
Fun with (columnstore) compression on a very large table – part 2
In part 1, I showed how both page and columnstore compression could reduce the size of a 1TB table by 80% or more. While I was impressed I could shrink a table from 1TB to 50GB, I wasn't very happy with the amount of time it took (anywhere from 2 to 14 hours). With some tips graciously borrowed from folks like Joe Obbish, Lonny Niederstadt, Niko Neugebauer, and others, in this post I will try to make some changes to my original attempt to get better load performance. Since the regular columnstore index didn't compress better than page compression on this data set, and took 13 hours longer to get there, I'll focus solely on the more advanced solution using COLUMNSTORE_ARCHIVE compression.
Some of the issues that I think affected performance include the following:
- Bad file layout choices – I put 8 files in one filegroup, with parallelism but no (or suboptimal) partitioning, spraying I/Os across multiple files with reckless abandon. To address this, I will:
- partition the table into 8 partitions (one per core)
- put each partition's data file on its own filegroup
- use 8 separate processes to affinitize to each partition
- use archive compression on all but the "active" partition
- too many small batches and sub-optimal rowgroup population – by processing 10 million rows at a time, I was populating nine rowgroups with a nice, 1,048,576 rows, and then the remaining 562,816 rows would end up in another smaller rowgroup. And any uneven distributions which left a remainder < 102,400 rows would trickle inserts into the less efficient delta store structure. To distribute rows more uniformly and avoid delta store, I will:
- process as much of the data as possible in exact multiples of 1,048,576 rows
- spread those across 8 partitions as evenly as possible
- use a batch size closer to 10x -> 100 million rows
- scheduler stacking – while I didn't check for this, it's possible that some of the slowdown was caused by one scheduler taking on too much work and another scheduler not enough, due to scheduler round-robining. Now that I will be intentionally loading the data with 8 maxdop 1 processes instead of one maxdop 8 process, to keep all the schedulers equally busy, I will:
- use a stored procedure that attempts to balance evenly across schedulers (see pages 189-191 in SQLCAT's Guide to: Relational Engine for the inspiration behind this idea)
- enable global trace flag 2467 and 2469, as cautioned against in the documentation
- background columnstore compression task – it was wasteful to allow this to run during population, since I planned to rebuild at the end anyway. This time I will:
- disable this task using global trace flag 634
I scrapped the initial partition function and scheme, and built a new one based on a more even distribution of the data. I want 8 partitions to match the number of cores and the number of data files, to maximize the "poor man's parallelism" I plan to use.
First, we need to create a new set of filegroups, each with its own file:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1;
ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000,
filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1;
-- ... 6 more ...
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8;
ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000,
filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
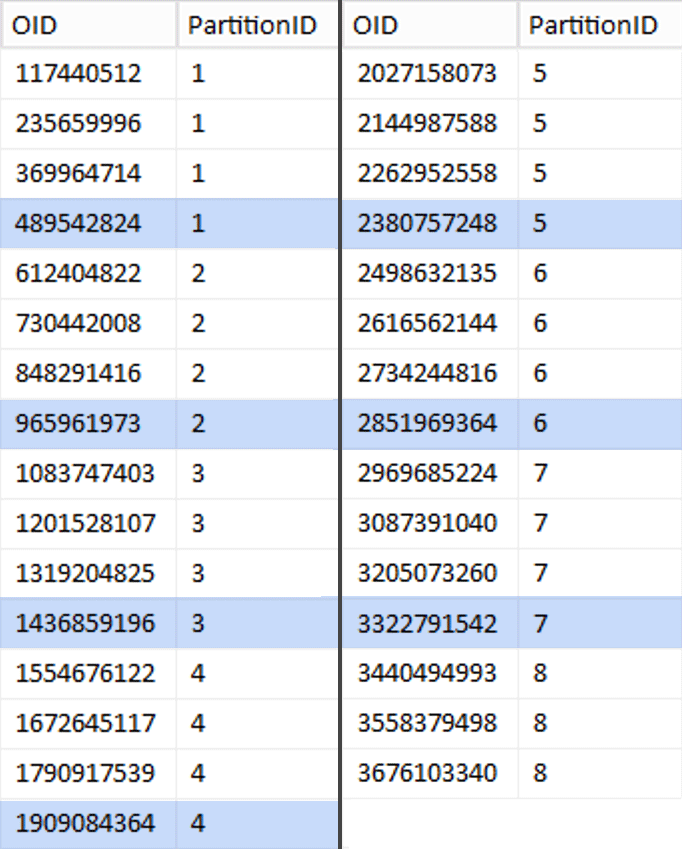
Next, I looked at the number of rows in the table: 3,754,965,954. To distribute those exactly evenly across 8 partitions, that would be 469,370,744.25 rows per partition. To make it work nicely, let's make the partition boundaries accommodate the next multiple of 1,048,576 rows. This is 1,048,576 x 448 = 469,762,048 – which would be the number of rows we shoot for in the first 7 partitions, leaving 466,631,618 rows in the last partition. To see the actual OID values that would serve as boundaries to contain the optimal number of rows in each partition, I ran this query against the original table (since it took 25 minutes to run, I quickly learned to dump these results into a separate table):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
 More to unpack here than you might expect. The CTE does all the heavy lifting, since it has to scan the entire 1.14TB table and assign a row number to every row. I only want to return every
More to unpack here than you might expect. The CTE does all the heavy lifting, since it has to scan the entire 1.14TB table and assign a row number to every row. I only want to return every (1048576*112)th row, though, as these are my batch boundary rows, so this is what the WHERE clause does. Remember that I want to split the work into batches closer to 100 million rows at a time, but I also don't really want to process 469 million rows in one shot. So in addition to splitting the data up into 8 partitions, I want to split up each of those partitions into four batches of 117,440,512 (1,048,576*112) rows. Each adjacent set of four batches belongs to one partition, so the PartitionID I derive just adds one to the result of the current row number integer divided by (1,048,576*448), which ensures that the boundary is always in the "left" set. We then add one to the result because otherwise we'd be referring to a 0-based collection of partitions, and nobody wants that.
Ok, that was a lot of words. At right is a picture showing the (abbreviated) contents of the stage table (click to show the full result, highlighting partition boundary values).
We can then derive another query from that staging table that shows us the min and max values for each batch inside of each partition, as well as the extra batch not accounted for (the rows in the original table with OID larger than the highest boundary value):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID);
Those values look like this:

To test our work, we can derive from there a set of queries that will update BatchQueue with actual rowcounts from the table.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql;
This took about 6 minutes on my system. Then you can run the following query to show that every batch except the very last one is capable of fully populating rowgroups and leaving no remainder for potential delta store usage:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Now the table looks like this:
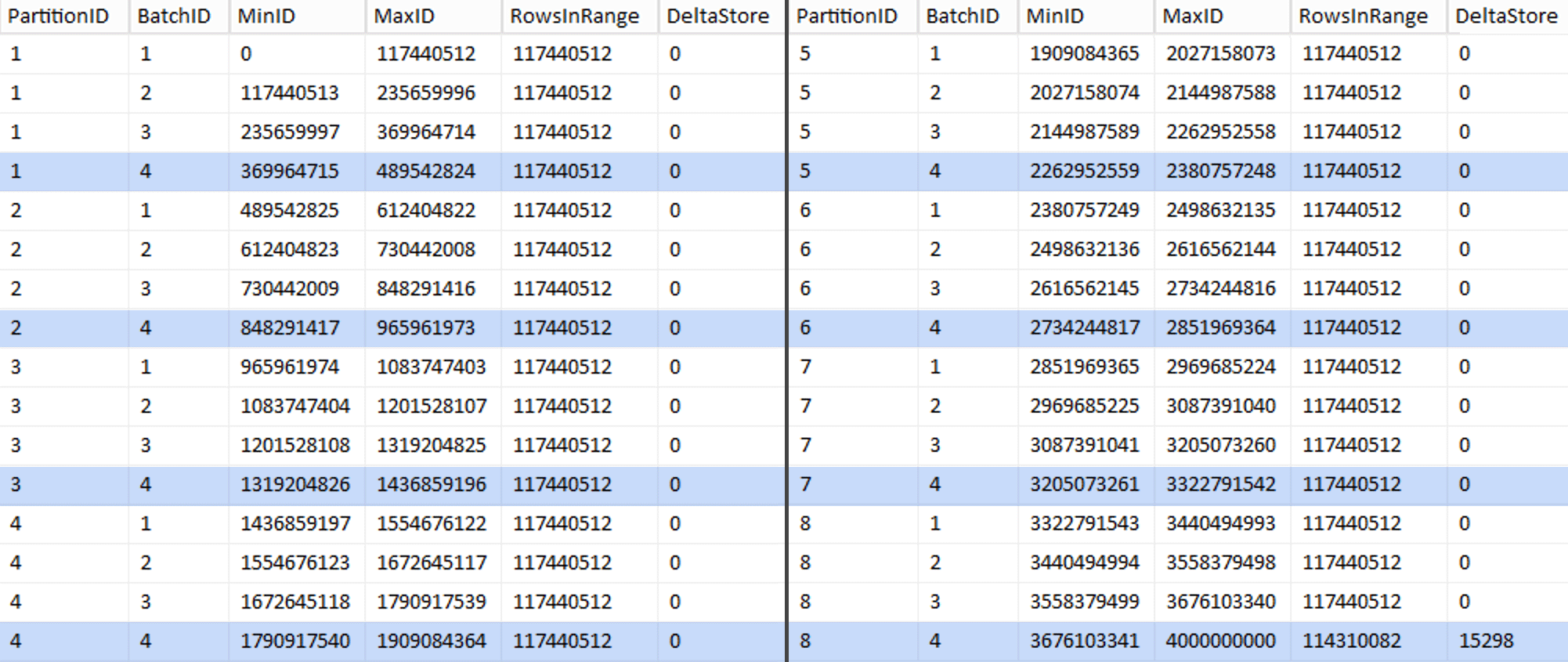
Sure enough, every batch has the calculated 117,440,512 million rows, except for the last one which will, at least ideally, contain our only uncompressed delta store. We can probably prevent this too, by changing the batch size just slightly for this partition so that all four batches are run with the same size, or by changing the number of batches to accommodate some other multiple of 102,400 or 1,048,576. Since that would require getting new OID values from the base table, adding another 25 minutes plus to our migration effort, I'm going to let this one imperfect partition slide — especially since we're not getting the full archival compression benefit from it anyway.
The BatchQueue table is starting to show signs of being useful for processing our batches to migrate data to our new, partitioned, clustered columnstore table. Which we need to create, now that we know the boundaries. There are only 7 boundaries, so you could certainly do this manually, but I like to make dynamic SQL do my work for me:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql;
Results:
CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
489542824,
965961973,
1436859196,
1909084364,
2380757248,
2851969364,
3322791542
);
Once that's created, we can create our partition scheme and assign each successive partition to its dedicated file:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO
(
CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4,
CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8
);
Now we can create the table and get it ready for migration:
CREATE TABLE dbo.tblPartitionedCCI
(
OID bigint NOT NULL,
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 varbinary(8000) NULL,
IN6 int NULL,
IN7 int NULL,
IN8 int NULL,
-- need to create a PK constraint on the partition scheme...
CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID)
);
-- ... only to drop it immediately...
ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part;
GO
-- ... so we can replace it with the CCI:
CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part
ON dbo.tblPartitionedCCI
ON PS_OID(OID);
GO
-- now rebuild with the compression we want:
ALTER TABLE dbo.tblPartitionedCCI
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7),
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8)
);
In Part 3, I'll further configure the BatchQueue table, build a procedure for processes to push the data to the new structure, and analyze the results.
