
Break large delete operations into chunks

Far too often I see folks complaining about how their transaction log took over their hard disk. Many times it turns out that they were performing a large delete operation, such as purging or archiving data, in one large transaction.
I wanted to run some tests to show the impact, on both duration and the transaction log, of performing the same data operation in chunks versus a single transaction. I created a database and populated it with a largish table SalesOrderDetailEnlarged,
After populating the table, I backed up the database, backed up the log, and ran a DBCC SHRINKFILE (don't shoot me) so that the impact on the log file could be established from a baseline (knowing full well that these operations *will* cause the transaction log to grow).
I purposely used a mechanical disk as opposed to an SSD. While we may start seeing a more popular trend of moving to SSD, it hasn't happened yet on a large enough scale; in many cases it's still too cost prohibitive to do so in large storage devices.
The Tests
So next I had to determine what I wanted to test for greatest impact. Since I was involved in a discussion with a co-worker just yesterday about deleting data in chunks, I chose deletes. And since the clustered index on this table is on SalesOrderID, I didn't want to use that – that would be too easy (and would very rarely match the way deletes are handled in real life). So I decided instead to go after a series of ProductID values, which would ensure I would hit a large number of pages and require a lot of logging. I determined which products to delete by the following query:
SELECT TOP (3)
ProductID, ProductCount = COUNT(*)
FROM dbo.SalesOrderDetailEnlarged
GROUP BY ProductID
ORDER BY ProductCount DESC;
This yielded the following results:
ProductID ProductCount
--------- ------------
870 187520
712 135280
873 134160
This would delete 456,960 rows (about 10% of the table), spread across many orders. This isn't a realistic modification in this context, since it will mess with pre-calculated order totals, and you can't really remove a product from an order that has already shipped. But using a database we all know and love, it is analogous to, say, deleting a user from a forum site, and also deleting all of their messages – a real scenario I have seen in the wild.
So one test would be to perform the following, one-shot delete:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
I know this is going to require a massive scan and take a huge toll on the transaction log. That's kind of the point. :-)
While that was running, I put together a different script that will perform this delete in chunks: 25,000, 50,000, 75,000 and 100,000 rows at a time. Each chunk will be committed in its own transaction (so that if you need to stop the script, you can, and all previous chunks will already be committed, instead of having to start over), and depending on the recovery model, will be followed by either a CHECKPOINT or a BACKUP LOG to minimize the ongoing impact on the transaction log. (I will also test without these operations.) It will look something like this (I am not going to bother with error handling and other niceties for this test, but you shouldn't be as cavalier):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Of course, after each test, I would restore the original backup of the database WITH REPLACE, RECOVERY, set the recovery model accordingly, and run the next test.
The Results
The outcome of the first test was not very surprising at all. To perform the delete in a single statement, it took 42 seconds in full, and 43 seconds in simple. In both cases this grew the log to 579 MB.
The next set of tests had a couple of surprises for me. One is that, while these chunking methods did significantly reduce impact to the log file, only a couple of combinations came close in duration, and none were actually faster. Another is that, in general, chunking in full recovery (without performing a log backup between steps) performed better than equivalent operations in simple recovery. Here are the results for duration and log impact:
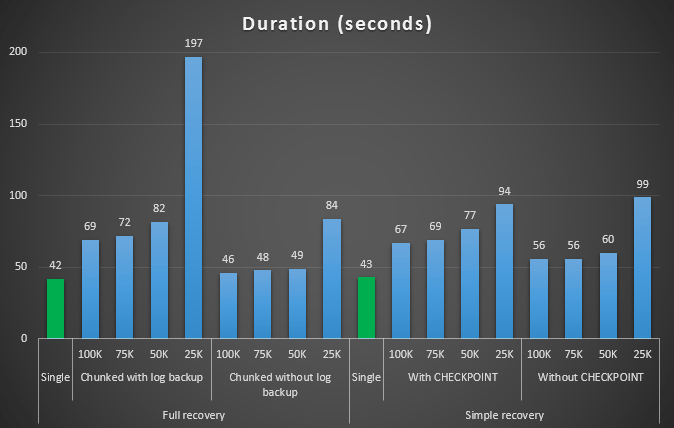
Duration, in seconds, of various delete operations removing 457K rows
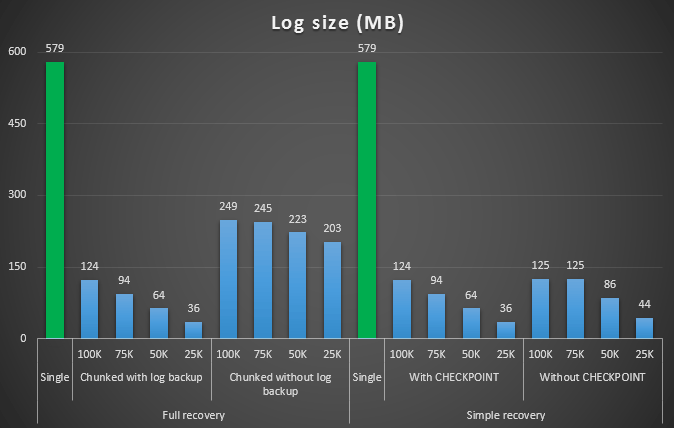
Log size, in MB, after various delete operations removing 457K rows
Again, in general, while log size is significantly reduced, duration is increased. You can use this type of scale to determine whether it's more important to reduce the impact to disk space or to minimize the amount of time spent. For a small hit in duration (and after all, most of these processes are run in the background), you can have a significant savings (up to 94%, in these tests) in log space usage.
Note that I did not try any of these tests with compression enabled (possibly a future test!), and I left the log autogrow settings at the terrible defaults (10%) – partly out of laziness and partly because many environments out there have retained this awful setting.
But what if I have more data?
Next I thought I should test this on a slightly larger database. So I made another database and created a new, larger copy of dbo.SalesOrderDetailEnlarged. Roughly ten times larger, in fact. This time instead of a primary key on SalesOrderID, SalesorderDetailID, I just made it a clustered index (to allow for duplicates), and populated it this way:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID);
Due to disk space limitations, I had to move off of my laptop's VM for this test (and chose a 40-core box, with 128 GB of RAM, that just happened to be sitting around quasi-idle :-)), and still it was not a quick process by any means. Population of the table and creation of the indexes took ~24 minutes.
The table has 48.5 million rows and takes up 7.9 GB in disk (4.9 GB in data, and 2.9 GB in index).
This time, my query to determine a good set of candidate ProductID values to delete:
SELECT TOP (3)
ProductID, ProductCount = COUNT(*)
FROM dbo.SalesOrderDetailReallyReallyEnlarged
GROUP BY ProductID
ORDER BY ProductCount DESC;
Yielded the following results:
ProductID ProductCount
--------- ------------
870 1828320
712 1318980
873 1308060
So we are going to delete 4,455,360 rows, a little under 10% of the table. Following a similar pattern to the above test, we're going to delete all in one shot, then in chunks of 500,000, 250,000 and 100,000 rows.
Results:
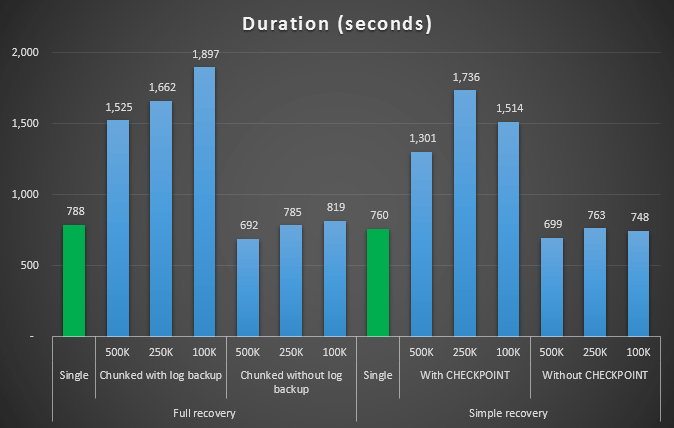 Duration, in seconds, of various delete operations removing 4.5MM rows
Duration, in seconds, of various delete operations removing 4.5MM rows
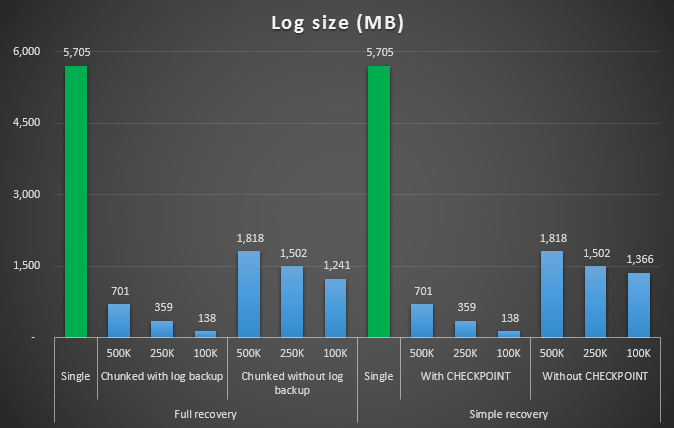 Log size, in MB, after various delete operations removing 4.5MM rows
Log size, in MB, after various delete operations removing 4.5MM rows
So again, we see a significant reduction in log file size (over 97% in cases with the smallest chunk size of 100K); however, at this scale, we see a few cases where we also accomplish the delete in less time, even with all the autogrow events that must have occurred. That sounds an awful lot like win-win to me!
This time with a bigger log
Now, I was curious how these different deletes would compare with a log file pre-sized to accommodate for such large operations. Sticking with our larger database, I pre-expanded the log file to 6 GB, backed it up, then ran the tests again:
ALTER DATABASE delete_test MODIFY FILE
(NAME=delete_test_log, SIZE=6000MB);
Results, comparing duration with a fixed log file to the case where the file had to autogrow continuously:
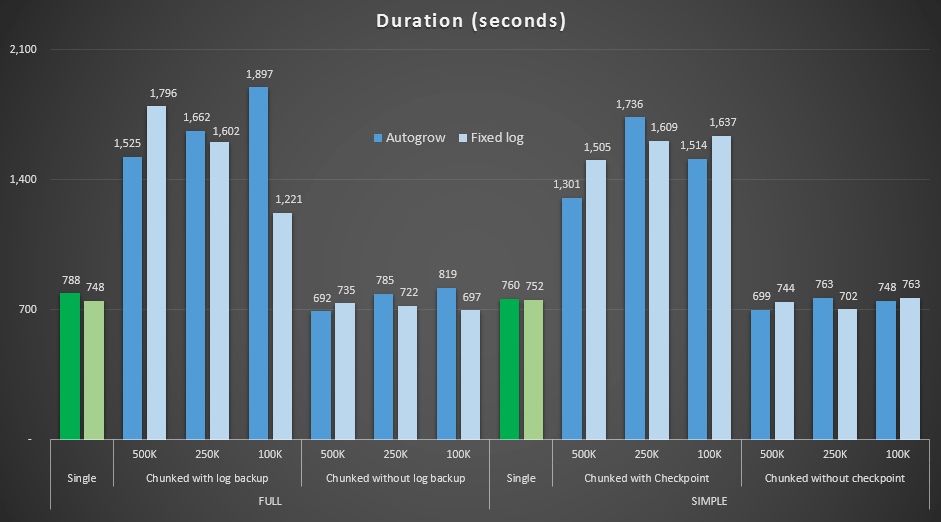
Duration, in seconds, of various delete operations removing 4.5MM rows, comparing fixed log size and autogrow
Again we see that the methods that chunk deletes into batches, and do *not* perform a log backup or a checkpoint after each step, rival the equivalent single operation in terms of duration. In fact, see that most actually perform in less overall time, with the added bonus that other transactions will be able to get in and out between steps. Which is a good thing unless you want this delete operation to block all unrelated transactions.
Conclusion
It is clear that there is no single, correct answer to this problem – there are a lot of inherent "it depends" variables. It may take some experimenting to find your magic number, as there will be a balance between the overhead it takes to backup the log and how much work and time you save at different chunk sizes. But if you are planning to delete or archive a large number of rows, it is quite likely that you will be better off, overall, performing the changes in chunks, rather than in one, massive transaction – even though the duration numbers seem to make that a less attractive operation. It's not all about duration – if you don't have a sufficiently pre-allocated log file, and don't have the space to accommodate such a massive transaction, it is probably much better to minimize log file growth at the cost of duration, in which case you'll want to ignore the duration graphs above and pay attention to the log size graphs.
If you can afford the space, you still may or may not want to pre-size your transaction log accordingly. Depending on the scenario, sometimes using the default autogrow settings ended up slightly faster in my tests than using a fixed log file with plenty of room. Plus, it may be tough to guess exactly how much you'll need to accommodate a large transaction you haven't run yet. If you can't test a realistic scenario, try your best to picture your worst case scenario – then, for safety, double it. Kimberly Tripp (blog | @KimberlyLTripp) has some great advice in this post: 8 Steps to better Transaction Log throughput – in this context, specifically, look at point #6. Regardless of how you decide to calculate your log space requirements, if you're going to end up needing the space anyway, better to take it in a controlled fashion well in advance, than to halt your business processes while they wait for an autogrow (never mind multiple!).
Another very important facet of this that I did not measure explicitly is the impact to concurrency – a bunch of shorter transactions will, in theory, have less impact on concurrent operations. While a single delete took slightly less time than the longer, batched operations, it held all of its locks for that entire duration, while the chunked operations would allow for other queued transactions to sneak in between each transaction. In a future post I'll try to take a closer look on this impact (and I have plans for other deeper analysis as well).
48 thoughts on “Break large delete operations into chunks”
Comments are closed.

Very valuable. I was surprised that in some cases chunking was able to outperform the big deletes as one would naively assume that a single query plan with all modifications nicely sorted per-partition would be most efficient. Maybe this happened because we spilled to disk with one of the sorting tables, or we exhaused some other cache.
An entirely different strategy to do this would be:
select * into NewTable from T where NOT(filter); create index ix on NewTable ...; alter table T switch NewTableSolid gold – thanks for posting.
Just wanted to say thanks for the very detailed info in your post. Saved my bacon!
Great post Aaron, as always :)
Thanks a lot for your explanation ;). It helped me to solve my problem.
All the best,
Albert
Hi there
It is a very interesting article about deleting and give all the info that i need and more than that, but i have question about the difference
between checkpoints and backup log in the mentioned example? I have Oracle background :)
thanks in advanced.
Both clear up log space for reuse (which can prevent the log from having to grow). CHECKPOINT is to be used in simple recovery mode because you can't back up the log there. You need to back up the log when in full recovery mode – even with manual checkpoints SQL Server still can't reuse those portions of the log until they're backed up.
Thanks Aaron
Thanks. helped to solve my problem.
hi Aaron
a very valuable article .
but i have a doubt there , why 'chunks delete' generate less logging ? could you explain that here ? as i googled lots of , nothing reasonable found .
best regards Min Yang
Hi Min, it's not that it generates less logging, it's that it generates less logging at one time. If you delete 1 billion rows, you have to log that entire thing as one single atomic operation. However if you break it up into chucks of 100,000 rows 10,000 times, you only ever have to log 100,000 rows at one time, once you back up the log or checkpoint (depending on recovery model), you can free up the log used for those first 100,000 rows to log another 100,000. This really reduces the stress on the transaction log and should eliminate most, if not all, of the growth required to accommodate your delete action.
Now, in some cases, that might mean the whole operation will take longer, but as I mentioned in the post, there are some other benefits that might outweigh absolute clock time…
In my recent project my task was to clean an entire database by using sql statement and each table having many constraints like Primary Key and Foreign Key. There are more than 1000 tables in database so its not possible to write a delete query on each and ever table.
By using a stored procedure named
which allows us to easily process some code against each and every table in a single database. It means that it is used to process a single T-SQL command or a different T-SQL commands against every table in the database.
So follow the below steps to truncate all tables in a SQL Server Database:-
Refer to http://www.etechpulse.com/2015/07/delete-all-rows-from-all-tables-in-sql.html
This works, but you should be aware of these points:
sp_MSforeachtableseems convenient, but it's undocumented, unsupported, and likely prone to the same problems inherent insp_MSforeachdb(see here and here for background).I would rather do this:
DECLARE @sql NVARCHAR(MAX) = N''; SELECT @sql += N'ALTER TABLE ' + QUOTENAME(s.name) + N'.' + QUOTENAME(t.name) + N' NOCKECK CONSTRAINT ALL;' FROM sys.schemas AS s INNER JOIN sys.tables AS t ON s.[schema_id] = t.[schema_id]; SELECT @sql += N'DELETE ' + QUOTENAME(s.name) + N'.' + QUOTENAME(t.name) + N';' FROM sys.schemas AS s INNER JOIN sys.tables AS t ON s.[schema_id] = t.[schema_id]; SELECT @sql += N'ALTER TABLE ' + QUOTENAME(s.name) + N'.' + QUOTENAME(t.name) + N' CHECK CONSTRAINT ALL;' FROM sys.schemas AS s INNER JOIN sys.tables AS t ON s.[schema_id] = t.[schema_id]; PRINT @sql; -- this may be too long to properly debug through PRINT -- EXEC sys.sp_executesql @sql;Hi Aaron, thanks for your post on this subject.
I have just finished writing a stored procedure to purge data from a number of tables.
I am using a similar technic with TOP (X) but with a CTE to sort by the Primary Key. I would think that there could be an advantage in deleting in this manner but I am not sure if SQL Server is smart enough not to re-gig it's index structures when you are not deleting/updating randomly as oppose to deleting in the same order that the data was created in the first place.
Do you have any insight on weather there is less IO when deleting data this way?
Regards, Ignacio
Hi Ignacio, I purposely used TOP without ORDER BY not only because dictating order would require more cumbersome code (like the CTE you mention), but also to allow SQL Server to determine the most efficient way to delete TOP N rows. Personally, I don't really care which n rows are deleted first, next, last, etc. Depending on the WHERE clause, forcing SQL Server to scan the PK (which may or may not be clustered) might *not* be the most efficient way to find n rows from before a certain date or for a certain customer. If the most efficient way to delete based on your filter happens to match the PK, then SQL Server should do that automatically (I'd love to hear about cases where something different happens).
Thanks, Aaron. I frequently face the need to chunk through DELETEs as you describe. I have a question, though. You encased the DELETE statement within an explicit transaction. Since the DELETE will always include an implicit transaction, what's the purpose of the explicit one?
Thanks, Vern Rabe
Hi Vern, I just prefer to be explicit, especially when I'm potentially recommending other things that rely on or interact with transaction semantics (which as checkpoint / backup log), and especially when people might borrow this code to perform deletes against multiple (potentially related) tables, add error handling and rollback capability, etc.
This post really helped get some clarity in my mind about how to approach a problem I was having. Thank you.
Great article! Here it is http://codingsight.com/tag/transaction-log/ a great series of article about SQL Server transaction log. May be it could be useful for readers.
I've played around with some similar techniques for archiving in non-enterprise edition environments.
While I appreciate it's specifically not the point of this exercise, one interesting approach we used with some success was to use a temp table to store the primary key of the records to be deleted and then do chunk deletes using the primary key. Its useful for the high volume environments where you want to limit the time spent with the table locked.
In that scenario you also need to avoid lock escalation, so you have to reduce the chunk sizes.
Another alternative is to copy the rows you want to keep into a new table. TRUNCATE the original table, then copy the keeper rows back. With that method there's no chance you forget to recreate an index, constraint, etc. If there are triggers on the table you should probably disable them while copying the rows back. If there's an identity column, you'll also need to enable identity_insert before copying the rows back.
A few downsides though:
(1) It might work out better but it depends on how many rows you're deleting and how many rows you're keeping> The technique I describe here helps minimize the pain of deleting a million rows, say, whether the remainder of the table is 1000 rows or a billion.
(2) it doesn't work with updates, which don't have a handy truncate alternative – I realize the title of the post says DELETE, but this technique could be used to swap in any sort of DML operation that can be applied to a subset of the rows.
(3) You need to consider what to do about the copied rows while the delete or truncate is happening. Do you take a mutex? Do you hold the copied rows inside the permanent table as part of your transaction (in which case you work against the purpose of reducing log writes)? Truncate is logged less, but it can still take time, and other transactions might want to do things with the data in the meantime.
I noticed that the durations for pre-expanded vs autogrowing log were pretty similar in most of the tests. I am just wondering whether IFI (Instant File Initialization) was enabled or not, and how it would affect the results if IFI was in the opposite state.
Hi Serge, IFI can't affect log files – they need to be zeroed out regardless of that setting.
Why the single deletion statement is wrapped in "begin tran"/"commit"? Should it be in a transaction implicitly?
Because people are going to take this code and plug it into their own processes, which might include deletes or updates to multiple tables (parent/child or otherwise related, or just from a bunch of reporting tables). They also might want to add error/rollback handling, etc.
We do that too. I think the query to find the next batch to be deleted (run repeatedly for each loop) adds to the overall overhead, such that doing it once has a benefit.
We get all Clustered Index keys into #TEMP, with IDENTITY (as the CI of #TEMP), sorted in Clustered Index order, and delete on ranges of IDENTITY values joining #TEMP back to original table. We vary the number (per loop batch) according to the elapsed time (reduce by 50% if "slow", increase by 10% if "fast" up to a predetermined limit). The aim is to yield when the system is busy (but in reality, even on an otherwise unused system, same-size batches take different amounts of time to delete).
Populating #TEMP sorted on Clustered Index keys is in the hope that deleting in clustered index order means that the disk processing is more efficient than deletes scattered randomly across the CI. But I've never tested if there is a gain …
Our Log Backup scheduled task increases to once-a-minute during the overnight delete-purge job.
Kristen, I like your concept above. I'm working on something similar, which landed me here. In my case I also chose to use a #temp table with similar keys, but this varying the "number (per loop batch) according to the elapsed time". Do you have any example code of this?
What if CHECKPOINT operation doesnt shrink log file with SIMPLE backup mode ?
Sometimes the issue is simple – you need to run CHECKPOINT multiple times to force the log to wrap around, or there is an active transaction keeping the active portion of the log hostage. What does this say?
While executing my script there is ACTIVE_TRANSACTION
Let's eliminate the obvious first – do you COMMIT on every loop, or every n loops, or are you waiting to commit until the end?
Next would be *other* activity, if you can't shrink the log because of active transactions, well, there are active transactions on the system. Start with DBCC OPENTRAN;
When doing large deletes, is it beneficial to disable indexes and rebuild them when the process is complete?
As with all things IT – It depends!
You can try benchmarking this, but I would guess that somewhere between 10% and 25% of the table there's a break point where its quicker to drop and recreate than to do a straight delete.
It also depends on your overall table size and how quickly you can rebuild the index.
There may be a few isolated cases where this can work, but usually an important table in a busy production database is going to be locked down by referential integrity, indexed views, constant use (no maintenance window), and often just sheer size. There are ways to get around these things but it can make the process cumbersome and sometimes brittle.
Hi,
Is there a PL/SQL version of this please?
I'm sure there is, but not here. I can spell 'Oracle' but I don't have the faintest idea how to translate T-SQL to PL/SQL.
Hello Aaron, Apologies if this is a duplicate comment. Thank you for your article. You thorough analysis is something worth learning and implementing. I had a question. If I really don't care how long it takes to delete old data based on where clause, can I use DELETE TOP(1) in a loop with MAXDOP(1) hint? My purpose is, I don't want to take a log backup and I don't want to lose concurrency. Any suggestions/thoughts? Thank you.
If you really don't care about how long it takes, then sure, that is worth a shot. But if that takes a week, is it going to run fast enough to keep up, or will it fall behind and never catch up? Usually there's a good middle ground.
Thank you for your reply, Aaron. I tested deletes in batches in test. It took me around 9 minutes to delete around 4 million rows for a given date range. My batch size was 10000 rows. I also calculated time to delete each batch. It was 2-3 seconds. (Not including time to complete checkpoint command). Do you still think it may take considerably high if I start deleting just one row at a time in a loop with maxdop(1)? Or is it safe to try batch size of 10/100/1000? I appreciate your reply.
It is definitely safe to test those, I feel like one at a time will take longer, especially if you are doing additional things like commits / checkpoints / log backups on each iteration (or n iterations), since deleting only one row each iteration means you'll have 4 million iterations. I'm interested to hear about your test results, but I suspect your best overall results (with no observable difference in impact on concurrency) will be somewhere between 1,000 and 10,000 rows per iteration.
I gave a second thought about deleting 1 row at a time (actually I wanted to do without checkpoint) when you mention about my deletes ever catching up. Then I thought about playing with a batch size of 10000 rows with no checkpoint at all and with maxdop 1. Results were quite impressive. I was able to delete an entire date range in around a minute and half without checkpoint. I was monitoring log file growth continuously. Out of 643MB current size, the max usage I saw was 21%. Obviously, this was on a database with no live transactions. But the time difference with and without a checkpoint was a shocker to me. So, I will probably go ahead with a batch size of 10000 rows without checkpoint & maxdop 1 hint. I will share my results for production system when I run it. Thank you so much for your feedback.
Hmm, this blog made me think more than I wanted. It took me back 20+ years to one of my fir SQL projects moving data from Mainframe data to SQL. The tables we were inserting into were large and we had numerous transactions occurring by end users. I needed to insert the records as fast as possible with limited locking. I came up with the number of rows to insert at a time being around 90% of the number that would fit on a 8K page. It ended up speeding up the insert processing significantly as there was less lock contention.
Now I currently want to delete hundreds of millions of rows and have limited disk space on a SIMPLE recovery mode database.
I do not see a reason to CHECKPOINT after each DELETE as it should auto checkpoint when the log is 70% full. CHECKPOINT after each DELETE would cause more wait between each delete and increase the duration. I am not concerned about recovery though and some may, hence want the checkpoint.
Now the documentation indicates the DELETE TOP is random, but my guess that is not entirely true. It depends more on how you are selecting what you are deleting. If the DELETE does not have a WHERE clause or JOIN then it would likely choose the TOP records in order of the clustered index. Of course in Aaron's example and in my case I am not going against the cluster index.
In my case I am not concerned so much about the duration. More about locking, blocking and log growth. I will set the row count around 10,000 and set MAXDOP to 1. This should limit the length of table lock during the delete and burden on the processor.
Has anyone tried this with SSDs instead of spinning platters? I'm curious if the run times changes much (I figure the log file sizes should be relatively unchanged) for the different batch sizes…