
Fundamentals of table expressions, Part 8 – CTEs, optimization considerations continued
 This article is the eighth part in a series about table expressions. So far I provided a background to table expressions, covered both the logical and optimization aspects of derived tables, the logical aspects of CTEs, and some of the optimization aspects of CTEs. This month I continue the coverage of optimization aspects of CTEs, specifically addressing how multiple CTE references are handled.
This article is the eighth part in a series about table expressions. So far I provided a background to table expressions, covered both the logical and optimization aspects of derived tables, the logical aspects of CTEs, and some of the optimization aspects of CTEs. This month I continue the coverage of optimization aspects of CTEs, specifically addressing how multiple CTE references are handled.
In my examples I’ll continue using the sample database TSQLV5. You can find the script that creates and populates TSQLV5 here, and its ER diagram here.
Multiple references and nondeterminism
Last month I explained and demonstrated that CTEs get unnested, whereas temporary tables and table variables actually persist data. I provided recommendations in terms of when it makes sense to use CTEs versus when it makes sense to use temporary objects from a query performance standpoint. But there’s another important aspect of CTE optimization, or physical processing, to consider beyond the solution’s performance—how multiple references to the CTE from an outer query are handled. It’s important to realize that if you have an outer query with multiple references to the same CTE, each gets unnested separately. If you have nondeterministic calculations in the CTE’s inner query, those calculations can have different results in the different references.
Say for instance that you invoke the SYSDATETIME function in a CTE’s inner query, creating a result column called dt. Generally, assuming no change in the inputs, a built-in function is evaluated once per query and reference, irrespective of the number of rows involved. If you refer to the CTE only once from an outer query, but interact with the dt column multiple times, all references are supposed to represent the same function evaluation and return the same values. However, if you refer to the CTE multiple times in the outer query, be it with multiple subqueries referring to the CTE or a join between multiple instances of the same CTE (say aliased as C1 and C2), the references to C1.dt and C2.dt represent different evaluations of the underlying expression and could result in different values.
To demonstrate this, consider the following three batches:
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GOBased on what I just explained, can you identify which of the batches have an infinite loop and which will stop at some point due to the two comparands of the predicate evaluating to different values?
Remember that I said that a call to a built-in nondeterministic function like SYSDATETIME is evaluated once per query and reference. This means that in Batch 1 you have two different evaluations and after enough iterations of the loop they will result in different values. Try it. How many iterations did the code report?
As for Batch 2, the code has two references to the dt column from the same CTE instance, meaning that both represent the same function evaluation and should represent the same value. Consequently, Batch 2 has an infinite loop. Run it for any amount of time that you like, but eventually you will need to stop the code execution.
As for Batch 3, the outer query has two different subqueries interacting with the CTE C, each representing a different instance that goes through an unnesting process separately. The code doesn’t explicitly assign different aliases to the different instances of the CTE because the two subqueries appear in independent scopes, but to make it easier to understand, you could think of the two as using different aliases such as C1 in one subquery and C2 in the other. So it’s as if one subquery interacts with C1.dt and the other with C2.dt. The different references represent different evaluations of the underlying expression and hence can result in different values. Try running the code and see that it stops at some point. How many iterations did it take until it stopped?
It's interesting to try and identify the cases where you have a single versus multiple evaluations of the underlying expression in the query execution plan. Figure 1 has the graphical execution plans for the three batches (click to enlarge).
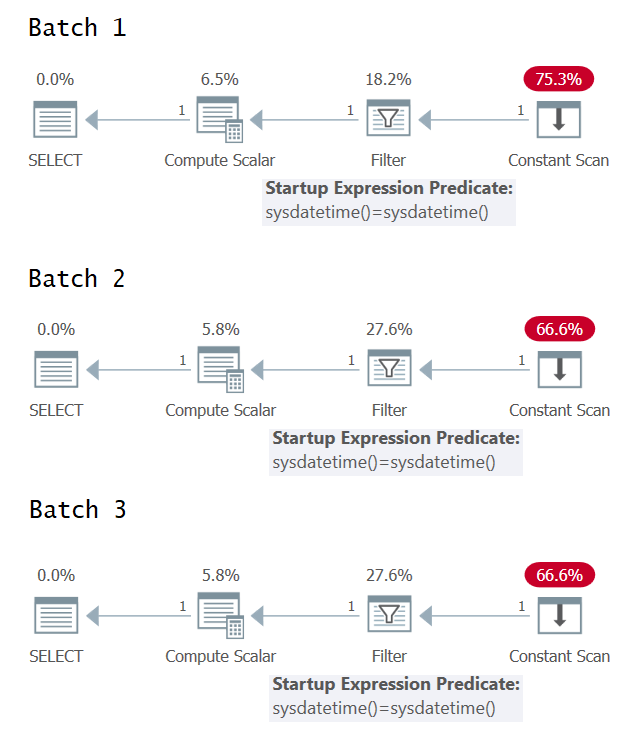 Figure 1: Graphical execution plans for Batch 1, Batch 2 and Batch 3
Figure 1: Graphical execution plans for Batch 1, Batch 2 and Batch 3
Unfortunately, no joy from the graphical execution plans; they all seem identical even though, semantically, the three batches do not have identical meanings. Thanks to @CodeRecce and Forrest (@tsqladdict), as a community we managed to get to the bottom of this with other means.
As @CodeRecce discovered, the XML plans hold the answer. Here are the relevant parts of the XML for the three batches:
<Predicate>
…
<Compare CompareOp="EQ">
<ScalarOperator>
<Intrinsic FunctionName="sysdatetime" />
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="sysdatetime" />
</ScalarOperator>
</Compare>
…
</Predicate>
−− Batch 2
<Predicate>
…
<Compare CompareOp="EQ">
<ScalarOperator>
<Identifier>
<ColumnReference Column="ConstExpr1002">
<ScalarOperator>
<Intrinsic FunctionName="sysdatetime" />
</ScalarOperator>
</ColumnReference>
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Identifier>
<ColumnReference Column="ConstExpr1002">
<ScalarOperator>
<Intrinsic FunctionName="sysdatetime" />
</ScalarOperator>
</ColumnReference>
</Identifier>
</ScalarOperator>
</Compare>
…
</Predicate>
−− Batch 3
<Predicate>
…
<Compare CompareOp="EQ">
<ScalarOperator>
<Identifier>
<ColumnReference Column="ConstExpr1005">
<ScalarOperator>
<Intrinsic FunctionName="sysdatetime" />
</ScalarOperator>
</ColumnReference>
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Identifier>
<ColumnReference Column="ConstExpr1006">
<ScalarOperator>
<Intrinsic FunctionName="sysdatetime" />
</ScalarOperator>
</ColumnReference>
</Identifier>
</ScalarOperator>
</Compare>
…
</Predicate>
You can clearly see in the XML plan for Batch 1 that the filter predicate compares the results of two separate direct invocations of the intrinsic SYSDATETIME function.
In the XML plan for Batch 2, the filter predicate compares the constant expression ConstExpr1002 representing one invocation of the SYSDATETIME function with itself.
In the XML plan for Batch 3, the filter predicate compares two different constant expressions called ConstExpr1005 and ConstExpr1006, each representing a separate invocation of the SYSDATETIME function.
As another option, Forrest (@tsqladdict) suggested using trace flag 8605, which shows the initial query tree representation created by SQL Server, after enabling trace flag 3604 which causes the output of TF 8605 to be directed the SSMS client. Use the following code to enable both trace flags:
DBCC TRACEON(3604); -- direct output to client
GO
DBCC TRACEON(8605); -- show initial query tree
GONext you run the code for which you want to get the query tree. Here are the relevant parts of the output that I got from TF 8605 for the three batches:
*** Converted Tree: ***
LogOp_Project COL: Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [empty]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL: Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL: @i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
−− Batch 2
*** Converted Tree: ***
LogOp_Project COL: Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [empty]
AncOp_PrjList
AncOp_PrjEl COL: Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL: Expr1000
ScaOp_Identifier COL: Expr1000
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL: @i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
−− Batch 3
*** Converted Tree: ***
LogOp_Project COL: Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [empty]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL: Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [empty]
AncOp_PrjList
AncOp_PrjEl COL: Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_Identifier COL: Expr1000
ScaOp_Subquery COL: Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [empty]
AncOp_PrjList
AncOp_PrjEl COL: Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL: Expr1003
ScaOp_Identifier COL: Expr1002
AncOp_PrjList
AncOp_PrjEl COL: Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL: @i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
In Batch 1, you can see a comparison between the results of two separate evaluations of the intrinsic function SYSDATETIME.
In Batch 2, you see one evaluation of the function resulting in a column called Expr1000, and then a comparison between this column and itself.
In Batch 3, you see two separate evaluations of the function. One in column called Expr1000 (later projected by the subquery column called Expr1001). Another in column called Expr1002 (later projected by the subquery column called Expr1003). You then have a comparison between Expr1001 and Expr1003.
So, with a little bit more digging beyond what the graphical execution plan exposes, you can actually figure out when an underlying expression gets evaluated only once versus multiple times. Now that you understand the different cases, you can develop your solutions based on the desired behavior that you’re after.
Window functions with nondeterministic order
There’s another class of computations that can get you into trouble when used in solutions with multiple references to the same CTE. Those are window functions that rely on nondeterministic ordering. Take the ROW_NUMBER window function as an example. When used with partial ordering (ordering by elements that do not uniquely identify the row), each evaluation of the underlying query could result in a different assignment of the row numbers even if the underlying data didn’t change. With multiple CTE references, remember that each gets unnested separately, and you could get different result sets. Depending on what the outer query does with each reference, e.g. which columns from each reference it interacts with and how, the optimizer can decide to access the data for each of the instances using different indexes with different ordering requirements.
Consider the following code as an example:
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid;Can this query ever return a nonempty result set? Perhaps your initial reaction is that it can’t. But think about what I just explained a bit more carefully and you will realize that, at least in theory, due to the two separate CTE unnesting processes that will take place here—one of C1 and another of C2—it is possible. However, it’s one thing to theorize that something can happen, and another to demonstrate it. For example, when I ran this code without creating any new indexes, I kept getting an empty result set:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
I got the plan shown in Figure 23 for this query.
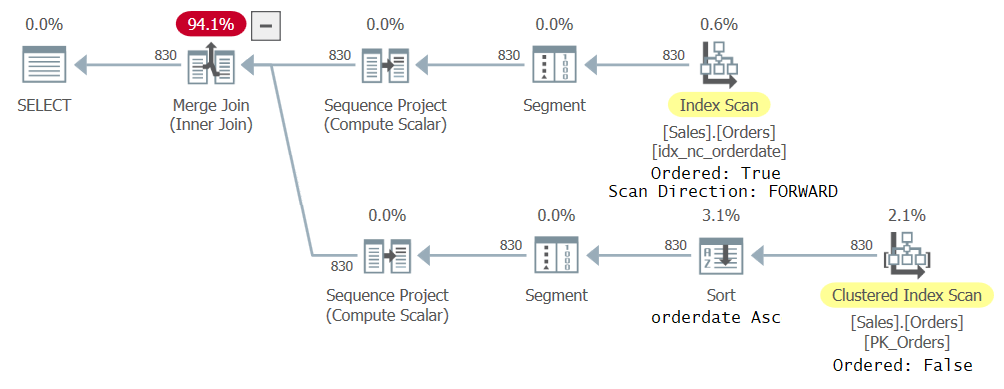 Figure 2: First plan for query with two CTE references
Figure 2: First plan for query with two CTE references
What’s interesting to note here is that the optimizer did choose to use different indexes to handle the different CTE references because that’s what it deemed optimal. After all, each reference in the outer query is concerned with a different subset of the CTE columns. One reference resulted in an ordered forward scan of the index idx_nc_orderedate, and the other in an unordered scan of the clustered index followed by a sort operation by orderdate ascending. Even though the index idx_nc_orderedate is explicitly defined only on the orderdate column as the key, in practice it’s defined on (orderdate, orderid) as its keys since orderid is the clustered index key, and is included as the last key in all nonclustered indexes. So an ordered scan of the index actually emits the rows ordered by orderdate, orderid. As for the unordered scan of the clustered index, at the storage engine level, the data is scanned in index key order (based on orderid) to address minimal consistency expectations of the default isolation level read committed. The Sort operator therefore ingests the data ordered by orderid, sorts the rows by orderdate, and in practice ends up emitting the rows ordered by orderdate, orderid.
Again, in theory there’s no assurance that the two references will always represent the same result set even if the underlying data doesn’t change. A simple way to demonstrate this is to arrange two different optimal indexes for the two references, but have one order the data by orderdate ASC, orderid ASC, and the other order the data by orderdate DESC, orderid ASC (or exactly the opposite). We already have the former index in place. Here’s code to create the latter:
CREATE INDEX idx_nc_odD_oid_I_sc
ON Sales.Orders(orderdate DESC, orderid)
INCLUDE(shipcountry);Run the code a second time after creating the index:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid;I got the following output when running this code after creating the new index:
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
Oops.
Examine the query plan for this execution as shown in Figure 3:
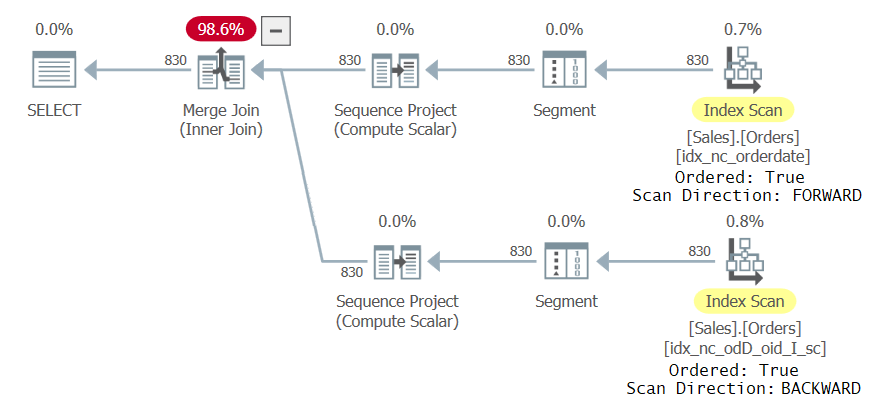 Figure 3: Second plan for query with two CTE references
Figure 3: Second plan for query with two CTE references
Notice that the top branch of the plan scans the index idx_nc_orderdate in an ordered forward fashion, causing the Sequence Project operator which computes the row numbers to ingest the data in practice ordered by orderdate ASC, orderid ASC. The bottom branch of the plan scans the new index idx_nc_odD_oid_I_sc in an ordered backward fashion, causing the Sequence Project operator to ingest the data in practice ordered by orderdate ASC, orderid DESC. This results in a different arrangement of row numbers for the two CTE references whenever there’s more than one occurrence of the same orderdate value. Consequently, the query generates a nonempty result set.
If you want to avoid such bugs, one obvious option is to persist the inner query result in a temporary object like a temporary table or table variable. However, if you have a situation where you’d rather stick to using CTEs, a simple solution is to use total order in the window function by adding a tiebreaker. In other words, make sure that you order by a combination of expressions that uniquely identifies a row. In our case, you can simply add orderid explicitly as a tiebreaker, like so:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid;You get an empty result set as expected:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Without adding any further indexes, you get the plan shown in Figure 4:
Figure 4: Third plan for query with two CTE references
The top branch of the plan is the same as for the previous plan shown in Figure 3. The bottom branch is a bit different though. The new index created earlier isn’t really ideal for the new query in the sense that it doesn’t have the data ordered like the ROW_NUMBER function needs (orderdate, orderid). It’s still the narrowest covering index that the optimizer could find for its respective CTE reference, so it’s selected; however, it’s scanned in an Ordered: False fashion. An explicit Sort operator then sorts the data by orderdate, orderid like the ROW_NUMBER computation needs. Of course, you can alter the index definition to have both orderdate and orderid use the same direction and this way the explicit sorting will be eliminated from the plan. The main point though is that by using total ordering, you avoid getting into trouble due to this specific bug.
When you’re done, run the following code for cleanup:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;Conclusion
It’s important to understand that multiple references to the same CTE from an outer query result in separate evaluations of the CTE’s inner query. Be especially careful with nondeterministic calculations, as the different evaluations could result in different values.
When using window functions like ROW_NUMBER and aggregates with a frame, make sure to use total order to avoid getting different results for the same row in the different CTE references.

{kind=link}