
Introduction to Wait Statistics
Back in 2014, I started a series of blog posts here to talk about specific wait types and what they do and don’t mean. That gave me the idea to create the wait and latches libraries that I maintain (more on these later).
If you’re reading this and thinking “what is he talking about?” then this post is for you. I’m going to introduce you to wait statistics and explain how critical they are for troubleshooting workload performance in SQL Server.
Scheduling
The execution of SQL Server’s internal code is done using a mechanism called threads. Each thread can be executing SQL Server code, and multiple threads coordinate together when a query runs in parallel. These threads are created when SQL Server starts, depending on the number of processor cores available for SQL Server to use.
Threads are placed on a scheduler when a query starts, with one scheduler per processor core, and don’t move off that scheduler until the query has finished. A scheduler has three basic ‘parts’:
- The processor, which has exactly one thread currently executing code.
- The waiter list, which has all the threads that are basically stuck, waiting for a particular resource to become available.
- The runnable queue, which has all the threads that are able to execute but are waiting to get on the processor.
Threads transition from state 1 to 2 to 3 to 1, around and around until the query has finished.
Waits
From our perspective, the most interesting part of scheduling is when a thread has to wait for a resource before it can continue. Some examples of this are:
- A thread needs to read a page, and the page isn’t in memory, so the thread issues an asynchronous physical I/O and then has to wait, off the processor, until the I/O completes.
- A thread needs to acquire a share lock on a row to read it, but another thread already holds a conflicting exclusive lock while it is updating the row.
When a thread encounters the need for a resource that it cannot get, it has no choice but to stop and wait for the resource to become available (the mechanism for how the thread is notified about resource availability is beyond the scope of this article). When that happens, SQL Server makes a note of why the thread had to wait and this is called the wait type. Some examples of this are:
- When a thread is waiting for a page to be read into memory so it can be read, the wait type is PAGEIOLATCH_SH (if the thread is waiting for a page that it will change, the wait type is PAGEIOLATCH_EX).
- When a thread is wait for a share lock on a row, the wait type is LCK_M_S (lock-mode-share)
SQL Server also keeps track of how long the thread has to wait. This is called the resource wait time, and is usually just known as the wait time.
Wait Statistics
The overall set of metrics of how many threads have waited for which resources and for how long on average is called wait statistics. This information is extremely useful for troubleshooting workload performance, as you can easily see where performance bottlenecks might be.
The basic idea is that SQL Server has the information on why threads have to stop and wait, and what they’re waiting for. So rather than having to guess at where to start troubleshooting, careful analysis of wait statistics can usually point you in a direction to take.
For instance, if the majority of waits on the server are PAGEIOLATCH_SH, this may indicate that there is memory pressure on the server, or that there are queries doing large table scans instead of using nonclustered indexes, or that there’s an issue with the underlying I/O subsystem, or a number of other reasons.
There are a large number of wait types but most of them don’t crop up very often, so there’s a core set that you’ll see over and over on your servers. Understanding what these mean and how to investigate them is critical so you don’t succumb to what I call ‘knee-jerk performance tuning’ and waste time and effort trying to fix a problem that isn’t actually a problem. I wrote a series of blog posts here that go into details there, and Aaron Bertrand also wrote a summary post of the top 10 wait statistics last year.
Tracking Waits
There are number of ways that you can track waits. The simplest is to look at what waits are occurring on the server right now, using a script that examines the sys.dm_os_waiting_tasks DMV. You can find a script to do that here, and that has auto-generated URLs into the wait library.
Another way is to look at the aggregate wait statistics for the whole server, with a script that examins the sys.dm_os_wait_stats DMV. You can find a script to do that here, and that has auto-generated URLs into the wait library. You need to be careful with that method though, as that will show all the waits that have occurred since the server started. A better way is to track waits over small intervals, say half an hour, and a script to do that is here.
You can also get wait statistics using the Server Reports add-in to the new Azure Data Studio tool, and using Query Store from SQL Server 2017 onwards.
Remember, you still need to understand what the wait types mean once you’ve collected the metrics.
Waits Resources
To help with this, and because Microsoft does not have documentation on how to interpret wait statistics, back in 2016 I released a wait type library, with details of hundreds of common wait types and how to troubleshoot them. You can get to the library at https://www.SQLskills.com/help/waits. And then in 2017, SentryOne created an automated system to provide an infographic for each page in the library that you can quickly use to see whether the wait type you’re interested in is a really common one or not (see this post for details). An example infographic is below, for the PAGEIOLATCH_SH wait type:
On the horizontal axis is a scale (switchable between linear and logarithmic) of what percentage of instances (monitored remotely by SentryOne) experienced this wait over the previous calendar month, and on the vertical axis is the percentage of time that those instances that experienced that wait actually had a thread waiting for that wait type.
One other resource for helping you understand waits is an online training course I recorded for Pluralsight – see here.
At the very least, you should read through the various blog posts in the Wait Statistics and Tracking Waits sections above.
Tracking Waits Using SentryOne Tools
SQL Sentry tracks instance-level waits for you automatically over time, so you don't have to catch high waits "in the act." Someone complained about a sluggish system yesterday afternoon or a report that timed out last Tuesday? No problem. You can dig into all the waits for any point in time or over a range, and correlate them with various other performance metrics collected at the time – be it other trends on the dashboard, like backup or database I/O activity, jumping to all the Top SQL commands that were running in the same window, investigating long-running blocking, or use baselines to compare the waits profile to other periods.
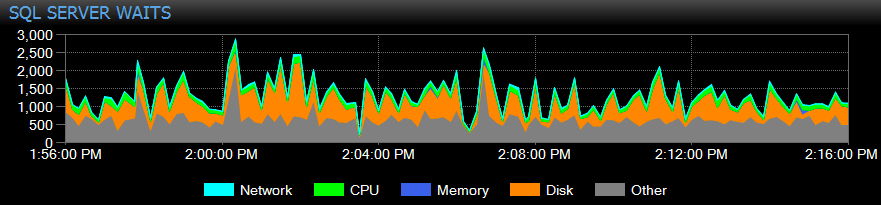
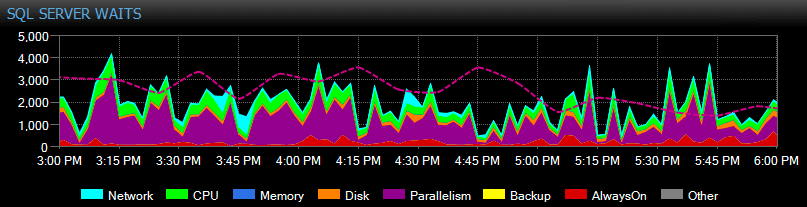
You can even customize waits that are or are not collected, change the categories that are presented visually, and build intelligent alerting and/or responses to specific wait scenarios. Many of our customers use SQL Sentry to focus on real performance issues relating to waits, since it allows them to ignore a lot of the noise that is just normal SQL Server thread activity.
Summary
As you can see from the information above, waits always happen in SQL Server, because that’s just how thread scheduling and multi-threaded systems work. They’re one of the most powerful tools in your troubleshooting toolbox, so if you’re not already using them, now is the time to start. The learning curve is short and steep – once you’ve run the various queries and tools a few times, you’ll quickly get the hang of it, and then it’s a case of reading through the guides for the waits you’re seeing and determining if they’re a problem of not.
Happy troubleshooting!
