
Fun with (columnstore) compression on a very large table – part 3
In part 1 of this series, I tried out a few ways to compress a 1TB table. While I got decent results in my first attempt, I wanted to see if I could improve the performance in part 2. There I outlined a few of the things I thought might be performance issues, and laid out how I would better partition the destination table for optimal columnstore compression. I've already:
- partitioned the table into 8 partitions (one per core);
- put each partition's data file on its own filegroup; and,
- set archive compression on all but the "active" partition.
I still need to make it so that each scheduler writes exclusively to its own partition.
First, I need to make changes to the batch table I created. I need a column to store the number of rows added per batch (kind of a self-auditing sanity check), and start/end times to measure progress.
ALTER TABLE dbo.BatchQueue ADD
RowsAdded int,
StartTime datetime2,
EndTime datetime2;
Next, I need to create a table to provide affinity – we don't ever want more than one process running on any scheduler, even if it means losing some time to retry logic. So we need a table that will keep track of any session on a specific scheduler and prevent stacking:
CREATE TABLE dbo.OpAffinity
(
SchedulerID int NOT NULL,
SessionID int NULL,
CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID)
);
The idea is I would have eight instances of an application (SQLQueryStress) that would each run on a dedicated scheduler, handling only the data destined for a specific partition / filegroup / data file, ~100 million rows at a time (click to enlarge):
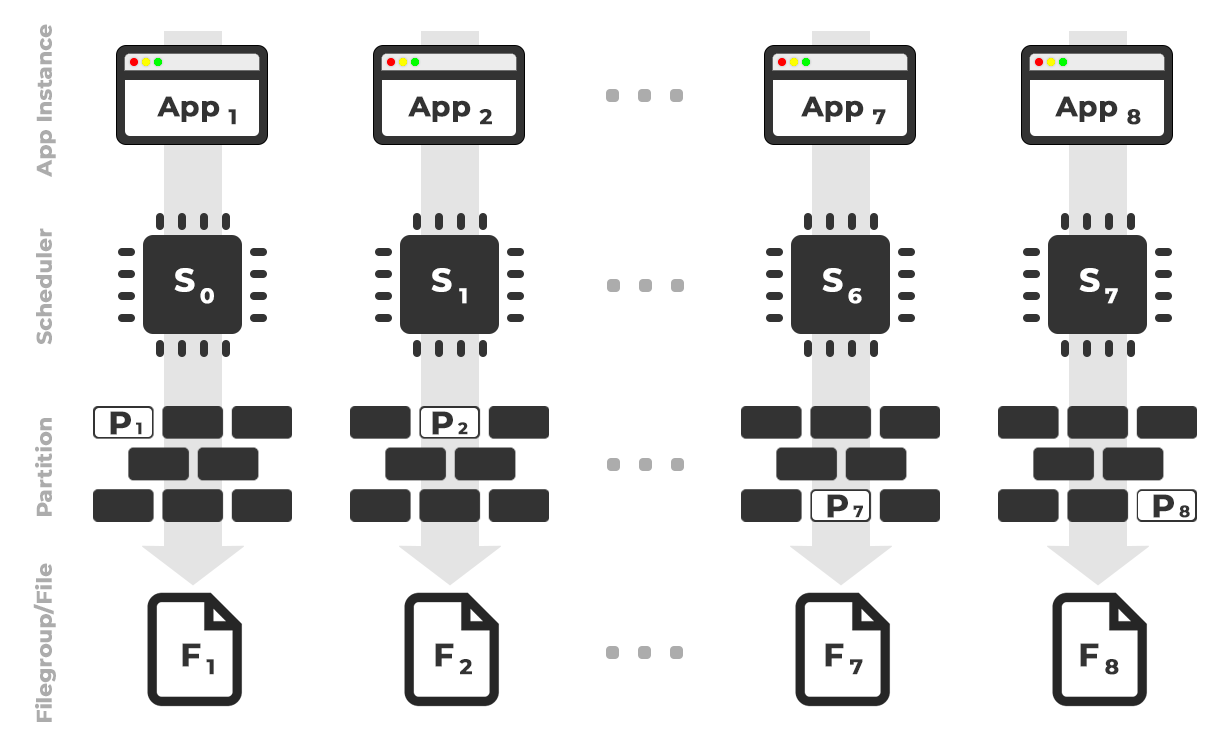 App 1 gets scheduler 0 and writes to partition 1 on filegroup 1, and so on…
App 1 gets scheduler 0 and writes to partition 1 on filegroup 1, and so on…
Next we need a stored procedure that will enable each instance of the application to reserve time on a single scheduler. As I mentioned in a previous post, this is not my original idea (and I would never have found it in that guide if not for Joe Obbish). Here is the procedure I created in Utility:
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END
Simple, right? Fire up 8 instances of SQLQueryStress, and put this batch into each:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1;
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2;
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3;
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Poor man's parallelism
Poor man's parallelism
Except it's not that simple, since scheduler assignment is kind of like a box of chocolates. It took many tries to get each instance of the app on the expected scheduler; I would inspect the exceptions on any given instance of the app, and change the PartitionID to match. This is why I used more than one iteration (but I still only wanted one thread per instance). As an example, this instance of the app was expecting to be on scheduler 3, but it got scheduler 4:
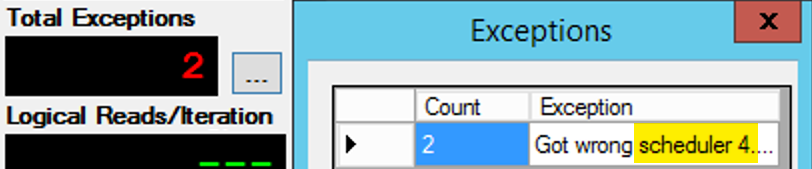 If at first you don't succeed...
If at first you don't succeed...
I changed the 3s in the query window to 4s, and tried again. If I was quick, the scheduler assignment was "sticky" enough that it would pick it right up and start chugging away. But I wasn't always quick enough, so it was kind of like whack-a-mole to get going. I probably could have devised a better retry/loop routine to make the work less manual here, and shortened up the delay so I knew immediately whether it worked or not, but this was good enough for my needs. It also made for an unintentional staggering of start times for each process, another piece of advice from Mr. Obbish.
Monitoring
While the affinitized copy is running, I can get a hint about current status with the following two queries:
If I did everything right, both queries would return 8 rows, and show incrementing logical reads and duration. Wait types will flip around between PAGEIOLATCH_SH, SOS_SCHEDULER_YIELD, and occasionally RESERVED_MEMORY_ALLOCATION_EXT. When a batch was finished (I could review these by uncommenting -- AND EndTime IS NULL, I would confirm that RowsAdded = RowsInRange.
Once all 8 instances of SQLQueryStress were completed, I could just perform a SELECT INTO <newtable> FROM dbo.BatchQueue to log the final results for later analysis.
Other Testing
In addition to copying the data to the partitioned clustered columnstore index that already existed, using affinity, I wanted to try a couple of other things too:
- Copying the data to the new table without trying to control affinity. I took the affinity logic out of the procedure and just left the whole "hope-you-get-the-right-scheduler" thing to chance. This took longer because, sure enough, scheduler stacking did occur. For example, at this specific point, scheduler 3 was running two processes, while scheduler 0 was off taking a lunch break:
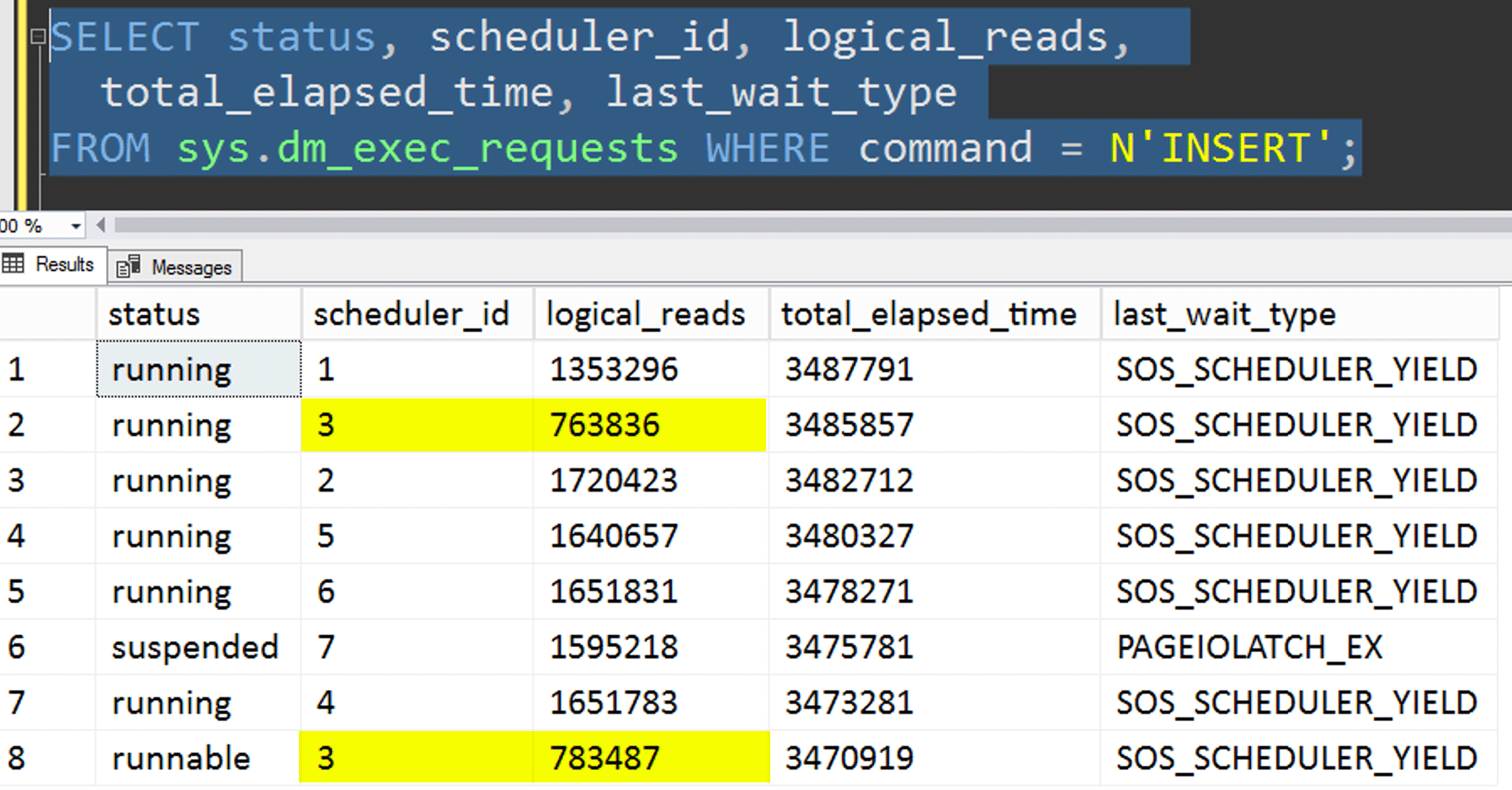 Whither art thou, scheduler number 0?
Whither art thou, scheduler number 0?
- Applying page or row compression (both online/offline) to the source before the affinitized copy (offline), to see if compressing the data first could speed up the destination. Note that the copy could be done online too but, like Andy Mallon's
inttobigintconversion, it requires some gymnastics. Note that in this case we can't take advantage of CPU affinity (though we could if the source table were already partitioned). I was smart and took a backup of the original source, and created a procedure to revert the database back to its initial state. Much faster and easier than trying to revert to a specific state manually.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- And finally, rebuilding the clustered index onto the partition scheme first, then building the clustered columnstore index on top of that. The downside to the latter is that, in SQL Server 2017, you cannot run this online… but you will be able to in 2019.
Here we need to drop the PK constraint first; you can't use
DROP_EXISTING, since the original unique constraint can't be enforced by the clustered columnstore index, and you can't replace a unique clustered index with a non-unique clustered index.Msg 1907, Level 16, State 1
Cannot recreate index 'pk_tblOriginal'. The new index definition does not match the constraint being enforced by the existing index.All these details make this a three-step process, only the second step online. The first step I only explicitly tested
OFFLINE; that ran in three minutes, whileONLINEI stopped after 15 minutes. One of those things that maybe shouldn't be a size-of-data operation in either case, but I'll leave that for another day.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Results
Timings and compression rates:
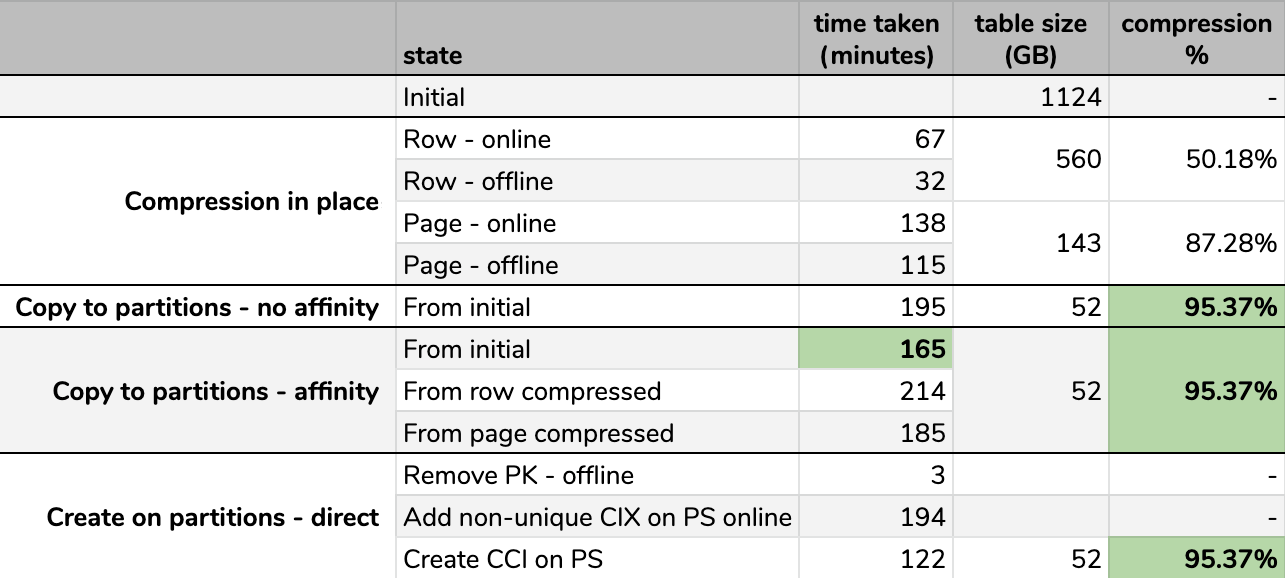 Some options are better than others
Some options are better than others
Note that I rounded to GB because there would be minor differences in final size after every run, even using the same technique. Also, the timings for the affinity methods were based on the average individual scheduler/batch runtime, since some schedulers finished faster than others.
It's hard to envision an exact picture from the spreadsheet as shown, because some tasks have dependencies, so I'll try to display the info as a timeline and show how much compression you get compared to the time spent:
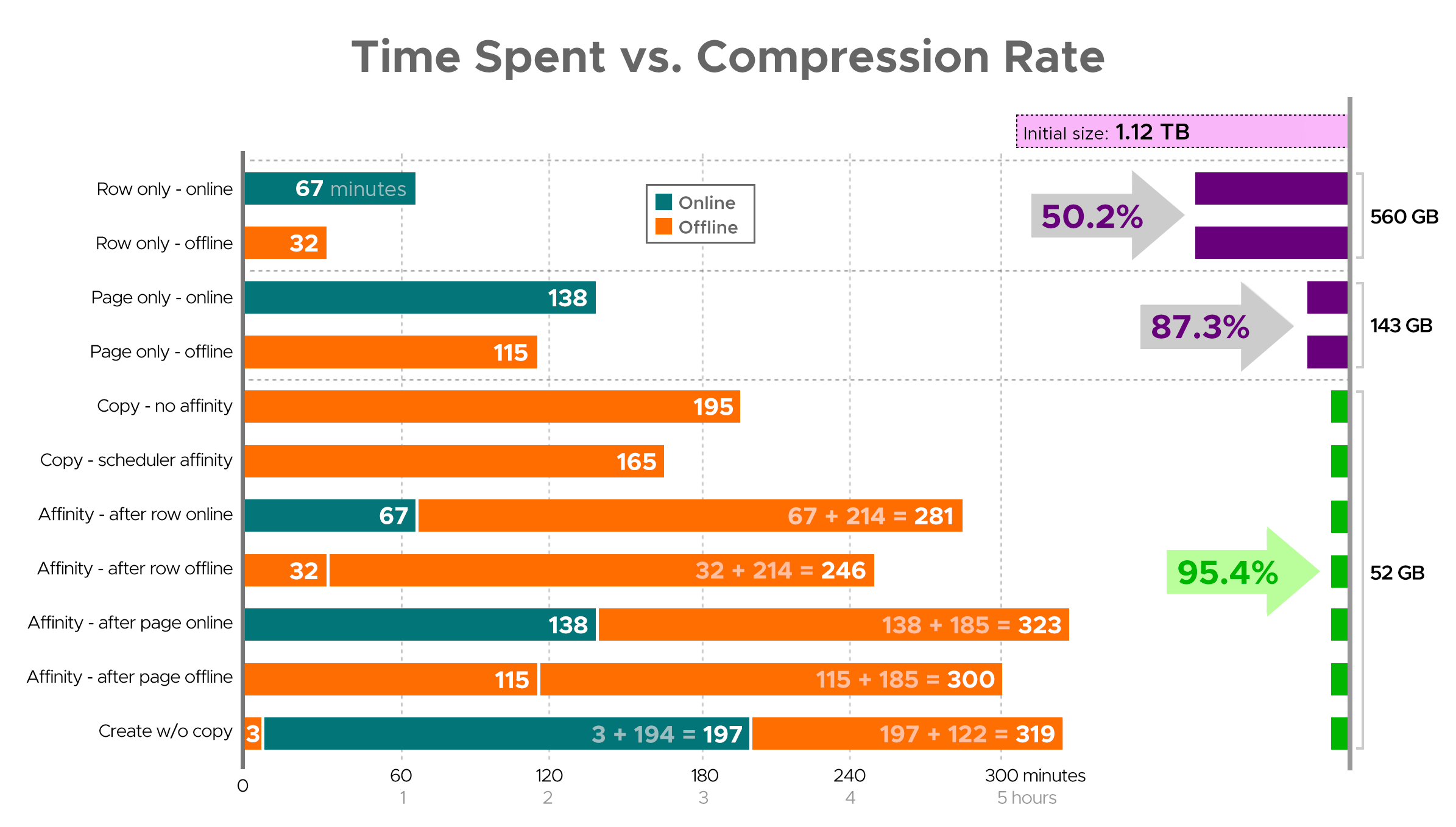 Time spent (minutes) vs. compression rate
Time spent (minutes) vs. compression rate
A few observations from the results, with the caveat that your data may compress differently (and that online operations only apply to you if you use Enterprise Edition):
- If your priority is to save some space as quickly as possible, your best bet is to apply row compression in place. If you want to minimize disruption, use online; if you want to optimize speed, use offline.
- If you want to maximize compression with zero disruption, you can approach 90% storage reduction without any disruption at all, using page compression online.
- If you want to maximize compression and disruption is okay, copy the data to a new, partitioned version of the table, with a clustered columnstore index, and use the affinity process described above to migrate the data. (And again, you can eliminate this disruption if you are a better planner than me.)
The final option worked best for my scenario, though we'll still have to kick the tires on the workloads (yes, plural). Also note that in SQL Server 2019 this technique may not work so well, but you can build clustered columnstore indexes online there, so it may not matter as much.
Some of these approaches may be more or less acceptable to you, because you may favor "staying available" over "finishing as quickly as possible," or "minimizing disk usage" over "staying available," or just balancing read performance and write overhead.
If you want more details on any aspect of this, just ask. I trimmed some of the fat to balance detail with digestibility, and I've been wrong about that balance before. A parting thought is that I'm curious how linear this is – we have another table with a similar structure that is over 25 TB, and I'm curious if we can make some similar impact there. Until then, happy compressing!
1 thought on “Fun with (columnstore) compression on a very large table – part 3”
Comments are closed.

Aaron, a nice Part 4 might be an issue ive run into when considering Columnstore. I know Sunil and his team have spent almost 10 years perfecting this tech, and its is amazing on DW queries, but one thing ive noticed is that CS often is WAYYYY slower and takes much more time to first row than rowstore for many workloads.
Just a thought