
Fun with (columnstore) compression on a very large table – part 1
Recently someone at work asked for more space to accommodate a rapidly growing table. At the time it had 3.75 billion rows, presented on 143 million pages, and occupying ~1.14TB. Of course we can always throw more disk at a table, but I wanted to see if we could scale this more efficiently than the current linear trend. Sounds like a great job for compression, right? But I also wanted to try out some other solutions, including columnstore – which people are surprisingly reluctant to try. I am no Niko, but I wanted to make an effort to see what it could do for us here.
Note that I am not focusing on reporting workload or other read query performance at this time – I merely want to see what impact I can have on storage (and memory) footprint of this data.
Here is the original table. I've changed table and column names to protect the innocent, but everything else is relatively accurate.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);There are some other little things in there that are wider than they should be and/or that row compression might clean up, like those numeric(24,12) and bigint columns that may be prematurely oversized, but I'm not going to go back to the application team and figure out if there are little efficiencies there, and I'm going to skip row compression for this exercise and focus on page and columnstore compression.
This is a copy of the data, on an idle server (8 cores, 64GB RAM), with plenty of disk space (well over 6TB). So first, let's add a couple of filegroups, one for standard clustered columnstore, and one for a partitioned version of the table (where all but the most recent partition will be compressed with COLUMNSTORE_ARCHIVE, since all of that older data is now "read only and infrequently"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI;
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;And then some files for these filegroups (one file per core, nice and uniformly sized at 256GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000,
filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI;
-- ... 6 more ...
ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000,
filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI;
ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000,
filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
-- ... 6 more ...
ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000,
filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;On this particular hardware (YMMV!), this took about 10 seconds per file, and yielded the following:

To generate the partitions, I naïvely divided the data up "evenly" – or so I thought. I just took the 3.75 billion rows and partitioned into something that I thought would be manageable: 38 partitions with 100 million rows in the first 37 partitions, and the remainder in the last one. (Remember, this is just part 1! There is an inherent assumption here about even distribution of values in the source table, and also around what is optimal for rowgroup population in the destination table.) Creating the partition schema and function for this is as follows:
CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000);
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);I use RANGE LEFT because, as Cathrine Wilhelmsen continues to help remind me, this means that the boundary value is a part of the partition to its left. In other words, the values I am specifying are the max values in each partition (with dates, you usually want RANGE RIGHT).
I then created two copies of the table, one on each filegroup. The first one had a standard clustered columnstore index, the only differences being the OID column is not an IDENTITY and the computed column is just a varbinary(8000):
CREATE TABLE dbo.tblCCI
(
OID bigint NOT NULL,
-- ... other columns ...
) ON FG_CCI;
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX
ON dbo.tblCCI;The second one was built on the partition scheme, so needed a named PK first, which then had to be replaced by a clustered columnstore index (though Brent Ozar shows in this brief post that there is some unintuitive syntax that will accomplish this in fewer steps):
CREATE TABLE dbo.tblCCI_Partitioned
(
OID bigint NOT NULL,
-- ... other columns ...,
CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID)
);
GO
ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part;
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part
ON dbo.tblCCI_Partitioned
ON PS_OID (OID);Then, in order to put archive compression on all but the last partition, I ran the following:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
);Now, I was ready to populate these tables with data, measure the time taken and the resulting size, and compare. I modified a helpful batching script from Andy Mallon, and inserted the rows into both tables sequentially, with a batch size of 10 million rows. There's a lot more to it than this in the real script (including updating a queue table with progress), but basically:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
ENDAfter I populated both columnstore tables from the original (uncompressed) source, I rebuilt those partitions again to clean up any rowgroup and dictionary mess. Finally, I applied page compression, in place, to the source table. Here were the timings and the compression results of each type:
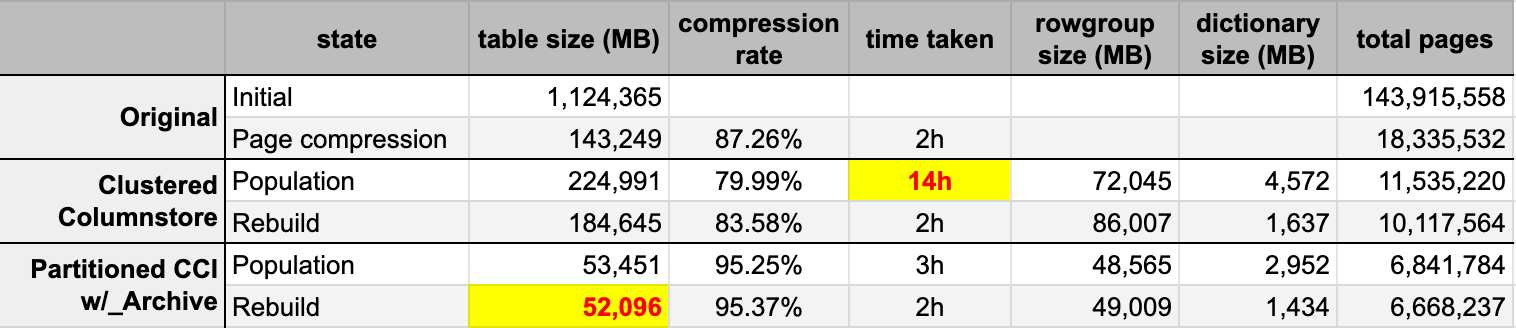
I'm both impressed and disappointed. Impressed because this data compresses really well - shrinking the storage footprint down to 5% of the original 1TB is kind of amazing. Disappointed because:
- I made those data files way too big.
- I don't understand what happened with the 14 hour initial columnstore compression:
- I didn't observe any memory or log pressure.
- There were no file growth events.
- Unfortunately, I didn't think to track waits. No, I'm not going to try it again. :-)
- Page compression outperformed regular columnstore compression - perhaps due to the data.
- Rebuilding the columnstore archive partitions used up a lot of CPU time for almost zero gain.
In forthcoming posts, and after reviewing my notes from an amazing columnstore presentation by Joe Obbish at PASS Summit (which I'd link to directly, if only PASS knew how to UI), I'll talk a little about the changes I'll make to the server configuration and my population script to see if I can get better performance from the columnstore population.
