
Fundamentals of Table Expressions, Part 11 – Views, Modification Considerations
This article is the eleventh part in a series about table expressions. So far, I’ve covered derived tables and CTEs, and recently started the coverage of views. In Part 9 I compared views to derived tables and CTEs, and in Part 10 I discussed DDL changes and the implications of using SELECT * in the view’s inner query. In this article, I focus on modification considerations.
As you probably know, you’re allowed to modify data in base tables indirectly through named table expressions like views. You can control modification permissions against views. In fact, you can grant users permissions to modify data through views without granting them permissions to modify the underlying tables directly.
You do need to be aware of certain complexities and restrictions that apply to modifications through views. Interestingly, some of the supported modifications can end up with surprising outcomes, especially if the user modifying the data isn’t aware they’re interacting with a view. You can impose further restrictions to modifications through views by using an option called CHECK OPTION, which I’ll cover in this article. As part of the coverage, I’ll describe a curious inconsistency between how the CHECK OPTION in a view and a CHECK constraint in a table handle modifications—specifically ones involving NULLs.
Sample Data
As sample data for this article, I’ll use tables called Orders and OrderDetails. Use the following code to create these tables in tempdb and populate them with some initial sample data:
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.OrderDetails, dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL
CONSTRAINT PK_Orders PRIMARY KEY,
orderdate DATE NOT NULL,
shippeddate DATE NULL
);
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate)
VALUES(1, '20210802', '20210804'),
(2, '20210802', '20210805'),
(3, '20210804', '20210806'),
(4, '20210826', NULL),
(5, '20210827', NULL);
CREATE TABLE dbo.OrderDetails
(
orderid INT NOT NULL
CONSTRAINT FK_OrderDetails_Orders REFERENCES dbo.Orders,
productid INT NOT NULL,
qty INT NOT NULL,
unitprice NUMERIC(12, 2) NOT NULL,
discount NUMERIC(5, 4) NOT NULL,
CONSTRAINT PK_OrderDetails PRIMARY KEY(orderid, productid)
);
INSERT INTO dbo.OrderDetails(orderid, productid, qty, unitprice, discount)
VALUES(1, 1001, 5, 10.50, 0.05),
(1, 1004, 2, 20.00, 0.00),
(2, 1003, 1, 52.99, 0.10),
(3, 1001, 1, 10.50, 0.05),
(3, 1003, 2, 54.99, 0.10),
(4, 1001, 2, 10.50, 0.05),
(4, 1004, 1, 20.30, 0.00),
(4, 1005, 1, 30.10, 0.05),
(5, 1003, 5, 54.99, 0.00),
(5, 1006, 2, 12.30, 0.08);The Orders table contains order headers, and the OrderDetails table contains order lines. Unshipped orders have a NULL in the shippeddate column. If you prefer a design that doesn’t use NULLs, you could use a specific future date for unshipped orders, such as “99991231.”
CHECK OPTION
To understand the circumstances where you would want to use the CHECK OPTION as part of a view’s definition, we’ll first examine what can happen when you don’t use it.
The following code creates a view called FastOrders representing orders shipped within seven days since they were placed:
CREATE OR ALTER VIEW dbo.FastOrders
AS
SELECT orderid, orderdate, shippeddate
FROM dbo.Orders
WHERE DATEDIFF(day, orderdate, shippeddate) <= 7;
GOUse the following code to insert through the view an order shipped two days after being placed:
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate)
VALUES(6, '20210805', '20210807');Query the view:
SELECT * FROM dbo.FastOrders;You get the following output, which includes the new order:
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 6 2021-08-05 2021-08-07
Query the underlying table:
SELECT * FROM dbo.Orders;You get the following output, which includes the new order:
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07
The row was inserted into the underlying base table through the view.
Next, insert through the view a row shipped 10 days after being placed, contradicting the view’s inner query filter:
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate)
VALUES(7, '20210805', '20210815');The statement completes successfully, reporting one row affected.
Query the view:
SELECT * FROM dbo.FastOrders;You get the following output, which excludes the new order:
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 6 2021-08-05 2021-08-07
If you know FastOrders is a view, this might all seem sensible. After all, the row was inserted into the underlying table, and it doesn’t satisfy the view’s inner query filter. But if you’re unaware that FastOrders is a view and not a base table, this behavior would seem surprising.
Query the underlying Orders table:
SELECT * FROM dbo.Orders;You get the following output, which includes the new order:
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 7 2021-08-05 2021-08-15
You could experience a similar surprising behavior if you update through the view the shippeddate value in a row that is currently part of the view to a date that makes it not qualify as part of the view anymore. Such an update is normally allowed, but again, it takes place in the underlying base table. If you query the view after such an update, the modified row seems to be gone. In practice it’s still there in the underlying table, it’s just not considered part of the view anymore.
Run the following code to delete the rows you added earlier:
DELETE FROM dbo.Orders WHERE orderid >= 6;If you want to prevent modifications that conflict with the view’s inner query filter, add WITH CHECK OPTION at the end of the inner query as part of the view definition, like so:
CREATE OR ALTER VIEW dbo.FastOrders
AS
SELECT orderid, orderdate, shippeddate
FROM dbo.Orders
WHERE DATEDIFF(day, orderdate, shippeddate) <= 7
WITH CHECK OPTION;
GOInserts and updates through the view are allowed as long as they comply with the inner query’s filter. Otherwise, they’re rejected.
For example, use the following code to insert through the view a row that doesn’t conflict with the inner query filter:
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate)
VALUES(6, '20210805', '20210807');The row is added successfully.
Attempt to insert a row that does conflict with the filter:
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate)
VALUES(7, '20210805', '20210815');This time the row is rejected with the following error:
The attempted insert or update failed because the target view either specifies WITH CHECK OPTION or spans a view that specifies WITH CHECK OPTION and one or more rows resulting from the operation did not qualify under the CHECK OPTION constraint.
NULL Inconsistencies
If you’ve been working with T-SQL for some time, you’re likely well aware of the aforementioned modification complexities and the function CHECK OPTION serves. Often, even experienced people find the NULL handling of the CHECK OPTION as surprising. For years I used to think of the CHECK OPTION in a view as serving the same function as a CHECK constraint in a base table’s definition. That’s also how I used to describe this option when writing or teaching about it. Indeed, as long as there are no NULLs involved in the filter predicate, it’s convenient to think of the two in similar terms. They behave consistently in such a case—accepting rows that agree with the predicate and rejecting ones that conflict with it. However, the two handle NULLs inconsistently.
When using the CHECK OPTION, a modification is allowed through the view as long as the predicate evaluates to true, otherwise it’s rejected. This means it’s rejected when the view’s predicate evaluates to false or unknown (when a NULL is involved). With a CHECK constraint, the modification is allowed when the constraint’s predicate evaluates to true or unknown, and rejected when the predicate evaluates to false. That’s an interesting difference! First, let’s see this in action, then we’ll try and figure out the logic behind this inconsistency.
Attempt to insert through the view a row with a NULL shipped date:
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate)
VALUES(8, '20210828', NULL);The view’s predicate evaluates to unknown, and the row is rejected with the following error:
The attempted insert or update failed because the target view either specifies WITH CHECK OPTION or spans a view that specifies WITH CHECK OPTION and one or more rows resulting from the operation did not qualify under the CHECK OPTION constraint.
Let’s try a similar insertion against a base table with a CHECK constraint. Use the following code to add such a constraint to our Order’s table definition:
ALTER TABLE dbo.Orders
ADD CONSTRAINT CHK_Orders_FastOrder
CHECK(DATEDIFF(day, orderdate, shippeddate) <= 7);First, to make sure the constraint works when there are no NULLs involved, try to insert the following order with a shipped date 10 days away from the order date:
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate)
VALUES(7, '20210805', '20210815');This attempted insertion is rejected with the following error:
The INSERT statement conflicted with the CHECK constraint "CHK_Orders_FastOrder". The conflict occurred in database "tempdb", table "dbo.Orders".
Use the following code to insert a row with a NULL shipped date:
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate)
VALUES(8, '20210828', NULL);A CHECK constraint is supposed to reject false cases, but in our case the predicate evaluates to unknown, so the row is added successfully.
Query the Orders table:
SELECT * FROM dbo.Orders;You can see the new order in the output:
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 8 2021-08-28 NULL
What’s the logic behind this inconsistency? You could argue that a CHECK constraint should only be enforced when the constraint’s predicate is clearly violated, meaning when it evaluates to false. This way, if you choose to allow NULLs in the column in question, rows with NULLs in the column are allowed even though the constraint’s predicate evaluates to unknown. In our case, we represent unshipped orders with a NULL in the shippeddate column, and we allow unshipped orders in the table while enforcing the “fast orders” rule only for shipped orders.
The argument to use different logic with a view is that a modification should be allowed through the view only if the result row is a valid part of the view. If the view’s predicate evaluates to unknown, e.g., when the shipped date is NULL, the result row is not a valid part of the view, hence it’s rejected. Only rows for which the predicate evaluates to true are a valid part of the view and hence allowed.
NULLs add lot of complexity to the language. Like them or not, if your data supports them, you want to make sure you understand how T-SQL handles them.
At this point you can drop the CHECK constraint from the Orders table and also drop the FastOrders view for cleanup:
ALTER TABLE dbo.Orders DROP CONSTRAINT CHK_Orders_FastOrder;
DROP VIEW IF EXISTS dbo.FastOrders;TOP/OFFSET-FETCH Restriction
Modifications through views involving the TOP and OFFSET-FETCH filters are normally allowed. However, like with our earlier discussion about views defined without the CHECK OPTION, the outcome of such modification might seem strange to the user if they’re unaware they’re interacting with a view.
Consider the following view representing recent orders as an example:
CREATE OR ALTER VIEW dbo.RecentOrders
AS
SELECT TOP (5) orderid, orderdate, shippeddate
FROM dbo.Orders
ORDER BY orderdate DESC, orderid DESC;
GOUse the following code to insert through the RecentOrders view six orders:
INSERT INTO dbo.RecentOrders(orderid, orderdate, shippeddate)
VALUES(9, '20210801', '20210803'),
(10, '20210802', '20210804'),
(11, '20210829', '20210831'),
(12, '20210830', '20210902'),
(13, '20210830', '20210903'),
(14, '20210831', '20210903');Query the view:
SELECT * FROM dbo.RecentOrders;You get the following output:
orderid orderdate shippeddate ----------- ---------- ----------- 14 2021-08-31 2021-09-03 13 2021-08-30 2021-09-03 12 2021-08-30 2021-09-02 11 2021-08-29 2021-08-31 8 2021-08-28 NULL
From the six inserted orders, only four are part of the view. This seems perfectly sensible if you’re aware that you’re querying a view that is based on a query with a TOP filter. But it might seem strange if you’re thinking that you’re querying a base table.
Query the underlying Orders table directly:
SELECT * FROM dbo.Orders;You get the following output showing all added orders:
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 8 2021-08-28 NULL 9 2021-08-01 2021-08-03 10 2021-08-02 2021-08-04 11 2021-08-29 2021-08-31 12 2021-08-30 2021-09-02 13 2021-08-30 2021-09-03 14 2021-08-31 2021-09-03
If you add the CHECK OPTION to the view definition, INSERT and UPDATE statements against the view will be rejected. Use the following code to apply this change:
CREATE OR ALTER VIEW dbo.RecentOrders
AS
SELECT TOP (5) orderid, orderdate, shippeddate
FROM dbo.Orders
ORDER BY orderdate DESC, orderid DESC
WITH CHECK OPTION;
GOTry to add an order through the view:
INSERT INTO dbo.RecentOrders(orderid, orderdate, shippeddate)
VALUES(15, '20210801', '20210805');You get the following error:
Cannot update the view "dbo.RecentOrders" because it or a view it references was created with WITH CHECK OPTION and its definition contains a TOP or OFFSET clause.
SQL Server doesn’t try to be too smart here. It’s going to reject the change even if the row you attempt to insert would become a valid part of the view at that point. For example, try to add an order with a more recent date that would fall in the top 5 at this point:
INSERT INTO dbo.RecentOrders(orderid, orderdate, shippeddate)
VALUES(15, '20210904', '20210906');The attempted insertion is still rejected with the following error:
Cannot update the view "dbo.RecentOrders" because it or a view it references was created with WITH CHECK OPTION and its definition contains a TOP or OFFSET clause.
Try to update a row through the view:
UPDATE dbo.RecentOrders
SET shippeddate = DATEADD(day, 2, orderdate);In this case the attempted change is also rejected with the following error:
Cannot update the view "dbo.RecentOrders" because it or a view it references was created with WITH CHECK OPTION and its definition contains a TOP or OFFSET clause.
Be aware that defining a view based on a query with TOP or OFFSET-FETCH and the CHECK OPTION will result in the lack of support for INSERT and UPDATE statements through the view.
Deletions through such a view are supported. Run the following code to delete all current five most-recent orders:
DELETE FROM dbo.RecentOrders;The command completes successfully.
Query the table:
SELECT * FROM dbo.Orders;You get the following output after the deletion of the orders with IDs 8, 11, 12, 13, and 14.
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 9 2021-08-01 2021-08-03 10 2021-08-02 2021-08-04
At this point, run the following code for cleanup before running the examples in the next section:
DELETE FROM dbo.Orders WHERE orderid > 5;
DROP VIEW IF EXISTS dbo.RecentOrders;Joins
Updating a view that joins multiple tables is supported, so long as only one of the underlying base tables is affected by the change.
Consider the following view joining Orders and OrderDetails as an example:
CREATE OR ALTER VIEW dbo.OrdersOrderDetails
AS
SELECT
O.orderid, O.orderdate, O.shippeddate,
OD.productid, OD.qty, OD.unitprice, OD.discount
FROM dbo.Orders AS O
INNER JOIN dbo.OrderDetails AS OD
ON O.orderid = OD.orderid;
GOTry to insert a row through the view, so both underlying base tables would be affected:
INSERT INTO dbo.OrdersOrderDetails(orderid, orderdate, shippeddate, productid, qty, unitprice, discount)
VALUES(6, '20210828', NULL, 1001, 5, 10.50, 0.05);You get the following error:
View or function 'dbo.OrdersOrderDetails' is not updatable because the modification affects multiple base tables.
Try to insert a row through the view, so only the Orders table would be affected:
INSERT INTO dbo.OrdersOrderDetails(orderid, orderdate, shippeddate)
VALUES(6, '20210828', NULL);This command completes successfully, and the row is inserted into the underlying Orders table.
But what if you also want to be able to insert a row trough the view into the OrderDetails table? With the current view definition, this is impossible (instead of triggers aside) since the view returns the orderid column from the Orders table and not from the OrderDetails table. Suffice that one column from the OrderDetails table that can’t somehow get its value automatically isn’t part of the view to prevent insertions into OrderDetails through the view. Of course, you can always decide the view will include both orderid from Orders and orderid from OrderDetails. In such a case, you’ll have to assign the two columns with different aliases since the heading of the table represented by the view has to have unique column names.
Use the following code to alter the view definition to include both columns, aliasing the one from Orders as O_orderid and the one from OrderDetails as OD_orderid:
CREATE OR ALTER VIEW dbo.OrdersOrderDetails
AS
SELECT
O.orderid AS O_orderid, O.orderdate, O.shippeddate,
OD.orderid AS OD_orderid,OD.productid, OD.qty, OD.unitprice, OD.discount
FROM dbo.Orders AS O
INNER JOIN dbo.OrderDetails AS OD
ON O.orderid = OD.orderid;
GONow you can insert rows through the view either to Orders or to OrderDetails, depending on which table the target column list is coming from. Here’s an example for inserting a couple of order lines associated with order 6 through the view into OrderDetails:
INSERT INTO dbo.OrdersOrderDetails(OD_orderid, productid, qty, unitprice, discount)
VALUES(6, 1001, 5, 10.50, 0.05),
(6, 1002, 5, 20.00, 0.05);The rows are added successfully.
Query the view:
SELECT * FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;You get the following output:
O_orderid orderdate shippeddate OD_orderid productid qty unitprice discount ----------- ---------- ----------- ----------- ----------- ---- ---------- --------- 6 2021-08-28 NULL 6 1001 5 10.50 0.0500 6 2021-08-28 NULL 6 1002 5 20.00 0.0500
A similar restriction is applicable to UPDATE statements through the view. Updates are allowed as long as only one underlying base table is affected. But you’re allowed to reference columns from both sides in the statement as long as only one side gets modified.
As an example, the following UPDATE statement through the view sets the order date of the row where the order line’s order ID is 6 and the product ID is 1001 to “20210901:”
UPDATE dbo.OrdersOrderDetails
SET orderdate = '20210901'
WHERE OD_orderid = 6 AND productid = 1001;We’ll call this statement Update statement 1.
The update completes successfully with the following message:
(1 row affected)
What’s important to note here is the statement filters by elements from the OrderDetails table, yet the modified column orderdate is from the Orders table. So, in the plan SQL Server builds for this statement, it has to figure out which orders need to be modified in the Orders table. The plan for this statement is shown in Figure 1.
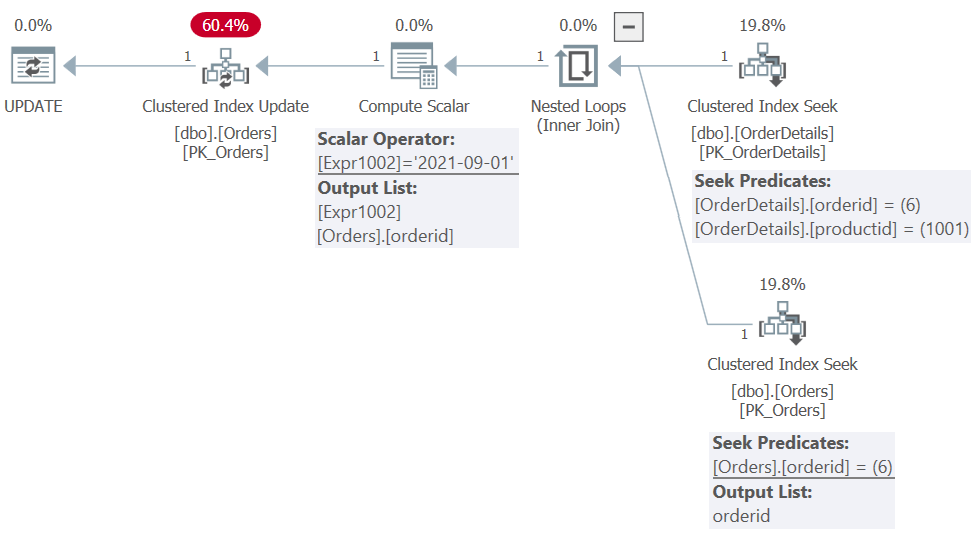 Figure 1: Plan for Update statement 1
Figure 1: Plan for Update statement 1
You can see how the plan starts by filtering the OrderDetails side by both orderid = 6 and productid = 1001, and the Orders side by orderid = 6, joining the two. The outcome is only one row. The only relevant part to keep from this activity is which order IDs in the Orders table represent rows that need to be updated. In our case, it’s the order with order ID 6. In addition, the Compute Scalar operator prepares a member called Expr1002 with the value the statement will assign to the orderdate column of the target order. The last part of the plan with the Clustered Index Update operator applies the actual update to the row in Orders with order ID 6, setting its orderdate value to Expr1002.
The key point to emphasize here is only one row with orderid 6 in the Orders table got updated. Yet this row has two matches in the result of the join with the OrderDetails table—one with product ID 1001 (which the original update filtered) and another with product ID 1002 (which the original update didn’t filter). Query the view at this point, filtering all rows with order ID 6:
SELECT * FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;You get the following output:
O_orderid orderdate shippeddate OD_orderid productid qty unitprice discount ----------- ---------- ----------- ----------- ----------- ---- ---------- --------- 6 2021-09-01 NULL 6 1001 5 10.50 0.0500 6 2021-09-01 NULL 6 1002 5 20.00 0.0500
Both rows show the new order date, even though the original update filtered only the row with product ID 1001. Yet again, this should seem perfectly sensible if you know you’re interacting with a view that joins two base tables beneath the covers, but could seem very strange if you don’t realize this.
Curiously, SQL Server even supports nondeterministic updates where multiple source rows (from OrderDetails in our case) match a single target row (in Orders in our case). Theoretically, one way to handle such a case would be to reject it. Indeed, with a MERGE statement where multiple source rows match one target row, SQL Server rejects the attempt. But not with an UPDATE based on a join, whether directly or indirectly through a named table expression like a view. SQL Server simply handles it as a nondeterministic update.
Consider the following example, which we’ll refer to as Statement 2:
UPDATE dbo.OrdersOrderDetails
SET orderdate = CASE
WHEN unitprice >= 20.00 THEN '20210902'
ELSE '20210903'
END
WHERE OD_orderid = 6;Hopefully you’ll forgive me that it’s a contrived example, but it illustrates the point.
There are two qualifying rows in the view, representing two qualifying source order line rows from the underlying OrderDetails table. But there’s only one qualifying target row in the underlying Orders table. Moreover, in one source OrderDetails row, the assigned CASE expression returns one value ('20210902') and in the other source OrderDetails row it returns another value ('20210903'). What should SQL Server do in this case? As mentioned, a similar situation with the MERGE statement would result in an error, rejecting the attempted change. Yet with an UPDATE statement, SQL Server simply flips a coin. Technically, this is done using an internal aggregate function called ANY.
So, our update completes successfully, reporting 1 row affected. The plan for this statement is shown in Figure 2.
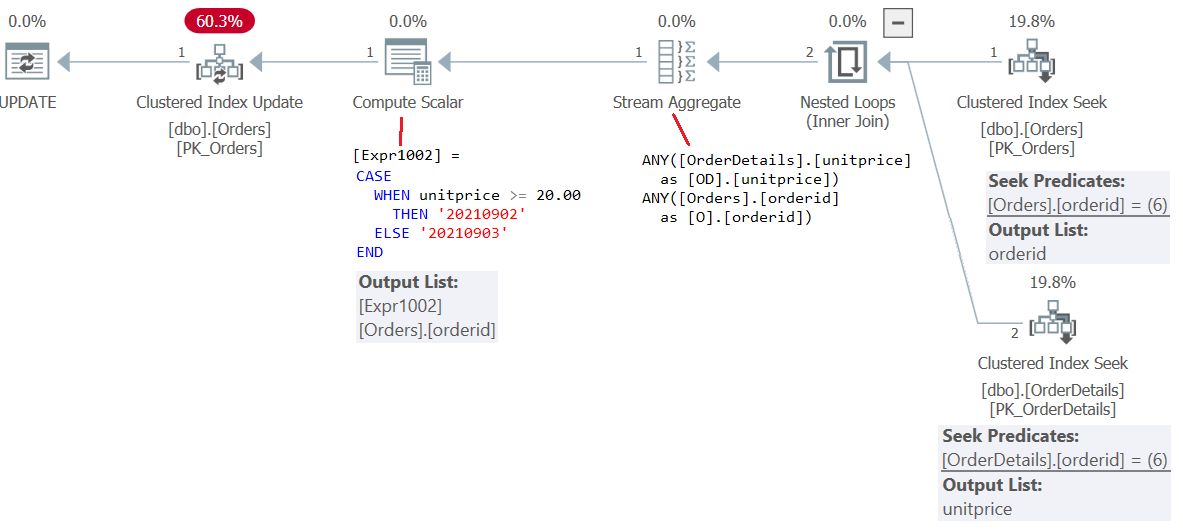
Figure 2: Plan for Update statement 2
There are two rows in the result of the join. These two rows become the source rows for the update. But then an aggregate operator applying the ANY function picks one (any) orderid value and one (any) unitprice value from these source rows. Both source rows have the same orderid value, so the right order will be modified. But depending on which of the source unitprice values the ANY aggregate ends up choosing, this will determine which value the CASE expression will return, to then be used as the updated orderdate value in the target order. You can certainly see an argument against supporting such an update, but it’s fully supported in SQL Server.
Let’s query the view to see the result of this change (now is the time to make your bet as for the outcome):
SELECT * FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;I got the following output:
O_orderid orderdate shippeddate OD_orderid productid qty unitprice discount ----------- ---------- ----------- ----------- ----------- ---- ---------- --------- 6 2021-09-03 NULL 6 1001 5 10.50 0.0500 6 2021-09-03 NULL 6 1002 5 20.00 0.0500
Only one of the two source unitprice values was picked and used to determine the orderdate of the single target order, yet when querying the view, the orderdate value is repeated for both matching order lines. As you can realize, the outcome could have just as well been the other date (2021-09-02) since the choice of the unitprice value was nondeterministic. Wacky stuff!
So, under certain conditions, INSERT and UPDATE statements are allowed through views that join multiple underlying tables. Deletes, however, are not allowed against such views. How can SQL Server tell which of the sides is supposed to be the target for the delete?
Here’s an attempt to apply such a delete through the view:
DELETE FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;This attempt is rejected with the following error:
View or function 'dbo.OrdersOrderDetails' is not updatable because the modification affects multiple base tables.
At this point, run the following code for cleanup:
DELETE FROM dbo.OrderDetails WHERE orderid = 6;
DELETE FROM dbo.Orders WHERE orderid = 6;
DROP VIEW IF EXISTS dbo.OrdersOrderDetails;Derived Columns
Another restriction to modifications through views has to do with derived columns. If a view column is a result of a computation, SQL Server won’t try to reverse engineer its formula when you attempt to insert or update data through the view—rather, it will reject such modifications.
Consider the following view as an example:
CREATE OR ALTER VIEW dbo.OrderDetailsNetPrice
AS
SELECT orderid, productid, qty, unitprice * (1.0 - discount) AS netunitprice, discount
FROM dbo.OrderDetails;
GOThe view computes the netunitprice column based on the underlying OrderDetails table columns unitprice and discount.
Query the view:
SELECT * FROM dbo.OrderDetailsNetPrice;You get the following output:
orderid productid qty netunitprice discount ----------- ----------- ----------- ------------- --------- 1 1001 5 9.975000 0.0500 1 1004 2 20.000000 0.0000 2 1003 1 47.691000 0.1000 3 1001 1 9.975000 0.0500 3 1003 2 49.491000 0.1000 4 1001 2 9.975000 0.0500 4 1004 1 20.300000 0.0000 4 1005 1 28.595000 0.0500 5 1003 5 54.990000 0.0000 5 1006 2 11.316000 0.0800
Try to insert a row through the view:
INSERT INTO dbo.OrderDetailsNetPrice(orderid, productid, qty, netunitprice, discount)
VALUES(1, 1005, 1, 28.595, 0.05);Theoretically, you can figure out what row needs to be inserted into the underlying OrderDetails table by reverse engineering the base table’s unitprice value from the view’s netunitprice and discount values. SQL Server doesn’t attempt such reverse engineering, but rejects the attempted insertion with the following error:
Update or insert of view or function 'dbo.OrderDetailsNetPrice' failed because it contains a derived or constant field.
Try to omit the computed column from the insertion:
INSERT INTO dbo.OrderDetailsNetPrice(orderid, productid, qty, discount)
VALUES(1, 1005, 1, 0.05);Now we’re back to the requirement that all columns from the underlying table that don't somehow get their values automatically have to be part of the insertion, and here we’re missing the unitprice column. This insertion fails with the following error:
Cannot insert the value NULL into column 'unitprice', table 'tempdb.dbo.OrderDetails'; column does not allow nulls. INSERT fails.
If you want to support insertions through the view, you basically have two options. One is to include the unitprice column in the view definition. Another is to create an instead of trigger on the view where you handle the reverse engineering logic yourself.
At this point, run the following code for cleanup:
DROP VIEW IF EXISTS dbo.OrderDetailsNetPrice;Set Operators
As mentioned in the last section, you’re not allowed to modify a column in a view if the column is a result of a computation. The columns modified in the view using INSERT and UPDATE statements have to map directly to the underlying base table’s columns with no manipulation. In the list of restrictions to modifications through views, T-SQL’s documentation specifies that columns formed by using the set operators UNION, UNION ALL, EXCEPT, and INTERSECT amount to a computation and therefore are also not updatable.
One exception to this restriction is when using the UNION ALL operator to combine rows from different tables to form an updatable partitioned view. That’s a big topic in its own right. I’ll cover it briefly here to give you a sense, and you can investigate it further if you like in the product’s documentation.
Partitioned views predates table and index partitioning in SQL Server. The basic idea is that you can store disjoint subsets of rows in different base tables and have a view that unifies the rows from the different tables using a UNION ALL operator. If certain requirements are met, you can not only read the data through the view but also modify it through the view. SQL Server will figure out how to direct the modifications through the view to the right underlying tables.
The requirements for supporting modifications through such a view include having a partitioning column. Each of the underlying tables needs to have a CHECK constraint based on the partitioning column that defines a disjoint subset of rows. Also, the partitioning column needs to be part of the table’s primary key, meaning it cannot allow NULLs.
Consider the Orders table you used earlier in this article. Suppose that instead of holding all orders in one table, you want to store unshipped orders in one table (called UnshippedOrders) and shipped orders in another table (called ShippedOrders). You also want to create a view called Orders combining the rows from both tables. You want the view to be updatable.
Let’s start by removing any existing objects before creating the new ones:
DROP VIEW IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.OrderDetails, dbo.Orders;
DROP TABLE IF EXISTS dbo.ShippedOrders, dbo.UnshippedOrders;The partitioning column in our example is the shippeddate column. Our first obstacle is that we want to represent unshipped orders with a NULL shippeddate, but the partitioning column cannot allow NULLs. One possible workaround is to decide on some specific future date to represent unshipped orders. For example, the maximum supported date December 31st, 9999. Then you could have a CHECK constraint in the UnshippedOrders table checking that the shipped date is this specific one, and a CHECK constraint in the ShippedOrders table checking that the shipped date is before this one. This will meet the requirement for disjoint sets of rows.
Another obstacle is that the partitioning column needs to be part of the primary key. Originally the primary key was based on the orderid column alone. Now it will need to be extended to be based on (orderid, shippeddate). You will probably still want to enforce uniqueness based on orderid alone. To achieve this, you’ll need to add a unique constraint based on orderid.
With all this in mind, here are the definitions of the ShippedOrders and UnshippedOrders tables:
CREATE TABLE dbo.ShippedOrders
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
shippeddate DATE NOT NULL,
CONSTRAINT PK_ShippedOrders PRIMARY KEY(orderid, shippeddate),
CONSTRAINT UNQ_ShippedOrders_orderid UNIQUE(orderid),
CONSTRAINT CHK_ShippedOrders_shippeddate CHECK(shippeddate < '99991231')
);
CREATE TABLE dbo.UnshippedOrders
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
shippeddate DATE NOT NULL DEFAULT('99991231'),
CONSTRAINT PK_UnshippedOrders PRIMARY KEY(orderid, shippeddate),
CONSTRAINT UNQ_UnshippedOrders_orderid UNIQUE(orderid),
CONSTRAINT CHK_UnshippedOrders_shippeddate CHECK(shippeddate = '99991231')
);You then create the Orders view, unifying the rows from the two tables using the UNION ALL operator, like so:
CREATE OR ALTER VIEW dbo.Orders
AS
SELECT orderid, orderdate, shippeddate
FROM dbo.ShippedOrders
UNION ALL
SELECT orderid, orderdate, shippeddate
FROM dbo.UnshippedOrders;
GOSince this view meets all requirements for updatability, you can insert, update, and delete rows through the view. SQL Server will direct the changes to the right underlying tables. As an example, the following statement inserts a few rows, including both shipped and unshipped orders:
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate)
VALUES(1, '20210802', '20210804'),
(2, '20210802', '20210805'),
(3, '20210804', '20210806'),
(4, '20210826', '99991231'),
(5, '20210827', '99991231');The plan for this code is shown in Figure 3.
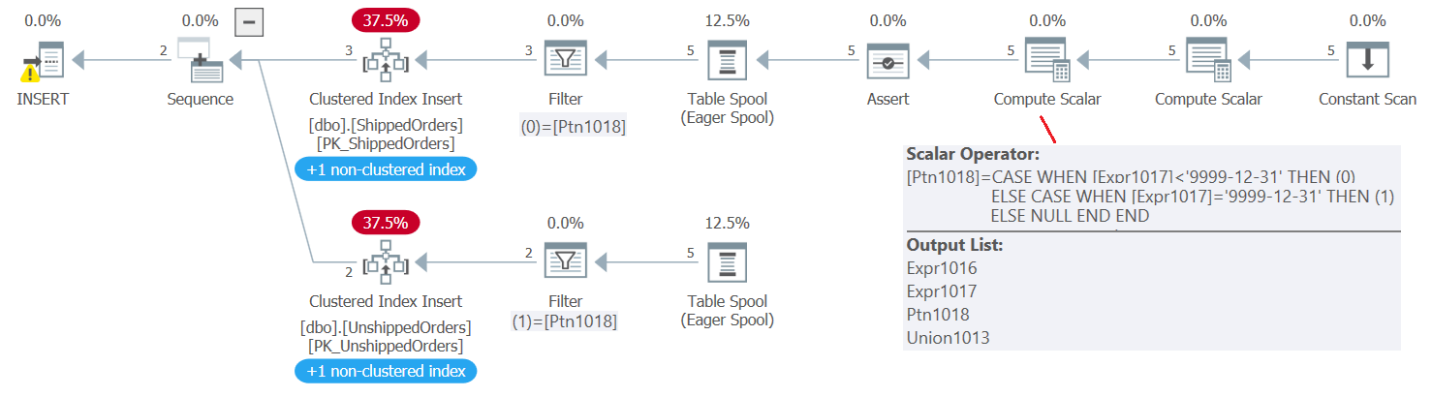 Figure 3: Plan for INSERT statement against partitioned view
Figure 3: Plan for INSERT statement against partitioned view
As you can see, a Compute Scalar operator computes for each source row a member called Ptn1018. This member is set to 0 for shipped orders (shippeddate < '9999-12-31') and 1 for unshipped orders (shippeddate = '9999-12-31'). The rows are spooled along with the member Ptn1018, and then the spool is read twice. Once filtering the rows where Ptn1018 = 0, inserting those into the underlying ShippedOrders table, and another time filtering the rows where Ptn1018 = 1, inserting those into the underlying UnshippedOrders table. If this seems like an attractive option, consider it very carefully. Remember this is an old feature, predating table and index partitioning. There are many requirements, restrictions, and complications, including optimization complications, integrity enforcement complications, and others. As mentioned, here I just wanted to cover it briefly to describe the exception to the modification restriction involving set operators. When you’re done, run the following code for cleanup:
DROP VIEW IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.OrderDetails, dbo.Orders;
DROP TABLE IF EXISTS dbo.ShippedOrders, dbo.UnshippedOrders;Summary
When I started the coverage of views, one of the first things I explained was that a view is a table. You can read data from a view and you can modify data through a view. But you need to understand that modifications through the view are restricted in a few ways, and the outcome of such modifications could be surprising in some cases.
Using the CHECK OPTION, you’re only allowed to update and insert rows through the view as long as the result rows are considered a valid part of the view. This means unlike a CHECK constraint in a table, the CHECK OPTION rejects changes where the inner query’s filter evaluates to unknown (when a NULL is involved). You’re not allowed to insert or update rows through a view if it’s defined with the CHECK OPTION and uses the TOP or OFFSET-FETCH filters. But you’re allowed to delete rows through such a view.
If a view joins multiple base tables, inserts and updates through the view are allowed provided that only one underlying base table is affected. Oddly, if a modification of a single target row involves multiple related source rows, the modification is allowed but is processed as a nondeterministic one. In such a case, SQL Server uses the internal ANY aggregate the pick a single value from the source rows.
You cannot update or insert rows through a view where at least one of the updated columns is a derived one resulting from a computation. The same applies when using a set operator, with an exception when using the UNION ALL operator to create an updatable partitioned view.
