
Performance Surprises and Assumptions : GROUP BY vs. DISTINCT
Last week, I presented my T-SQL : Bad Habits and Best Practices session during the GroupBy conference. A video replay and other materials are available here:
One of the items I always mention in that session is that I generally prefer GROUP BY over DISTINCT when eliminating duplicates. While DISTINCT better explains intent, and GROUP BY is only required when aggregations are present, they are interchangeable in many cases.
Let's start with something simple using Wide World Importers. These two queries produce the same result:
SELECT DISTINCT Description FROM Sales.OrderLines;
SELECT Description FROM Sales.OrderLines GROUP BY Description;And in fact derive their results using the exact same execution plan:

Same operators, same number of reads, negligible differences in CPU and total duration (they take turns "winning").
So why would I recommend using the wordier and less intuitive GROUP BY syntax over DISTINCT? Well, in this simple case, it's a coin flip. However, in more complex cases, DISTINCT can end up doing more work. Essentially, DISTINCT collects all of the rows, including any expressions that need to be evaluated, and then tosses out duplicates. GROUP BY can (again, in some cases) filter out the duplicate rows before performing any of that work.
Let's talk about string aggregation, for example. While in SQL Server v.Next you will be able to use STRING_AGG (see posts here and here), the rest of us have to carry on with FOR XML PATH (and before you tell me about how amazing recursive CTEs are for this, please read this post, too). We might have a query like this, which attempts to return all of the Orders from the Sales.OrderLines table, along with item descriptions as a pipe-delimited list:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description
FROM Sales.OrderLines
WHERE OrderID = o.OrderID
FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'')
FROM Sales.OrderLines AS o;This is a typical query for solving this kind of problem, with the following execution plan (the warning in all of the plans is just for the implicit conversion coming out of the XPath filter):
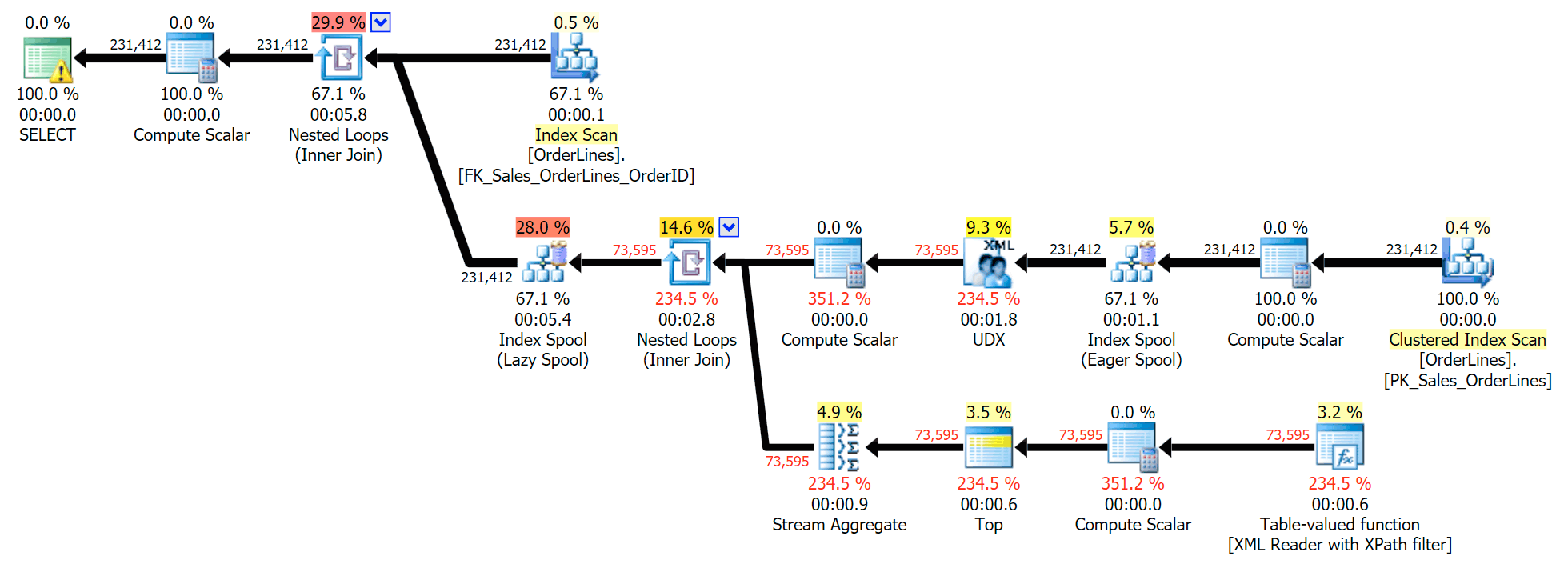
However, it has a problem that you might notice in the output number of rows. You can certainly spot it when casually scanning the output:

For every order, we see the pipe-delimited list, but we see a row for each item in each order. The knee-jerk reaction is to throw a DISTINCT on the column list:
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description
FROM Sales.OrderLines
WHERE OrderID = o.OrderID
FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'')
FROM Sales.OrderLines AS o;That eliminates the duplicates (and changes the ordering properties on the scans, so the results won't necessarily appear in a predictable order), and produces the following execution plan:
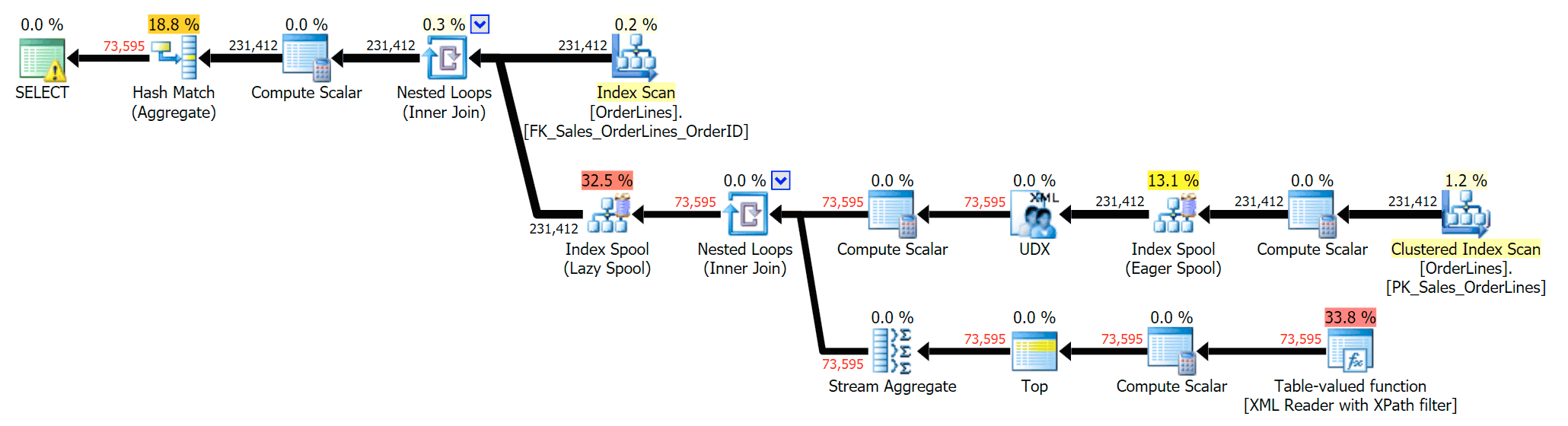
Another way to do this is to add a GROUP BY for the OrderID (since the subquery doesn't explicitly need to be referenced again in the GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description
FROM Sales.OrderLines
WHERE OrderID = o.OrderID
FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'')
FROM Sales.OrderLines AS o
GROUP BY o.OrderID;This produces the same results (though order has returned), and a slightly different plan:
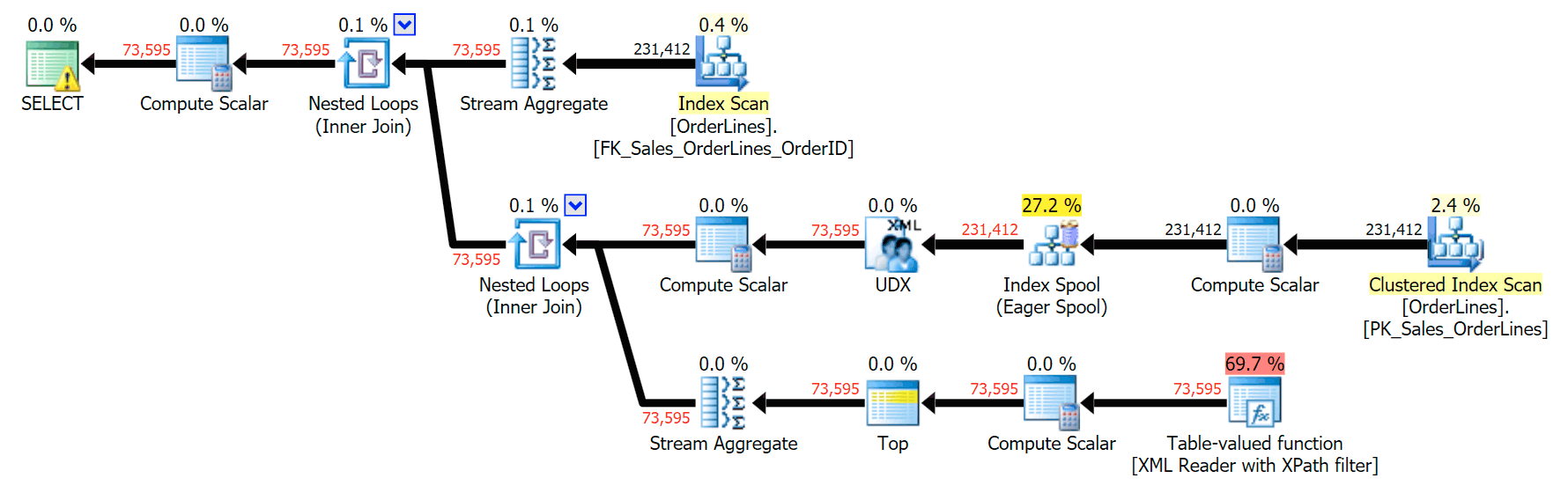
The performance metrics, however, are interesting to compare.

The DISTINCT variation took 4X as long, used 4X the CPU, and almost 6X the reads when compared to the GROUP BY variation. (Remember, these queries return the exact same results.)
We can also compare the execution plans when we change the costs from CPU + I/O combined to I/O only, a feature exclusive to Plan Explorer. We also show the re-costed values (which are based on the actual costs observed during query execution, a feature also only found in Plan Explorer). Here is the DISTINCT plan:
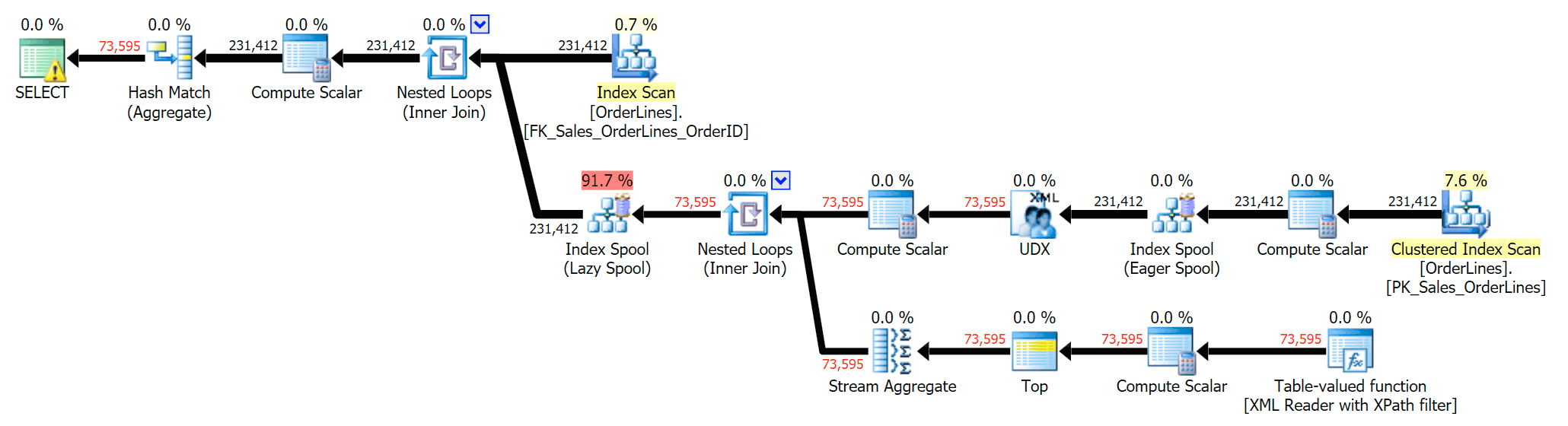
And here is the GROUP BY plan:
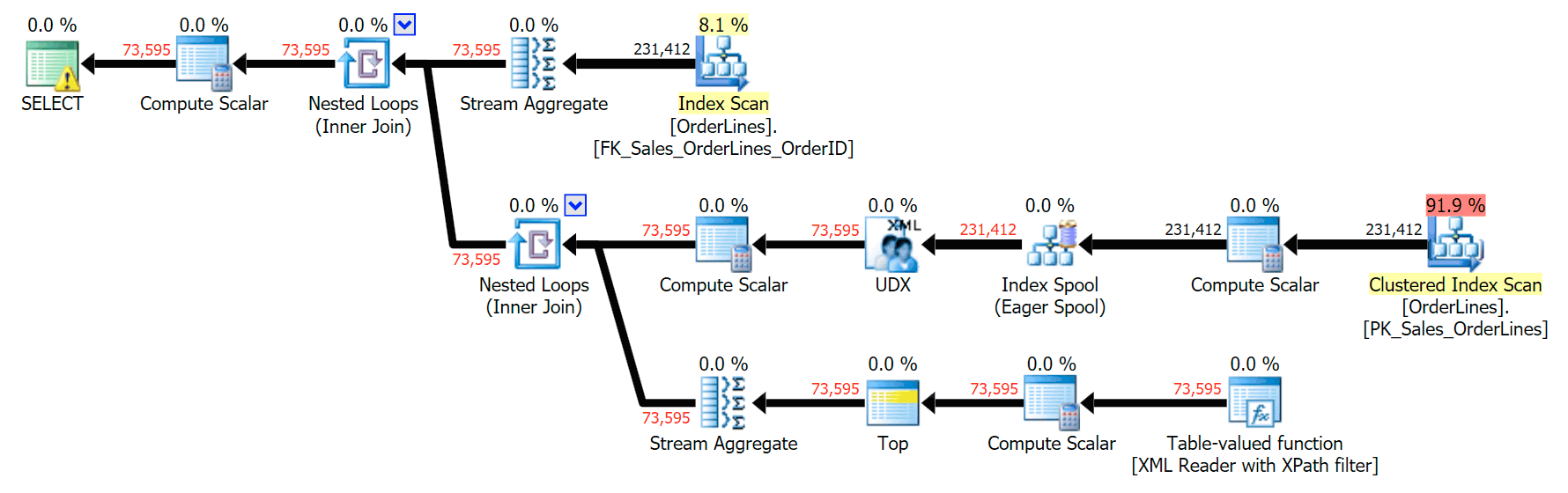
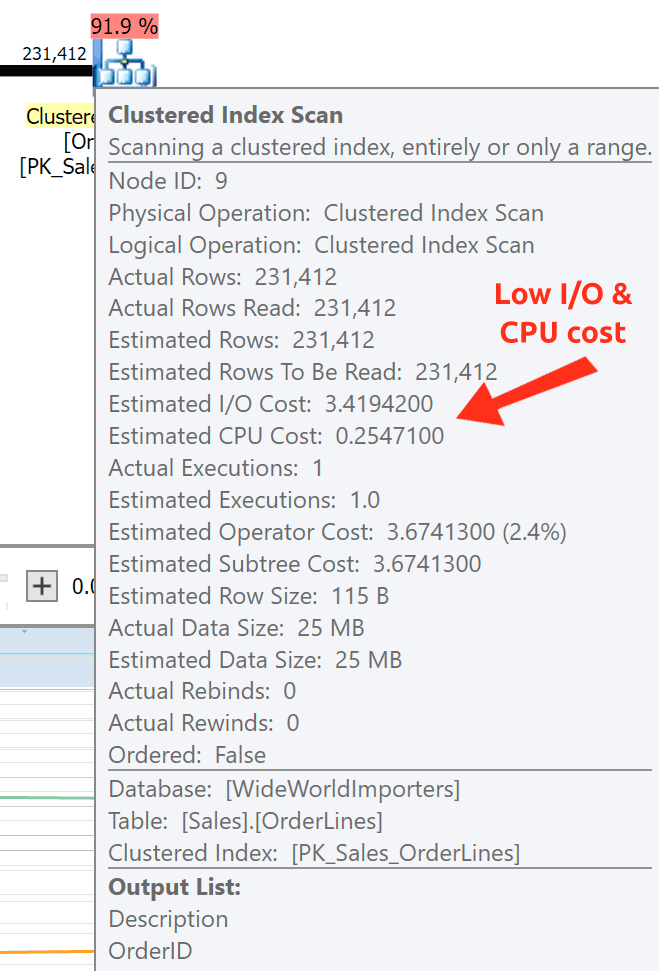
You can see that, in the GROUP BY plan, almost all of the I/O cost is in the scans (here's the tooltip for the CI scan, showing an I/O cost of ~3.4 "query bucks"). Yet in the DISTINCT plan, most of the I/O cost is in the index spool (and here's that tooltip; the I/O cost here is ~41.4 "query bucks"). Note that the CPU is a lot higher with the index spool, too. We'll talk about "query bucks" another time, but the point is that the index spool is more than 10X as expensive as the scan – yet the scan is still the same 3.4 in both plans. This is one reason it always bugs me when people say they need to "fix" the operator in the plan with the highest cost. Some operator in the plan will always be the most expensive one; that doesn't mean it needs to be fixed.
@AaronBertrand those queries are not really logically equivalent — DISTINCT is on both columns, whereas your GROUP BY is only on one
— Adam Machanic (@AdamMachanic) January 20, 2017
While Adam Machanic is correct when he says that these queries are semantically different, the result is the same – we get the same number of rows, containing exactly the same results, and we did it with far fewer reads and CPU.
So while DISTINCT and GROUP BY are identical in a lot of scenarios, here is one case where the GROUP BY approach definitely leads to better performance (at the cost of less clear declarative intent in the query itself). I'd be interested to know if you think there are any scenarios where DISTINCT is better than GROUP BY, at least in terms of performance, which is far less subjective than style or whether a statement needs to be self-documenting.
This post fit into my "surprises and assumptions" series because many things we hold as truths based on limited observations or particular use cases can be tested when used in other scenarios. We just have to remember to take the time to do it as part of SQL query optimization…
References
15 thoughts on “Performance Surprises and Assumptions : GROUP BY vs. DISTINCT”
Comments are closed.

{kind=link}
{kind=link}
Wouldn't the following query be the logical equivalent without using the group by?
This seems clearer to me.
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description
FROM Sales.OrderLines
WHERE OrderID = o.OrderID
FOR XML PATH(N"), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N")
FROM (select distinct OrderID from Sales.OrderLines) AS o
Sure, if that is clearer to you. Just remember that for brevity I create the simplest, most minimal queries to demonstrate a concept. Add two joins to this query (like say they wanted to output the customer name and the total cost of manufacturing for each order) and then it gets a little harder to read and maintain as you'll be adding a bunch of these subqueries from different tables. IMHO, anyway.
There is no single right or perfect way to do anything, but my point here was simply to point out that throwing DISTINCT on the original query isn't necessarily the best plan.
Sometimes I use DISTINCT in a subquery to force it to be "materialized", when I know that this would reduce the number of results very much but the compiler does not "believe" this and groups to late. It could reduce the I/O very much in this cases.
Thomas, can you share an example that demonstrates this? (I'm curious both if there are better ways to inform the optimizer, and whether GROUP BY would work the same.)
sadly not at the moment, since it was in some older data migration scripts. When I remember correct there was a second 'trick' on it by using a UNION with a SELECT NULL, NULL, NULL … I'll bookmark this article and come back, when I find a current statement, that benefits this behavior.
Interesting! And for cases where you do need all the selected columns in the GROUP BY, is there ever a difference?
The big difference, for me, is understanding the DISTINCT is logically performed well after GROUP BY. They just aren't logically equivalent, and therefore shouldn't be used interchangeably; you can further filter groupings with the HAVING clause, and can apply windowed functions that will be processed prior to the deduping of a DISTINCT clause. In my opinion, if you want to dedupe your completed result set, with the emphasis on completed, use DISINCT. Otherwise, you're probably after grouping.
https://msdn.microsoft.com/en-us/library/ms189499.aspx#Anchor_2
I personally think that the use of DISTINCT (and GROUP BY) at the outer level of a complicated query is a code smell.
When I see DISTINCT in the outer level, that usually indicated that the developer didn't properly analyze the cardinality of the child tables and how the joins worked, and they slapped a DISTINCT on the end result to eliminate duplicates that are the result of a poorly thought out join (or that could have been resolved through the judicious use of DISTINCT on an inner sub-query).
When I see GROUP BY at the outer level of a complicated query, especially when it's across half a dozen or more columns, it is frequently associated with poor performance. It's generally an aggregation that could have been done in a sub-query and then joined to the associated data, resulting in much less work for SQL Server.
+1
This is correct. The Logical Query Processing Phase Order of Execution is as follows:
1. FROM
2. ON
3. OUTER
4. WHERE
5. GROUP BY
6. CUBE | ROLLUP
7. HAVING
8. SELECT
9. DISTINCT
10 ORDER BY
11. TOP
Looking at the list you can see that GROUP BY and HAVING will happen well before DISTINCT (which is itself an adjective of the SELECT CLAUSE).
with uniqueOL as (
SELECT distinct OrderID
from Sales.OrderLines
)
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description
FROM Sales.OrderLines
WHERE OrderID = o.OrderID
FOR XML PATH(N"), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N")
FROM uniqueOL AS o;
Jose, thanks for the comment.
You've made a query perform relatively okay using the keyword DISTINCT – I think you've made the point, but you've missed the spirit.
When you ask 100 people how they would add DISTINCT to the original query (or how they would eliminate duplicates), I would guess you might get 2 or 3 who do it the way you did. You might get 1 or 2 who use GROUP BY. But at least 90 would just slap DISTINCT at the beginning of the keyword list. (This isn't scientific data; just my observation/experience.)
Given that all other performance attributes are identical, what advantage do you feel your syntax has over GROUP BY?
404: https://groupby.org/2016/11/t-sql-bad-habits-and-best-practices/
groupby.org seems to have rebuilt their website without leaving 301 GONE redirects.
I think this is the new URL:
https://groupby.org/conference-session-abstracts/t-sql-bad-habits-and-best-practices/
Thanks Emyr, you're right, the updated link is:
https://groupby.org/conference-session-abstracts/t-sql-bad-habits-and-best-practices/
The rule I have always required is that if the are two queries and performance is roughly identical then use the easier query to maintain. When performance is critical then DOCUMENT why and store the slower but query to read away so it could be reviewed as I've seen slower performing queries perform later in subsequent versions of SQL Server. IF YOU HAVE A BAD QUERY… publish that query in a document on what not to do and why so other developers can learn from past mistakes.