GUIDs:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Conversely, if you have a derived table with a column that is based on a nondeterminstic computation, and the outer query has multiple references to that column, the computation is supposed to be evaluated only once. Consider the following query (we’ll call this Query 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2
FROM ( SELECT NEWID() AS mynewid ) AS D;The plan for this query is shown in Figure 4.
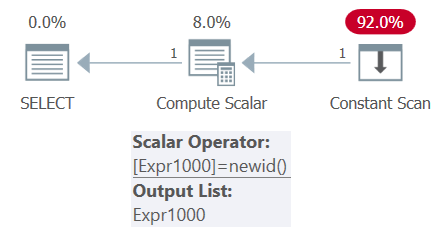 Figure 4: Plan for Query 4
Figure 4: Plan for Query 4
Observe that there’s only one invocation of the NEWID function in the plan. Accordingly, the output shows the same GUID twice:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
So, the above two queries are not logically equivalent, and there are cases where inlining/substitution does not take place.
With some nondeterministic functions it’s a bit trickier to demonstrate that multiple invocations in a query are handled separately. Take the SYSDATETIME function as an example. It has 100 nanosecond precision. What are the chances that a query such as the following will actually show two different values?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;If you’re bored, you could hit F5 repeatedly until it happens. If you have more important things to do with your time, you might prefer to run a loop, like so:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i;For instance, when I ran this code, I got 1971.
If you want to make sure that the nondeterministic function is invoked only once, and rely on the same value in multiple query references, make sure that you define a table expression with a column based on the function invocation, and have multiple references to that column from the outer query, like so (we’ll call this Query 5):
SELECT mydt AS mydt1, mydt AS mydt1
FROM ( SELECT SYSDATETIME() AS mydt ) AS D;The plan for this query is shown in Figure 5.
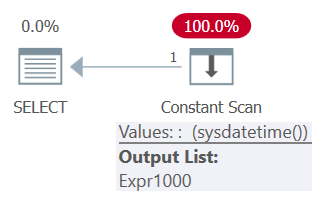 Figure 5: Plan for Query 5
Figure 5: Plan for Query 5
Notice in the plan that the function is invoked only once.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i;You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END;Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D;Summary
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.
1 thought on “Fundamentals of table expressions, Part 3 – Derived tables, optimization considerations”
Comments are closed.

NEWID() can be a bit funny sometimes. Officially it should be a single invocation per row both when it's in a derived table that's JOINed and when in an APPLY, it should be one total invocation on a non-correlated CROSS JOIN.
But I have had NEWID() invoked only once in the whole query for a derived APPLY and vv for a CROSS JOIN, the optimizer seems to get confused when it rearranges the compute scalar.