
What to do (or not do) about top wait stats
One of the most common terms to come up in discussions about SQL Server performance tuning is wait stats. This goes back a long way, even before this 2006 Microsoft document, "SQL Server 2005 Waits and Queues."
Waits are absolutely not everything, and this methodology is not the only way to tune an instance, never mind an individual query. In fact, waits are often useless when all you have is the query that suffered them, and no surrounding context, especially long after the fact. This is because, quite often, the thing a query is waiting on is not that query's fault. Like anything, there are exceptions, but if you're picking a tool or script only because it offers this very specific functionality, I think you are doing yourself a disservice. I tend to follow a piece of advice Paul Randal gave me some time ago:
Occasionally, yes, you might want to dig deeper into an individual query and see what it is waiting on; in fact Microsoft recently added query-level wait stats to showplan to help with this analysis. But these numbers are typically not going to help you tune the performance of your instance as a whole, unless they are helping point out something that happens to also be affecting your entire workload. If you see one query from yesterday that ran for 5 minutes, and notice that its wait type was LCK_M_S, what are you going to do about it now? How are you going to track down what was actually blocking the query and causing that wait type? It might have been caused by a transaction that wasn't committing for some other reason, but you can't see that if you can't see the state of the entire system and are focusing just on individual queries and the waits they experienced.
Jason Hall (@SQLSaurus) mentioned something in passing that was interesting to me as well. He said that if query-level wait stats were such an important part of tuning efforts, that this methodology would have been baked into Query Store from the start. It has been added recently (in SQL Server 2017). But you still don't get per-execution wait stats; you get averages over time, like the query stats and procedure stats you see in DMVs. So sudden anomalies might be apparent based on other metrics that are captured per query execution, but not based on averages of wait times that are drawn over all executions. You can customize the range waits are aggregated over, but on busy systems this still might not be granular enough to do what you think it's going to do for you.
The point of this post is to discuss some of the more common wait types we see out in our customer base, and what kind of actions you can (and shouldn't) take when they happen. We have a database of anonymous wait stats that we've been collecting from our Cloud Sync customers for quite some time, and since May of 2017 we've been showing everyone how these look over on the SQLskills Waits Library.
Paul talks about the reason behind the library and also about our integration with this free service. Basically, you look up a wait type you're experiencing or curious about, and he explains what it means and what you can do about it. We supplement this qualitative info with a chart showing how prevalent the current wait is among our user base, comparing that to all the other wait types we see, so you can quickly tell if you are dealing with a common wait type or something a little more exotic. (Keep in mind SQL Sentry doesn't include the benign, background, and queue waits that amount to noise and that most of the scripts out there filter out, like WAITFOR or LAZYWRITER_SLEEP – these are just not sources of performance issues.)
Here's an example chart for CXPACKET, the most common wait type out there:
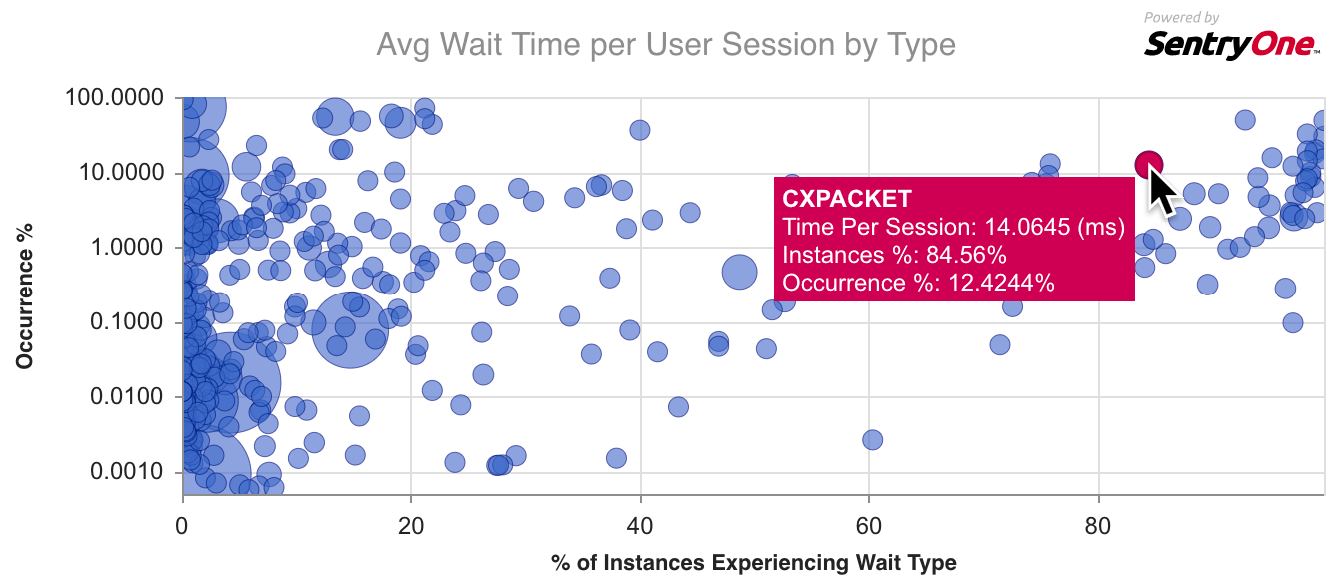
I started going a little further than this, mapping out some of the more common wait types, and noting some of the properties they shared. Translated into questions a tuner might have about a wait type they are experiencing:
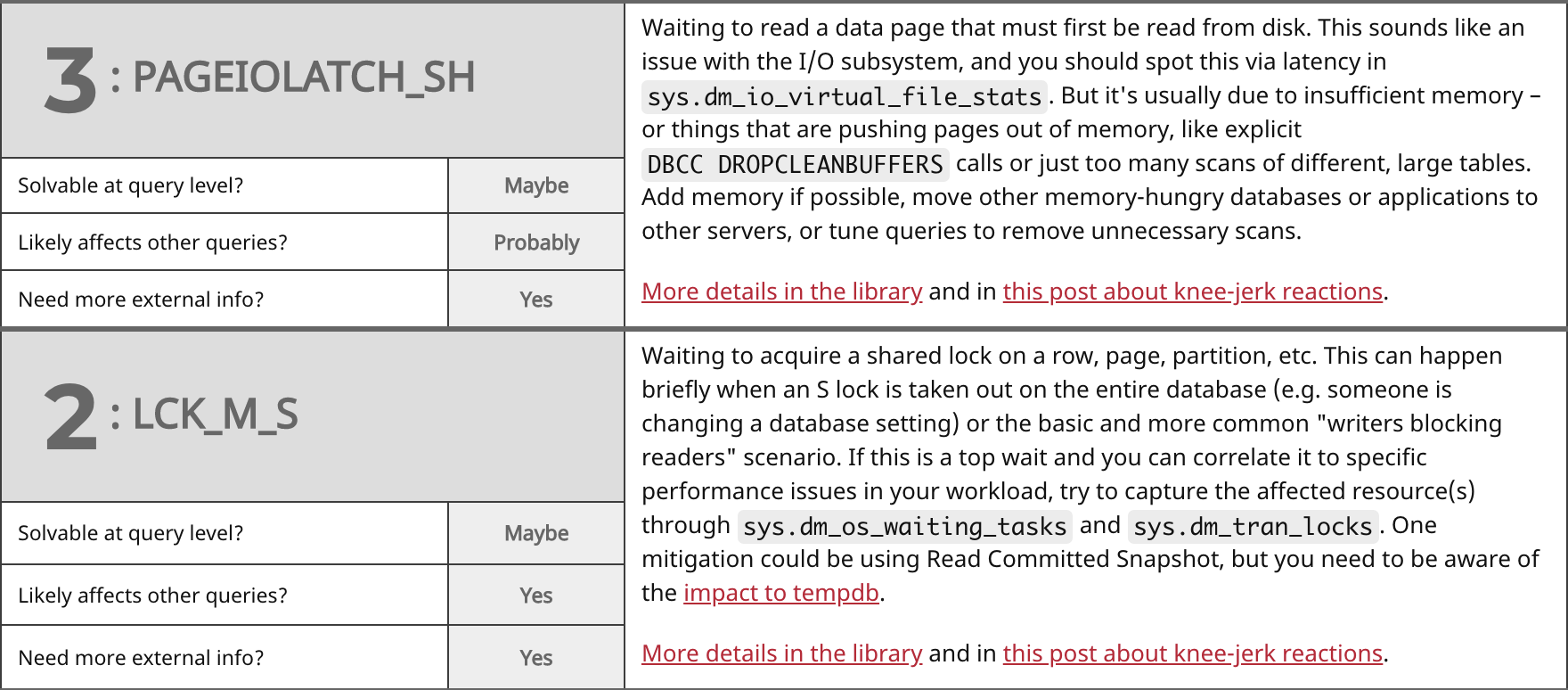
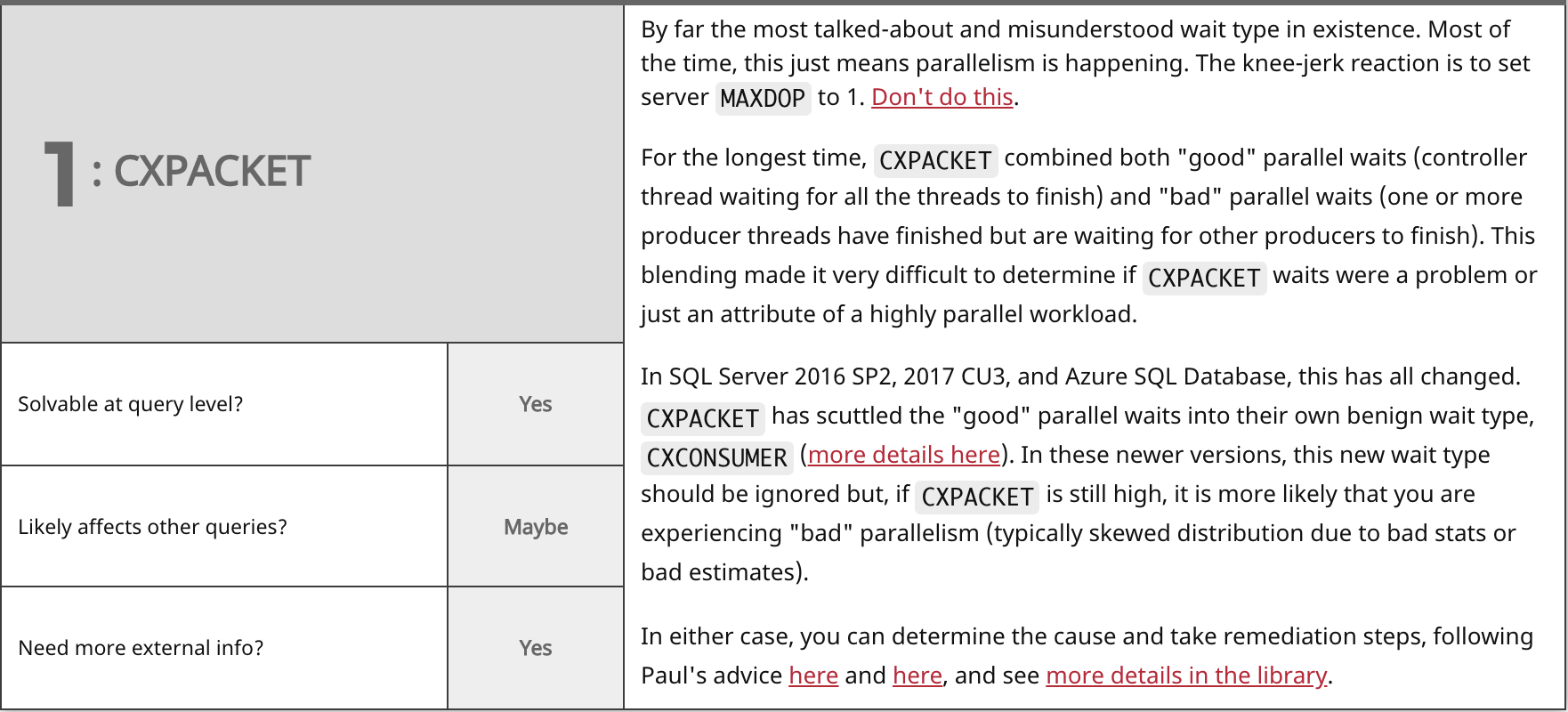
- Can the wait type be solved at the query level?
- Is the core symptom of the wait likely to be affecting other queries?
- Is it likely you will need more information outside the context of a single query and the wait types it experienced in order to "solve" the problem?
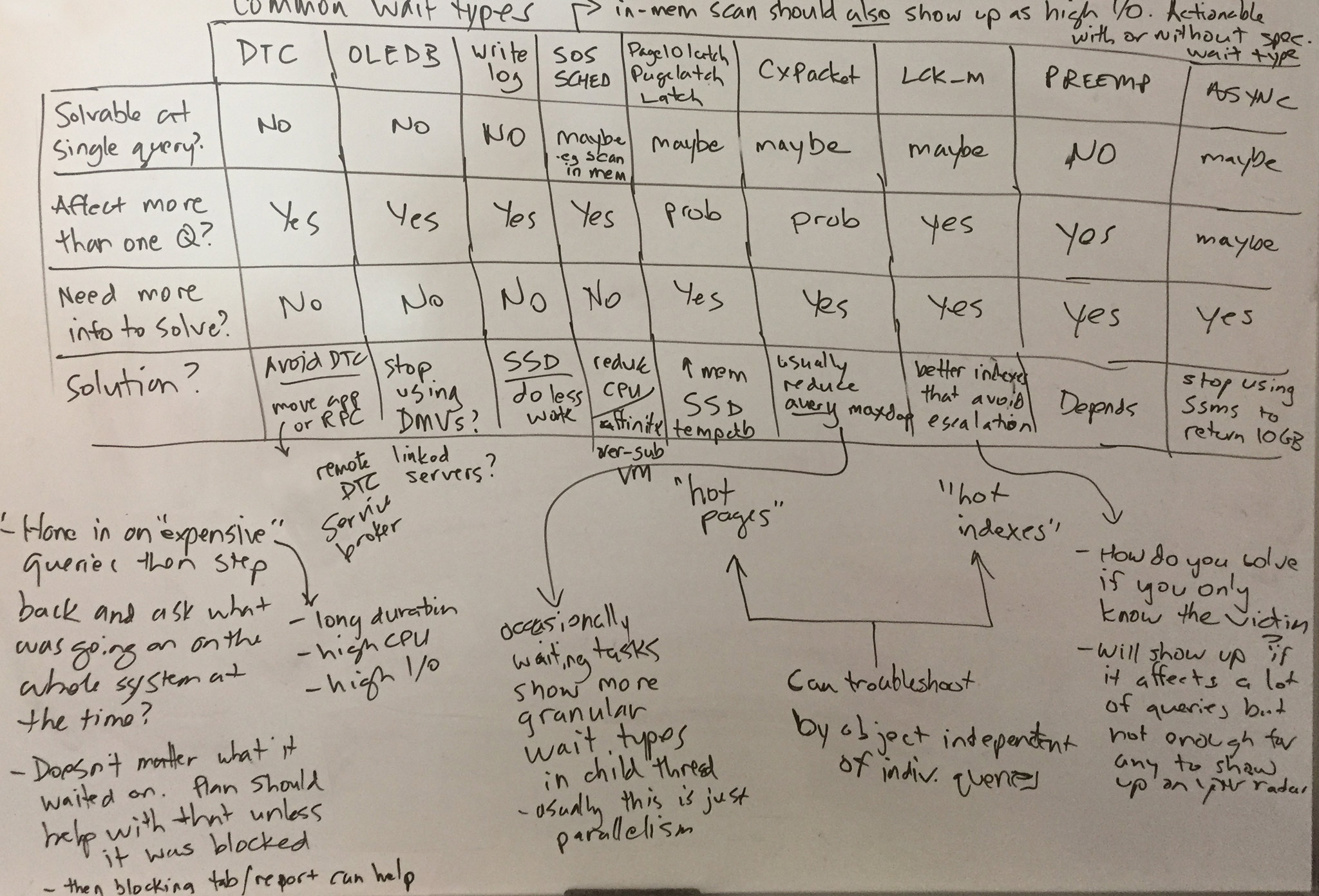
When I set out to write this post, my goal was just to group the most common wait types together, and then start jotting notes about them relating to the above questions. Jason pulled the most common ones from the library, and then I drew some chicken scratch on a whiteboard, which I later tidied up a bit. This initial research led to a talk that Jason gave on the most recent TechOutbound SQL Cruise in Alaska. I'm kind of embarrassed that he put a talk together months before I could finish this post, so let's just get on with it. Here are the top waits we see (which largely match Paul's survey from 2014), my answers to the above questions, and some commentary on each:
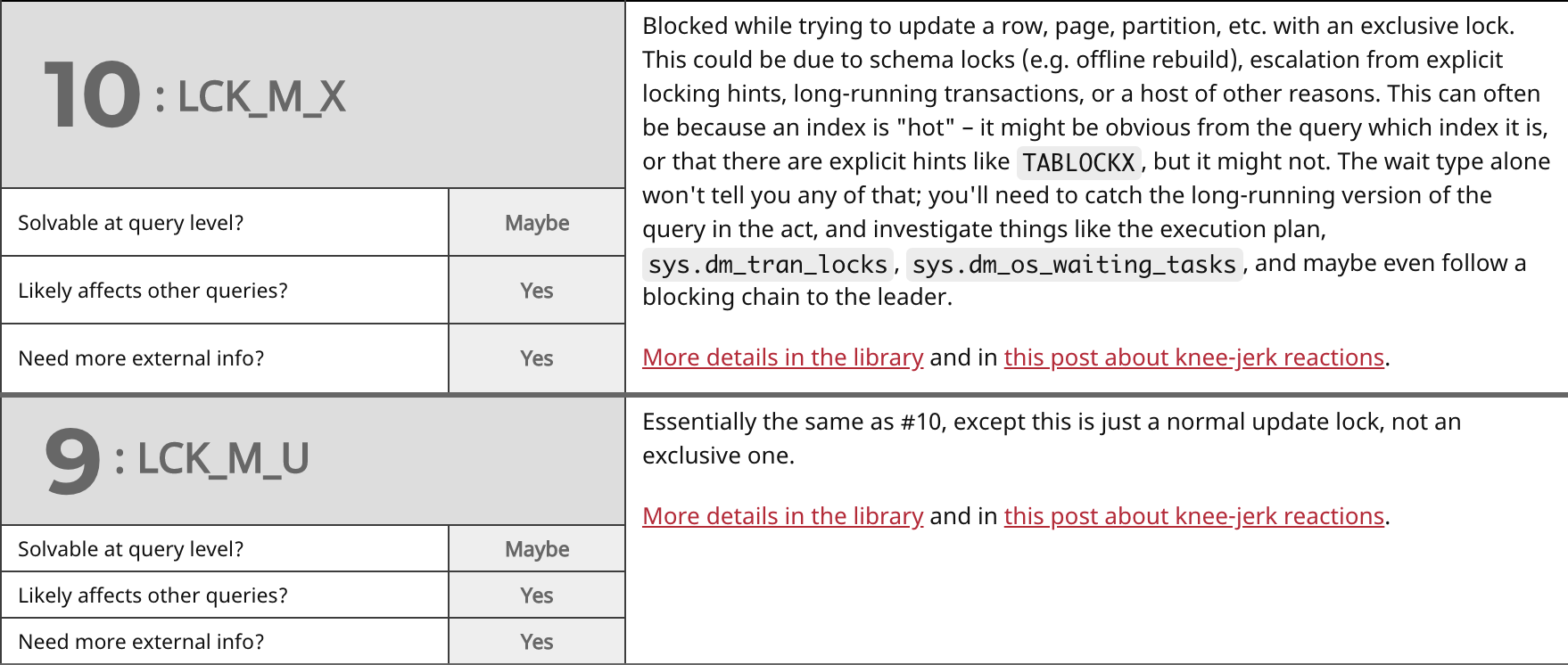
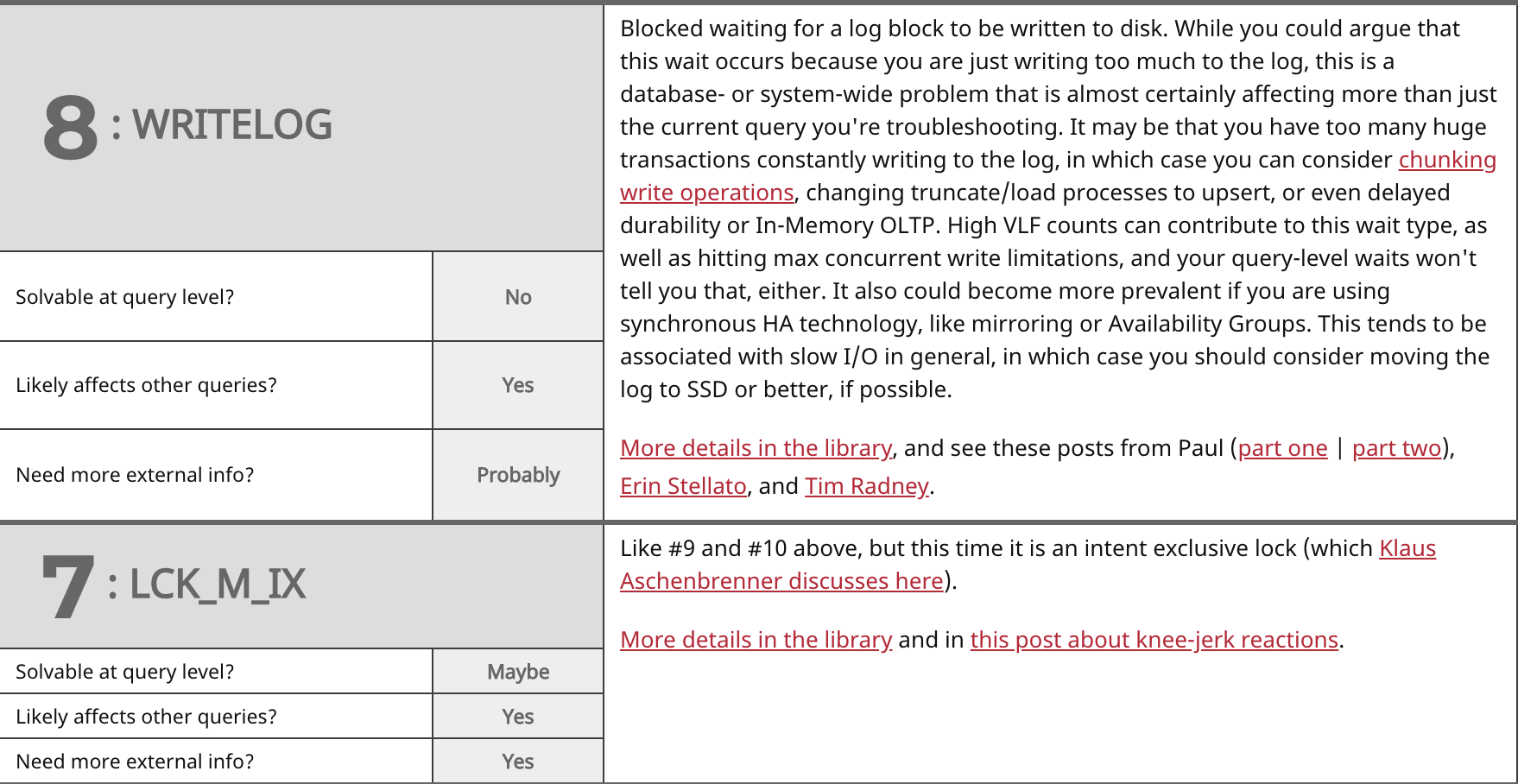
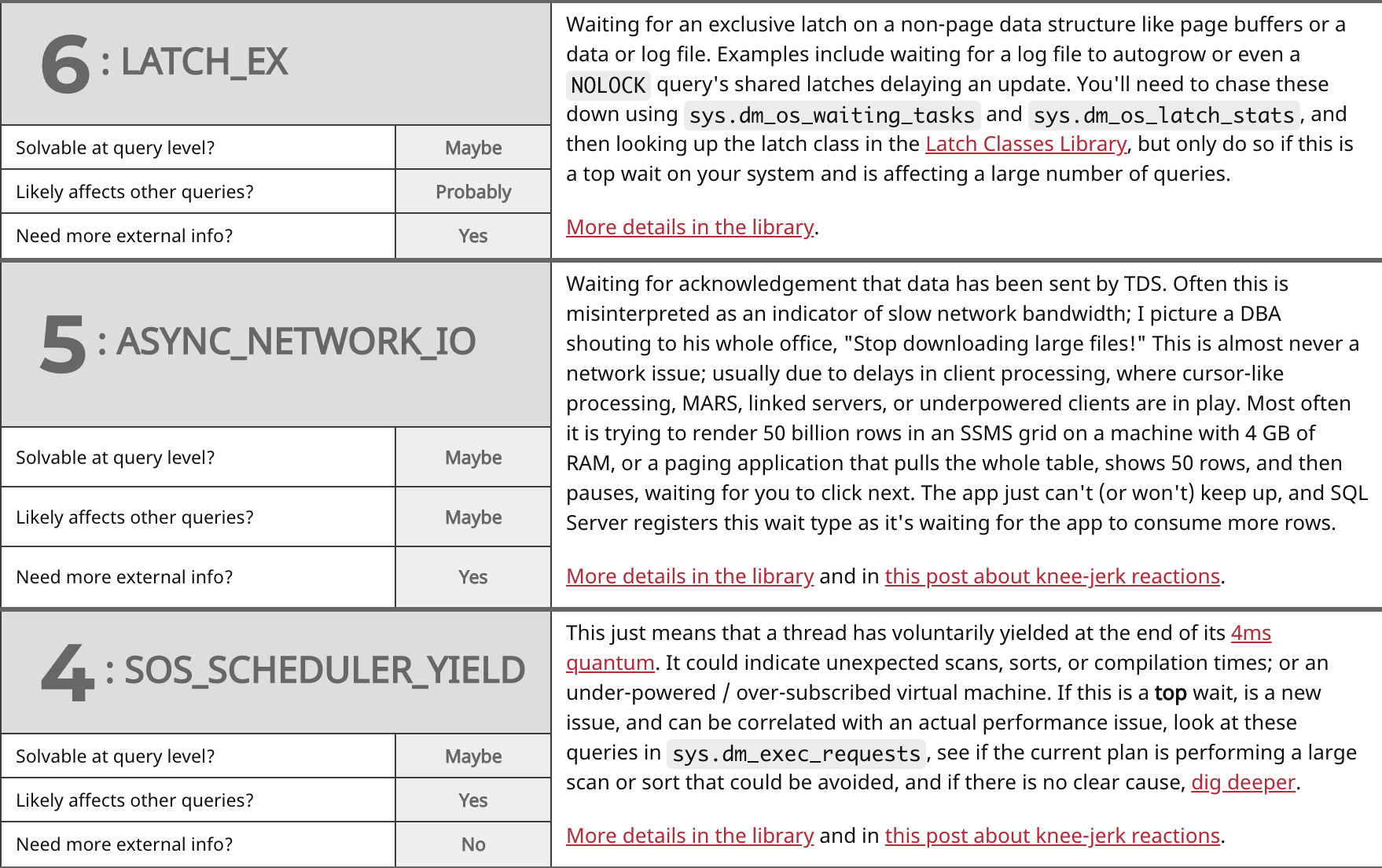
Summary
In most of these cases, it is better to look at waits at the instance level, and only hone in on query-level waits when you are troubleshooting specific queries that exhibit performance problems regardless of wait type. These are things that surface for other reasons, like long duration, high CPU, or high I/O, and can't be explained by simpler things (like a clustered index scan when you were expecting a seek).
Even at the instance level, don't chase down every wait that becomes the top wait on your system – you'll ALWAYS have a top wait, and you'll never be able to stop chasing it down. Make sure you ignore benign waits (Paul keeps a list) and only worry about waits that you can associate with an actual performance problem you are experiencing. If CXPACKET waits are high, so what? Are there any other symptoms aside from that number being "high" or happening to be at the top of the list?
It all comes down to why you're troubleshooting in the first place. Is a single user complaining about a single instance of a rogue query? Is your server on its knees? Something in between? In the first case, sure, knowing why a query is slow can be useful, but it's quite expensive to track (never mind keep indefinitely) all of the waits associated with every single query, all day, every day, on the odd chance you want to come back and review them later. If it's a pervasive problem isolated to that query, you should be able to determine what's making that query slow by running it again and collecting the execution plan, compilation time, and other runtime metrics. If it was a one-time thing that happened last Tuesday, whether you have the waits for that single instance of the query or not, you may not be able to sort out the problem without more context. Maybe there was blocking, but you won't know by what, or maybe there was an I/O spike, but you'll have to go track down that issue separately. The wait type on its own usually just doesn't provide enough information except, at best, a pointer to something else.
Of course, I need to earn my keep, here, too. Our flagship product, SQL Sentry, takes a holistic approach to monitoring. We collect instance-wide wait stats, categorize them for you, and graph them on our dashboard:
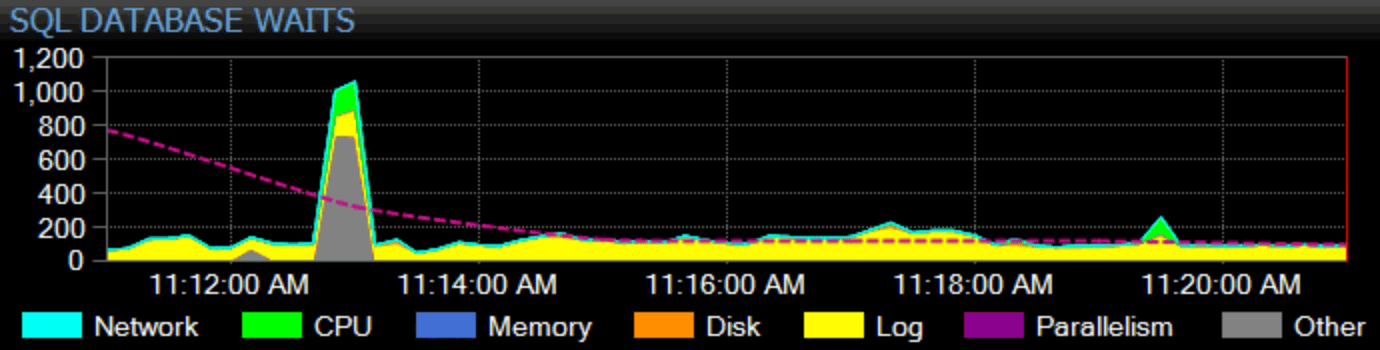
You can customize how any individual wait is categorized and whether or not that category even shows up on the dashboard. You can compare the current wait stats with built-in or custom baselines, and even set up alerts or actions when they exceed some defined deviation from the baseline. And, perhaps most importantly, you can look at a data point from the past, and sync the entire dashboard to that point in time, so you can capture all of the surrounding context and any other situation that may have influenced the issue. When you find more granular things to focus on, like blocking, high disk latency, or queries with high I/O or long duration, you can drill into those metrics and get to the root of the problem rather quickly.
For more info on both general wait stats approaches and our solution specifically, you can look at Kevin Kline's white paper, Troubleshooting SQL Server Wait Stats, and you can download a two-part webinar presented by Paul Randal, Andy Yun (@SQLBek), and Andy Mallon (@AMtwo):
- Part 1 : Performance Troubleshooting Using Wait Statistics
- Part 2 : Rapid Analysis of Wait Statistics with SentryOne
And if you want to give the SentryOne Platform a spin, you can get started here with a limited time offer:
2 thoughts on “What to do (or not do) about top wait stats”
Comments are closed.

{kind=link}
{kind=link}
Great post, Aaron. I’d also argue that writelog needs further info. What is subsystem look like, what is caching, etc.
Yes, admittedly, my whiteboard scrawlings were not 100% accurate. :-)