
SQL Server v.Next : STRING_AGG Performance, Part 2
Last week, I made a couple of quick performance comparisons, pitting the new STRING_AGG() function against the traditional FOR XML PATH approach I've used for ages. I tested both undefined/arbitrary order as well as explicit order, and STRING_AGG() came out on top in both cases:
For those tests, I left out several things (not all intentionally):
- Mikael Eriksson and Grzegorz Łyp both pointed out that I was not using the absolute most efficient
FOR XML PATHconstruct (and to be clear, I never have). - I did not perform any tests on Linux; only on Windows. I don't expect those to be vastly different, but since Grzegorz saw very different durations, this is worth further investigation.
- I also only tested when output would be a finite, non-LOB string – which I believe is the most common use case (I don't think people will commonly be concatenating every row in a table into a single comma-separated string, but this is why I asked in my previous post for your use case(s)).
- For the ordering tests, I did not create an index that might be helpful (or try anything where all the data came from a single table).
In this post, I'm going to deal with a couple of these items, but not all of them.
FOR XML PATH
I had been using the following:
... FOR XML PATH, TYPE).value(N'.[1]', ...After this comment from Mikael, I have updated my code to use this slightly different construct instead:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ...Linux vs. Windows
Initially, I had only bothered to run tests on Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
But Grzegorz made a fair point that he (and presumably many others) only had access to the Linux flavor of CTP 1.1. So I added Linux to my test matrix:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Some interesting but completely tangential observations:
@@VERSIONdoesn't show edition in this build, butSERVERPROPERTY('Edition')returns the expectedDeveloper Edition (64-bit).- Based on the build times encoded into the binaries, the Windows and Linux versions seem to now be compiled at the same time and from the same source. Or this was one crazy coincidence.
Unordered tests
I started by testing the arbitrarily ordered output (where there is no explicitly defined ordering for the concatenated values). Following Grzegorz, I used WideWorldImporters (Standard), but performed a join between Sales.Orders and Sales.OrderLines. The fictional requirement here is to output a list of all orders, and along with each order, a comma-separated list of each StockItemID.
Since StockItemID is an integer, we can use a defined varchar, which means the string can be 8000 characters before we have to worry about needing MAX. Since an int can be a max length of 11 (really 10, if unsigned), plus a comma, this means an order would have to support about 8,000/12 (666) stock items in the worst case scenario (e.g. all StockItemID values have 11 digits). In our case, the longest ID is 3 digits, so until data gets added, we would actually need 8,000/4 (2,000) unique stock items in any single order to justify MAX. In our case, there are only 227 stock items in total, so MAX isn't necessary, but you should keep an eye on that. If such a large string is possible in your scenario, you'll need to use varchar(max) instead of the default (STRING_AGG() returns nvarchar(max), but truncates to 8,000 bytes unless the input is a MAX type).
The initial queries (to show sample output, and to observe durations for single executions):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
I ignored the parse and compile time data completely, as they were always exactly zero or close enough to be irrelevant. There were minor variances in the execution times for each run, but not much – the comments above reflect the typical delta in runtime (STRING_AGG seemed to take a little advantage of parallelism there, but only on Linux, while FOR XML PATH did not on either platform). Both machines had a single socket, quad-core CPU allocated, 8 GB of memory, out-of-the-box configuration, and no other activity.
Then I wanted to test at scale (simply a single session executing the same query 500 times). I didn't want to return all of the output, as in the above query, 500 times, since that would have overwhelmed SSMS – and hopefully doesn't represent real-world query scenarios anyway. So I assigned the output to variables and just measured the overall time for each batch:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();I ran those tests three times, and the difference was profound – nearly an order of magnitude. Here is the average duration across the three tests:
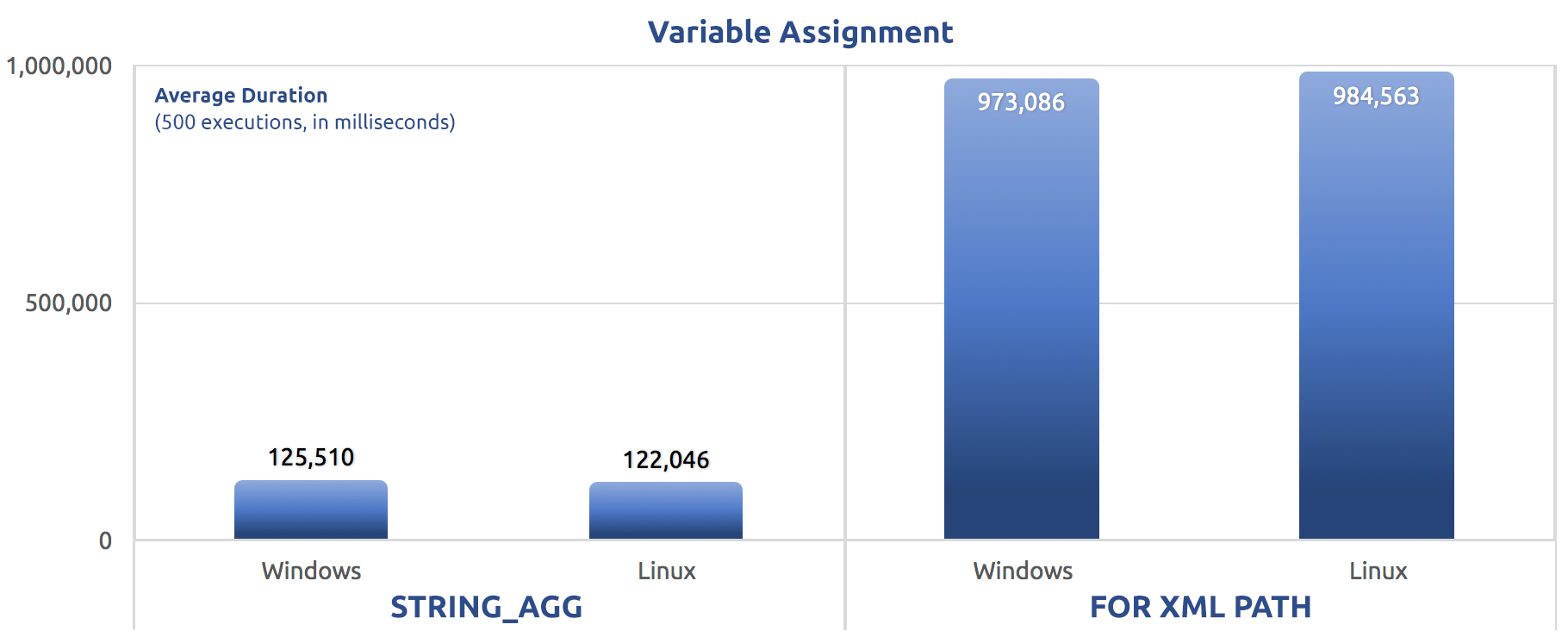 Average duration, in milliseconds, for 500 executions of variable assignment
Average duration, in milliseconds, for 500 executions of variable assignment
I tested a variety of other things this way as well, mostly to make sure I was covering the types of tests Grzegorz was running (without the LOB part).
- Selecting just the length of the output
- Getting the max length of the output (of an arbitrary row)
- Selecting all of the output into a new table
Selecting just the length of the output
This code merely runs through each order, concatenates all of the StockItemID values, and then returns just the length.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/For the batched version, again, I used variable assignment, rather than try to return many resultsets to SSMS. The variable assignment would end up on an arbitrary row, but this still requires full scans, because the arbitrary row isn't selected first.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();Performance metrics of 500 executions:
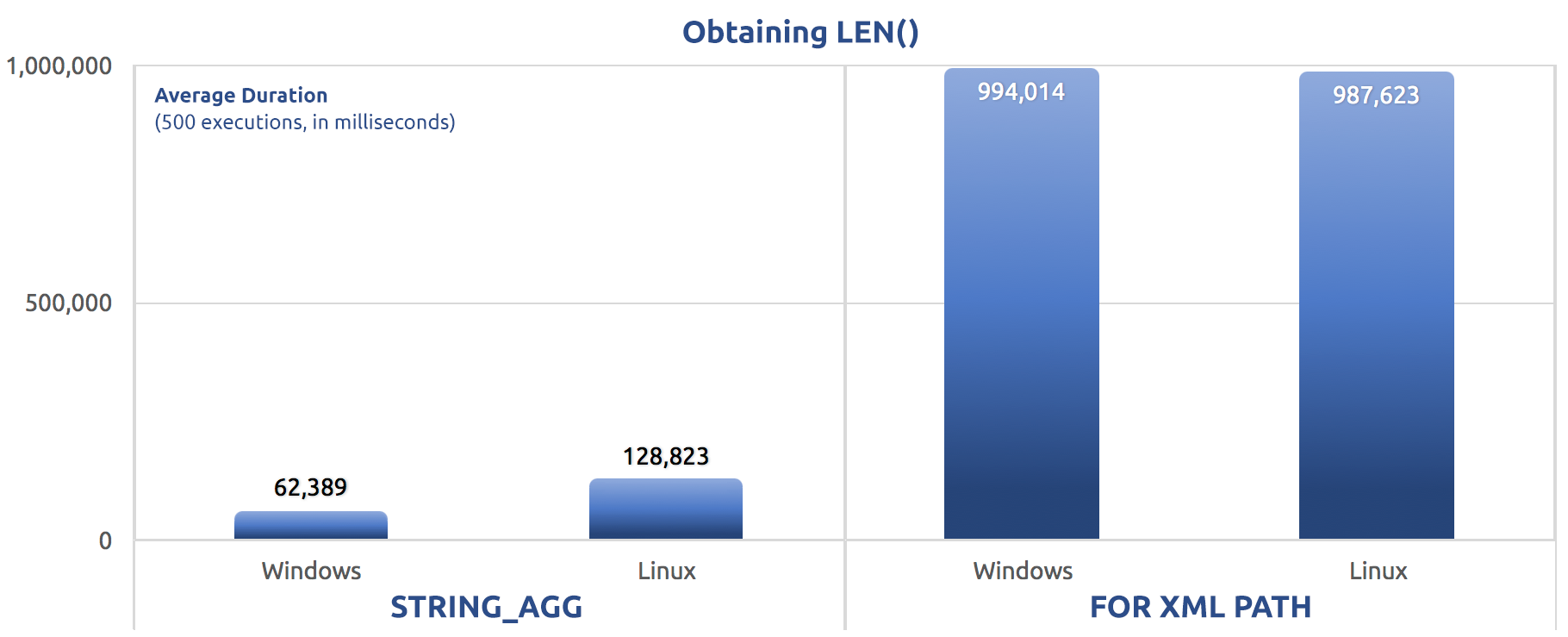 500 executions of assigning LEN() to a variable
500 executions of assigning LEN() to a variable
Again, we see FOR XML PATH is far slower, on both Windows and Linux.
Selecting the maximum length of the output
A slight variation on the previous test, this one just retrieves the maximum length of the concatenated output:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/And at scale, we just assign that output to a variable again:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();Performance results, for 500 executions, averaged across three runs:
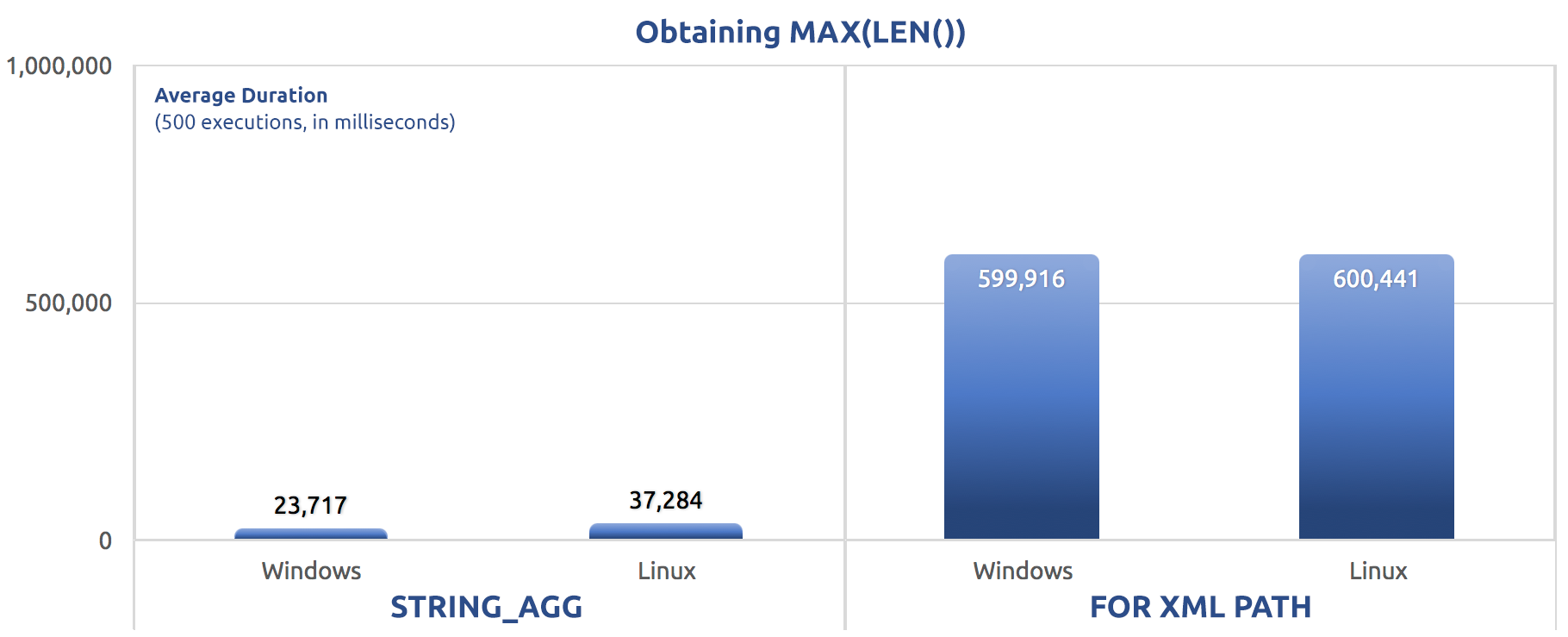 500 executions of assigning MAX(LEN()) to a variable
500 executions of assigning MAX(LEN()) to a variable
You might start to notice a pattern across these tests – FOR XML PATH is always a dog, even with the performance improvements suggested in my previous post.
SELECT INTO
I wanted to see if the method of concatenation had any impact on writing the data back to disk, as is the case in some other scenarios:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/In this case we see that perhaps SELECT INTO was able to take advantage of a bit of parallelism, but still we see FOR XML PATH struggle, with runtimes an order of magnitude longer than STRING_AGG.
The batched version just swapped out the SET STATISTICS commands for SELECT sysdatetime(); and added the same GO 500 after the two main batches as with the previous tests. Here is how that panned out (again, tell me if you've heard this one before):
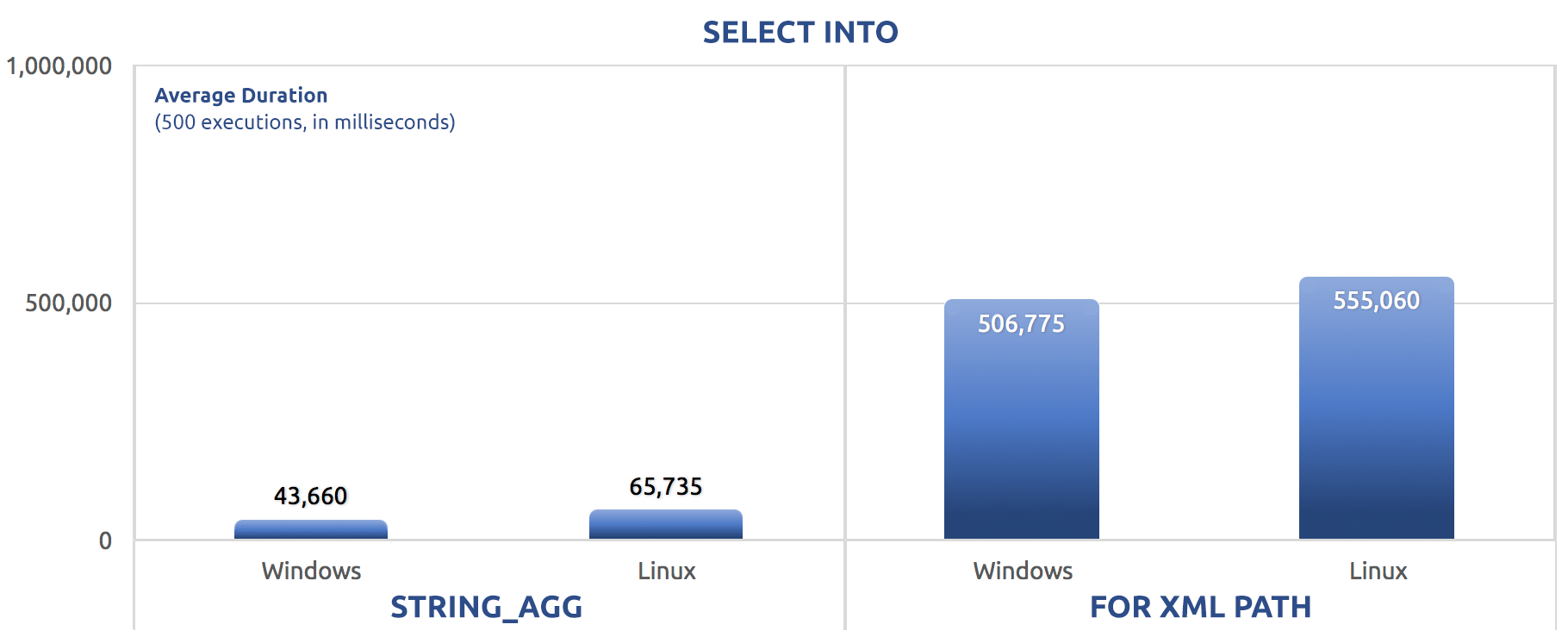 500 executions of SELECT INTO
500 executions of SELECT INTO
Ordered Tests
I ran the same tests using the ordered syntax, e.g.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ...This had very little impact on anything – the same set of four test rigs showed nearly identical metrics and patterns across the board.
I will be curious to see if this is different when the concatenated output is in non-LOB or where the concatenation needs to order strings (with or without a supporting index).
Conclusion
For non-LOB strings, it is clear to me that STRING_AGG has a definitive performance advantage over FOR XML PATH, on both Windows and Linux. Note that, to avoid the requirement of varchar(max) or nvarchar(max), I didn't use anything similar to the tests Grzegorz ran, which would have meant simply concatenating all of the values from a column, across an entire table, into a single string. In my next post, I'll take a look at the use case where the output of the concatenated string could feasibly be greater than 8,000 bytes, and so LOB types and conversions would have to be used.
1 thought on “SQL Server v.Next : STRING_AGG Performance, Part 2”
Comments are closed.

Informative article with exhaustive tests. This was an excellent quick read. Thanks for putting in the time to write this up.