
SQL Server v.Next : STRING_AGG() performance
While SQL Server on Linux has stolen almost all of the headlines about v.Next, there are some other interesting advancements coming in the next version of our favorite database platform. On the T-SQL front, we finally have a built-in way to perform grouped string concatenation: STRING_AGG().
Let's say we have the following simple table structure:
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);For performance tests, we're going to populate this using sys.all_objects and sys.all_columns. But for a simple demonstration first, let's add the following rows:
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID');If the forums are any indication, it is a very common requirement to return a row for each object, along with a comma-separated list of column names. (Extrapolate that to whatever entity types you model this way – product names associated with an order, part names involved in the assembly of a product, subordinates reporting to a manager, etc.) So, for example, with the above data we'd want output like this:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
The way we would accomplish this in current versions of SQL Server is probably to use FOR XML PATH, as I demonstrated to be the most efficient outside of CLR in this earlier post. In this example, it would look like this:
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o;Predictably, we get the same output demonstrated above. In SQL Server v.Next, we will be able to express this more simply:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];Again, this produces the exact same output. And we were able to do this with a native function, avoiding both the expensive FOR XML PATH scaffolding, and the STUFF() function used to remove the first comma (this happens automatically).
What About Order?
One of the problems with many of the kludge solutions to grouped concatenation is that the ordering of the comma-separated list should be considered arbitrary and non-deterministic.
For the XML PATH solution, I demonstrated in another earlier post that adding an ORDER BY is trivial and guaranteed. So in this example, we could order the column list by column name alphabetically instead of leaving it to SQL Server to sort (or not):
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o;Output:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
CTP 1.1 adds WITHIN GROUP to STRING_AGG(), so using the new approach, we can say:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];Now we get the same results. Note that, just like a normal ORDER BY clause, you can add multiple ordering columns or expressions inside WITHIN GROUP ().
All Right, Performance Already!
Using quad-core 2.6 GHz processors, 8 GB of memory, and SQL Server CTP1.1 (14.0.100.187), I created a new database, re-created these tables, and added rows from sys.all_objects and sys.all_columns. I made sure to only include objects that had at least one column:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
);On my system, this yielded 656 objects and 8,085 columns (your system may yield slightly different numbers).
The Plans
First, let's compare the plans and Table I/O tabs for our two unordered queries, using Plan Explorer. Here are the overall runtime metrics:
 Runtime metrics for XML PATH (top) and STRING_AGG() (bottom)
Runtime metrics for XML PATH (top) and STRING_AGG() (bottom)
The graphical plan and Table I/O from the FOR XML PATH query:
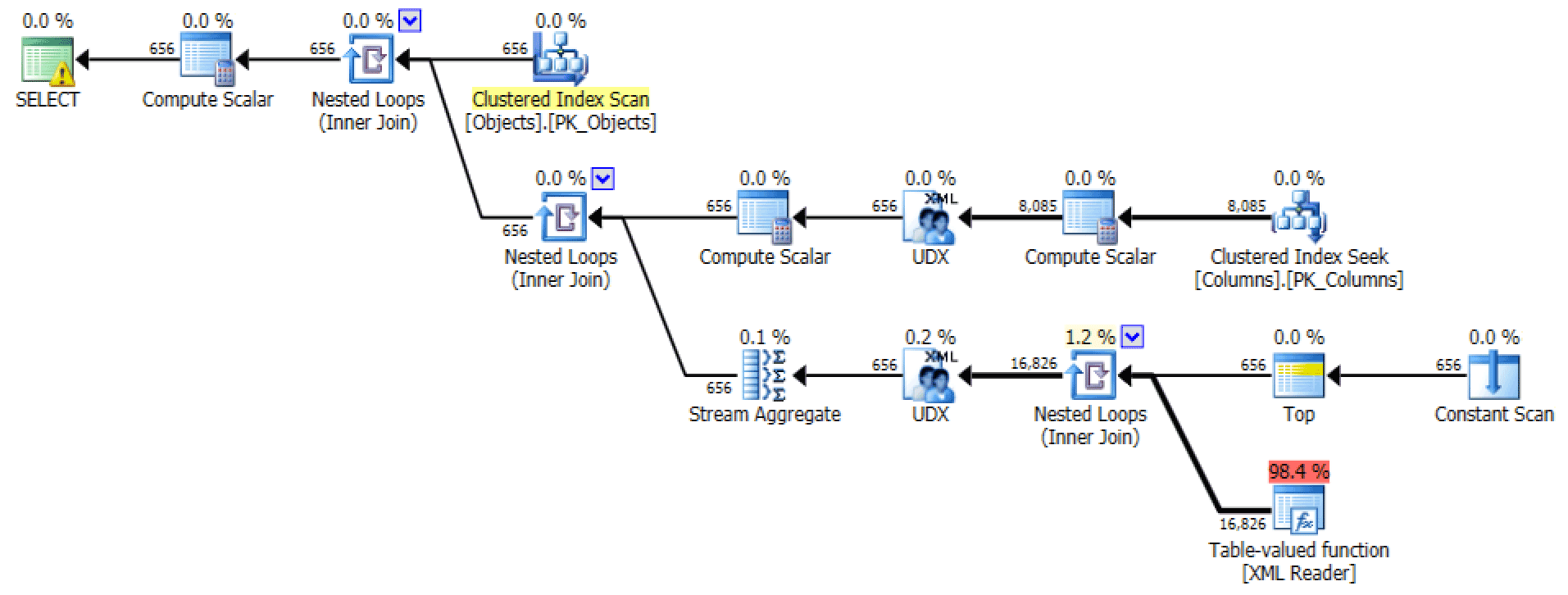
 Plan and Table I/O for XML PATH, no order
Plan and Table I/O for XML PATH, no order
And from the STRING_AGG version:
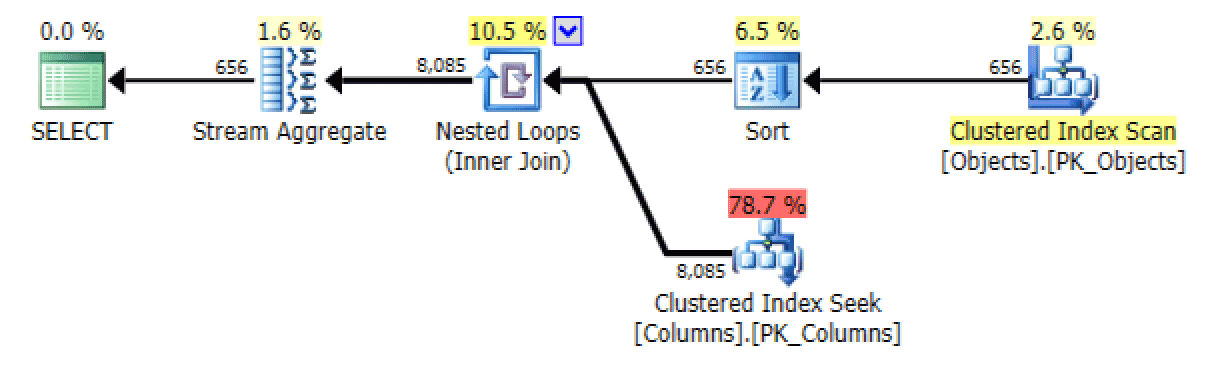
 Plan and Table I/O for STRING_AGG, no ordering
Plan and Table I/O for STRING_AGG, no ordering
For the latter, the clustered index seek seems a little troubling to me. This seemed like a good case for testing out the seldom-used FORCESCAN hint (and no, this would certainly not help out the FOR XML PATH query):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];Now the plan and Table I/O tab look a lot better, at least on first glance:
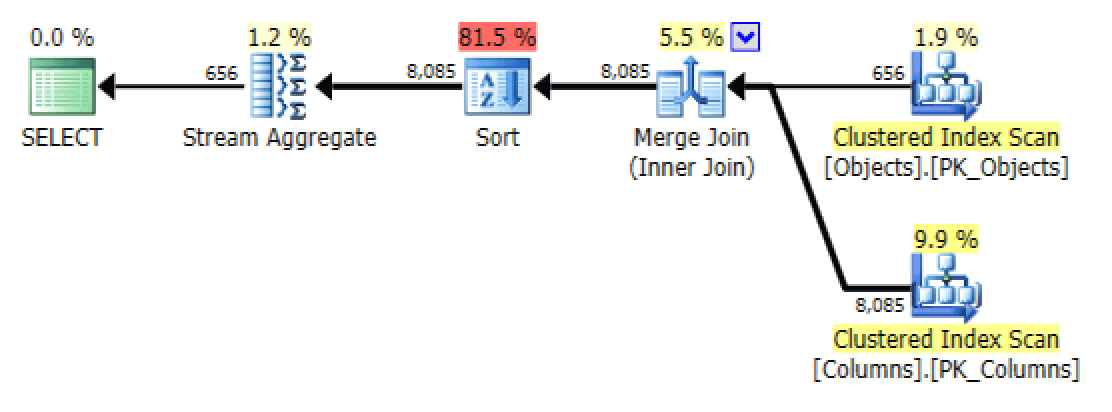
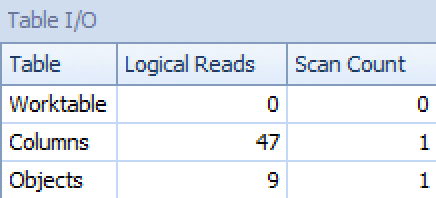 Plan and Table I/O for STRING_AGG(), no ordering, with FORCESCAN
Plan and Table I/O for STRING_AGG(), no ordering, with FORCESCAN
The ordered versions of the queries generate roughly the same plans. For the FOR XML PATH version, a sort is added:
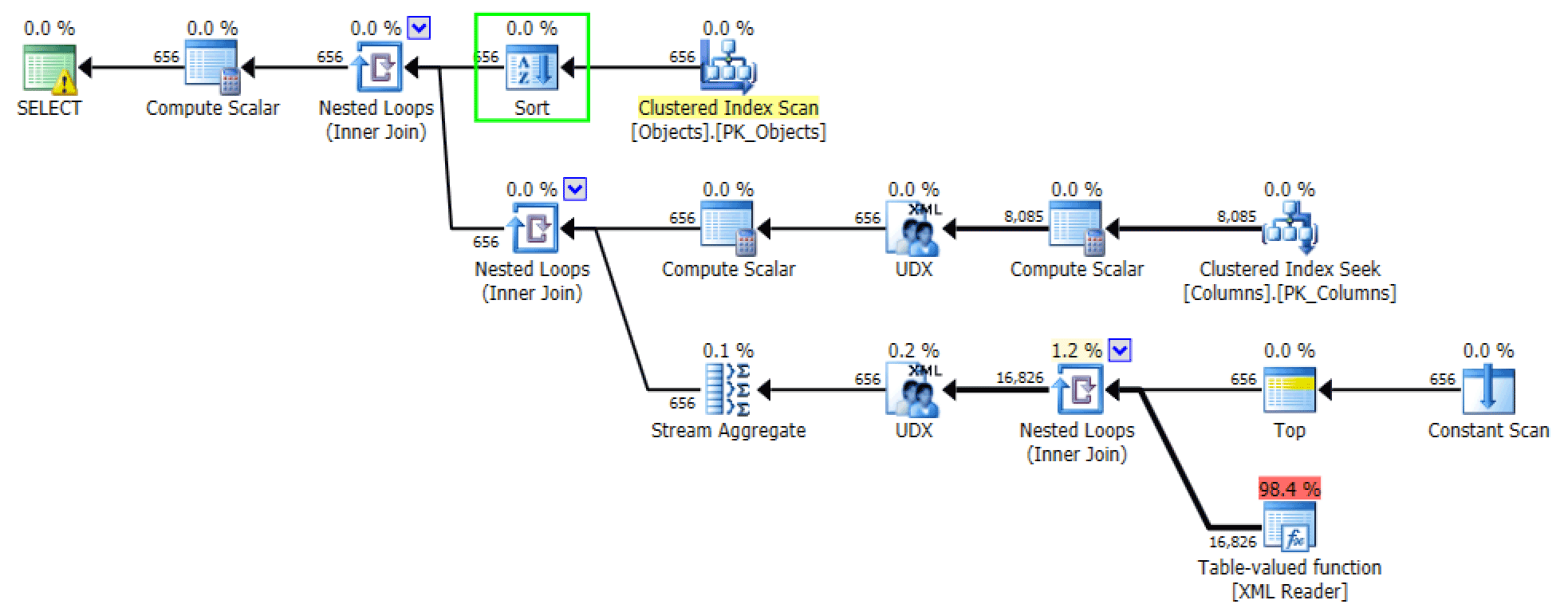 Added sort in FOR XML PATH version
Added sort in FOR XML PATH version
For STRING_AGG(), a scan is chosen in this case, even without the FORCESCAN hint, and no additional sort operation is required – so the plan looks identical to the FORCESCAN version.
At Scale
Looking at a plan and one-off runtime metrics might give us some idea about whether STRING_AGG() performs better than the existing FOR XML PATH solution, but a larger test might make more sense. What happens when we perform the grouped concatenation 5,000 times?
SELECT SYSDATETIME();
GO
DECLARE @x nvarchar(max);
SELECT @x = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
GO 5000
SELECT [string_agg, unordered] = SYSDATETIME();
GO
DECLARE @x nvarchar(max);
SELECT @x = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN)
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
GO 5000
SELECT [string_agg, unordered, forcescan] = SYSDATETIME();
GO
DECLARE @x nvarchar(max);
SELECT @x = STUFF((SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o;
GO 5000
SELECT [for xml path, unordered] = SYSDATETIME();
GO
DECLARE @x nvarchar(max);
SELECT @x = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name)
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
GO 5000
SELECT [string_agg, ordered] = SYSDATETIME();
GO
DECLARE @x nvarchar(max);
SELECT @x = STUFF((SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name
FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o
ORDER BY o.[object_name];
GO 5000
SELECT [for xml path, ordered] = SYSDATETIME();After running this script five times, I averaged the duration numbers and here are the results:
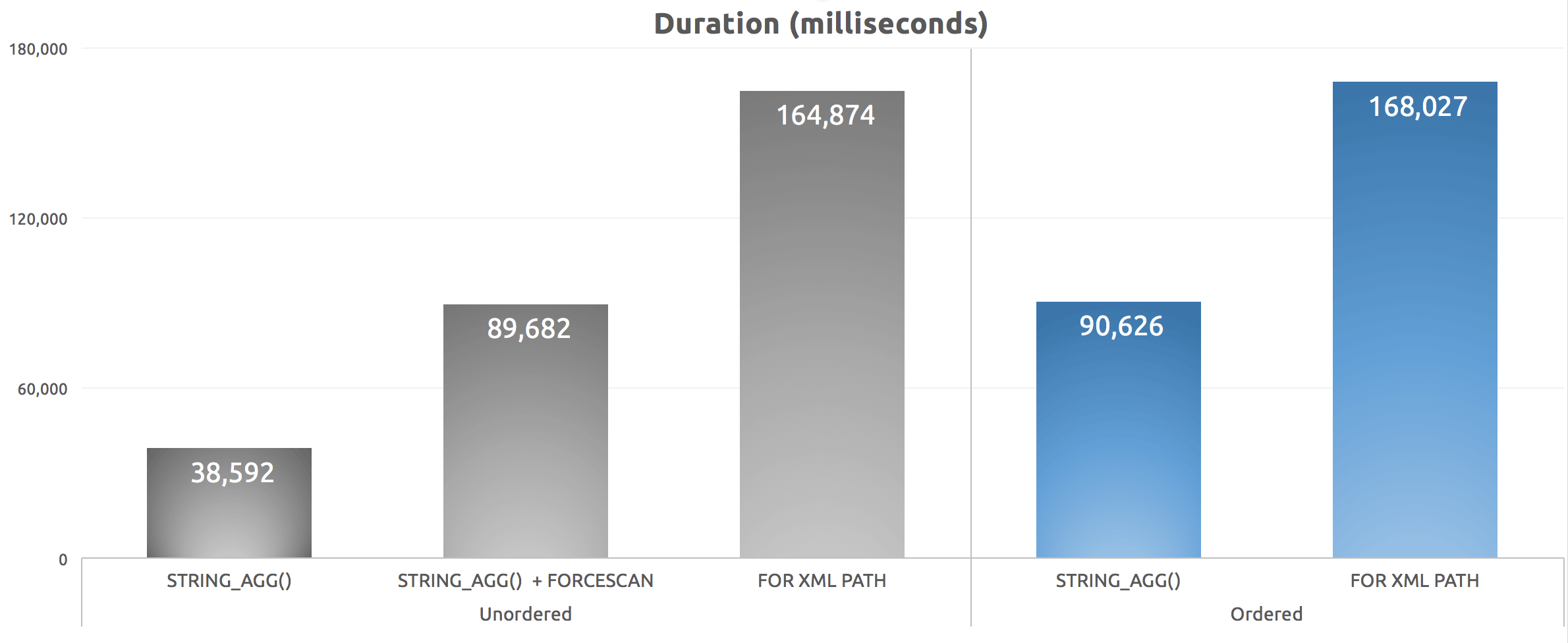 Duration (milliseconds) for various grouped concatenation approaches
Duration (milliseconds) for various grouped concatenation approaches
We can see that our FORCESCAN hint really did make things worse – while we shifted the cost away from the clustered index seek, the sort was actually much worse, even though the estimated costs deemed them relatively equivalent. More importantly, we can see that STRING_AGG() does offer a performance benefit, whether or not the concatenated strings need to be ordered in a specific way. As with STRING_SPLIT(), which I looked at back in March, I am quite impressed that this function scales well prior to "v1."
I have further tests planned, perhaps for a future post:
- When all the data comes from a single table, with and without an index that supports ordering
- Similar performance tests on Linux
In the meantime, if you have specific use cases for grouped concatenation, please share them below (or e-mail me at abertrand@sentryone.com). I'm always open to making sure my tests are as real-world as possible.
14 thoughts on “SQL Server v.Next : STRING_AGG() performance”
Comments are closed.

Hi Aaron,
Try changing XML concatenation method.
On my test XML turns out to be much faster.
http://www.lyp.pl/blog/sql-vnext-string_agg-vs-xml-string-concatenation/
Thanks Grzegorz, but I cannot reproduce. I see the same performance in both cases (mine is 32.07ms per execution, while yours is 31.19ms per execution). There are several differences between our tests to keep in mind that may be misleading you:
(1) You only performed a single run of your test, and it's unclear if the first test using STRING_AGG paid the cost of loading that data into cache (e.g. if you had just restarted or dropped clean buffers). Even still, a single execution against a catalog view is not much of a test IMHO. :-)
(2) Your XML approach actually requires an additional convert to xml, and without the STUFF my approach uses, yields different results. (You only take the length of the output string, so it's not as obvious that you maintain the leading comma that both my approach and STRING_AGG leave out.) I did not test performance adding STUFF to your solution to ensure I was testing what you wrote – all I did was change it to variable assignment to match my tests.
(3) Your tests were using CTP1, while we know further work has been done on STRING_AGG in CTP1.1 (they added WITHIN GROUP and perhaps also may have optimized performance).
Perhaps you could try again on a more current build and with fewer facets of your test being different from mine? Against a real table with real data and no cache shenanigans or NOLOCK, on CTP1.1, your XML method performed about the same as mine, and STRING_AGG beat them both.
I went further with this case. I have MS SQL vNext on Linux CTP 1.1 (Ubuntu 16.04). Machine is 2 cores (3.4GHz Intel Xeon) and 8GB of RAM. The values of 100 times test gives variation of time up to 100ms on STRING_AGG and with XML variation is about 20ms. Test is performed on WorldWideImportes standard database (https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0). The length of concatenated data is 9695735 and 9927146 for comma separated. There are 231412 rows.
Here are the results:
— 1310 ms
select len(string_agg(convert(nvarchar(max),s.Description),"))
from Sales.OrderLines s with (nolock)
— 395 ms
select len(convert(xml,(select s.Description [*]
from Sales.OrderLines s with (nolock) for xml path ("))).value('text()[1]','nvarchar(max)'))
— 1529 ms
select len(string_agg(convert(varchar(max),s.Description),','))
from Sales.OrderLines s with (nolock)
— 522 ms
select len(stuff(convert(xml,(select ','+ s.Description [*]
from Sales.OrderLines s with (nolock) for xml path ("))).value('text()[1]','nvarchar(max)'),1,1,"))
This should be repeatable.
Forgot about ordered case:
— 2307 ms
select len(string_agg(convert(nvarchar(max),s.Description),") WITHIN GROUP (ORDER BY s.Description))
from Sales.OrderLines s with (nolock)
— 895 ms
select len(convert(xml,(select s.Description [*]
from Sales.OrderLines s with (nolock) ORDER BY s.Description for xml path ("))).value('text()[1]','nvarchar(max)'))
PS. Happy New Year to all SQL Sentry people.
Our tests are still not the same.
(1) You're testing on Linux (I haven't tested there yet, as I mention toward the bottom of the article, and I can't even do it right now because hotel WiFi won't let me pull the mssql-server image).
(2) You're still just retrieving the *length* of the string. My test actually returns the string. My point is simply that changing my concatenation method, which you suggested in your first comment, was not going to improve my XML path performance, because I wasn't just checking the length of the string, I was actually returning the string. In my tests my method is always faster when returning the actual string, and always a little bit slower when checking the length.
(3) You are performing a concatenation that would yield strings longer than 8K, adding the requirement of an explicit convert to nvarchar(max). My tests specifically don't cross that boundary and it wasn't a case I tested.
It's clear there isn't going to be some magic "string_agg will ALWAYS be better or worse," and I will concede that it might be true that LOB is not a good use case. It *was* the clear winner in the use case I tested (which, I hope, is far more common). You're just blindly concatenating all of the strings in an entire table, which is a data point, sure, but not very practical.
Hi, Aaron,
(1) On the SQL vNext Preview page the CTP 1.1 for Windows is still not available. Can You share how to get it on Windows ?
(2) The len function takes same time for both cases, so it does have the same impact in both cases.
(3) Concatenation of data that is lower than 8K runs so fast in both cases that only in specific situations it is important.
The typical application of large data concatenation is SQL code generation (like altering user data type).
(1) I got mine from MSDN downloads IIRC, but it seems CTP 1.1 is also available from Visual Studio Essentials.
(2) I wasn't suggesting LEN() was different from LEN(). I was suggesting that LEN() might be different from not using LEN() at all and just returning the string.
(3) I don't know that we quite agree on what the most common use case for concatenation might be.
Hi Aaron and Happy New Year!
There is room for some improvement in your XML version. Not so much that it matter in the comparison against STRING_AGG but anyway.
When you use "FOR XML PATH" you get the XML with an element "row" for each value in the generated XML like this ",CurrentStatus,EmployeeID". Using the values function with '.' extracts all the text nodes for you and then makes the proper concatenation.
If you instead specify the empty tag in PATH "FOR XML PATH(")" you get one XML element with the value ",CurrentStatus,EmployeeID" that is then extracted by the values function as is.
You can see the difference in the execution plan by the number of rows coming from the lower left TVF.
That change made your tests on my machine go 10% faster.
If I also change the first parameter in the values function to "N'text()[1]'" I got it another 4% faster so a total improvement of about 14%.
That change will cut the number of rows returned from the TVF by half and remove an "expensive" UDF operator.
I know we talked about this before and you have said that you sometimes seen an improvement with text() and sometimes not. In this case I have seen a small one :).
It would be interesting to see what difference it makes on your end if you can find the time to run some tests.
cheers
/Micke
Thanks Mikael,
I'm aware that is not the most efficient XML approach, and I'm willing to run more tests, but I suspect a 10-15% improvement is not going to tip the scales.
A question for you: What percentage of users do you think are concatenating strings that end up being larger than 4000/8000 characters? STRING_AGG by default truncates at 8000 bytes, and I suspect an explicit conversion to MAX in order to avoid that is not going to be very friendly. In which case it might make sense to use TVFs that wrap STRING_AGG or XML depending on the usage.
I can't see any reason why anyone should want to concatenate strings to that size so I guess a very low percentage.
The only case where concatenated strings make sense that I can think of is for some presentation logic where you need to show something that may have multiple values in one row. But since we are talking about showing something for a user, a string of more than perhaps a couple of hundred characters makes no sense.
Hi Aaron,
Thanks for the write up.
I recently created one process in my organization to analyze message logs that are stored in table as one row per message. There may be hundred's of messages for every message session. I was needed to do some natural language analysis on that data so I used FOR XML to concatenate all messages in a session as one large paragraph . Finally send each large paragraph through python NLP program for analysis. I haven't tried new STRING_AGG yet but just wanted to provide one use case for concatenating large strings. Quite excited about about some of these new changes in TSQL finally.
Thanks!
Well, in my last position, concatenated lists of more than 8k were produced multiple thousands of times per day. Trust me, I got bit by trying to optimize for 8k or less.
What these strings were is lists of productIDs covering all variations of a given Product. For example, an aftermarket gas tank that fits multiple years of multiple models of multiple manufacturers of motorcycles, and comes in multiple colors, has far more individual SKUs than you would ever imagine. Since this was for a website, and they wanted the data available at the customer's end, these lists were an important component on many pages of the website that handled products with multiple variations.
Two use cases:
In my last position, we needed to build "very long" (20k+ characters)dynamic SQL to operate on a number of tables, so, using the MSDN Magazine-based SQL CLR, we easily exceeded 8000 characters. Something much longer than, but very similar to this example:
DECLARE @SqlCommand nvarchar(max)
SELECT @SqlCommand =
dbo.Concatenate('SELECT <<>> FROM ' + TABLE_NAME, ' UNION ', 0)
FROM INFORMATION_SCHEMA.TABLES
<<>>
We also sometimes had to pass lists of ZIP codes, and as there are ca. 40,000 ZIP codes, it's easy to get beyond 8000 characters
Hi, i see in your example, but also in one mine that STRING_AGG produces exactly 100 logical reads more than FOR XML. AGG is faster but i don't understand from where are the 100 logical reads more.
USE [WideWorldImporters];
SET NOCOUNT ON;
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT
C.[CustomerID]
, STUFF((
SELECT
',' + CAST(I.[InvoiceID] AS NVARCHAR(MAX))
FROM
[Sales].[Invoices] I
WHERE
I.[CustomerID] = C.[CustomerID]
ORDER BY
I.[InvoiceID] ASC
FOR XML PATH("), TYPE).value('.', 'varchar(max)'),1,1,") AS InvoicesList
FROM
[Sales].[Customers] AS C
ORDER BY
C.[CustomerID] ASC;
SELECT
C.[CustomerID]
, (
SELECT
STRING_AGG([InvoiceID], ',') WITHIN GROUP(ORDER BY [InvoiceID] ASC) AS InvoicesList
FROM
[Sales].[Invoices] I
WHERE
I.[CustomerID] = C.[CustomerID]
)
FROM
[Sales].[Customers] AS C
ORDER BY
C.[CustomerID] ASC;