
Fundamentals of table expressions, Part 5 – CTEs, logical considerations
This article is the fifth part in a series about table expressions. In Part 1 I provided the background to table expressions. In Part 2, Part 3, and Part 4, I covered both the logical and the optimization aspects of derived tables. This month I start the coverage of common table expressions (CTEs). Like with derived tables, I’ll first address the logical treatment of CTEs, and in the future I’ll get to optimization considerations.
In my examples I’ll use a sample database called TSQLV5. You can find the script that creates and populates it here, and its ER diagram here.
CTEs
Let’s start with the term common table expression. Neither this term, nor its acronym CTE, appear in the ISO/IEC SQL standard specs. So it could be that the term originated in one of the database products and later adopted by some of the other database vendors. You can find it in the documentation of Microsoft SQL Server and Azure SQL Database. T-SQL supports it starting with SQL Server 2005. The standard uses the term query expression to represent an expression that defines one or more CTEs, including the outer query. It uses the term with list element to represent what T-SQL calls a CTE. I’ll provide the syntax for a query expression shortly.
The source of the term aside, common table expression, or CTE, is the commonly used term by T-SQL practitioners for the structure that is the focus of this article. So first, let’s address whether it is an appropriate term. We already concluded that the term table expression is appropriate for an expression that conceptually returns a table. Derived tables, CTEs, views and inline table valued functions are all types of named table expressions that T-SQL supports. So, the table expression part of common table expression certainly seems appropriate. As for the common part of the term, it probably has to do with one of the design advantages of CTEs over derived tables. Remember that you cannot reuse the derived table name (or more accurately the range variable name) more than once in the outer query. Conversely, the CTE name can be used multiple times in the outer query. In other words, the CTE name is common to the outer query. Of course, I’ll demonstrate this design aspect in this article.
CTEs give you similar benefits to derived tables, including enabling the development of modular solutions, reusing column aliases, indirectly interacting with window functions in clauses that don’t normally allow them, supporting modifications that indirectly rely on TOP or OFFSET FETCH with order specification, and others. But there are certain design advantages compared to derived tables, which I’ll cover in detail after I provide the syntax for the structure.
Syntax
Here’s the standard’s syntax for a query expression:
Function
Specify a table.
Format
<query expression> ::=
[ <with clause> ] <query expression body>
[ <order by clause> ] [ <result offset clause> ] [ <fetch first clause> ]
<with clause> ::= WITH [ RECURSIVE ] <with list>
<with list> ::= <with list element> [ { <comma> <with list element> }… ]
<with list element> ::=
<query name> [ <left paren> <with column list> <right paren> ]
AS <table subquery> [ <search or cycle clause> ]
<with column list> ::= <column name list>
<query expression body> ::=
<query term>
| <query expression body> UNION [ ALL | DISTINCT ]
[ <corresponding spec> ] <query term>
| <query expression body> EXCEPT [ ALL | DISTINCT ]
[ <corresponding spec> ] <query term>
<query term> ::=
<query primary>
| <query term> INTERSECT [ ALL | DISTINCT ]
[ <corresponding spec> ] <query primary>
<query primary> ::=
<simple table>
| <left paren> <query expression body>
[ <order by clause> ] [ <result offset clause> ] [ <fetch first clause> ]
<right paren>
<simple table> ::=
<query specification> | <table value constructor> | <explicit table>
<explicit table> ::= TABLE <table or query name>
<corresponding spec> ::=
CORRESPONDING [ BY <left paren> <corresponding column list> <right paren> ]
<corresponding column list> ::= <column name list>
<order by clause> ::= ORDER BY <sort specification list>
<result offset clause> ::= OFFSET <offset row count> { ROW | ROWS }
<fetch first clause> ::=
FETCH { FIRST | NEXT } [ <fetch first quantity> ] { ROW | ROWS } { ONLY | WITH TIES }
<fetch first quantity> ::=
<fetch first row count>
| <fetch first percentage>
<offset row count> ::= <simple value specification>
<fetch first row count> ::= <simple value specification>
<fetch first percentage> ::= <simple value specification> PERCENT
7.18 <search or cycle clause>
Function
Specify the generation of ordering and cycle detection information in the result of recursive query expressions.
Format
<search or cycle clause> ::=
<search clause> | <cycle clause> | <search clause> <cycle clause>
<search clause> ::=
SEARCH <recursive search order> SET <sequence column>
<recursive search order> ::=
DEPTH FIRST BY <column name list> | BREADTH FIRST BY <column name list>
<sequence column> ::= <column name>
<cycle clause> ::=
CYCLE <cycle column list> SET <cycle mark column> TO <cycle mark value>
DEFAULT <non-cycle mark value> USING <path column>
<cycle column list> ::= <cycle column> [ { <comma> <cycle column> }… ]
<cycle column> ::= <column name>
<cycle mark column> ::= <column name>
<path column> ::= <column name>
<cycle mark value> ::= <value expression>
<non-cycle mark value> ::= <value expression>
7.3 <table value constructor>
Function
Specify a set of <row value expression>s to be constructed into a table.
Format
<table value constructor> ::= VALUES <row value expression list>
<row value expression list> ::=
<table row value expression> [ { <comma> <table row value expression> }… ]
<contextually typed table value constructor> ::=
VALUES <contextually typed row value expression list>
<contextually typed row value expression list> ::=
<contextually typed row value expression>
[ { <comma> <contextually typed row value expression> }… ]
The standard term query expression represents an expression involving a WITH clause, a with list, which is made of one or more with list elements, and an outer query. T-SQL refers to the standard with list element as a CTE.
T-SQL doesn’t support all of the standard syntax elements. For example, it doesn’t support some of the more advanced recursive query elements that allow you to control the search direction and handle cycles in a graph structure. Recursive queries are the focus of next month’s article.
Here’s the T-SQL syntax for a simplified query against a CTE:
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;Here’s an example for a simple query against a CTE representing USA customers:
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;You will find the same three parts in a statement against a CTE like you would with a statement against a derived table:
- The table expression (the inner query)
- The name assigned to the table expression (the range variable name)
- The outer query
What’s different about the design of CTEs compared to derived tables is where in the code these three elements are located. With derived tables, the inner query is nested within the outer query’s FROM clause, and the table expression’s name is assigned after the table expression itself. The elements are sort of intertwined. Conversely, with CTEs, the code separates the three elements: first you assign the table expression name; second you specify the table expression—from start to end with no interruptions; third you specify the outer query—from start to end with no interruptions. Later, under “Design considerations,” I’ll explain the implications of these design differences.
A word about CTEs and the use of a semicolon as a statement terminator. Unfortunately, unlike standard SQL, T-SQL doesn’t force you to terminate all statements with a semicolon. However, there are very few cases in T-SQL where without a terminator the code is ambiguous. In those cases, the termination is mandatory. One such case concerns the fact that the WITH clause is used for multiple purposes. One is to define a CTE, another is to define a table hint for a query, and there are a few additional use cases. As an example, in the following statement the WITH clause is used to force the serializable isolation level with a table hint:
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);The potential for ambiguity is when you have an unterminated statement preceding a CTE definition, in which case the parser might not be able to tell whether the WITH clause belongs to the first or second statement. Here’s an example demonstrating this:
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UCHere the parser cannot tell whether the WITH clause is supposed to be used to define a table hint for the Customers table in the first statement, or start a CTE definition. You get the following error:
Incorrect syntax near 'UC'. If this is intended to be a common table expression, you need to explicitly terminate the previous statement with a semi-colon.
The fix is of course to terminate the statement preceding the CTE definition, but as a best practice, you really should be terminating all of your statements:
SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;You may have noticed that some people start their CTE definitions with a semicolon as a practice, like so:
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;The point in this practice is to reduce the potential for future errors. What if at a later point someone adds an unterminated statement right before your CTE definition in the script, and doesn’t bother checking the complete script, rather only their statement? Your semicolon right before the WITH clause effectively becomes their statement terminator. You can certainly see the practicality of this practice, but it is a bit unnatural. What’s recommended, albeit harder to achieve, is to instill good programming practices in the organization, including the termination of all statements.
In terms of the syntax rules that apply to the table expression used as the inner query in the CTE definition, they are the same as the ones that apply to the table expression used as the inner query in a derived table definition. Those are:
- All of the table expression’s columns must have names
- All of the table expression’s column names must be unique
- The table expression’s rows have no order
For details, see the section “A table expression is a table” in Part 2 of the series.
Design considerations
If you survey experienced T-SQL developers about whether they prefer to use derived tables or CTEs, not everyone will agree on which is better. Naturally, different people have different styling preferences. I sometimes use derived tables and sometimes CTEs. It’s good to be able to consciously identify the specific language design differences between the two tools, and choose based on your priorities in any given solution. With time and experience, you make your choices more intuitively.
Furthermore, it’s important not to confuse the use of table expressions and temporary tables, but that’s a performance related discussion that I will address in a future article.
CTEs have recursive querying capabilities and derived tables don’t. So, if you need to rely on those, you would naturally go with CTEs. Recursive queries are the focus of next month’s article.
In Part 2 I explained that I see nesting of derived tables as adding complexity to the code, since it makes it hard to follow the logic. I provided the following example, identifying order years in which more than 70 customers placed orders:
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70;CTEs don’t support nesting. So when you review or troubleshoot a solution based on CTEs, you don’t get lost in the nested logic. Instead of nesting, you build more modular solutions by defining multiple CTEs under the same WITH statement, separated by commas. Each of the CTEs is based on a query that is written from start to end with no interruptions. I see it as a good thing from a code clarity and maintainability perspective.
Here’s a solution to the aforementioned task using CTEs:
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;I like the CTE-based solution better. But again, ask experienced developers which of the above two solutions they prefer, and they won’t all agree. Some actually do prefer the nested logic, and being able to see everything in one place.
One very clear advantage of CTEs over derived tables, is when you need to interact with multiple instances of the same table expression in your solution. Remember the following example based on derived tables from Part 2 in the series:
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1;This solution returns order years, order counts per year, and the difference between the current year’s and the previous year’s counts. Yes, you could do it more easily with the LAG function, but my focus here is not finding the best way to achieve this very specific task. I use this example to illustrate certain language design aspects of named table expressions.
The issue with this solution is that you cannot assign a name to a table expression and reuse it in the same logical query processing step. You name a derived table after the table expression itself in the FROM clause. If you define and name a derived table as the first input of a join, you cannot also reuse that derived table name as the second input of the same join. If you need to self-join two instances of the same table expression, with derived tables you have no choice but to duplicate the code. That’s what you did in the above example. Conversely, the CTE name is assigned as the first element of the code among the aforementioned three (CTE name, inner query, outer query). In logical query processing terms, by the time you get to the outer query, the CTE name is already defined and available. This means that you can interact with multiple instances of the CTE name in the outer query, like so:
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1;This solution has a clear programmability advantage to the one based on derived tables in that you don’t need to maintain two copies of the same table expression. There’s more to say about it from a physical processing perspective, and compare it with the use of temporary tables, but I’ll do so in a future article that focuses on performance.
One advantage that code based on derived tables has compared to code based on CTEs has to do with the closure property that a table expression is supposed to possess. Remember that the closure property of a relational expression says that both the inputs and the output are relations, and that a relational expression can therefore be used where a relation is expected, as input to yet another relational expression. Similarly, a table expression returns a table and is supposed to be available as an input table for another table expression. This holds true for a query that is based on derived tables—you can use it where a table is expected. For example, you can use a query that is based on derived tables as the inner query of a CTE definition, as in the following example:
WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C;However, the same does not hold true for a query that is based on CTEs. Even though it is conceptually supposed to be considered a table expression, you cannot use it as the inner query in derived table definitions, subqueries, and CTEs themselves. For example, the following code is not valid in T-SQL:
SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D;The good news is that you can use a query that is based on CTEs as the inner query in views and inline table-valued functions, which I cover in future articles.
Also, remember, you can always define another CTE based on the last query, and then have the outermost query interact with that CTE:
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;From a troubleshooting standpoint, as mentioned, I usually find it easier to follow the logic of code that is based on CTEs, compared to code based on derived tables. However, solutions based on derived tables do have an advantage in that you can highlight any nesting level and run it independently, as shown in Figure 1.
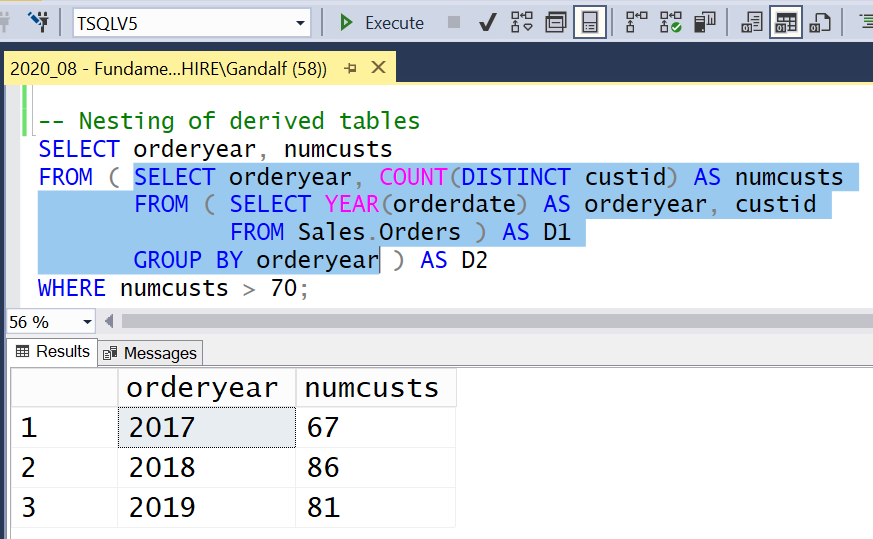 Figure 1: Can highlight and run part of the code with derived tables
Figure 1: Can highlight and run part of the code with derived tables
With CTEs things are trickier. In order for code involving CTEs to be runnable, it has to start with a WITH clause, followed by one or more named parenthesized table expressions separated by commas, followed by a nonparenthesized query with no preceding comma. You are able to highlight and run any of the inner queries that are truly self-contained, as well as the complete solution’s code; however, you cannot highlight and successfully run any other intermediate part of the solution. For example, Figure 2 shows an unsuccessful attempt to run the code representing C2.
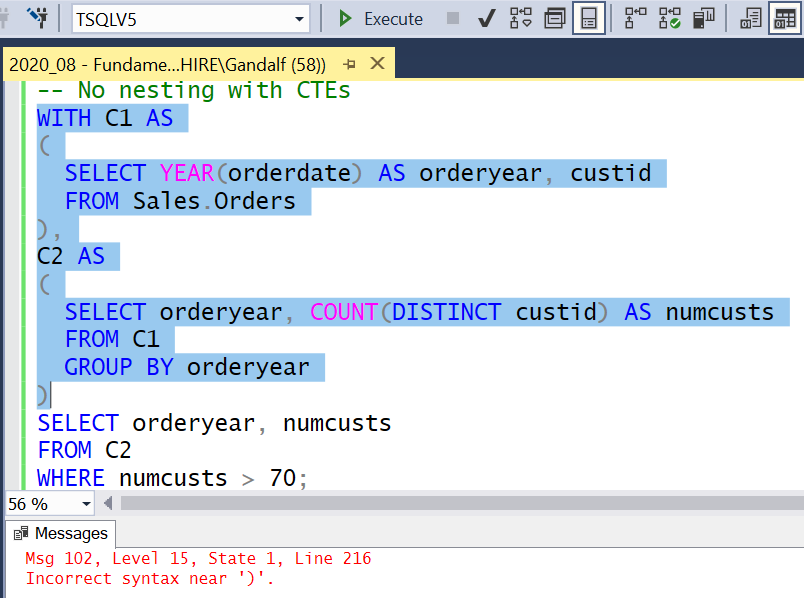 Figure 2: Cannot highlight and run part of the code with CTEs
Figure 2: Cannot highlight and run part of the code with CTEs
So with CTEs, you have to resort to somewhat awkward means in order to be able to troubleshoot an intermediate step of the solution. For example, one common solution is to temporarily inject a SELECT * FROM your_cte query right below the relevant CTE. You then highlight and run the code including the injected query, and when you’re done, you delete the injected query. Figure 3 demonstrates this technique.
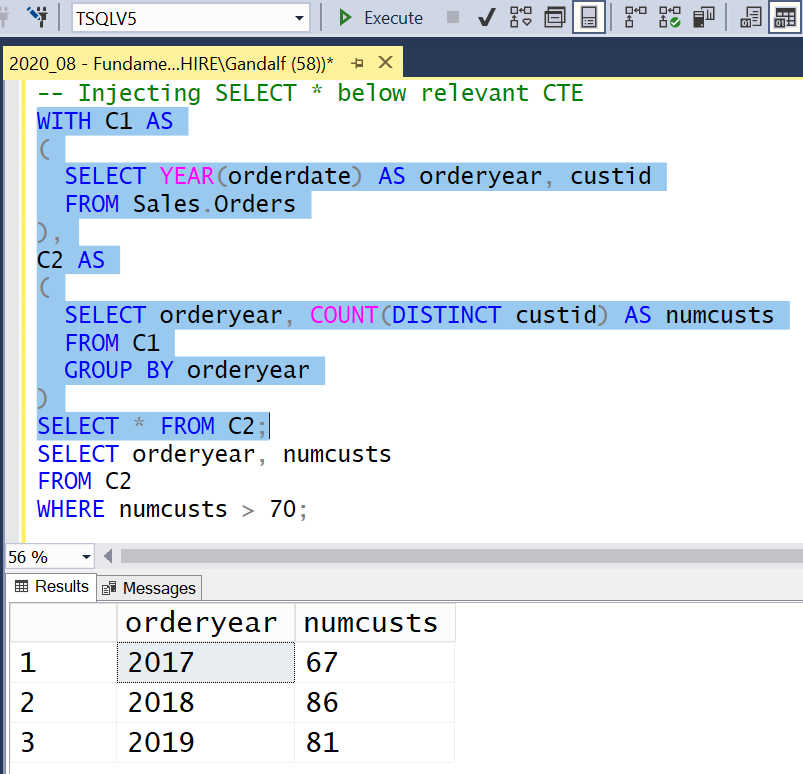 Figure 3: Inject SELECT * below relevant CTE
Figure 3: Inject SELECT * below relevant CTE
The problem is that whenever you make changes to the code—even temporary minor ones like the above—there’s a chance that when you attempt to revert back to the original code, you’ll end up introducing a new bug.
Another option is to style your code a bit differently, such that each nonfirst CTE definition starts with a separate line of code that looks like this:
, cte_name AS (Then, whenever you want to run an intermediate part of the code down to a given CTE, you can do so with minimal changes to your code. Using a line comment you comment out only that one line of code that corresponds to that CTE. You then highlight and run the code down to and including that CTE’s inner query, which is now considered the outermost query, as illustrated in Figure 4.
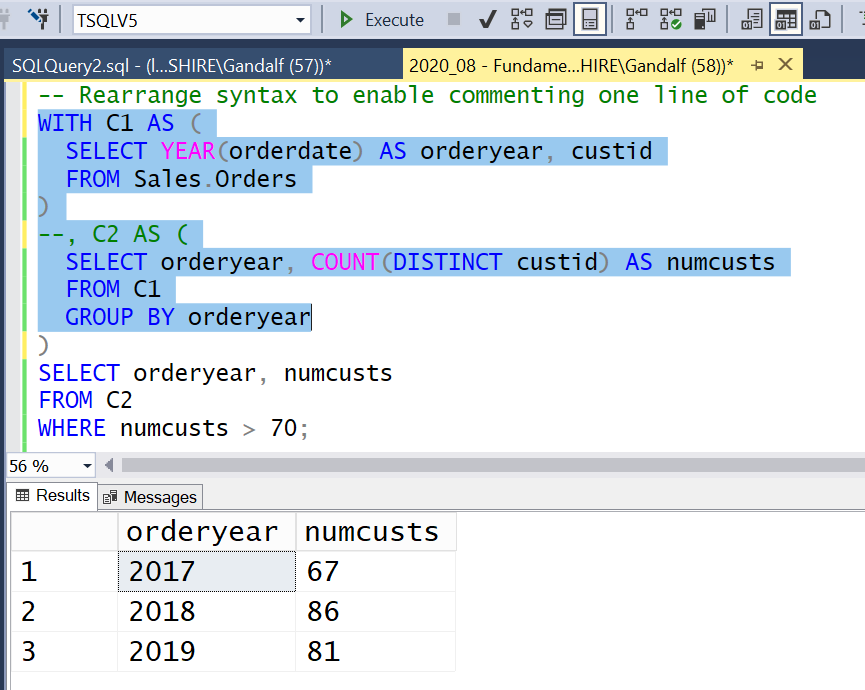 Figure 4: Rearrange syntax to enable commenting one line of code
Figure 4: Rearrange syntax to enable commenting one line of code
If you’re not happy with this style, you have yet another option. You can use a block comment that starts right before the comma that precedes the CTE of interest and ends after the open parenthesis, as illustrated in Figure 5.
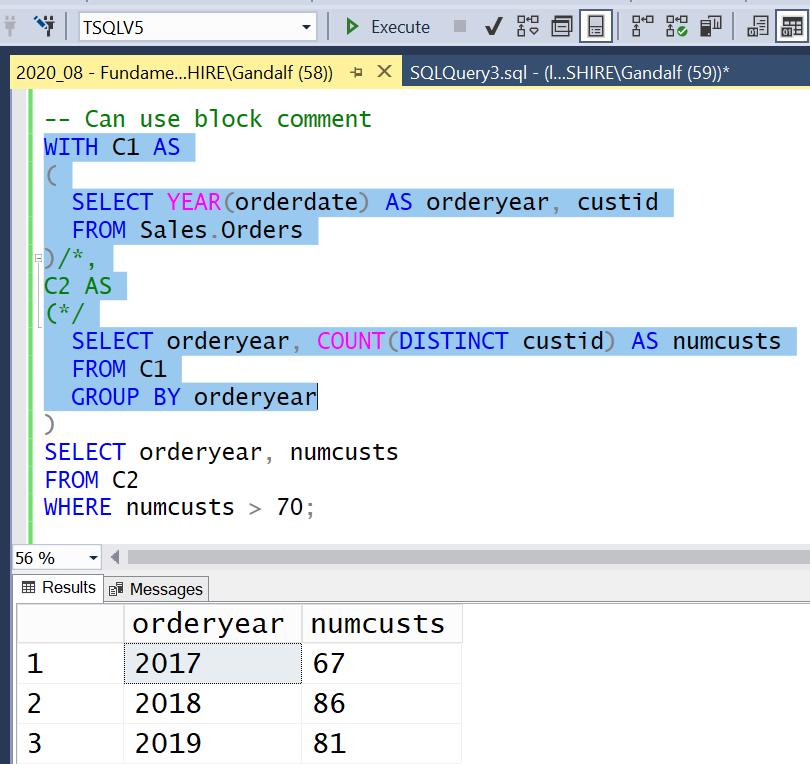 Figure 5: Use block comment
Figure 5: Use block comment
It boils down to personal preferences. I typically use the temporarily injected SELECT * query technique.
Table value constructor
There’s a certain limitation in T-SQL’s support for table value constructors compared to the standard. If you’re not familiar with the construct, make sure to check out Part 2 in the series first, where I describe it in detail. Whereas T-SQL allows you to define a derived table based on a table value constructor, it doesn’t allow you to define a CTE based on a table value constructor.
Here’s a supported example that uses a derived table:
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate);Unfortunately, similar code that uses a CTE isn’t supported:
WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;This code generates the following error:
Incorrect syntax near the keyword 'VALUES'.
There are a couple of workarounds, though. One is to use a query against a derived table, that in turn is based on a table value constructor, as the CTE’s inner query, like so:
WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts;Another is to resort to the technique that people used before table-valued constructors were introduced into T-SQL—using a series of FROMless queries separated by UNION ALL operators, like so:
WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts;Notice that the column aliases are assigned right after the CTE name.
The two methods get algebrized and optimized the same, so use whichever you’re more comfortable with.
Producing a sequence of numbers
A tool that I use quite often in my solutions is an auxiliary table of numbers. One option is to create an actual numbers table in your database and populate it with a reasonably sized sequence. Another is to develop a solution that produces a sequence of numbers on the fly. For the latter option, you want the inputs to be the delimiters of the desired range (we’ll call them @low and @high). You want your solution to support potentially large ranges. Here’s my solution for this purpose, using CTEs, with a request for the range 1001 through 1010 in this specific example:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;This code generates the following output:
n ----- 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010
The first CTE called L0 is based on a table value constructor with two rows. The actual values there are insignificant; what’s important is that it has two rows. Then, there’s a sequence of five additional CTEs named L1 through L5, each applying a cross join between two instances of the preceding CTE. The following code calculates the number of rows potentially generated by each of the CTEs, where @L is the CTE level number:
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));Here are the numbers that you get for each CTE:
| CTE | Cardinality |
|---|---|
| L0 | 2 |
| L1 | 4 |
| L2 | 16 |
| L3 | 256 |
| L4 | 65,536 |
| L5 | 4,294,967,296 |
Going up to level 5 gives you over four billion rows. This should be sufficient for any practical use case that I can think of. The next step takes place in the CTE called Nums. You use a ROW_NUMBER function to generate a sequence of integers starting with 1 based on no defined order (ORDER BY (SELECT NULL)), and name the result column rownum. Finally, the outer query uses a TOP filter based on rownum ordering to filter as many numbers as the desired sequence cardinality (@high – @low + 1), and computes the result number n as @low + rownum – 1.
Here you can really appreciate the beauty in the CTE design and the savings that it enables when you build solutions in a modular fashion. Ultimately, the unnesting process unpacks 32 tables, each consisting of two rows based on constants. This can be clearly seen in the execution plan for this code, as shown in Figure 6 using SentryOne Plan Explorer.
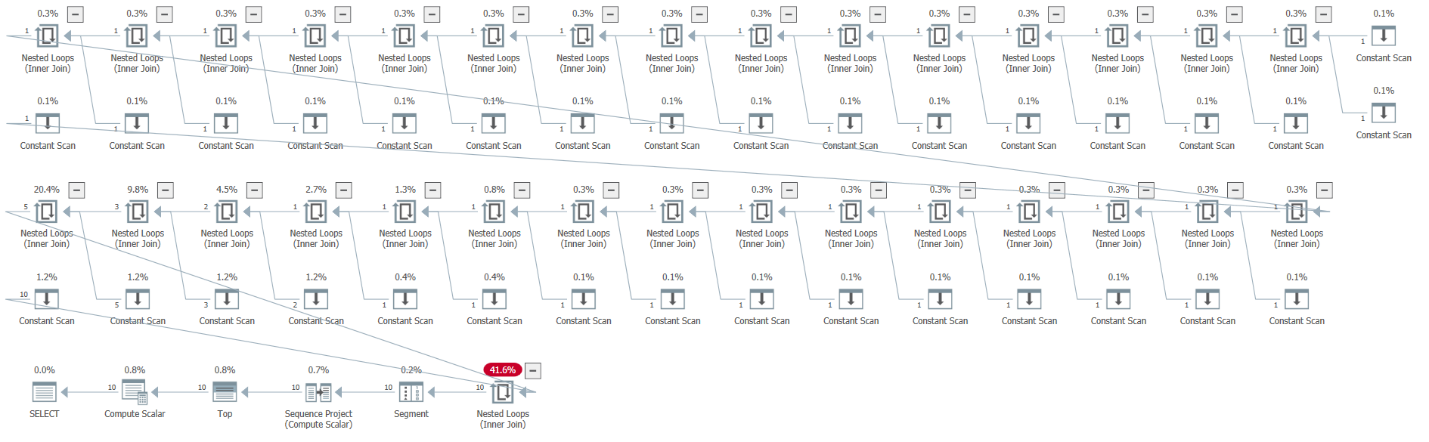 Figure 6: Plan for query generating sequence of numbers
Figure 6: Plan for query generating sequence of numbers
Each Constant Scan operator represents a table of constants with two rows. The thing is, the Top operator is the one requesting those rows, and it short circuits after it gets the desired number. Notice the 10 rows indicated above the arrow flowing into the Top operator.
I know that this article’s focus is the conceptual treatment of CTEs and not physical/performance considerations, but by looking at the plan you can really appreciate the brevity of the code compared to the long-windedness of what it translates to behind the scenes.
Using derived tables, you can actually write a solution that substitutes each CTE reference with the underlying query that it represents. What you get is quite scary:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum;Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum;Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
Used in modification statements
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];As an example (don’t actually run it), the following code deletes the 10 oldest orders:
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;Here’s the general syntax of an UPDATE statement against a CTE:
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN;The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
orderid oldrequireddate newrequireddate ----------- --------------- --------------- 11008 2019-05-06 2020-07-16 11019 2019-05-11 2020-07-16 11039 2019-05-19 2020-07-16 11040 2019-05-20 2020-07-16 11045 2019-05-21 2020-07-16 11051 2019-05-25 2020-07-16 11054 2019-05-26 2020-07-16 11058 2019-05-27 2020-07-16 11059 2019-06-10 2020-07-16 11061 2019-06-11 2020-07-16 (10 rows affected)
Of course you will get a different new required date based on when you run this code.
Summary
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
| Item | Derived table | CTE |
|---|---|---|
| Supports nesting | Yes | No |
| Supports multiple references | No | Yes |
| Supports table value constructor | Yes | No |
| Can highlight and run part of code | Yes | No |
| Supports recursion | No | Yes |
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
8 thoughts on “Fundamentals of table expressions, Part 5 – CTEs, logical considerations”
Comments are closed.

{kind=link}
Clear and thorough, as always.
Thanks Itzik!
Thanks Guy!
One of the things I really wish T-SQL syntax had, is defining a common iTVF on a single query, similar to a CTE. So something like this (obviously a trivial example):
;WITH TVF (@headerId int) AS
(SELECT *
FROM Detail
WHERE headerId = @headerId)
SELECT *
FROM Header h
OUTER APPLY TVF(h.HeaderId)
Sounds like a good idea!
Hi Itzik, great article, thanks!
I've done some tests with your solution to produce a sequence of numbers, but instead of getting TOP N numbers in the outermost query I used a COUNT_BIG just to check how long it would take to produce and count the expected four billion rows. Then I realized the last join occurs after a partial aggregation, so it's not really producing 4 billion rows, but the analysis below still make sense to me.
With all CTEs from L0 to L5 you defined, it took about 3 minutes when using MAXDOP 1.
Then I changed L0 to produce four rows instead of two and took out the last CTE. The time dropped to less than a minute.
I then changed L0 again to produce 16 rows and took out another CTE, keeping from L0 to L3. This time it finished in 7 seconds.
The query plans got significantly smaller in each interaction. Even though the same number of rows were processed the amount of CPU used dropped a lot, probably due to having less operators in the query tree, which ultimately translates into less code being executed inside the engine.
The time reduction might not be noticeably when doing some other work but at the very least the plans are smaller to read.
Hi Marcos,
Thanks for sharing your testing results!
Itzik
Thank you. Another proof that I should never think I know enough of all the useful things in T-Sql
Thanks Manuel!