
Matching Supply With Demand Challenge
My friend Peter Larsson sent me a T-SQL challenge involving matching supply with demand. As far as challenges go, it's a formidable one. It's a pretty common need in real life; it's simple to describe, and it's quite easy to solve with reasonable performance using a cursor-based solution. The tricky part is to solve it using an efficient set-based solution.
When Peter sends me a puzzle, I typically respond with a suggested solution, and he usually comes up with a better-performing, brilliant solution. I sometimes suspect he sends me puzzles to motivate himself to come up with a great solution.
Since the task represents a common need and is so interesting, I asked Peter if he would mind if I shared it and his solutions with the sqlperformance.com readers, and he was happy to let me.
This month, I'll present the challenge and the classic cursor-based solution. In subsequent articles, I'll present set-based solutions—including the ones Peter and I worked on.
The Challenge
The challenge involves querying a table called Auctions, which you create using the following code:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
);
This table holds demand and supply entries. Demand entries are marked with the code D and supply entries with S. Your task is to match supply and demand quantities based on ID ordering, writing the result into a temporary table. The entries could represent cryptocurrency buy and sell orders such as BTC/USD, stock buy and sell orders such as MSFT/USD, or any other item or good where you need to match supply with demand. Notice the Auctions entries are missing a price attribute. As mentioned, you should match the supply and demand quantities based on ID ordering. This ordering could have been derived from price (ascending for supply entries and descending for demand entries) or any other relevant criteria. In this challenge, the idea was to keep things simple and assume the ID already represents the relevant order for matching.
As an example, use the following code to fill the Auctions table with a small set of sample data:
SET NOCOUNT ON;
DELETE FROM dbo.Auctions;
SET IDENTITY_INSERT dbo.Auctions ON;
INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES
(1, 'D', 5.0),
(2, 'D', 3.0),
(3, 'D', 8.0),
(5, 'D', 2.0),
(6, 'D', 8.0),
(7, 'D', 4.0),
(8, 'D', 2.0),
(1000, 'S', 8.0),
(2000, 'S', 6.0),
(3000, 'S', 2.0),
(4000, 'S', 2.0),
(5000, 'S', 4.0),
(6000, 'S', 3.0),
(7000, 'S', 2.0);
SET IDENTITY_INSERT dbo.Auctions OFF;
You're supposed to match the supply and demand quantities like so:
- A quantity of 5.0 is matched for Demand 1 and Supply 1000, depleting Demand 1 and leaving 3.0 of Supply 1000
- A quantity of 3.0 is matched for Demand 2 and Supply 1000, depleting both Demand 2 and Supply 1000
- A quantity of 6.0 is matched for Demand 3 and Supply 2000, leaving 2.0 of Demand 3 and depleting supply 2000
- A quantity of 2.0 is matched for Demand 3 and Supply 3000, depleting both Demand 3 and Supply 3000
- A quantity of 2.0 is matched for Demand 5 and Supply 4000, depleting both Demand 5 and Supply 4000
- A quantity of 4.0 is matched for Demand 6 and Supply 5000, leaving 4.0 of Demand 6 and depleting Supply 5000
- A quantity of 3.0 is matched for Demand 6 and Supply 6000, leaving 1.0 of Demand 6 and depleting Supply 6000
- A quantity of 1.0 is matched for Demand 6 and Supply 7000, depleting Demand 6 and leaving 1.0 of Supply 7000
- A quantity of 1.0 is matched for Demand 7 and Supply 7000, leaving 3.0 of Demand 7 and depleting Supply 7000; Demand 8 isn't matched with any Supply entries and therefore is left with the full quantity 2.0
Your solution is supposed to write the following data into the resulting temporary table:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Large Set of Sample Data
To test the performance of the solutions, you'll need a larger set of sample data. To help with this, you can use the function GetNums, which you create by running the following code:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
This function returns a sequence of integers in the requested range.
With this function in place, you can use the following code provided by Peter to populate the Auctions table with sample data, customizing the inputs as needed:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code;
As you can see, you can customize the number of buyers and sellers as well as the minimum and maximum buyer and seller quantities. The above code specifies 200,000 buyers and 200,000 sellers, resulting in a total of 400,000 rows in the Auctions table. The last query tells you how many demand (D) and supply (S) entries were written to the table. It returns the following output for the aforementioned inputs:
Code Items ---- ----------- D 200000 S 200000
I'm going to test the performance of various solutions using the above code, setting the number of buyers and sellers each to the following: 50,000, 100,000, 150,000, and 200,000. This means I'll get the following total numbers of rows in the table: 100,000, 200,000, 300,000, and 400,000. Of course, you can customize the inputs as you wish to test the performance of your solutions.
Cursor-Based Solution
Peter provided the cursor-based solution. It's pretty basic, which is one of its important advantages. It will be used as a benchmark.
The solution uses two cursors: one for demand entries ordered by ID and the other for supply entries ordered by ID. To avoid a full scan and a sort per cursor, create the following index:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity
ON dbo.Auctions(Code, ID)
INCLUDE(Quantity);
Here's the complete solution's code:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply;
As you can see, the code starts by creating a temporary table. It then declares the two cursors and fetches a row from each, writing the current demand quantity to the variable @DemandQuantity and the current supply quantity to @SupplyQuantity. It then processes the entries in a loop as long as the last fetch was successful. The code applies the following logic in the loop's body:
If the current demand quantity is less than or equal to the current supply quantity, the code does the following:
- Writes a row into the temp table with the current pairing, with the demand quantity (@DemandQuantity) as the matched quantity
- Subtracts the current demand quantity from the current supply quantity (@SupplyQuantity)
- Fetches the next row from the demand cursor
Otherwise, the code does the following:
-
Checks if the current supply quantity is greater than zero, and if so, it does the following:
- Writes a row into the temp table with the current pairing, with the supply quantity as the matched quantity
- Subtracts the current supply quantity from the current demand quantity
- Fetches the next row from the supply cursor
Once the loop is done, there are no more pairs to match, so the code just cleans up the cursor resources.
From a performance standpoint, you do get the typical overhead of cursor fetching and looping. Then again, this solution does a single ordered pass over the demand data and a single ordered pass over the supply data, each using a seek and range scan in the index you created earlier. The plans for the cursor queries are shown in Figure 1.

Figure 1: Plans for Cursor Queries
Since the plan performs a seek and ordered range scan of each of the parts (demand and supply) with no sorting involved, it has linear scaling. This was confirmed by the performance numbers I got when testing it, as shown in Figure 2.
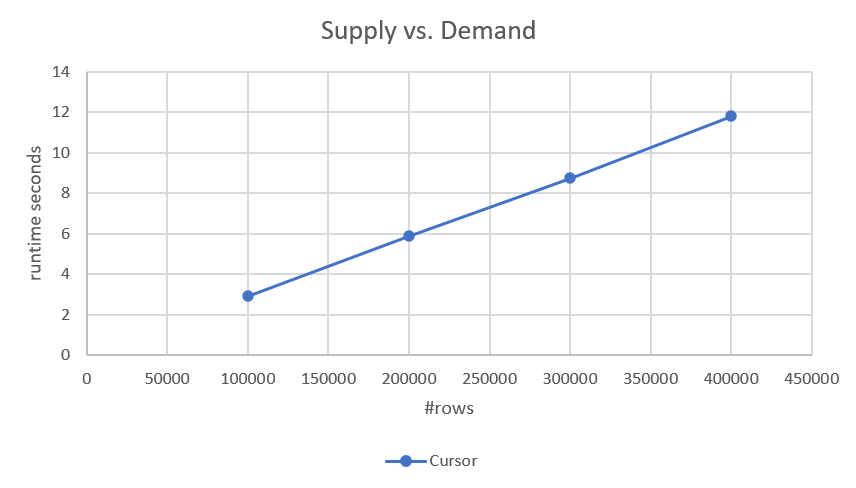
Figure 2: Performance of Cursor-Based Solution
If you're interested in the more precise run times, here they are:
- 100,000 rows (50,000 demands and 50,000 supplies): 2.93 seconds
- 200,000 rows: 5.89 seconds
- 300,000 rows: 8.75 seconds
- 400,000 rows: 11.81 seconds
Given the solution has linear scaling, you can easily predict the run time with other scales. For example, with a million rows (say, 500,000 demands and 500,000 supplies) it should take about 29.5 seconds to run.
The Challenge Is On
The cursor-based solution has linear scaling and, as such, it isn't bad. But it does incur the typical cursor fetching and looping overhead. Obviously, you can reduce this overhead by implementing the same algorithm using a CLR-based solution. The question is, can you come up with a well-performing set-based solution for this task?
As mentioned, I'll explore set-based solutions—both poorly performing and well-performing—starting next month. In the meanwhile, if you're up to the challenge, see if you can come up with set-based solutions of your own.
To verify the correctness of your solution, first compare its result with the one shown here for the small set of sample data. You can also check the validity of your solution's result with a large set of sample data by verifying the symmetric difference between the cursor solution's result and yours is empty. Assuming the cursor's result is stored in a temp table called #PairingsCursor and yours in a temp table called #MyPairings, you can use the following code to achieve this:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings)
UNION ALL
(SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
The result should be empty.
Good luck!

Hi Itzik,
the underlying idea is to calculare running totals and couple where totals are overlapping.
The timing id about 3mins in the 100K case.
Let's take this for a starting point, let me know your opinion.
Hi Itzik, Optimizing final Join Query:
This will simplify the join so that the SQL can handle in a better way
Now with 800.000 rows we have 21s for cursor and 5 seconds for the set based. Not too bad.
Hi Itzik,
Is it allowed to create additional indexes or utilities (functions, columnstore tables, etc.)?
Hi Tom,
Sure, you can.
Hi Itzik,
I've applied similar logic to Luca i.e. matching overlapping intervals between supply and demand.
I've tried to optimize using temp tables / indexing and used nonclustered columnstore to enable batch processing.
--big test drop index if exists idx_Code_ID_i_Quantity on dbo.Auctions; DECLARE -- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers -- so total rowcount is double (100K, 200K, 300K, 400K) @Buyers AS INT = 400000, @Sellers AS INT = 400000, @BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001, @BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999, @SellerMinQuantity AS DECIMAL(19, 6) = 0.000001, @SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999; TRUNCATE TABLE dbo.Auctions; INSERT INTO dbo.Auctions(Code, Quantity) SELECT Code, Quantity FROM ( SELECT 'D' AS Code, (ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity))) / 1000000E + @BuyerMinQuantity AS Quantity FROM dbo.GetNums(1, @Buyers) UNION ALL SELECT 'S' AS Code, (ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity))) / 1000000E + @SellerMinQuantity AS Quantity FROM dbo.GetNums(1, @Sellers) ) AS X ORDER BY NEWID(); SELECT Code, COUNT(*) AS Items FROM dbo.Auctions GROUP BY Code; CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); --Start DROP TABLE IF EXISTS #supply; DROP TABLE IF EXISTS #demand; CREATE TABLE #demand ( DemandID INT NOT NULL, Code CHAR(1) NOT NULL, DemandQuantity DECIMAL(19, 6) NOT NULL, QuantityFromDemand DECIMAL(19, 6) NOT NULL, QuantityToDemand DECIMAL(19, 6) NOT NULL ); CREATE TABLE #supply ( SupplyID INT NOT NULL, Code CHAR(1) NOT NULL, SupplyQuantity DECIMAL(19, 6) NOT NULL, QuantityFromSupply DECIMAL(19, 6) NOT NULL, QuantityToSupply DECIMAL(19,6) NOT NULL ); WITH demand AS ( SELECT a.ID AS DemandID, a.Code, a.Quantity AS DemandQuantity, SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) - a.Quantity AS QuantityFromDemand, SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS QuantityToDemand FROM dbo.Auctions AS a WHERE Code = 'D' ) INSERT INTO #demand ( Code, DemandID, DemandQuantity, QuantityFromDemand, QuantityToDemand ) SELECT d.Code, d.DemandID, d.DemandQuantity, d.QuantityFromDemand, d.QuantityToDemand FROM demand AS d; WITH supply AS ( SELECT a.ID AS SupplyID, a.Code, a.Quantity AS SupplyQuantity, SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) - a.Quantity AS QuantityFromSupply, SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS QuantityToSupply FROM dbo.Auctions AS a WHERE Code = 'S' ) INSERT INTO #supply ( Code, SupplyID, SupplyQuantity, QuantityFromSupply, QuantityToSupply ) SELECT s.Code, s.SupplyID, s.SupplyQuantity, s.QuantityFromSupply, s.QuantityToSupply FROM supply AS s; CREATE NONCLUSTERED INDEX ix_1 ON #demand(QuantityFromDemand) INCLUDE(Code, DemandID, DemandQuantity, QuantityToDemand); CREATE NONCLUSTERED INDEX ix_1 ON #supply(QuantityFromSupply) INCLUDE(Code, SupplyID, QuantityToSupply); CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(Code) WHERE DemandID is null; DROP TABLE IF EXISTS #myPairings; CREATE TABLE #myPairings ( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19, 6) NOT NULL ); INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity) SELECT d.DemandID, s.SupplyID, d.DemandQuantity - CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end - CASE WHEN s.QuantityToSupply < d.QuantityToDemand THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity FROM #demand AS d INNER JOIN #supply AS s ON (d.QuantityFromDemand < s.QuantityToSupply AND s.QuantityFromSupply <= d.QuantityFromDemand) UNION ALL SELECT d.DemandID, s.SupplyID, d.DemandQuantity - CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END - CASE WHEN s.QuantityToSupply < d.QuantityToDemand THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity FROM #supply AS s INNER JOIN #demand AS d ON (s.QuantityFromSupply < d.QuantityToDemand AND d.QuantityFromDemand < s.QuantityFromSupply);Actually now that I have broken demand and supply into separate tables I should have dropped some fields and make them (and indexes) narrower. Also I forgot to mention earlier, the query takes around 1.5 seconds on my system to run.
DROP TABLE #Demand; DROP TABLE #Supply; DROP TABLE #MyPairings; CREATE TABLE #Demand( ID INT, Quantity DECIMAL(19, 6) NOT NULL, StartValue DECIMAL(19, 6) NOT NULL, EndValue DECIMAL(19, 6) NOT NULL ); CREATE TABLE #Supply( ID INT, Quantity DECIMAL(19, 6) NOT NULL, StartValue DECIMAL(19, 6) NOT NULL, EndValue DECIMAL(19, 6) NOT NULL ); CREATE TABLE #MyPairings ( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19, 6) NOT NULL ); CREATE INDEX xnDemand_Start ON #Demand( StartValue ASC ) INCLUDE( EndValue, ID ); CREATE INDEX xnDemand_End ON #Demand( EndValue DESC) INCLUDE( StartValue, ID ); CREATE INDEX xnSupply_Start ON #Supply( StartValue ASC) INCLUDE( EndValue, ID ); CREATE INDEX xnSupply_End ON #Supply( EndValue DESC) INCLUDE( StartValue, ID ); WITH Demand_Pre AS ( select *, EndValue = SUM(Quantity) OVER(ORDER BY ID) from #Auctions WHERE Code = 'D' ), Demand AS ( SELECT ID, Code, Quantity, StartValue = LAG( EndValue, 1, 0 ) OVER( ORDER BY ID), EndValue FROM Demand_Pre ) INSERT INTO #Demand SELECT ID, Quantity, StartValue, EndValue FROM Demand; WITH Supply_Pre AS ( select *, EndValue = SUM(Quantity) OVER(ORDER BY ID) from #Auctions WHERE Code = 'S' ), Supply AS ( SELECT ID, Code, Quantity, StartValue = LAG( EndValue, 1, 0 ) OVER( ORDER BY ID), EndValue FROM Supply_Pre ) INSERT INTO #Supply SELECT ID, Quantity, StartValue, EndValue FROM Supply; INSERT INTO #MyPairings /* Demand begining at or within a supply */ SELECT D.ID AS DemandID, S.ID AS SupplyID, TradeQuantity = ( CASE WHEN S.EndValue > D.EndValue THEN D.EndValue ELSE S.EndValue END ) - ( CASE WHEN S.StartValue > D.StartValue THEN S.StartValue ELSE D.StartValue END ) FROM #Demand D JOIN #Supply S ON (D.StartValue >= S.StartValue AND D.StartValueD.EndValue THEN D.EndValue ELSE S.EndValue END ) - ( CASE WHEN S.StartValue > D.StartValue THEN S.StartValue ELSE D.StartValue END ) FROM #Demand D JOIN #Supply S ON (D.EndValue > S.StartValue AND D.EndValue <= S.EndValue AND D.StartValueD.EndValue THEN D.EndValue ELSE S.EndValue END ) - ( CASE WHEN S.StartValue > D.StartValue THEN S.StartValue ELSE D.StartValue END ) FROM #Demand D JOIN #Supply S ON (S.StartValue > D.StartValue AND S.StartValue = D.StartValue AND S.EndValue < D.EndValue)last touch – making non-clustered indexes unique for temp tables
This in indeed a very good puzzle, Itzik. But I am betting that I Peter already HAS the fastest solution in his back pocket when he challenges you! :-D
Should you do this in the future, may I suggest that you have the submissions sent in privately? I think them being public could stiffle interest and competition. Few people will choose to submit their solution if it does not beat the current fastest. Some/many may not even give it a go once a very fast set-based solution is posted.
Hi Kevin,
To me, with this puzzle the goal is for the community to join forces in attempt to find an optimal solution for this common need. Even though there's always a sense of competition with any puzzle, I see it as the less important thing here. So I actually think that people posting their solutions publicly enables sharing of ideas.
I think there's a problem with the statement provided to verify solutions. It does not find all discrepancies in result sets. It does not catch cases where rows in #PairingsCursor are missing from #MyPairings. It also provides only half of the information when rows are different.
Check this out…
If you go through the SELECT statements you will see what's happening. I added parentheses to the last three statements to obtain the results that I believe were intended.
Personally, I prefer to use a FULL JOIN to compare result sets. It provides more information and it's more flexible. The SQL statements above do not tell you whether a returned row is a missing row or an extra row. The SQL statements below make it much more clear. They also make it easier to find different data for the same key (see the last SQL statement).
SELECT W.* , X.* FROM #W AS W FULL JOIN #X AS X ON W.ID = X.ID AND W.Value = X.Value WHERE W.Value IS NULL OR X.Value IS NULL ORDER BY W.ID , X.ID; SELECT W.* , Y.* FROM #W AS W FULL JOIN #Y AS Y ON W.ID = Y.ID AND W.Value = Y.Value WHERE W.Value IS NULL OR Y.Value IS NULL ORDER BY W.ID , Y.ID; SELECT W.* , Z.* FROM #W AS W FULL JOIN #Z AS Z ON W.ID = Z.ID AND W.Value = Z.Value WHERE W.Value IS NULL OR Z.Value IS NULL ORDER BY W.ID , Z.ID; SELECT W.* , Z.* FROM #W AS W FULL JOIN #Z AS Z ON W.ID = Z.ID WHERE W.Value IS NULL OR Z.Value IS NULL OR W.Value != Z.Value ORDER BY W.ID , Z.ID;Hi Brian,
That's a very nice catch! :) I was missing parentheses. The correct code for a symmetric difference is:
The first pair of parentheses is not required, but still good to have for clarity. The second pair is of course the important thing to get the right meaning.
Assuming that #PairingsCursor does have the correct result, if this query returns an empty set, the solution's result set is correct. If this query produces a nonempty set, there's a problem with the solution.
I updated the article's query to include the parentheses.
As for the information that this query provides versus the full outer join query, you're right the the latter gives you more info when the result is incorrect. Still, the symmetric difference is sufficient if all you need to know is whether the result is correct or not.
Thanks for catching this!
Hello Kevin.
I first approached Itzik with my rewrite of the old code I found in a database. It was not a good performance but still better than the original.
I asked him if he knew about a general algoritm for this, and Itzik sent back a nice working query.
Then I had an epiphany and came up with my newest query and sent that back. Itzik spotted an edge case bug and added a filter criteria.
The idea of this article grew and here we are!
Hi Itzik,
I blogged about one possible solution here: https://www.erikdarlingdata.com/sql-server/using-batch-mode-for-the-matching-supply-with-demand-challenge/
Thanks for posting this!
I submitted a comment about 15 hours ago. The website did not act quite right and I'm not sure the submission happened correctly. I cannot submit the comment again because the website sees it as a duplicate. Have you seen my submission?
Solution from Brian Walker:
"I suggested using FULL JOIN for comparing result sets in my comment yesterday. In more than 20 years of working with SQL Server, I do not recall ever using FULL JOIN for any other purpose… until now. Here's my submission for this challenge. The approach is different from the other submissions.
NOTE: The warning about null values being eliminated by an aggregate is very expected. The warning can be disabled, or I could avoid it in the SQL code, but I did not do either for this purpose."
Itzik – Thank you very much for posting the submission on my behalf!
I should have thought of doing a link – http://www.wingenious.com/Challenge.txt
This proposed solution is different because there are no intervals and no temporary tables. The SQL code is relatively short and it's very fast.
Brian Walker you made my day. Brilliant FULL JOIN ing and walking between Demand Or Supply with LEAD. Great.
Luca – Thanks!
Hello,
this is not meant as a solution, also it is DB2. I would just like to know if it could be seen as valid set-based and hopefully get some comment.
with auctions (id,code,qty) as (values (1, 'D', 5.0),(2, 'D', 3.0),(3, 'D', 8.0), (5, 'D', 2.0),(6, 'D', 8.0),(7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0),(2000, 'S', 6.0), (3000, 'S', 2.0),(4000, 'S', 2.0), (5000, 'S', 4.0),(6000, 'S', 3.0), (7000, 'S', 2.0) ), demands (drn,did,dqty) as ( select row_number() over (order by id), id, qty from auctions where code = 'D' ), supplies (srn,sid,sqty) as ( select row_number() over (order by id), id, qty from auctions where code = 'S' ), dist (asrn,asid,asqty,adrn,adid,adqty,moved,sts) as ( values (0, 0, 0.0, 0, 0, 0.0, 0.0, cast('next_both' as varchar(20)) ) union all select srn, sid, case when sqty > dqty then sqty - dqty else 0 end, drn, did, case when sqty < dqty then dqty - sqty else 0 end, case when sqty > dqty then dqty when dqty > sqty then sqty else dqty end, case when sqty = dqty then 'next_both' when sqty < dqty then 'next_supply' else 'next_demand' end from dist,supplies,demands where asrn + 1 = srn and adrn + 1 = drn and sts = 'next_both' union all select asrn, asid, case when asqty > dqty then asqty - dqty else 0 end, drn, did, case when asqty < dqty then dqty - asqty else 0 end, case when asqty > dqty then dqty when dqty > asqty then asqty else dqty end, case when asqty = dqty then 'next_both' when asqty < dqty then 'next_supply' else 'next_demand' end from dist,demands where adrn + 1 = drn and sts = 'next_demand' union all select srn, sid, case when sqty > adqty then sqty - adqty else 0 end, adrn, adid, case when sqty < adqty then adqty - sqty else 0 end, case when sqty > adqty then adqty when adqty > sqty then sqty else adqty end, case when sqty = adqty then 'next_both' when sqty < adqty then 'next_supply' else 'next_demand' end from dist,supplies where asrn + 1 = srn and sts = 'next_supply' ) select asid as supply_id, adid as demand_id, moved as quantity from dist where asrn > 0 order by asrnHi Itzik,
Here's my attempt:
DROP TABLE IF EXISTS #PairingsCursor2; CREATE TABLE #PairingsCursor2 ( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL ); GO INSERT #PairingsCursor2 WITH (TABLOCK) ( DemandID, SupplyID, TradeQuantity ) SELECT Q3.DemandID, Q3.SupplyID, Q3.TradeQuantity FROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity = -- Interval overlap CASE WHEN Q2.Code = 'S' THEN CASE WHEN Q2.CumDemand >= Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumDemand > Q2.IntStart THEN Q2.CumDemand - Q2.IntStart ELSE 0.0 END WHEN Q2.Code = 'D' THEN CASE WHEN Q2.CumSupply >= Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumSupply > Q2.IntStart THEN Q2.CumSupply - Q2.IntStart ELSE 0.0 END END FROM ( SELECT Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID = MAX(IIF(Q1.Code = 'D', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), SupplyID = MAX(IIF(Q1.Code = 'S', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumSupply = SUM(IIF(Q1.Code = 'S', Q1.IntLength, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumDemand = SUM(IIF(Q1.Code = 'D', Q1.IntLength, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING) FROM ( -- Demand intervals SELECT A.ID, A.Code, IntStart = SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A.Quantity, IntEnd = SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength = A.Quantity FROM dbo.Auctions AS A WHERE A.Code = 'D' UNION ALL -- Supply intervals SELECT A.ID, A.Code, IntStart = SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A.Quantity, IntEnd = SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength = A.Quantity FROM dbo.Auctions AS A WHERE A.Code = 'S' ) AS Q1 ) AS Q2 ) AS Q3 WHERE Q3.TradeQuantity > 0;It’s great to see so many ideas! Keep ‘em coming. I’m going to start exploring solutions next month.
Rainer,
There were too many issues when I tried to convert your code to T-SQL. If you want to provide a working T-SQL version, you can send it to me (itzik at lucient dot com), and I'll be happy to check how it performs.
Daniel,
There seem to be a few issues with your code that prevent it from compiling. Could be the result of some formatting done by the website when you posted the comment. I revised the outer query to use logic similar to that in Kamil's solution, plus I changed the source table name to the one from the challenge. Here's the code after the revision:
DROP TABLE IF EXISTS #Demand, #Supply, #MyPairings; CREATE TABLE #Demand( ID INT, Quantity DECIMAL(19, 6) NOT NULL, StartValue DECIMAL(19, 6) NOT NULL, EndValue DECIMAL(19, 6) NOT NULL ); CREATE TABLE #Supply( ID INT, Quantity DECIMAL(19, 6) NOT NULL, StartValue DECIMAL(19, 6) NOT NULL, EndValue DECIMAL(19, 6) NOT NULL ); CREATE TABLE #MyPairings ( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19, 6) NOT NULL ); CREATE INDEX xnDemand_Start ON #Demand( StartValue ASC ) INCLUDE( EndValue, ID ); CREATE INDEX xnDemand_End ON #Demand( EndValue DESC) INCLUDE( StartValue, ID ); CREATE INDEX xnSupply_Start ON #Supply( StartValue ASC) INCLUDE( EndValue, ID ); CREATE INDEX xnSupply_End ON #Supply( EndValue DESC) INCLUDE( StartValue, ID ); WITH Demand_Pre AS ( select *, EndValue = SUM(Quantity) OVER(ORDER BY ID) from dbo.Auctions WHERE Code = 'D' ), Demand AS ( SELECT ID, Code, Quantity, StartValue = LAG( EndValue, 1, 0 ) OVER( ORDER BY ID), EndValue FROM Demand_Pre ) INSERT INTO #Demand SELECT ID, Quantity, StartValue, EndValue FROM Demand; WITH Supply_Pre AS ( select *, EndValue = SUM(Quantity) OVER(ORDER BY ID) from dbo.Auctions WHERE Code = 'S' ), Supply AS ( SELECT ID, Code, Quantity, StartValue = LAG( EndValue, 1, 0 ) OVER( ORDER BY ID), EndValue FROM Supply_Pre ) INSERT INTO #Supply SELECT ID, Quantity, StartValue, EndValue FROM Supply; INSERT INTO #MyPairings /* Demand begining at or within a supply */ SELECT D.ID AS DemandID, S.ID AS SupplyID, TradeQuantity = ( CASE WHEN S.EndValue > D.EndValue THEN D.EndValue ELSE S.EndValue END ) - ( CASE WHEN S.StartValue > D.StartValue THEN S.StartValue ELSE D.StartValue END ) FROM #Demand D JOIN #Supply S ON D.StartValue >= S.StartValue AND D.StartValue < S.EndValue UNION ALL /* Supply begining within a demand */ SELECT D.ID AS DemandID, S.ID AS SupplyID, TradeQuantity = ( CASE WHEN S.EndValue > D.EndValue THEN D.EndValue ELSE S.EndValue END ) - ( CASE WHEN S.StartValue > D.StartValue THEN S.StartValue ELSE D.StartValue END ) FROM #Demand D JOIN #Supply S ON S.StartValue > D.StartValue AND S.StartValue < D.EndValue;If that's not what you intended, you can send your solution directly to me to itzik at lucient dot com.
Here's Rainer's solution converted from DB2 to T-SQL:
drop table if exists #MyPairings; with demands (drn,did,dqty) as ( select row_number() over (order by id), id, quantity from dbo.Auctions where code = 'D' ), supplies (srn,sid,sqty) as ( select row_number() over (order by id), id, quantity from dbo.Auctions where code = 'S' ), dist (asrn,asid,asqty,adrn,adid,adqty,moved,sts) as ( select cast(0 as bigint), 0, cast(0.0 as decimal(19, 6)), cast(0 as bigint), 0, cast(0.0 as decimal(19, 6)), cast(0.0 as decimal(19, 6)), cast('next_both' as varchar(20)) union all select srn, sid, cast( case when sqty > dqty then sqty - dqty else 0.0 end as decimal(19, 6)), drn, did, cast( case when sqty < dqty then dqty - sqty else 0.0 end as decimal(19, 6)), case when sqty > dqty then dqty when dqty > sqty then sqty else dqty end, cast( case when sqty = dqty then 'next_both' when sqty < dqty then 'next_supply' else 'next_demand' end as varchar(20)) from dist,supplies,demands where asrn + 1 = srn and adrn + 1 = drn and sts = 'next_both' union all select asrn, asid, cast( case when asqty > dqty then asqty - dqty else 0.0 end as decimal(19, 6)), drn, did, cast( case when asqty < dqty then dqty - asqty else 0.0 end as decimal(19, 6)), case when asqty > dqty then dqty when dqty > asqty then asqty else dqty end, case when asqty = dqty then 'next_both' when asqty < dqty then 'next_supply' else 'next_demand' end from dist,demands where adrn + 1 = drn and sts = 'next_demand' union all select srn, sid, cast( case when sqty > adqty then sqty - adqty else 0.0 end as decimal(19, 6)), adrn, adid, cast( case when sqty < adqty then adqty - sqty else 0.0 end as decimal(19, 6)), case when sqty > adqty then adqty when adqty > sqty then sqty else adqty end, case when sqty = adqty then 'next_both' when sqty < adqty then 'next_supply' else 'next_demand' end from dist,supplies where asrn + 1 = srn and sts = 'next_supply' ) select adid as DemandID, asid as SupplyID, moved as TradeQuantity into #MyPairings from dist where asrn > 0;I also posted something but can't see it anymore. Do you have it in the backend?
Hi Charlie,
No, I don't see anything from you. Do you mind posting it again? If you don't see your post, you can email it to me to itzik at lucient dot com.
Just posted again and it seems to have disappeared. Should I email it?
Hi Charlie,
Not sure why your comments keep disappearing. At any rate, I got it via email. Here's Charlie's solution:
OK here we go. I'm doing a fairly simple cross-join of both sides, taking only the values that overlap.
1. Take a running sum of each set of values: the D and the S. Also take a running sum up to but not including the current row.
2. Then join the two together using a standard interval overlap check: End1 > Start2 AND End2 > Start1
3. Then simply take the amount of Quantity which overlaps.
SELECT DemandID = d.ID, SupplyID = s.Id, TradeQuantity = IIF(d.CumeQty > s.CumeQty, s.CumeQty, d.CumeQty) - IIF(d.PrevCumeQty > s.PrevCumeQty, d.PrevCumeQty, s.PrevCumeQty) FROM ( SELECT *, CumeQty = SUM(Quantity) OVER (ORDER BY ID ROWS UNBOUNDED PRECEDING), PrevCumeQty = SUM(Quantity) OVER (ORDER BY ID ROWS UNBOUNDED PRECEDING) - Quantity FROM Auctions d WHERE Code = 'D' ) d JOIN ( SELECT *, CumeQty = SUM(Quantity) OVER (ORDER BY ID ROWS UNBOUNDED PRECEDING), PrevCumeQty = SUM(Quantity) OVER (ORDER BY ID ROWS UNBOUNDED PRECEDING) - Quantity FROM Auctions d WHERE Code = 'S' ) s ON s.CumeQty > d.PrevCumeQty AND d.CumeQty > s.PrevCumeQty;https://dbfiddle.uk/?rdbms=sqlserver_2019&fiddle=bb4d712ff5e0c3241a22fd7a4d798e07
For performance you will probably want an index
Auctions (Code, ID) INCLUDE (Quantity)
You could also calculate PrevCumeQty using ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING, but I found this required an extra Segment / Sequence Project calculation, and also causes complications with nulls on the first row.
Batch mode will obviously improve this even further.
i fairly appreciate the idea of sharing the code and the experience
I think we should maintain this type of collaboration
thanks
I modified Brian Walker's answer to get rid of the full outer join. That's not needed since you can do the same thing by using a case statement and a single pass over the table. This is more efficient and has much nicer query execution plan. The larger the number of rows with supply and demand the more this version out performs the full outer join version. I added a suggested index.
CREATE INDEX NC_AUCTIONS_INCLUDE_QUANTITY ON dbo.Auctions ([Code]) INCLUDE ([Quantity]) GO DROP TABLE IF EXISTS #MyPairings CREATE TABLE #MyPairings ( DemandID int NOT NULL , SupplyID int NOT NULL , TradeQuantity decimal(19,06) NOT NULL ) INSERT #MyPairings ( DemandID , SupplyID , TradeQuantity ) SELECT Z.DemandID , Z.SupplyID , Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0) AS TradeQuantity --, Z.Running --, Z.D_RUNNING --, Z.S_RUNNING FROM ( SELECT case when [Code] = 'D' THEN W.ID ELSE MIN(case when [Code] = 'D' then ID end) OVER (ORDER BY W.Running ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) END AS DemandID , case when [Code] = 'S' THEN W.ID ELSE MIN(case when [Code] = 'S' then ID end) OVER (ORDER BY W.Running ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) END AS SupplyID , W.Running , W.D_RUNNING , W.S_RUNNING FROM ( SELECT Q.*, RUNNING = ISNULL(D_RUNNING, S_RUNNING) FROM ( SELECT A.ID, A.Quantity, A.[Code] , SUM(case when A.Code = 'D' then A.Quantity end) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS D_Running , SUM(case when A.Code = 'S' then A.Quantity end) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS S_Running FROM dbo.Auctions AS A) Q ) AS W ) AS Z WHERE Z.DemandID IS NOT NULL AND Z.SupplyID IS NOT NULLMy previous solution didn't work when there were ties with running totals between demand and supply. Brian Walker's full outer join solves this by joining on the running total thereby handling that case. He really does have the best solution. Brilliant.
Hi Aaron,
Yes, Brian's solution is very impressive, and the outer join part is well thought out!