
Paying Attention to Estimates
Last week I published a post called #BackToBasics : DATEFROMPARTS(), where I showed how to use this 2012+ function for cleaner, sargable date range queries. I used it to demonstrate that if you use an open-ended date predicate, and you have an index on the relevant date/time column, you can end up with much better index usage and lower I/O (or, in the worst case, the same, if a seek can't be used for some reason, or if no suitable index exists):
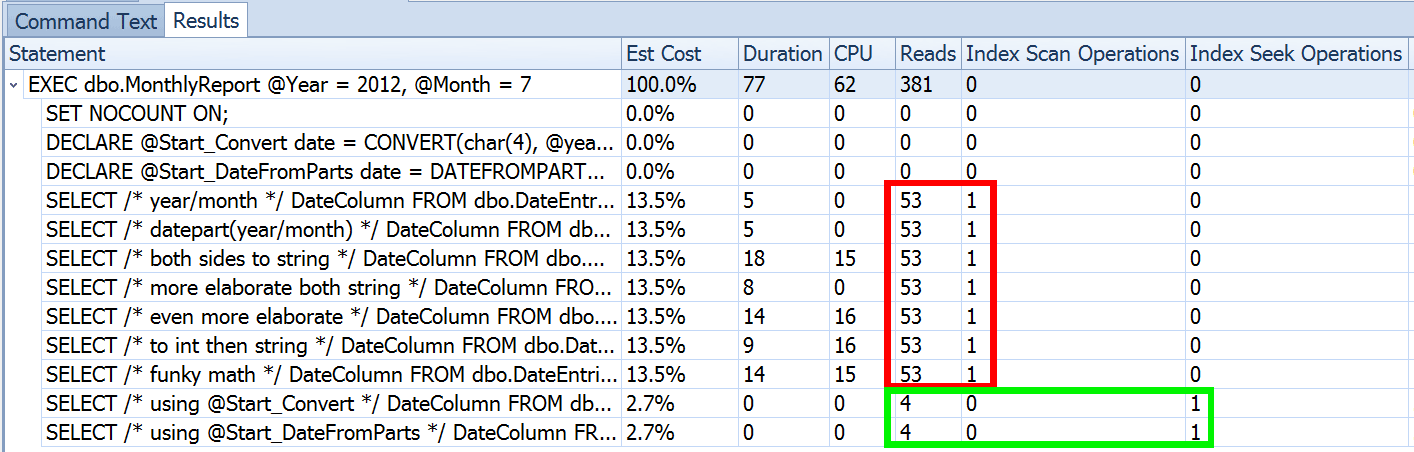
But that's only part of the story (and to be clear, DATEFROMPARTS() isn't technically required to get a seek, it's just cleaner in that case). If we zoom out a bit, we notice that our estimates are far from accurate, a complexity I didn't want to introduce in the previous post:
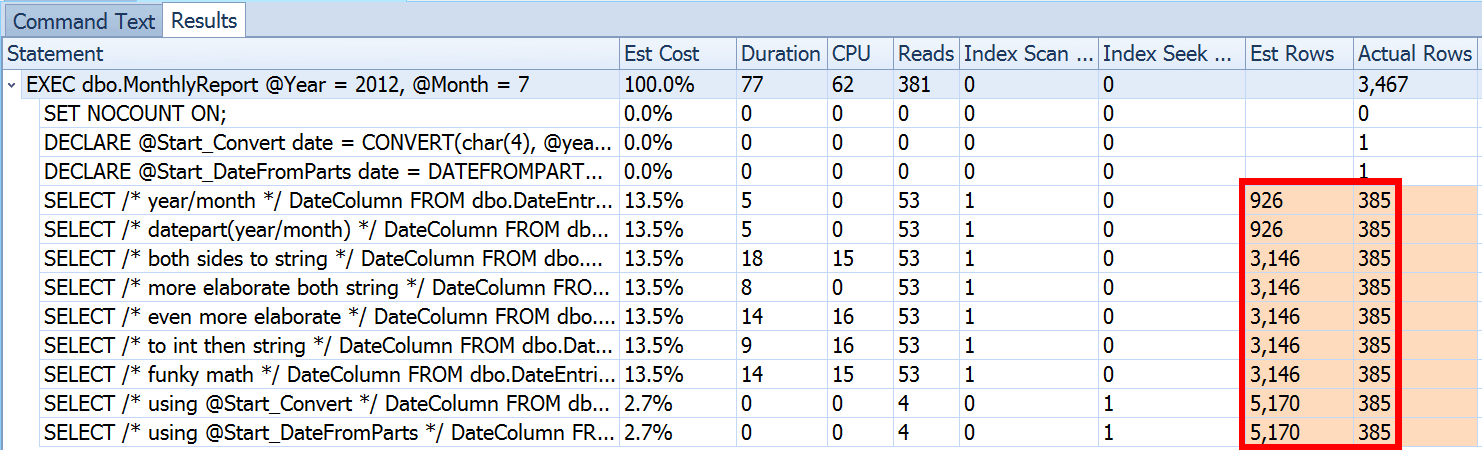
This is not uncommon for both inequality predicates and with forced scans. And of course, wouldn't the method I suggested yield the most inaccurate stats? Here is the basic approach (you can get the table schema, indexes, and sample data from my previous post):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GONow, inaccurate estimates won't always be a problem, but it can cause issues with inefficient plan choices at the two extremes. A single plan might not be optimal when the chosen range will yield a very small or very large percentage of the table or index, and this can get very hard for SQL Server to predict when the data distribution is uneven. Joseph Sack outlined the more typical things bad estimates can affect in his post, "Ten Common Threats to Execution Plan Quality:"
There are others, too, like memory grants that are too large or too small. He goes on to describe some of the more common causes of bad estimates, but the primary cause in this case is missing from his list: guesstimates. Because we're using a local variable to change the incoming int parameters to a single local date variable, SQL Server doesn't know what the value will be, so it makes standardized guesses of cardinality based on the entire table.
We saw above that the estimate for my suggested approach was 5,170 rows. Now, we know that with an inequality predicate, and with SQL Server not knowing the parameter values, it will guess 30% of the table. 31,645 * 0.3 is not 5,170. Nor is 31,465 * 0.3 * 0.3, when we remember that there are actually two predicates working against the same column. So where does this 5,170 value come from?
As Paul White describes in his post, "Cardinality Estimation for Multiple Predicates," the new cardinality estimator in SQL Server 2014 uses exponential backoff, so it multiplies the row count of the table (31,465) by the selectivity of the first predicate (0.3), and then multiplies that by the square root of the selectivity of the second predicate (~0.547723).
So, now we can see where SQL Server came up with its estimate; what are some of the methods we can use to do anything about it?
- Pass in date parameters. When possible, you can change the application so that it passes in proper date parameters instead of separate integer parameters.
- Use a wrapper procedure. A variation on method #1 - for example if you can't change the application - would be to create a second stored procedure that accepts constructed date parameters from the first.
- Use
OPTION (RECOMPILE). At the slight cost of compilation every time the query is run, this forces SQL Server to optimize based on the values presented each time, instead of optimizing a single plan for unknown, first, or average parameter values. (For a thorough treatment of this topic, see Paul White's "Parameter Sniffing, Embedding, and the RECOMPILE Options."
- Use dynamic SQL. Having dynamic SQL accept the constructed
datevariable forces proper parameterization (just as if you had called a stored procedure with adateparameter), but it is a little ugly, and harder to maintain.
- Mess with hints and trace flags. Paul White talks about some of these in the aforementioned post.
I'm not going to suggest that this is an exhaustive list, and I'm not going to reiterate Paul's advice about hints or trace flags, so I'll just focus on showing how the first four approaches can mitigate the issue with bad estimates.
1. Date Parameters
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO2. Wrapper Procedure
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO3. OPTION (RECOMPILE)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO4. Dynamic SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GOThe Tests
With the four sets of procedures in place, it was easy to construct tests that would show me the plans and the estimates SQL Server derived. Since some months are busier than others, I picked three different months, and executed them all multiple times.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month;
EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End;
EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month;
EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month;
EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month;
/* repeat for @Year = 2011, @Month = 9 -- 157 rows */
/* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */The result? Every single plan yields the same Index Seek, but the estimates are only correct across all three date ranges in the OPTION (RECOMPILE) version. The rest continue to use the estimates derived from the first set of parameters (July 2012), and so while they get better estimates for the first execution, that estimate won't necessarily be any better for subsequent executions using different parameters (a classic, textbook case of parameter sniffing):
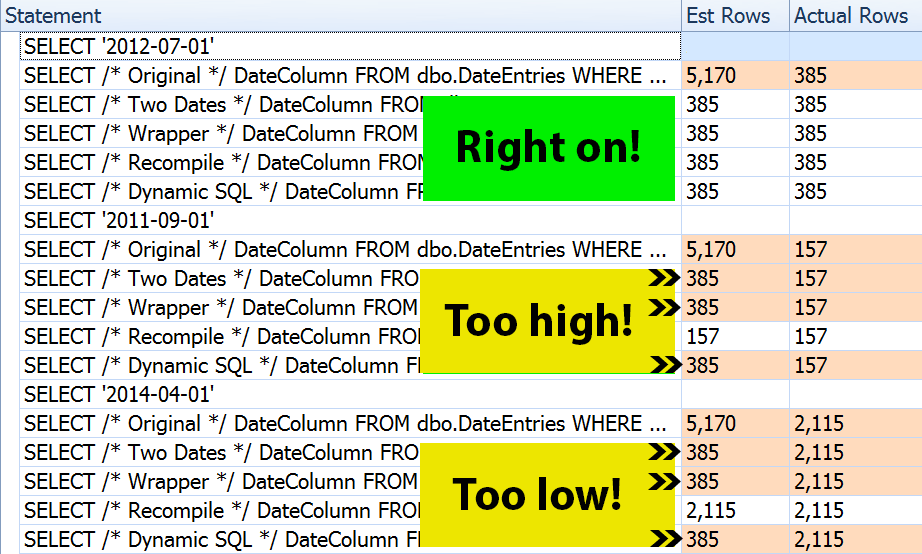
Note that the above is not *exact* output from SQL Sentry Plan Explorer - for example, I removed the statement tree rows that showed the outer stored procedure calls and parameter declarations.
It will be up to you to determine whether the tactic of compiling every time is best for you, or whether you need to "fix" anything in the first place. Here, we ended up with the same plans, and no noticeable differences in runtime performance metrics. But on bigger tables, with more skewed data distribution, and larger variances in predicate values (e.g. consider a report that can cover a week, a year, and anything in between), it may be worth some investigation. And note that you can combine methods here - for example, you could switch to proper date parameters *and* add OPTION (RECOMPILE), if you wanted.
Conclusion
In this specific case, which is an intentional simplification, the effort of getting the correct estimates didn't really pay off - we didn't get a different plan, and the runtime performance was equivalent. There are certainly other cases, though, where this will make a difference, and it is important to recognize estimate disparity and determine whether it might become an issue as your data grows and/or your distribution skews. Unfortunately, there is no black-or-white answer, as many variables will affect whether compilation overhead is justified - as with many scenarios, IT DEPENDS™...
