
Fundamentals of table expressions, Part 4 – Derived tables, optimization considerations, continued
This article is the fourth part in a series on table expressions. In Part 1 and Part 2 I covered the conceptual treatment of derived tables. In Part 3 I started covering optimization considerations of derived tables. This month I cover further aspects of optimization of derived tables; specifically, I focus on substitution/unnesting of derived tables.
In my examples I’ll use sample databases called TSQLV5 and PerformanceV5. You can find the script that creates and populates TSQLV5 here, and its ER diagram here. You can find the script that creates and populates PerformanceV5 here.
Unnesting/substitution
Unnesting/substitution of table expressions is a process of taking a query that involves nesting of table expressions, and as if substituting it with a query where the nested logic is eliminated. I should stress that in practice, there’s no actual process in which SQL Server converts the original query string with the nested logic to a new query string without the nesting. What actually happens is that the query parsing process produces an initial tree of logical operators closely reflecting the original query. Then, SQL Server applies transformations to this query tree, eliminating some of the unnecessary steps, collapsing multiple steps into fewer steps, and moving operators around. In its transformations, as long as certain conditions are met, SQL Server can shift things around across what were originally table expression boundaries—sometimes effectively as if eliminating the nested units. All of this in attempt to find an optimal plan.
In this article I cover both cases where such unnesting takes place, as well as unnesting inhibitors. That is, when you use certain query elements it prevent SQL Server from being able to move logical operators in the query tree, forcing it to process the operators based on the boundaries of the table expressions used in the original query.
I’ll start by demonstrating a simple example where derived tables get unnested. I’ll also demonstrate an example for an unnesting inhibitor. I’ll then talk about unusual cases where unnesting can be undesirable, resulting in either errors or performance degradation, and demonstrate how to prevent unnesting in those cases by employing an unnesting inhibitor.
The following query (we’ll call it Query 1) uses multiple nested layers of derived tables, where each of the table expressions applies basic filtering logic based on constants:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401';As you can see, each of the table expressions filters a range of order dates starting with a different date. SQL Server unnests this multi-layered querying logic, which enables it to then merge the four filtering predicates into a single one representing the intersection of all four predicates.
Examine the plan for Query 1 shown in Figure 1.
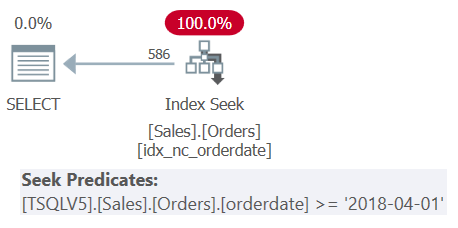 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
Observe that all four filtering predicates were merged into a single predicate representing the intersection of the four. The plan applies a seek in the index idx_nc_orderdate based on the single merged predicate as the seek predicate. This index is defined on orderdate (explicitly), orderid (implicitly due to the presence of a clustered index on orderid) as the index keys.
Also observe that even though all table expressions use SELECT * and only the outermost query projects the two columns of interest: orderdate and orderid, the aforementioned index is considered covering. As I explained in Part 3, for optimization purposes such as index selection, SQL Server ignores the columns from the table expressions that are ultimately not relevant. Remember though that you do need to have permissions to query those columns.
As mentioned, SQL Server will attempt to unnest table expressions, but will avoid the unnesting if it stumbles into an unnesting inhibitor. With a certain exception that I’ll describe later, the use of TOP or OFFSET FETCH will inhibit unnesting. The reason being that attempting to unnest a table expression with TOP or OFFSET FETCH could result in a change to the original query’s meaning.
As an example, consider the following query (we’ll call it Query 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401';The input number of rows to the TOP filter is a BIGINT-typed value. In this example I’m using the maximum BIGINT value (2^63 – 1, compute in T-SQL using SELECT POWER(2., 63) – 1). Even though you and I know that our Orders table will never have that many rows, and therefore the TOP filter is really meaningless, SQL Server has to take into account the theoretical possibility for the filter to be meaningful. Consequently, SQL Server doesn’t unnest the table expressions in this query. The plan for Query 2 is shown in Figure 2.
 Figure 2: Plan for Query 2
Figure 2: Plan for Query 2
The unnesting inhibitors prevented SQL Server from being able to merge the filtering predicates, causing the plan shape to more closely resemble the conceptual query. However, it’s interesting to observe that SQL Server still ignored the columns that were ultimately not relevant to the outermost query, and therefore was able to use the covering index on orderdate, orderid.
To illustrate why TOP and OFFSET-FETCH are unnesting inhibitors, let’s take a simple predicate pushdown optimization technique. Predicate pushdown means that the optimizer pushes a filter predicate to an earlier point compared to the original point that it appears in the logical query processing. For example, suppose that you have a query with both an inner join and a WHERE filter based on a column from one of the sides of the join. In terms of logical query processing, the WHERE filter is supposed to be evaluated after the join. But often the optimizer will push the filter predicate to a step prior to the join, since this leaves the join with fewer rows to work with, typically resulting in a more optimal plan. Remember though that such transformations are allowed only in cases where the meaning of the original query is preserved, in the sense that you’re guaranteed to get the correct result set.
Consider the following code, which has an outer query with a WHERE filter against a derived table, which in turn is based on a table expression with a TOP filter:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101';This query is of course nondeterministic due to the lack of an ORDER BY clause in the table expression. When I ran it, SQL Server happened to access first three rows with order dates earlier than 2018, so I got an empty set as the output:
orderid orderdate ----------- ---------- (0 rows affected)
As mentioned, the use of TOP in the table expression prevented the unnesting/substitution of the table expression here. Had SQL Server unnested the table expression, the substitution process would have resulted in the equivalent to the following query:
SELECT TOP (3) orderid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20180101';This query is also nondeterministic due to the lack of ORDER BY clause, but clearly, it has a different meaning than the original query. If the Sales.Orders table has at least three orders placed in 2018 or later—and it does—this query will necessarily return three rows, unlike the original query. Here’s the result that I got when I ran this query:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
In case the nondeterministic nature of the above two queries confuses you, here’s an example with a deterministic query:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid;The table expression filters the three orders with the lowest order IDs. The outer query then filters from those three orders only those that were placed on or after July 8th, 2017. Turns out that there’s only one qualifying order. This query generates the following output:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Suppose that SQL Server unnested the table expression in the original query, with the substitution process resulting in the following query equivalent:
SELECT TOP (3) orderid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20170708'
ORDER BY orderid;The meaning of this query is different than the original query. This query first filters the orders that were placed on or after July 8th, 2017, and then filters the top three among those with the lowest order IDs. This query generates the following output:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
To avoid changing the meaning of the original query, SQL Server doesn’t apply unnesting/substitution here.
The last two examples involved a simple mix of WHERE and TOP filtering, but there could be additional conflicting elements resulting from unnesting. For instance, what if you have different ordering specifications in the table expression and the outer query, like in the following example:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid;You realize that if SQL Server unnested the table expression, collapsing the two different ordering specifications into one, the resultant query would have had a different meaning than the original query. It would have either filtered the wrong rows or presented the result rows in the wrong presentation order. In short, you realize why the safe thing for SQL Server to do is to avoid unnesting/substitution of table expressions that are based on TOP and OFFSET-FETCH queries.
I mentioned earlier that there is an exception to the rule that the use of TOP and OFFSET-FETCH prevents unnesting. That’s when you use TOP (100) PERCENT in a nested table expression, with or without an ORDER BY clause. SQL Server realizes that there’s no real filtering going on and optimizes the option out. Here’s an example demonstrating this:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401';The TOP filter is ignored, unnesting takes place, and you get the same plan as the one shown earlier for Query 1 in Figure 1.
When using OFFSET 0 ROWS with no FETCH clause in a nested table expression, there’s also no real filtering going on. So, theoretically SQL Server could have optimized this option out as well and enabled unnesting, but at the date of this writing it doesn’t. Here’s an example demonstrating this:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401';You get the same plan as the one shown earlier for Query 2 in Figure 2, showing that no unnesting took place.
Earlier I explained that the unnesting/substitution process doesn’t really generate a new query string that then gets optimized, rather has to do with transformations that SQL Server applies to the tree of logical operators. There is a difference between the way SQL Server optimizes a query with nested table expressions versus an actual logically equivalent query without the nesting. The use of table expressions such as derived tables, as well as subqueries prevents simple parameterization. Recall Query 1 shown earlier in the article:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401';Since the query uses derived tables, simple parameterization does not take place. That is, SQL Server doesn’t replace the constants with parameters and then optimizes the query, rather optimizes the query with the constants. With predicates based on constants, SQL Server can merge the intersecting periods, which in our case resulted in a single predicate in the plan, as shown earlier in Figure 1.
Next, consider the following query (we’ll call it Query 3), which is a logical equivalent of Query 1, but where you apply the unnesting yourself:
SELECT orderid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20180101'
AND orderdate >= '20180201'
AND orderdate >= '20180301'
AND orderdate >= '20180401';The plan for this query is shown in Figure 3.
 Figure 3: Plan for Query 3
Figure 3: Plan for Query 3
This plan is considered safe for simple parameterization, so the constants are substituted with parameters, and consequently, the predicates are not merged. The motivation for parameterization is of course increasing the likelihood for plan reuse when executing similar queries that differ only in the constants that they use.
As mentioned, the use of derived tables in Query 1 prevented simple parameterization. Similarly, the use of subqueries would prevent simple parameterization. For example, here’s our previous Query 3 with a meaningless predicate based on a subquery added to the WHERE clause:
SELECT orderid, orderdate
FROM Sales.Orders
WHERE orderdate >= '20180101'
AND orderdate >= '20180201'
AND orderdate >= '20180301'
AND orderdate >= '20180401'
AND (SELECT 42) = 42;This time simple parameterization doesn’t take place, enabling SQL Server to merge the intersecting periods represented by the predicates with the constants, resulting in the same plan as shown earlier in Figure 1.
If you have queries with table expressions that use constants, and it’s important for you that SQL Server parameterized the code, and for whatever reason you cannot parameterize it yourself, remember that you have the option to use forced parameterization with a plan guide. As an example, the following code creates such a plan guide for Query 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)';Run Query 3 again after creating the plan guide:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401';You get the same plan as the one shown earlier in Figure 3 with the parameterized predicates.
When you’re done, run the following code to drop the plan guide:
EXEC sys.sp_control_plan_guide
@operation = N'DROP',
@name = N'TG1';Preventing unnesting
Remember that SQL Server unnests table expressions for optimization reasons. The goal is to increase the likelihood to find a plan with a lower cost compared to without unnesting. That’s true for most transformation rules applied by the optimizer. However, there could be some unusual cases where you would want to prevent unnesting. This could be either to avoid errors (yes in some unusual cases unnesting can result in errors) or for performance reasons to force a certain plan shape, similar to using other performance hints. Remember, you have a simple way to inhibit unnesting using TOP with a very large number.
Example for avoiding errors
I’ll start with a case where unnesting of table expressions can result in errors.
Consider the following query (we’ll call it Query 4):
SELECT orderid, productid, discount
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
AND 1.0 / discount > 10.0;This example is a bit contrived in the sense that it’s easy to rewrite the second filter predicate so it would never result in an error (discount < 0.1), but it’s a convenient example for me to illustrate my point. Discounts are nonnegative. So even if there are order lines with a zero discount, the query is supposed to filter those out (the first filter predicate says that the discount must be greater than the minimum discount in the table). However, there’s no assurance that SQL Server will evaluate the predicates in written order, so you cannot count on a short circuit.
Examine the plan for Query 4 shown in Figure 4.
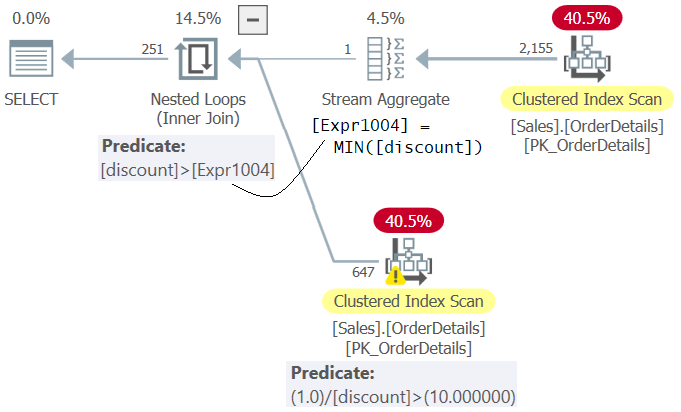 Figure 4: Plan for Query 4
Figure 4: Plan for Query 4
Observe that in the plan the predicate 1.0 / discount > 10.0 (second in WHERE clause) is evaluated before the predicate discount > <subquery result> (first in WHERE clause). Consequentially, this query generates a divide by zero error:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Perhaps you’re thinking that you can avoid the error by using a derived table, separating the filtering tasks to an inner one and an outer one, like so:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0;However, SQL Server applies unnesting of the derived table, resulting in the same plan shown earlier in Figure 4, and consequentially, this code also fails with a divide by zero error:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
A simple fix here is to introduce an unnesting inhibitor, like so (we’ll call this solution Query 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0;The plan for Query 5 is shown in Figure 5.
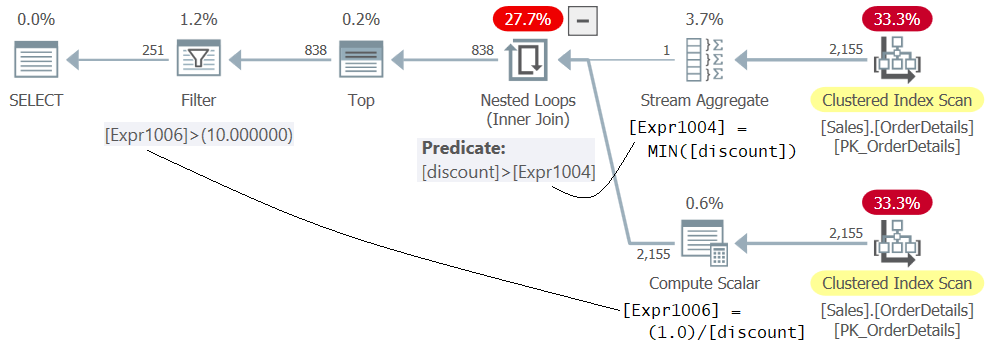 Figure 5: Plan for Query 5
Figure 5: Plan for Query 5
Don’t be confused by the fact that the expression 1.0 / discount appears in the inner part of the Nested Loops operator, as if being evaluated first. This is just the definition of the member Expr1006. The actual evaluation of the predicate Expr1006 > 10.0 is applied by the Filter operator as the last step in the plan after the rows with the minimum discount were filtered out by the Nested Loops operator earlier. This solution runs successfully with no errors.
Example for performance reasons
I’ll continue with a case where unnesting of table expressions can hurt performance.
Start by running the following code to switch context to the PerformanceV5 database and enable STATISTICS IO and TIME:
USE PerformanceV5;
SET STATISTICS IO, TIME ON;Consider the following query (we’ll call it Query 6):
SELECT shipperid, MAX(orderdate) AS maxod
FROM dbo.Orders
GROUP BY shipperid;The optimizer identifies a supporting covering index with shipperid and orderdate as the leading keys. So it creates a plan with an ordered scan of the index followed by an order-based Stream Aggregate operator, as shown in the plan for Query 6 in Figure 6.
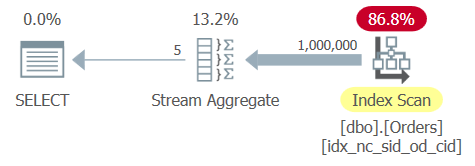 Figure 6: Plan for Query 6
Figure 6: Plan for Query 6
The Orders table has 1,000,000 rows, and the grouping column shipperid is very dense—there are only 5 distinct shipper IDs, resulting in 20% density (average percent per distinct value). Applying a full scan of the index leaf involves reading a few thousand pages, resulting in a run time of about a third of a second on my system. Here are the performance statistics that I got for the execution of this query:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
The index tree is currently three levels deep.
Let’s scale the number of orders by a factor of 1,000 to 1,000,000,000, but still with only 5 distinct shippers. The number of pages in the index leaf would grow by a factor of 1,000, and the index tree would probably result in one extra level (four levels deep). This plan has linear scaling. You would end up with close to 4,000,000 logical reads, and a run time of a few minutes.
When you need to compute a MIN or MAX aggregate against a large table, with very high density in the grouping column (important!), and a supporting B-tree index keyed on the grouping column and the aggregation column, there’s a much more optimal plan shape than the one in Figure 6. Imagine a plan shape that scans the small set of shipper IDs from some index on the Shippers table, and in a loop applies for each shipper a seek against the supporting index on Orders to obtain the aggregate. With 1,000,000 rows in the table, 5 seeks would involve 15 reads. With 1,000,000,000 rows, 5 seeks would involve 20 reads. With a trillion rows, 25 reads total. Clearly, a much more optimal plan. You can actually achieve such a plan by querying the Shippers table, and obtaining the aggregate using a scalar aggregate subquery against Orders, like so (we’ll call this solution Query 7):
SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S;The plan for this query is shown in Figure 7.
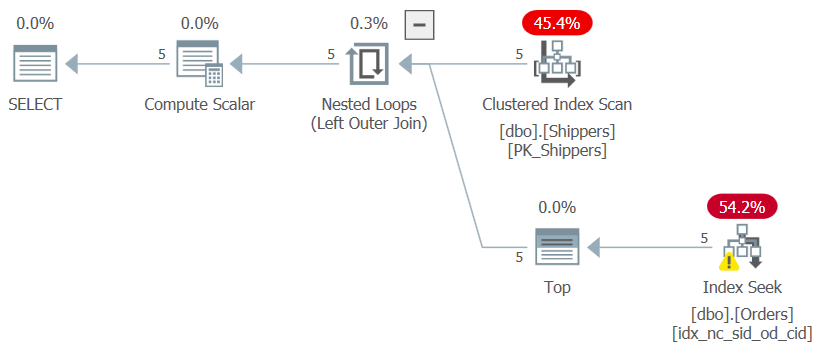 Figure 7: Plan for Query 7
Figure 7: Plan for Query 7
The desired plan shape is achieved, and the performance numbers for the execution of this query are negligible as expected:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
As long as the grouping column is very dense, the size of the Orders table becomes virtually insignificant.
But wait a moment before you go celebrating. There’s a requirement to keep only the shippers whose maximum related order date in the Orders table is on or after 2018. Sounds like a simple enough addition. Define a derived table based on Query 7, and apply the filter in the outer query, like so (we’ll call this solution Query 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101';Alas, SQL Server unnests the derived table query, as well as the subquery, converting the aggregation logic to the equivalent of the grouped query logic, with shipperid as the grouping column. And the way SQL Server knows to optimize a grouped query is based on a single pass over the input data, resulting in a plan very similar to the one shown earlier in Figure 6, only with the extra filter. The plan for Query 8 is shown in Figure 8.
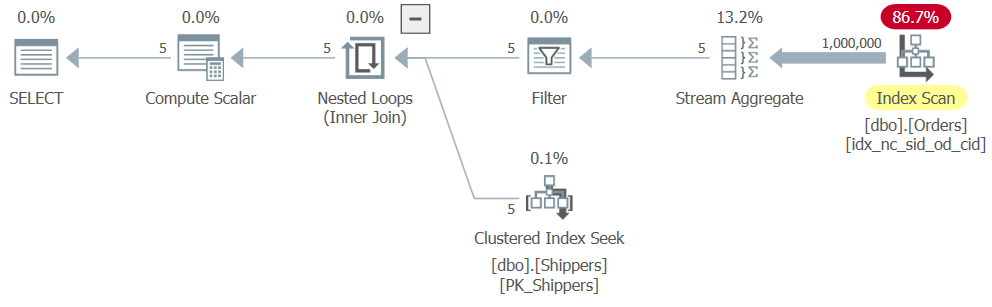 Figure 8: Plan for Query 8
Figure 8: Plan for Query 8
Consequentially, the scaling is linear, and the performance numbers are similar to the ones for Query 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
The fix is to introduce an unnesting inhibitor. This can be done by adding a TOP filter to the table expression that the derived table is based on, like so (we’ll call this solution Query 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101';The plan for this query is shown in Figure 9 and has the desired plan shape with the seeks:
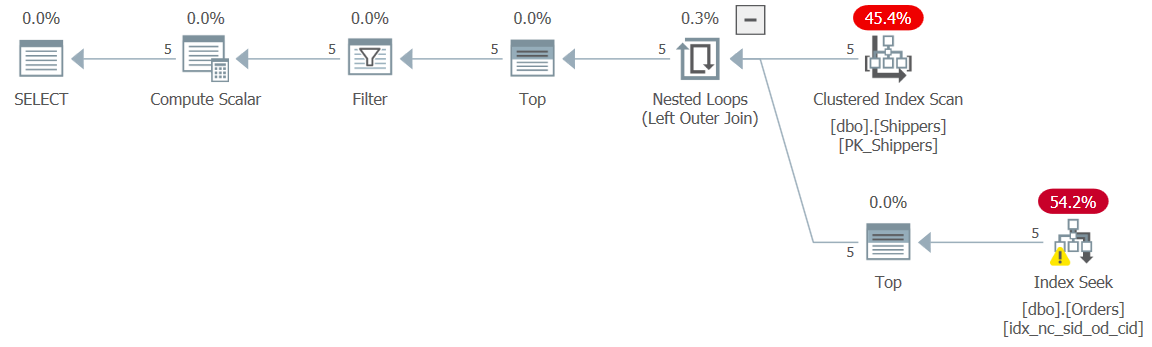 Figure 9: Plan for Query 9
Figure 9: Plan for Query 9
The performance numbers for this execution are then of course negligible:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Yet another option is to prevent the unnesting of the subquery, by replacing the MAX aggregate with an equivalent TOP (1) filter, like so (we’ll call this solution Query 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101';The plan for this query is shown in Figure 10 and again, has the desired shape with the seeks.
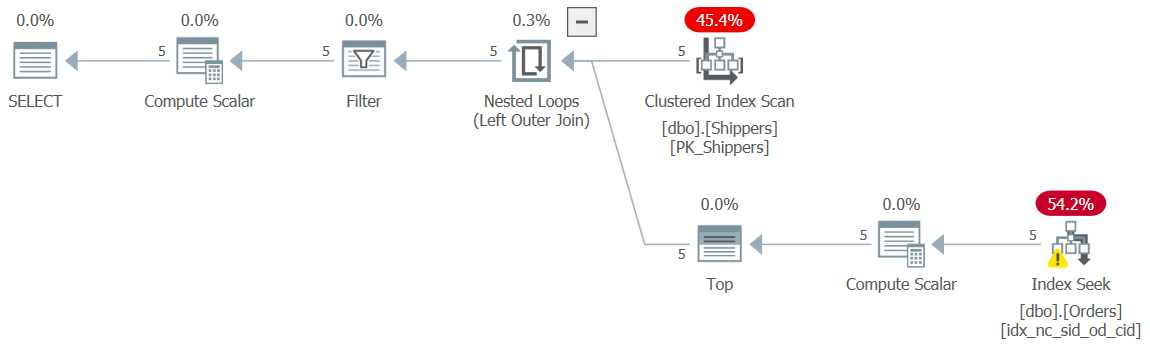 Figure 10: Plan for Query 10
Figure 10: Plan for Query 10
I got the familiar negligible performance numbers for this execution:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
When you’re done, run the following code to stop reporting performance statistics:
SET STATISTICS IO, TIME OFF;Summary
In this article I continued the discussion I started last month about optimization of derived tables. This month I focused on unnesting of derived tables. I explained that typically unnesting results in a more optimal plan compared to without unnesting, but also covered examples where it’s undesirable. I showed an example where unnesting resulted in an error as well as an example resulting in performance degradation. I demonstrated how to prevent unnesting by applying an unnesting inhibitor like TOP.
Next month I’ll continue the exploration of named table expressions, shifting the focus to CTEs.
4 thoughts on “Fundamentals of table expressions, Part 4 – Derived tables, optimization considerations, continued”
Comments are closed.

{kind=link}
Thank you Itzik!
I enjoyed reading this post very much.
I wish Microsoft introduced a more structured way to introduce an unnesting inhibitor in the form of a query hint, rather than using the TOP operator with the maximum BIGINT value. Because, while achieving the desired result, it makes the code less readable, and without proper documentation, someone else might not understand it and remove it (since logically it is redundant).
Also, you have an HTML element injected into query 4 by mistake.
Thanks Guy!
I totally agree regarding the hint.
Typo fixed (thanks to Aaron for this).
Arguably the reason why there isn't one is that you're supposed to rely on the optimizer for this kind of thing.
Ergo, MS did a bad job in this case (a kind of skip-scanning, but on a related table) so really they need to work on that. SQL Server doesn't doo well with thinking out of the box in that sort of way, which is a shame.
Hi Charlie,
You could say this about any performance hint. The reality is that sometimes you need those. A good optimizer does a good job most of the time and occasionally needs a hint. SQL Server's optimizer certainly falls into this category.