
AT TIME ZONE – a new favourite feature in SQL Server 2016

Image © Mark Boyle | Australia Day Council of NSW.
Images property of respective artist(s). All rights reserved.
AT TIME ZONE is such a cool feature and I hadn’t noticed it until recently, even though Microsoft have had a page about it since December.
I live in Adelaide in Australia. And like over a billion other people in the world, Adelaide people have to cope with being on a half-hour time zone. In winter time, we’re UTC+9:30, and in summer time we’re UTC+10:30. Except that if you’re reading this in the northern hemisphere, you’ll need to remember that by ‘winter’, I mean April to October. Summer time is October to April, and Santa Claus sits on the beach with a cold drink, sweating through his thick red suit and beard. Unless he’s out saving lives, of course.
Within Australia, we have three main time zones (Western, Central, and Eastern), but this extends to five in the summer, as the three states which extend to the northern end of Australia (WA, Qld, and NT) don’t try to save any daylight. They’re close enough to the equator to not care, or something like that. It’s loads of fun for the Gold Coast airport, whose runway crosses the NSW-QLD border.
Database servers often run in UTC, because it’s simply easier to not have to deal with converting between UTC and local (and the reverse) in SQL Server. Many years ago I remember having to fix a report which listed incidents that occurred along with response times (I have blogged about this since). Measuring SLA was quite straight forward – I could see that one incident happened during the customer’s working hours, and that they responded within one hour. I could see that another incident occurred outside working hours, and the response was within two hours. The problem came when a report was produced at the end of a period when the time zone changed, causing an incident that actually happened at 5:30pm (outside hours) to be listed as if it had occurred at 4:30pm (inside hours). The response had taken about 90 minutes, which was okay, but the report was showing otherwise.
All this is fixed in SQL Server 2016.
How to use AT TIME ZONE in SQL Server 2016
Now, with AT TIME ZONE, instead of saying: '20160101 00:00 +10:30', I can start with a datetime value which does not have a time zone offset, and use AT TIME ZONE to explain that it’s in Adelaide.
SELECT CONVERT(datetime,'20160101 00:00')
AT TIME ZONE 'Cen. Australia Standard Time';
-- 2016-01-01 00:00:00.000 +10:30And this can be converted to the American time by appending AT TIME ZONE again.
SELECT CONVERT(datetime,'20160101 00:00')
AT TIME ZONE 'Cen. Australia Standard Time'
AT TIME ZONE 'US Eastern Standard Time';
-- 2015-12-31 08:30:00.000 -05:00Now, I know this is a lot more longwinded. And I need to explicitly convert the string to datetime, to avoid an error saying:
But despite the longwindedness of it, I love it, because at no point did I need to figure out that Adelaide was in +10:30, or that Eastern was -5:00 – I simply needed to know the time zone by name. Figuring out whether daylight saving should apply or not was handled for me, and I did not have to do any conversion from local to UTC to establish some baseline.
It works by using the Windows registry, which has all that information in it, but sadly, it’s not perfect when looking back in time. Australia changed the dates in 2008, and the US changed its dates in 2005 – both countries saving daylight for more of the year. AT TIME ZONE understands this. But it doesn’t seem to appreciate that in Australia in the year 2000, thanks to the Sydney Olympics, Australia started daylight saving about two months earlier. This is a little frustrating, but it’s not SQL’s fault – we need to blame Windows for that. I guess the Windows registry doesn’t remember the hotfix that went around that year. (Note to self: I might need to ask someone in the Windows team to fix that…)
The usefulness just continues though!
That time zone name doesn’t even need to be a constant. I can pass variables in, and even use columns:
WITH PeopleAndTZs AS
(
SELECT * FROM (VALUES
('Rob', 'Cen. Australia Standard Time'),
('Paul', 'New Zealand Standard Time'),
('Aaron', 'US Eastern Standard Time')
) t (person, tz)
)
SELECT tz.person, SYSDATETIMEOFFSET() AT TIME ZONE tz.tz
FROM PeopleAndTZs tz;
/*
Rob 2016-07-18 18:29:11.9749952 +09:30
Paul 2016-07-18 20:59:11.9749952 +12:00
Aaron 2016-07-18 04:59:11.9749952 -04:00
*/(Because I ran that just before 6:30pm here in Adelaide, which happens to be nearly 9pm in New Zealand where Paul is, and nearly 5am this morning in the eastern bit of America where Aaron is.)
This would let me easily see what time it is for people wherever they are in the world, and to see who would be best to respond to some issue, without having to perform any manual datetime conversions. And even more so, it would let me do it for people in the past. I could have a report which analyses which time zones would allow the greatest number of events to occur during business hours.
Those time zones are listed in sys.time_zone_info, along with what the current offset is, and whether daylight saving is currently applied.
| name | current_utc_offset | is_currently_dst |
|---|---|---|
| Singapore Standard Time | +08:00 | 0 |
| W. Australia Standard Time | +08:00 | 0 |
| Taipei Standard Time | +08:00 | 0 |
| Ulaanbaatar Standard Time | +09:00 | 1 |
| North Korea Standard Time | +08:30 | 0 |
| Aus Central W. Standard Time | +08:45 | 0 |
| Transbaikal Standard Time | +09:00 | 0 |
| Tokyo Standard Time | +09:00 | 0 |
Sampling of rows from sys.time_zone_info
I’m only really interested in what the name is, but anyway. And it’s interesting to see that there is a time zone called “Aus Central W. Standard Time” which is on the quarter-hour. Go figure. Also worth noting that places are referred to using their Standard Time name, even if they’re currently observing DST. Such as Ulaanbaatar in that list above, which isn’t listed as Ulaanbaatar Daylight Time. This may throw people for a loop when they start using AT TIME ZONE.
Can AT TIME ZONE cause performance issues?
Now, I’m sure you’re wondering what the impact of using AT TIME ZONE might be on indexing.
In terms of the shape of the plan, it’s no different to dealing with datetimeoffset in general. If I have datetime values, such as in the AdventureWorks column Sales.SalesOrderHeader.OrderDate (upon which I created an index called rf_IXOD), then running both this query:
select OrderDate, SalesOrderID
from Sales.SalesOrderHeader
where OrderDate >= convert(datetime,'20110601 00:00') at time zone 'US Eastern Standard Time'
and OrderDate < convert(datetime,'20110701 00:00') at time zone 'US Eastern Standard Time' ;And this query:
select OrderDate, SalesOrderID
from Sales.SalesOrderHeader
where OrderDate >= convert(datetimeoffset,'20110601 00:00 -04:00')
and OrderDate < convert(datetimeoffset,'20110701 00:00 -04:00');In both cases, you get plans that look like this:
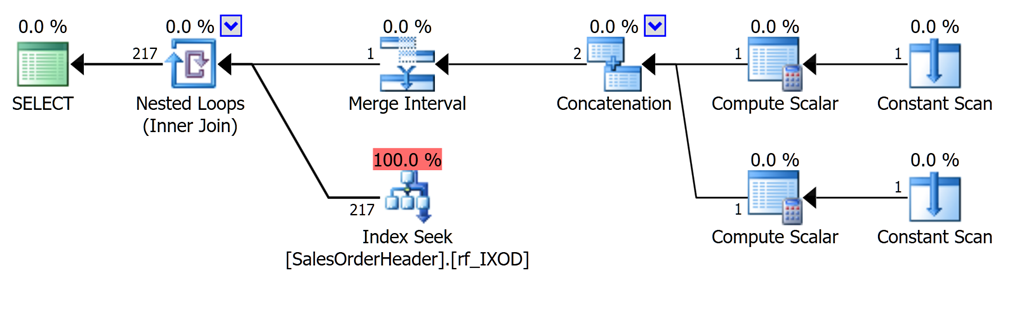
But if we explore a little more closely, there is a problem.
The one that uses AT TIME ZONE doesn’t use the statistics very well. It thinks it’s going to see 5,170 rows come out of that Index Seek, when there’s actually only 217. Why 5,170? Well, Aaron’s recent post, “Paying Attention To Estimates,” explains it, by referring to the post “Cardinality Estimation for Multiple Predicates” from Paul. 5,170 is 31,465 (rows in the table) * 0.3 * sqrt(0.3).
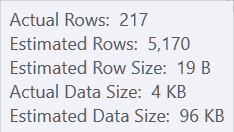
The second query gets it right, estimating 217. No functions involved, you see.
This is probably fair enough. I mean – at the point when it’s producing the plan, it won’t have asked the registry for the information it needs, so it really doesn’t know how many to estimate. But there is potential for it to be a problem.
If I add extra predicates which I know can’t be a problem, then my estimates actually drop even further – down to 89.9 rows.
select OrderDate, SalesOrderID
from Sales.SalesOrderHeader
where OrderDate >= convert(datetime,'20110601 00:00') at time zone 'US Eastern Standard Time'
and OrderDate < convert(datetime,'20110701 00:00') at time zone 'US Eastern Standard Time'
and OrderDate >= convert(datetimeoffset,'20110601 00:00 +14:00')
and OrderDate < convert(datetimeoffset,'20110701 00:00 -12:00');Estimating too many rows means too much memory is allocated, but estimating too few can cause too little memory, with potentially needing a spill to correct the problem (which can often be disastrous from a performance perspective). Go read Aaron’s post for more information about how poor estimates can be bad.
When I consider how to handle displaying values for those people from before, I can use queries like this:
WITH PeopleAndTZs AS
(
SELECT * FROM (VALUES
('Rob', 'Cen. Australia Standard Time'),
('Paul', 'New Zealand Standard Time'),
('Aaron', 'US Eastern Standard Time')
) t (person, tz)
)
SELECT tz.person, o.SalesOrderID, o.OrderDate AT TIME ZONE 'UTC' AT TIME ZONE tz.tz
FROM PeopleAndTZs tz
CROSS JOIN Sales.SalesOrderHeader o
WHERE o.SalesOrderID BETWEEN 44001 AND 44010;And get this plan:
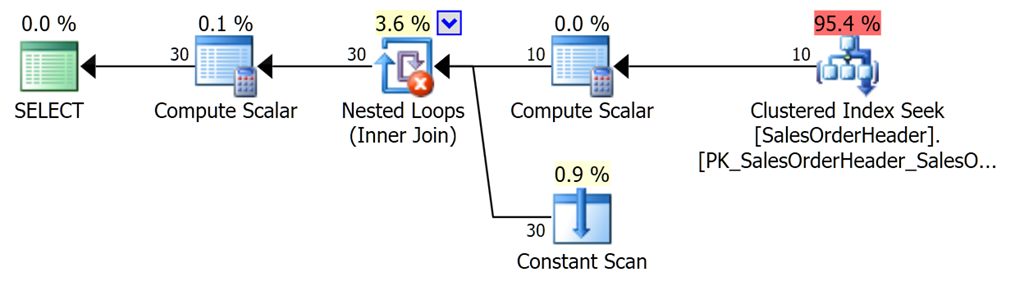
…which has no such concerns – the right-most Compute Scalar is converting the datetime OrderDate into datetimeoffset for UTC, and the left-most Compute Scalar is converting it into the appropriate time zone for the person. The warning is because I’m doing a CROSS JOIN, and that was fully intentional.
Advantages and Disadvantages of other time conversion methods
Before AT TIME ZONE, one of my favourite, but often unappreciated, features of SQL 2008 was the data type datetimeoffset. This allows date/time data to be stored with the time zone as well, such as '20160101 00:00 +10:30', which is when we celebrated New Year in Adelaide this year. To see when that was in US Eastern, I can use the function SWITCHOFFSET.
SELECT SWITCHOFFSET('20160101 00:00 +10:30', '-05:00');
-- 2015-12-31 08:30:00.0000000 -05:00This is the same moment in time, but in a different part of the world. If I were on the phone to someone in North Carolina or New York, wishing them a Happy New Year because it was just past midnight in Adelaide, they would be saying “What do you mean? It’s still breakfast time here on New Year’s Eve!”
The problem is that to do this, I need to know that in January, Adelaide is +10:30 and US Eastern is –5:00. And that’s often a pain. Especially if I’m asking about late March, early April, October, early November - those times of year when people can’t be sure which time zone people in other countries were in because they change by an hour for daylight saving, and they all do so according to different rules. My computer tells me what time zone people are in now, but it’s much harder to tell what time zone they will be in at other times of the year.
For some other information about converting between time zones, and how folks like Aaron have dealt with daylight saving, see the following links:
- Using AT TIME ZONE to fix an old report (that’s me!)
- Handle conversion between time zones in SQL Server - part 1
- Handle conversion between time zones in SQL Server - part 2
- Handle conversion between time zones in SQL Server - part 3
And some official Microsoft documentation:
Should you use AT TIME ZONE?
AT TIME ZONE isn’t perfect. But it is really useful – incredibly so. It’s flexible enough to accept columns and variables as input, and I can see a huge amount of potential for it. But if it’s going to cause my estimates to be out, then I’m going to need to be careful. For display purposes, this shouldn’t matter at all though, and that’s where I can see it being most useful. Making it easier to convert a display value to or from UTC (or to or from a local time), without anyone having to bust their brains about offsets and DST, is a big win.
This really is one of my favourite features of SQL Server 2016. I’ve been crying out for something like this for a very long time.
Oh, and most of those billion people on the half-hour time zone are in India. But you probably already knew that…
34 thoughts on “AT TIME ZONE – a new favourite feature in SQL Server 2016”
Comments are closed.

It seems the best way to *store* data (as opposed to compute with) is still datetime2 as UTC. Would you agree with that?
@tobi, I'm not Rob, but yes, I agree – my first choice would be to store all data in UTC format, since it is easier to get to any other time zone in one hop rather than two. But only with as much precision as necessary, which means I won't always use datetime2 (sometimes date or smalldatetime is plenty).
I'm pretty sure I rolled something very similar in SQL 2005 using CLR functions to perform the conversion, it's still in use to this day to performing many many conversions a day. Would have been nice to have this back then.
If I still worked on that team, I'd try and get it implemented, I'll send them this article anyway – but that might see the death of my CLR code :(.
From datetime or datetime2 it would be a hop to get it into datetimeoffset (specifying UTC), and then a hop to put it into the preferred time zone. And there's the matter of whether you consider the offset of the original to be useful information or not. If UTC can be used consistently, then great. If you need to use SQL on a box which isn't in UTC, then can you rely on every piece of code using GETUTCDATE() or SYSUTCDATETIME()? If you have any code using GETDATE(), then it's better to have your data types as datetimeoffset so that the OS time zone (specifically the DST flag) gets picked up.
But it's all about compromise. If you have control over how everything is handled, then I'd tend towards using the smaller datetime and insisting on GETUTCDATE() / SYSUTCDATETIME(), and on a server that is fixed in UTC.
I'm sure many people solved this with CLR, much like people implemented Row-Level Security using views, and Data Masking using scalar functions (with schemabinding of course), and STRING_SPLIT() in a variety of ways. This makes it way easier, and as a consultant, it's one more scenario where I can avoid needing to persuade the customer to either allow CLR or compromise on functionality.
Is it even possible to fix a server in UTC? You'd have to disable daylight savings and who knows what else. What about split seconds? I don't understand them enough to be sure.
My experience with a fairly big app (>400 tables, lot's of C#) is that the UTC-everywhere approach works really well. So far I never had the case where I wanted to store the time zone. I always wanted to store instants in time. Calculating with UTC also is much easier because it's a contiguous timeline without gaps and duplication.
I did have a few UTC/local front-end bugs but they are found immediately because the time displayed is obviously off. It's a cheap and low-risk bug category. Backend bugs did not occur according to my recollection.
Looks like I still have to use .net to get proper date timezone conversions.
Datetimeoffset doesn't have gaps either. So you can either use SYSUTCDATETIME() or SYSDATETIMEOFFSET() to avoid gaps.
This method essentially works the same way as a .Net solution. So this gives another option.
Agreed, this is one of the best hidden features of SQL Server 2016.
Thank you. This might just save the day for a client that has one system that uses standard time and another that uses DST and they need to talk to each other and join on dates and times. Fun fun.
Looking at any date that is not in a datetimeoffset data type, I don't believe that you can determine if it was put in as UTC, so there's no guarantee that your dates are actually consistent.
To guarantee that your dates are always stored as UTC, I believe that you can specify the data type as datetimeoffset and then put a check constraint so that the offset is only 0.
ADD CONSTRAINT CHECK (DATEPART(TZOFFSET, ) = 0);
Nice one, Rob.
Reminds me of a story that happened in nineties, on a German airport. A colleague of mine was participating in rollout of some system to the airport servers. At some stage he sat in front of a screen and noticed that the current time displayed isn't right… So he fixed it. And the luggage handling system went bananas.. My colleague found himself in his way home much faster than he had anticipated ?
Can this function be used inside VIEWS query ?
I have failed hard at this. However I cannot find any information that it is not working.
Have anyone an experience with this matter ?
It should be fine. Can you send me a sample of your code and what error you're getting? Use rob at LobsterPot dot com dot au.
Ouch – learning the hard way!
If you cast a datetime to a datetimeoffset, it'll assume UTC, so you're still not safe. Imagine my server in +9:30. If I use GETDATE(), it'll give the time in my time zone, but store it as +0, which would be wrong.
Unfortunatelly, the de-facto standard for time zone names is the IANA timezone database. If I want the current time in Adelaide I'll look for `Australia/Adelaide`. If I search for a flight, Qantas will return the departure and arrival times with an offset and `Australia/Adelaide`. So do the GDSs (Amadeus, Sabre), and sites like Flightstats.
The IANA time zone names are used in any REST API, SOAP Web Service or database where the timezone name is required instead of an offset. This means that in order to use `AT TIME ZONE` we'll have to map from the standard names to the (often ambiguous and duplicated) Windows timezone names. Storing Windows time zone names can't work precisely because there is ambiguity and duplication.
If you care about time zone names enough to need `AT TIME ZONE` for querying it probably means you want to store the names themselves instead of offsets. If one has to *map* timezone names before querying, why not calculate the offsets externally and use a `datetimeoffset` parameter ?
This limits the usefulness of `AT TIME ZONE` quite a bit.
Yes, but when you want to be able to tell that the time zone changed for seasons, it's still useful. I agree that it's not fully complete, and I would the DMV to contain extra information such as whether DST is observed, and example cities – but it's way better than before.
For example, I can tell that on one day of the year, there are only two minutes between 1:59am and 3:01am, and on another day, there are 122 minutes. I find this hugely valuable, even if I can't easily tell which TZ is Adelaide and which is Darwin.
Sure, but I'd rather have a table that maps the names than have a table that has to keep track of names, offsets, and also DST (datetimeoffset is not DST-aware). Just because AT TIME ZONE isn't perfect when you're using IANA, does not mean it is not generally better. :-) And if you already have a solution in place, okay, don't use AT TIME ZONE. I do think this feature will simplify a lot of scenarios.
Regarding the comment "I'd rather have a table that maps the names than have a table that has to keep track of names, offsets, and also DST (datetimeoffset is not DST-aware)."
The TIMEZONE is DST offsets, it seems the sys.time_zone_info, the column 'is_currently_dst' confuse us it is only DST-aware.
I test based on example below from the documentation ( or please let me know if I misunderstood the statement above)
/*
Moving to DST in "Central European Standard Time" zone:
offset changes from +01:00 -> +02:00
Change occurred on March 29th, 2015 at 02:00:00.
Adjusted local time became 2015-03-29 03:00:00.
*/
–Time before DST change has standard time offset (+01:00)
SELECT CONVERT(datetime2(0), '2015-03-29T01:01:00', 126)
AT TIME ZONE 'Central European Standard Time';
–Result: 2015-03-29 01:01:00 +01:00
/*
Adjusted time from the "gap interval" (between 02:00 and 03:00)
is moved 1 hour ahead and presented with the summer time offset
(after the DST change)
*/
SELECT CONVERT(datetime2(0), '2015-03-29T02:01:00', 126)
AT TIME ZONE 'Central European Standard Time';
–Result: 2015-03-29 03:01:00 +02:00
–Time after 03:00 is presented with the summer time offset (+02:00)
SELECT CONVERT(datetime2(0), '2015-03-29T03:01:00', 126)
AT TIME ZONE 'Central European Standard Time';
–Result: 2015-03-29 03:01:00 +02:00
However, IANA/Olson Time Zone Database refined to a specific narrow location compare to Microsoft Window Time Zone Database which is broad.
This git project use IANA/Olson timezone database to SQL Server but it seems scenario such as "spring forward" and "fall back" DST transition doesn't include.
https://github.com/mj1856/SqlServerTimeZoneSupport
How would I simulate AT TIME ZONE for non-2016 SQL users?
The majority of the world's databases are NOT 2016 MSSQL
It's not easy, Fran.
The easy bit is changing from one offset to another, that's just adding and subtracting minutes. The hard bit is knowing how many minutes. I'd consider having a table that you maintain, with the dates that each TZ starts or ends daylight saving. You could get this from somewhere online maybe? Or see if you can extract it from the Windows registry somehow?
When I've had to do this before, I've typically only needed a handful of TZs, across a small number of years.
What's the time zone name in Sydney? thanks
Sydney is 'AUS Eastern Standard Time', as opposed to Brisbane which is 'E. Australia Standard Time'. The way I test for these types of things is to compare times when they should be different (such as in January, when Sydney observes DST and Brisbane doesn't.
what is the time zone name in india?
I want to Convert Pacific Time Zone to Indian Time Zone
i have tried with "(BeginDate at time zone 'Pacific Standard Time') AT TIME ZONE 'UTC' as PST2IST"
Here My BeginDate is Pacific tImezone.
Thanks for the post, it was exactly what I was looking for.
It’s ‘India Standard Time’
Thanks for this post.
It helped.
Its really help full and works as required in sql server 2016.
But I am not able to build SQL Server Project because of AT TIME ZONE in Visual studio 2015.
Anyone have idea why its happening? working correct in sql server but giving error in visual studio 2015. Any updates or settings need to be done in visual studio?
Glad you like it. You’ll need to make sure that VS knows that it’s targetting SQL 2016 to support any of the new features.
Hi Rob,
Thanks for an excellent article. I've a question though.
When it is 10 am UTC, it is 5 am in NewYork, USA (standard time)
How do I get that 5 am as a datetime field value?
Thanks.
Wouldn't it just be like this (I wouldn't bring
datetimeoffsetinto it at all):That’s the one! Using datetimeoffset here makes it a little more confusing, because datetimeoffset has its time zone information built in, while AT TIME ZONE is used to specify the time zone context for a datetime value that doesn’t have that info.
I do still like datetimeoffset – it’s tremendously useful when you have globally distributed servers – some in Australia, some in America, some in Europe – with legislation requiring they’re in local time zones. Then you can use sysdatetimeoffset() instead of getdate() and have nicely sortable data. But if you have a datetime value that you need to convert to a different time zone and be DST-aware, AT TIME ZONE really helps.
You can always work out what the offset is and create a datetimeoffset too…