
Pagination with OFFSET / FETCH : A better way
Pagination is a common use case throughout client and web applications everywhere. Google shows you 10 results at a time, your online bank may show 20 bills per page, and bug tracking and source control software might display 50 items on the screen.
I wanted to look at the common pagination approach on SQL Server 2012 – OFFSET / FETCH (a standard equivalent to MySQL’s prioprietary LIMIT clause) – and suggest a variation that will lead to more linear paging performance across the entire set, instead of only being optimal at the beginning. Which, sadly, is all that a lot of shops will test.
What is pagination in SQL Server?
Based on the indexing of the table, the columns needed, and the sort method chosen, pagination can be relatively painless. If you're looking for the "first" 20 customers and the clustered index supports that sorting (say, a clustered index on an IDENTITY column or DateCreated column), then the query is going to be relatively efficient. If you need to support sorting that requires non-clustered indexes, and especially if you have columns needed for output that aren't covered by the index (never mind if there is no supporting index), the queries can get more expensive. And even the same query (with a different @PageNumber parameter) can get much more expensive as the @PageNumber gets higher – since more reads may be required to get to that "slice" of the data.
Some will say that progressing toward the end of the set is something that you can solve by throwing more memory at the problem (so you eliminate any physical I/O) and/or using application-level caching (so you're not going to the database at all). Let's assume for the purposes of this post that more memory isn't always possible, since not every customer can add RAM to a server that's out of memory slots or not in their control, or just snap their fingers and have newer, bigger servers ready to go. Especially since some customers are on Standard Edition, so are capped at 64GB (SQL Server 2012) or 128GB (SQL Server 2014), or are using even more limited editions such as Express (1GB) or one of many cloud offerings.
So I wanted to look at the common paging approach on SQL Server 2012 – OFFSET / FETCH – and suggest a variation that will lead to more linear paging performance across the entire set, instead of only being optimal at the beginning. Which, sadly, is all that a lot of shops will test.
Pagination Data Setup / Example
I'm going to borrow from another post, Bad habits : Focusing only on disk space when choosing keys, where I populated the following table with 1,000,000 rows of random-ish (but not entirely realistic) customer data:
CREATE TABLE [dbo].[Customers_I]
(
[CustomerID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL,
[Active] [bit] NOT NULL DEFAULT ((1)),
[Created] [datetime] NOT NULL DEFAULT (sysdatetime()),
[Updated] [datetime] NULL,
CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC)
);
GO
CREATE NONCLUSTERED INDEX [C_Active_Customers_I]
ON [dbo].[Customers_I]
([FirstName] ASC, [LastName] ASC, [EMail] ASC)
WHERE ([Active] = 1);
GO
CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I]
ON [dbo].[Customers_I]
([EMail] ASC);
GO
CREATE NONCLUSTERED INDEX [C_Name_Customers_I]
ON [dbo].[Customers_I]
([LastName] ASC, [FirstName] ASC)
INCLUDE ([EMail]);
GOSince I knew I would be testing I/O here, and would be testing from both a warm and cold cache, I made the test at least a little bit more fair by rebuilding all of the indexes to minimize fragmentation (as would be done less disruptively, but regularly, on most busy systems that are performing any type of index maintenance):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);After the rebuild, fragmentation comes in now at 0.05% – 0.17% for all indexes (index level = 0), pages are filled over 99%, and the row count / page count for the indexes are as follows:
| Index | Page Count | Row Count |
|---|---|---|
| C_PK_Customers_I (clustered index) | 19,210 | 1,000,000 |
| C_Email_Customers_I | 7,344 | 1,000,000 |
| C_Active_Customers_I (filtered index) | 13,648 | 815,235 |
| C_Name_Customers_I | 16,824 | 1,000,000 |
Indexes, page counts, row counts
This obviously isn't a super-wide table, and I've left compression out of the picture this time. Perhaps I will explore more configurations in a future test.
How to effectively paginate a SQL query
The concept of pagination – showing the user only rows at a time – is easier to visualize than explain. Think of the index of a physical book, which may have multiple pages of references to points within the book, but organized alphabetically. For simplicity, let’s say that ten items fit on each page of the index. This might looks like this:
Now, if I have already read pages 1 and 2 of the index, I know that to get to page 3, I need to skip 2 pages. But since I know that there are 10 items on each page, I can also think of this as skipping 2 x 10 items, and starting on the 21st item. Or, to put it another way, I need to skip the first (10*(3-1)) items. To make this more generic, I can say that to start on page n, I need to skip the first (10 * (n-1)) items. To get to the first page, I skip 10*(1-1) items, to end on item 1. To get to the second page, I skip 10*(2-1) items, to end on item 11. And so on.
With that information, users will formulate a paging query like this, given that the OFFSET / FETCH clauses added in SQL Server 2012 were specifically designed to skip that many rows:
SELECT [a_bunch_of_columns]
FROM dbo.[some_table]
ORDER BY [some_column_or_columns]
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY;As I mentioned above, this works just fine if there is an index that supports the ORDER BY and that covers all of the columns in the SELECT clause (and, for more complex queries, the WHERE and JOIN clauses). However, the sort costs might be overwhelming with no supporting index, and if the output columns aren't covered, you will either end up with a whole bunch of key lookups, or you may even get a table scan in some scenarios.
Sorting SQL pagination best practices
Given the table and indexes above, I wanted to test these scenarios, where we want to show 100 rows per page, and output all the columns in the table:
- Default –
ORDER BY CustomerID(clustered index). This is the most convenient ordering for the database folks, since it requires no additional sorting, and all of the data from this table that could possibly be needed for display is included. On the other hand, this might not be the most efficient index to use if you are displaying a subset of the table. The order also might not make sense to end users, especially if CustomerID is a surrogate identifier with no external meaning. - Phone book –
ORDER BY LastName, FirstName(supporting non-clustered index). This is the most intuitive ordering for users, but would require a non-clustered index to support both sorting and coverage. Without a supporting index, the entire table would have to be scanned. - User-defined –
ORDER BY FirstName DESC, EMail(no supporting index). This represents the ability for the user to choose any sorting order they wish, a pattern Michael J. Swart warns about in "UI Design Patterns That Don't Scale."
I wanted to test these methods and compare plans and metrics when – under both warm cache and cold cache scenarios – looking at page 1, page 500, page 5,000, and page 9,999. I created these procedures (differing only by the ORDER BY clause):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail
In reality, you will probably just have one procedure that either uses dynamic SQL (like in my “kitchen sink” example) or a CASE expression to dictate the order.
In either case, you may see best results by using OPTION (RECOMPILE) on the query to avoid reuse of plans that are optimal for one sorting option but not all. I created separate procedures here to take those variables away; I added OPTION (RECOMPILE) for these tests to stay away from parameter sniffing and other optimization issues without flushing the entire plan cache repeatedly.
An alternate approach to SQL Server pagination for better performance
A slightly different approach, which I don't see implemented very often, is to locate the "page" we're on using only the clustering key, and then join to that:
;WITH pg AS
(
SELECT [key_column]
FROM dbo.[some_table]
ORDER BY [some_column_or_columns]
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT t.[bunch_of_columns]
FROM dbo.[some_table] AS t
INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS
ORDER BY [some_column_or_columns];It's more verbose code, of course, but hopefully it's clear what SQL Server can be coerced into doing: avoiding a scan, or at least deferring lookups until a much smaller resultset is whittled down. Paul White (@SQL_Kiwi) investigated a similar approach back in 2010, before OFFSET/FETCH was introduced in the early SQL Server 2012 betas (I first blogged about it later that year).
Given the scenarios above, I created three more procedures, with the only difference between the column(s) specified in the ORDER BY clauses (we now need two, one for the page itself, and one for ordering the result):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail
Note: This may not work so well if your primary key is not clustered – part of the trick that makes this work better, when a supporting index can be used, is that the clustering key is already in the index, so a lookup is often avoided.
Testing the clustering key sort
First I tested the case where I didn't expect much variance between the two methods – sorting by the clustering key. I ran these statements in a batch in SQL Sentry Plan Explorer and observed duration, reads, and the graphical plans, making sure that each query was starting from a completely cold cache:
SET NOCOUNT ON;
-- default method
DBCC DROPCLEANBUFFERS;
EXEC dbo.Pagination_Test_1 @PageNumber = 1;
DBCC DROPCLEANBUFFERS;
EXEC dbo.Pagination_Test_1 @PageNumber = 500;
DBCC DROPCLEANBUFFERS;
EXEC dbo.Pagination_Test_1 @PageNumber = 5000;
DBCC DROPCLEANBUFFERS;
EXEC dbo.Pagination_Test_1 @PageNumber = 9999;
-- alternate method
DBCC DROPCLEANBUFFERS;
EXEC dbo.Alternate_Test_1 @PageNumber = 1;
DBCC DROPCLEANBUFFERS;
EXEC dbo.Alternate_Test_1 @PageNumber = 500;
DBCC DROPCLEANBUFFERS;
EXEC dbo.Alternate_Test_1 @PageNumber = 5000;
DBCC DROPCLEANBUFFERS;
EXEC dbo.Alternate_Test_1 @PageNumber = 9999;The results here were not astounding. Over 5 executions the average number of reads are shown here, showing negligible differences between the two queries, across all page numbers, when sorting by the clustering key:
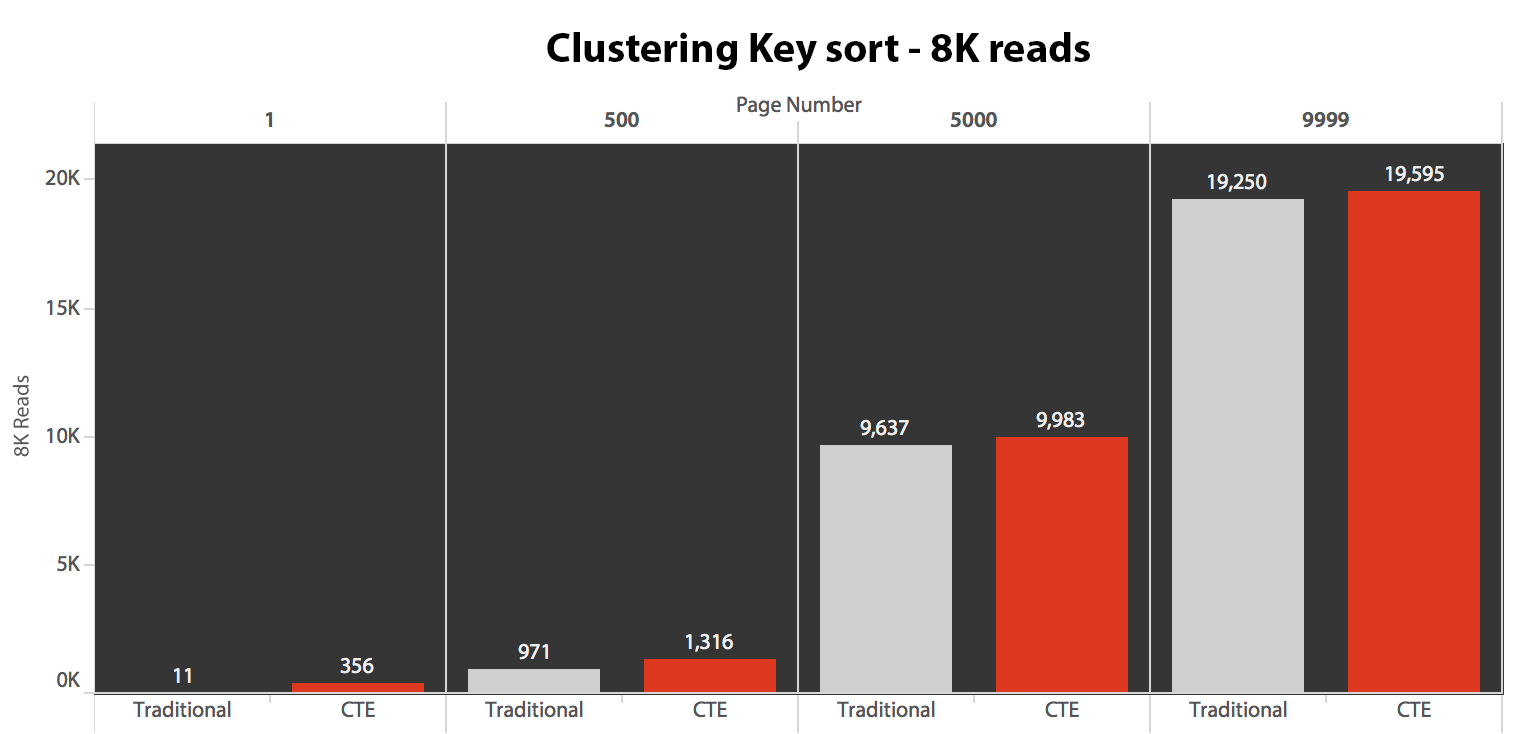
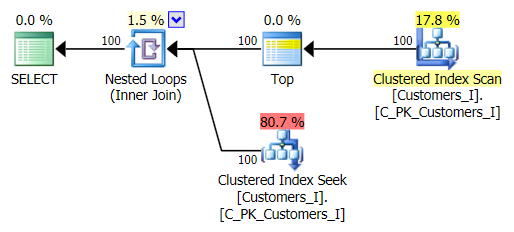
The plan for the default method (as shown in Plan Explorer) in all cases was as follows:

While the plan for the CTE-based method looked like this:
Now, while I/O was the same regardless of caching (just a lot more read-ahead reads in the cold cache scenario), I measured the duration with a cold cache and also with a warm cache (where I commented out the DROPCLEANBUFFERS commands and ran the queries multiple times before measuring). These durations looked like this:
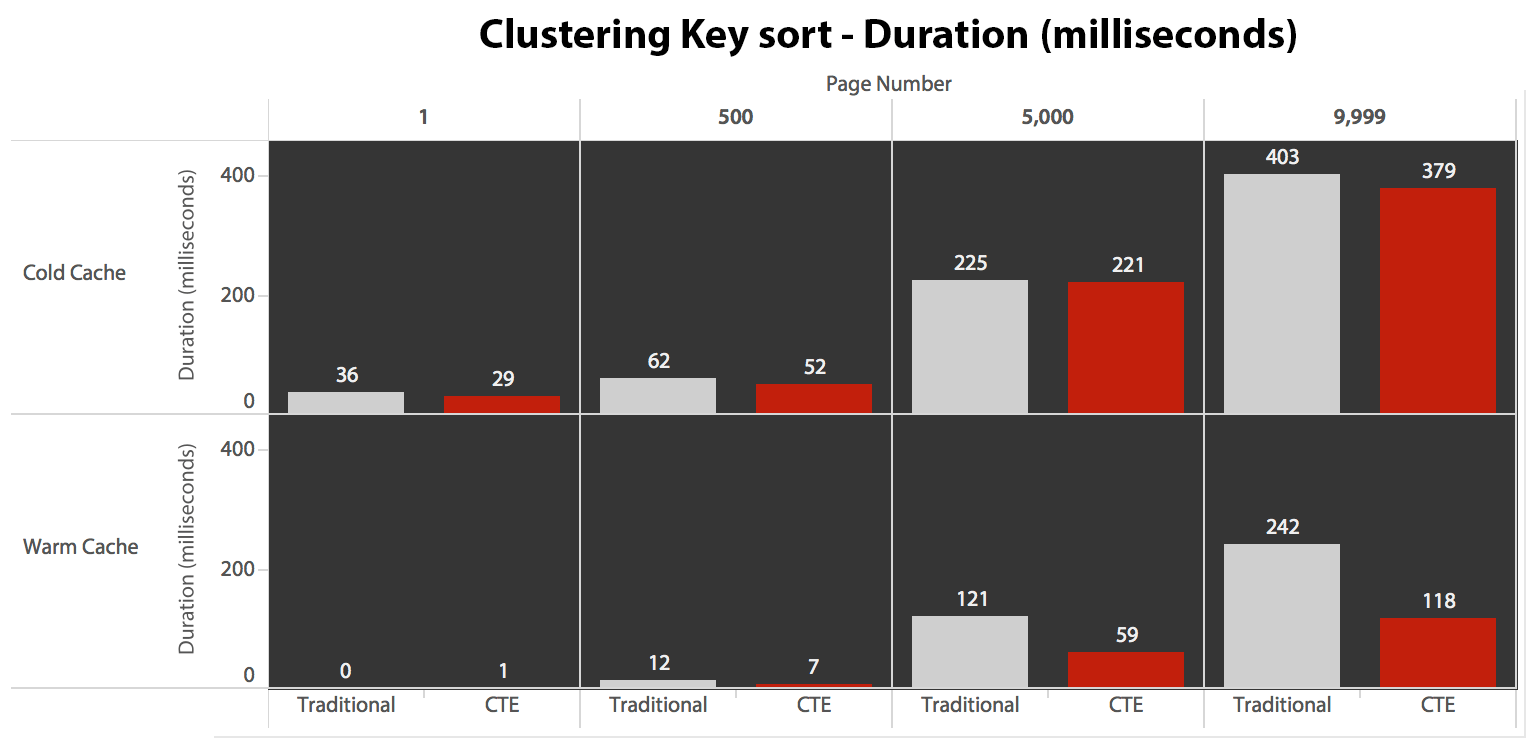
While you can see a pattern that shows duration increasing as the page number gets higher, keep the scale in mind: to hit rows 999,801 -> 999,900, we're talking half a second in the worst case and 118 milliseconds in the best case. The CTE approach wins, but not by a whole lot.
Testing the phone book sort
Next, I tested the second case, where the sorting was supported by a non-covering index on LastName, FirstName. The query above just changed all instances of Test_1 to Test_2. Here were the reads using a cold cache:
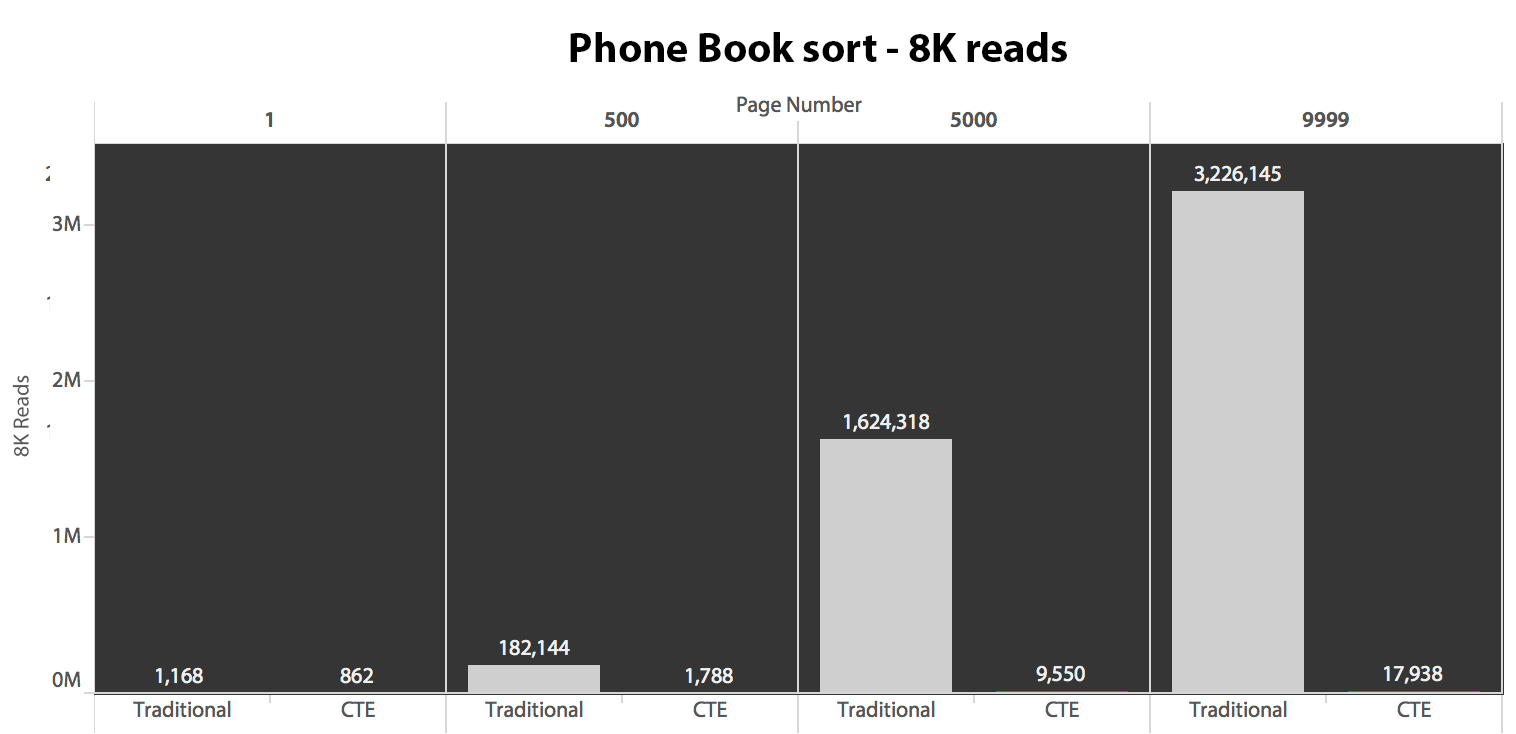
(The reads under a warm cache followed the same pattern – the actual numbers differed slightly, but not enough to justify a separate chart.)
When we're not using the clustered index to sort, it is clear that the I/O costs involved with the traditional method of OFFSET/FETCH are far worse than when identifying the keys first in a CTE, and pulling the rest of the columns just for that subset.
Here is the plan for the traditional query approach:
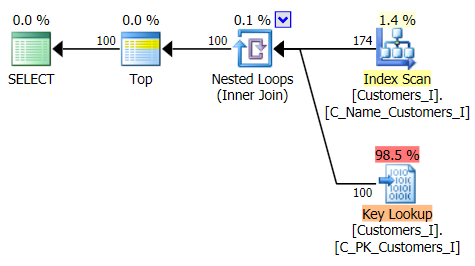
And the plan for my alternate, CTE approach:
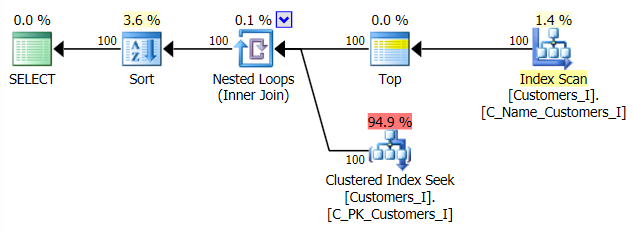
Finally, the durations:
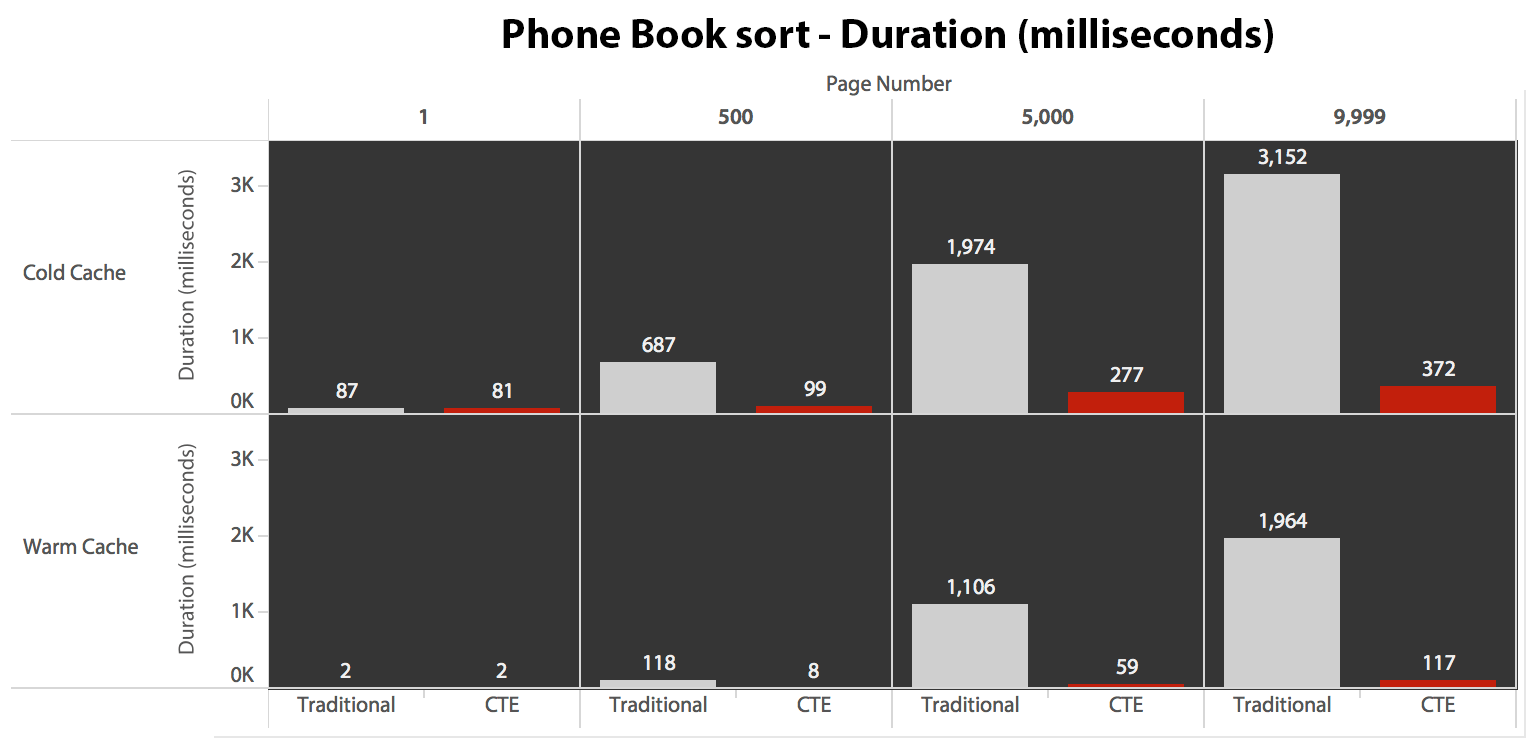
The traditional approach shows a very obvious upswing in duration as you march toward the end of the pagination. The CTE approach also shows a non-linear pattern, but it is far less pronounced and yields better timing at every page number. We see 117 milliseconds for the second-to-last page, versus the traditional approach coming in at almost two seconds.
Testing the user-defined sort
Finally, I changed the query to use the Test_3 stored procedures, testing the case where the sort was defined by the user and did not have a supporting index. The I/O was consistent across each set of tests; the graph is so uninteresting, I'm just going to link to it. Long story short: there were a little over 19,000 reads in all tests. The reason is because every single variation had to perform a full scan due to the lack of an index to support the ordering. Here is the plan for the traditional approach:
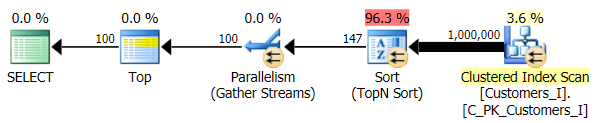
And while the plan for the CTE version of the query looks alarmingly more complex…
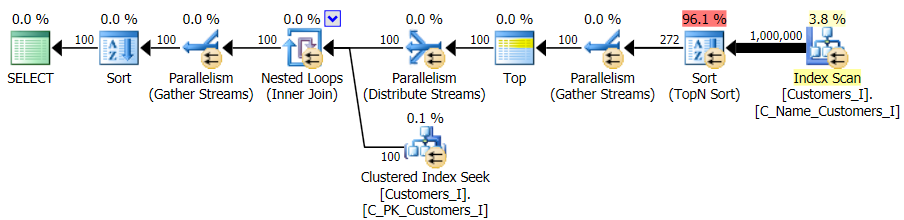
…it leads to lower durations in all but one case. Here are the durations:
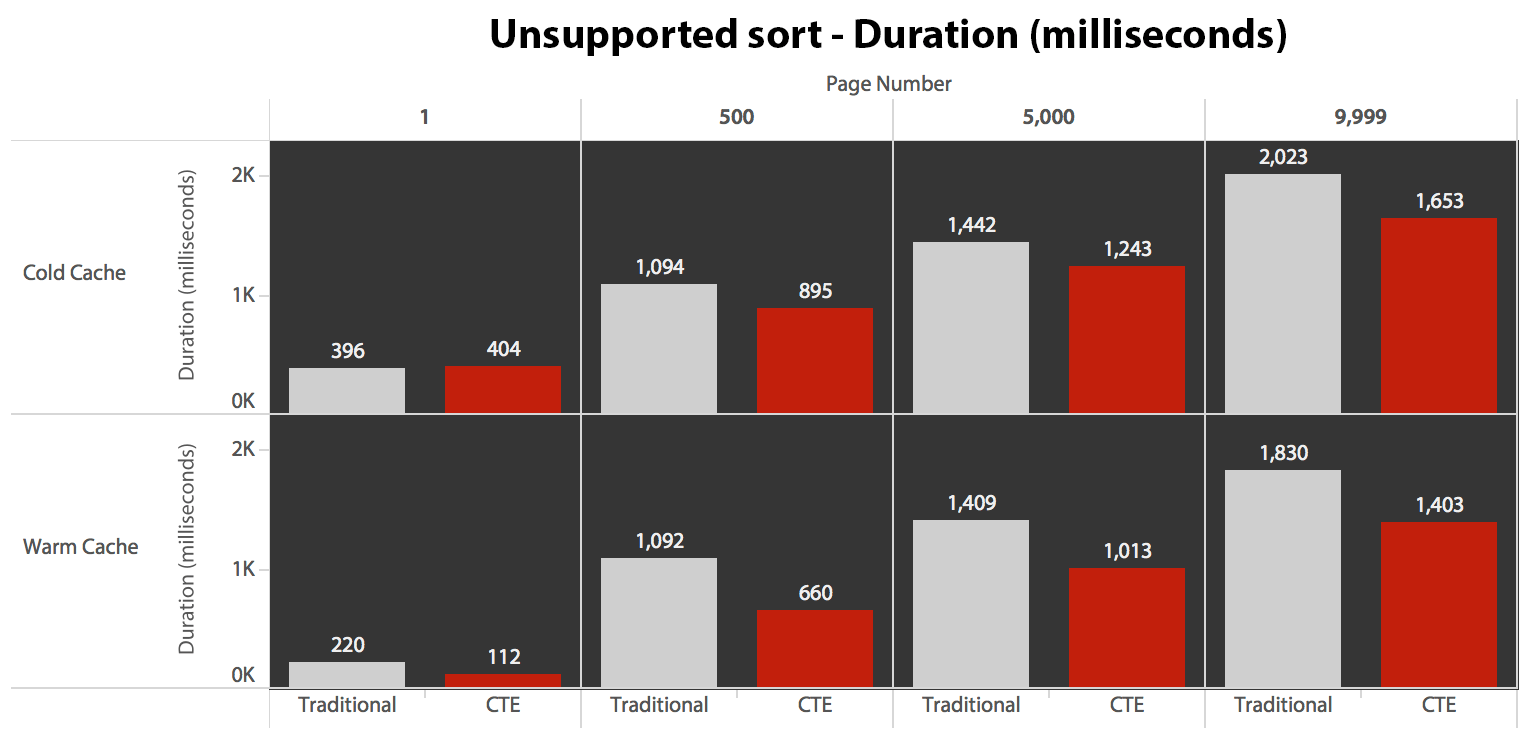
You can see that we can't get linear performance here using either method, but the CTE does come out on top by a good margin (anywhere from 16% to 65% better) in every single case except the cold cache query against the first page (where it lost by a whopping 8 milliseconds). Also interesting to note that the traditional method isn't helped much at all by a warm cache in the "middle" (pages 500 and 5000); only toward the end of the set is any efficiency worth mentioning.
Higher volume
After individual testing of a few executions and taking averages, I thought it would also make sense to test a high volume of transactions that would somewhat simulate real traffic on a busy system. So I created a job with 6 steps, one for each combination of query method (traditional paging vs. CTE) and sort type (clustering key, phone book, and unsupported), with a 100-step sequence of hitting the four page numbers above, 10 times each, and 60 other page numbers chosen at random (but the same for each step). Here is how I generated the job creation script:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';';Here is the resulting job step list and one of the step's properties:
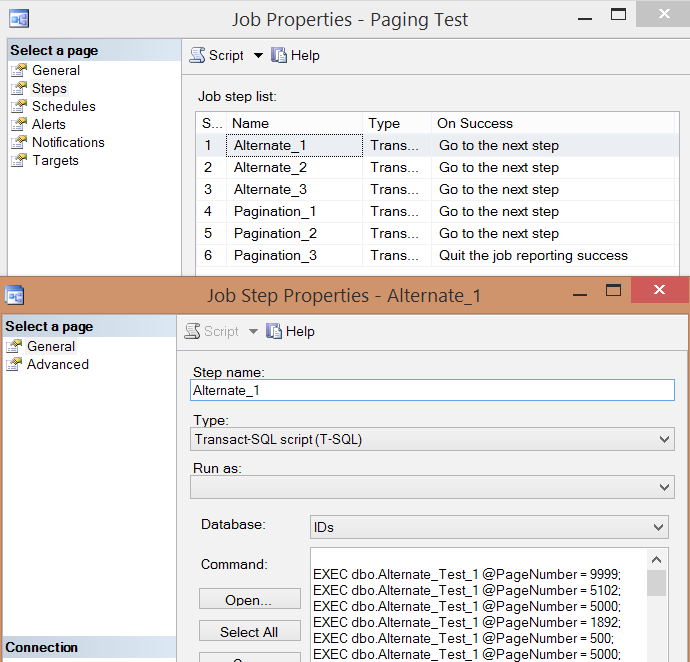
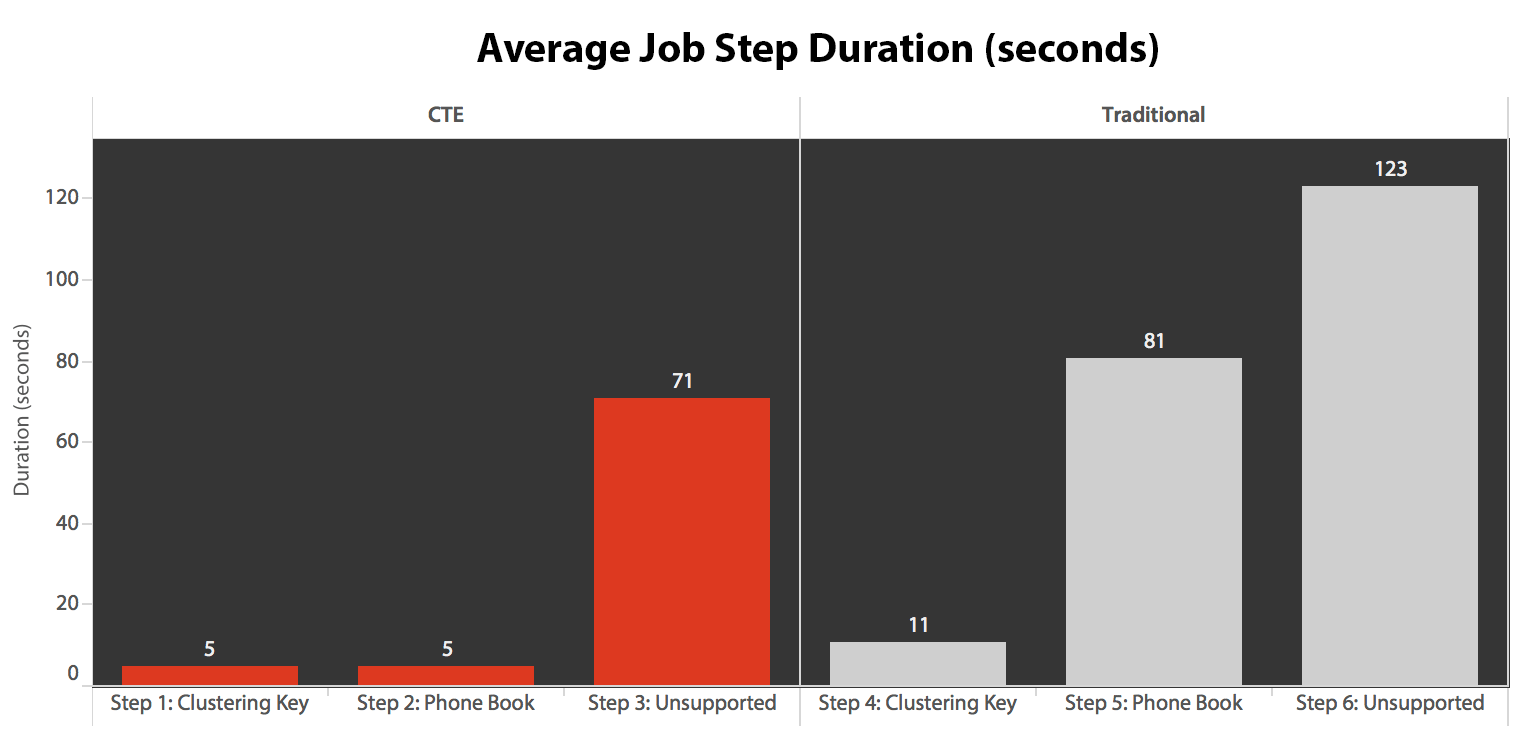
I ran the job five times, then reviewed the job history, and here were the average runtimes of each step:
I also correlated one of the executions on the SQL Sentry Event Manager calendar…
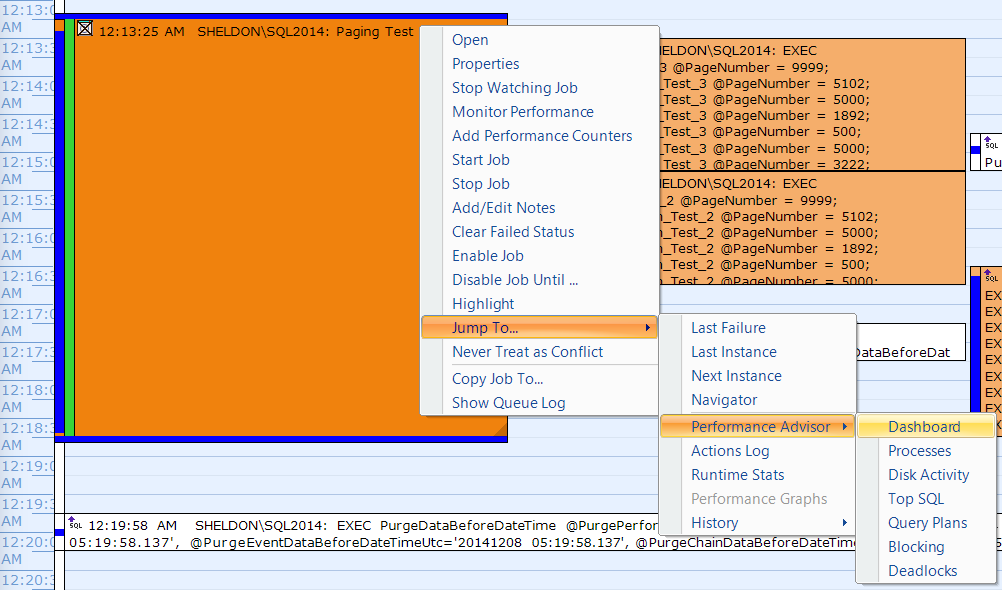
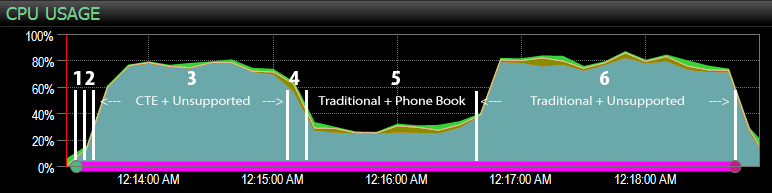
…with the SQL Sentry dashboard, and manually marked roughly where each of the six steps ran. Here is the CPU usage chart from the Windows side of the dashboard:
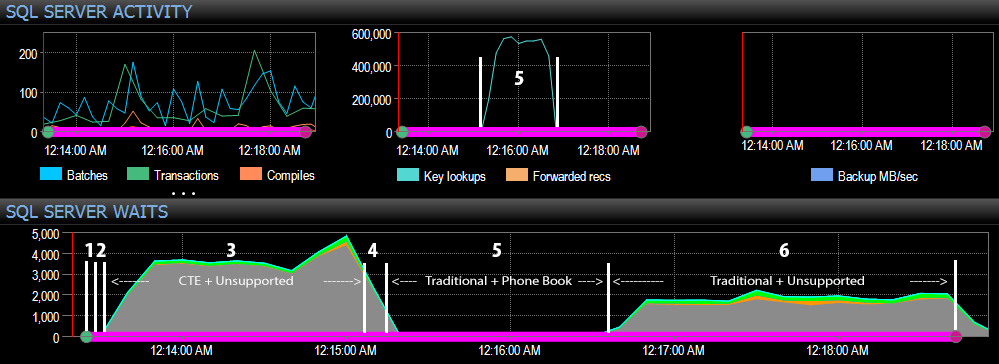
And from the SQL Server side of the dashboard, the interesting metrics were in the Key Lookups and Waits graphs:
The most interesting observations just from a purely visual perspective:
- CPU is pretty hot, at around 80%, during step 3 (CTE + no supporting index) and step 6 (traditional + no supporting index);
- CXPACKET waits are relatively high during step 3 and to a lesser extent during step 6;
- you can see the massive jump in key lookups, to almost 600,000, in about a one-minute span (correlating to step 5 – the traditional approach with a phone book-style index).
In a future test – as with my previous post on GUIDs – I'd like to test this on a system where the data doesn't fit into memory (easy to simulate) and where the disks are slow (not so easy to simulate), since some of these results probably do benefit from things not every production system has – fast disks and sufficient RAM. I also should expand the tests to include more variations (using skinny and wide columns, skinny and wide indexes, a phone book index that actually covers all of the output columns, and sorting in both directions). Scope creep definitely limited the extent of my testing for this first set of tests.
How to improve SQL Server pagination
Pagination doesn't always have to be painful; SQL Server 2012 certainly makes the syntax easier, but if you just plug the native syntax in, you might not always see a great benefit. Here I have shown that slightly more verbose syntax using a CTE can lead to much better performance in the best case, and arguably negligible performance differences in the worst case. By separating data location from data retrieval into two different steps, we can see a tremendous benefit in some scenarios, outside of higher CXPACKET waits in one case (and even then, the parallel queries finished faster than the other queries displaying little or no waits, so they were unlikely to be the "bad" CXPACKET waits everyone warns you about).
Still, even the faster method is slow when there is no supporting index. While you may be tempted to implement an index for every possible sorting algorithm a user might choose, you may want to consider providing fewer options (since we all know that indexes aren't free). For example, does your application absolutely need to support sorting by LastName ascending *and* LastName descending? If they want to go directly to the customers whose last names start with Z, can't they go to the *last* page and work backward? That's a business and usability decision more than a technical one, just keep it as an option before slapping indexes on every sort column, in both directions, in order to get the best performance for even the most obscure sorting options.
33 thoughts on “Pagination with OFFSET / FETCH : A better way”
Comments are closed.

Pagination is common enough that SQL Server should simply rewrite to use the "CTE trick". That one can actually be used in places unrelated to paging in order to convert sorts on big amounts of data to smaller sorts with lookups. Should be a standard rewrite.
Awesome article!
With the "CTE trick" I was able to reduce the execution time drastically.
What if there is the need to get the total of rows in your query example? (alternate approach)
You can do this:
CREATE PROCEDURE dbo.Alternate_Test_WithCount @PageNumber INT = 1, @PageSize INT = 100 AS BEGIN SET NOCOUNT ON; ;WITH pg AS ( SELECT CustomerID, c = COUNT(*) OVER() FROM dbo.Customers_I ORDER BY CustomerID OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT c.CustomerID, c.FirstName, c.LastName, c.EMail, c.Active, c.Created, c.Updated, TotalRowCount = c FROM dbo.Customers_I AS c INNER JOIN pg ON pg.CustomerID = c.CustomerID ORDER BY c.CustomerID OPTION (RECOMPILE); ENDHowever, this is about 20X as expensive. I wouldn't do this as part of the paging procedure – I would calculate the count in a single query all by itself, every time a new set of criteria or sorting are passed. If there is no filtering, you can get this count from
sys.partitionsinstead of from the table.Nice Article,
Kindly correct; that your all tests has been performed with Option RECOMPILE; If yes, then is it practical for production/UAT servers?
What impact if RECOMPILE is skipped?
Thank You
OPTION (RECOMPILE) was just for my tests, but you still may want to use it depending on how you actually structure your SQL, whether you allow dynamic sorting, etc. One single plan hardly fits all and the cost of recompile should be extremely minor.
The plan for the CTE approach for the phone book sort is worse than the traditional query approach. It needs a sort and memory for it. Why is it faster?
Hi Bruno, this is because the I/O involved with the scan and key lookups costs a lot more than the sort does (which may change if the sort spilled to disk for some reason). Don't always assume that a sort is a bad thing.
Very interesting. The only / main problem I see is, when the end user adds a filtering that is not covered by the CTE (e.g. because he filtered for a column that was joined in the main query).
In this case we would have e.g. 100 CTE rows but only e.g. 7 result rows (if the condition was very specific)
@Thomas Any filtering should happen within the CTE, not afterward. Especially if you're using those row_number values for display.
I think I get it now. Your plans are for the first page. Plans for other pages show that the number of key lookups/seeks goes way down: http://i.imgur.com/6yPYiPo.png
I combined James M's answer here: http://stackoverflow.com/questions/12352471/getting-total-row-count-from-offset-fetch-next, with your demo, and had great results. Something like:
with
cte_maxRows as (
select count(*) as totalRows from base.OneMillionPeople
),
cte_idsOnPage as (
select [id]
from base.OneMillionPeople
order by firstName asc,lastName desc
offset 400000 rows fetch first 25 rows only
)
select pIds.[id],totalRows,[firstName],[lastName]
from cte_idsOnPage pIds
inner join base.OneMillionPeople t on pIds.id = t.id,cte_maxRows
order by firstName asc,lastName desc
@Aaron if you filter within the CTE, and your filter contains field not in the clustered index, don't you still end up with a table scan in the CTE?
also, does the CTE style work if some of the filter params are from joined tables?
Not necessarily – your filters could be against columns in the non-clustered index, for example, which will include the clustering key, so doing this filtering early instead of against a wider index or the entire table may still be beneficial.
I think it's possible, but it all depends – are the join and filter columns indexed? The benefit of the CTE is that it eliminates rows as cheaply as possible, e.g. using the skinniest index/key, giving the optimizer a chance (well, almost forcing its hand) to defer grabbing the rest of the columns until it has whittled down to the page of rows you're after. You can't use the CTE to define the 10 rows you want and then apply subsequent filtering, because you may end up with fewer or even 0 rows. But it's possible that moving the join into the CTE to filter out rows, and then again deferring the retrieval of the rest of the columns until later, may still pay off. There are no guarantees, it's something you'd just have to test.
Thanks for the quick reply, this definitely helps… I'm going to try it out in all these ways. I've got many optional search parameters and on the order of 10 million rows to search through, and I'm just looking for the best way possible paginate the results. Definitely follow as well on the point of making all the join and filter columns indexed.
If you have a lot of optional parameters, there may not be an optimal way to support all permutations efficiently, so you may just have to concede that some types of searches will be slower.
What I would do in that scenario is combine the CTE approach here with my solution to what I call "the kitchen sink"… this way at least you have a fighting chance to only pay for the expensive plans when the set of parameters dictates that you do so; in other cases, the dynamic SQL can construct the CTE without the join or without certain filters so that sometimes you will get decent performance. I don't have anything ready-made to demonstrate this but it sounds like it might be a worthwhile follow-up.
Too many levels deep on the other comment thread but, regarding your kitchen sink article – that's exactly what I am doing. I've used the concept before in stored procedures like you have shown. This time around I am doing the same thing, but with a java application (using native SQL calls over JDBC, using a library called sql2o). My optional search parameters are coming in from query parameters in a REST API, and these complex search queries live in the data access layer ("repositories"). I think the original article that got me down this path was this one:
http://www.sommarskog.se/dyn-search.html
The performance so far with the kitchen sink approach has been acceptable with about ~half a million rows, but I'm worried that once I get more production like volume in my test system, and optimistically to allow for future growth, that it will need some extra "tweaks" like the CTE approach. I guess in the end, I will just have to experiment and see what works best.
Cheers,
Jim
the plan for the alternate, CTE approach (phonebook ordering) contains a sort.
This shouldn't be needed as the rows are already in the desired order.
If you project the sort columns from the CTE and join onto it instead of using EXISTS you can get rid of the sort operator whilst still ensuring the desired presentation order.
;WITH pg
AS (SELECT CustomerID,
LastName,
FirstName
FROM dbo.Customers_I
ORDER BY LastName,
FirstName
OFFSET @PageSize * (@PageNumber – 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID,
c.FirstName,
c.LastName,
c.EMail,
c.Active,
c.Created,
c.Updated
FROM dbo.Customers_I AS c
JOIN pg
ON pg.CustomerID = c.CustomerID
ORDER BY pg.LastName,
pg.FirstName
OPTION (RECOMPILE);
I was thinking about the same thing, but from a different angle. I think it would be more economic to simply join to the pg table, not the other way around, then you wouldn't need the order by at all IMO
What do you mean? A user won't be happy if their 100 results are listed in some arbitrary order… you need an ORDER BY to pick the right 100 rows, and you also need to present those 100 rows to the end user in a predictable / repeatable way. You can't just whisk away the outer ORDER BY because then the ordered results aren't guaranteed.
with pg( select id from table order by columns offset x rows fetch next y rows only )
select t.*
from pg
inner join table t on t.id=pg.id
this way you don't need the 2nd order, and I've tested it, it takes less reads
My point remains: Output order of the final resultset is not guaranteed without an outer ORDER BY. It may work great in your one single test case today, but that doesn't mean it will work tomorrow (e.g. after data growth, index changes, etc.) or that it work at all in other cases.
You are right! Sorry :)
Great Explanation from the expert, it's really helped me.
Aaron, in some use cases, it is possible to use the clustered primary key for pagination (select top N … where Id > @Id ). In such cases, if we always order by that PK column last (after arbitrary sorts requested by user), it performs better than the CTE with offset, because less rows have to be read.
CREATE PROCEDURE dbo.Alternate_Test_4
@First INT = 100,
@AfterID INT = 0
AS
BEGIN
SET NOCOUNT ON;
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE c.CustomerID > @AfterID
ORDER BY FirstName DESC, EMail, CustomerID OPTION (RECOMPILE);
END
This will actually do better the closer to the end you get. It does 8 logical reads for the equivalent of Page 9999, for example (compared to the constant 17, 418 across all pages for Alternative_Test_3).
For "page 1", it has about the same number of logical reads.
The downside to this approach is that there is no more random seeking. E.g., if you wanted to a list with pagination, i.e., links with page 1 to 50, and have the user be able to click on one to go to it, that is no longer possible.
That's what I'm using, right, in the case of the clustering key sort? The problem is this only works if you want the output to sort in clustering key order.
Yea, but for the ones that include user specified sort order (FirstName, Email), you don't include it (the clustering key). The sort I'm suggesting, (as an alternative to the strategy and query in Alternate_Test_3) has this order:
FirstName DESC, EMail, CustomerID
If you include the clustering key (CustomerID) like this, you can use it for paging, even though the output is *not* sorted in clustering key order (unless FirstName and Email are equal for all rows).
I rewired it a bit so I could get the total record count, but it only runs on the first page, and I can pass in sort, date search, filters, etc
@Jim – that's what I was thinking. I think the performance gains are just from the fact that the query doing the table scan is pulling only one column, thereby minimizing the cost of the table scan. It's not avoiding the scan. Still clever, though. (And like @tabi said above, this optimization ought to be built-in.)
I create stored procedure as
`
CREATE PROCEDURE [dbo].[spBaseVoterIndex]
@SortCol NVARCHAR(128) = 0,
@SortDir VARCHAR(4) = 'asc',
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT id
FROM dbo.base_voter
WITH(NOLOCK)
ORDER BY id
OFFSET @PageSize * (@PageNumber – 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT b.id, b.name_voter, b.home_street_address_1,b.home_address_city
FROM dbo.base_voter AS b
WITH(NOLOCK)
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.id = b.id)
ORDER BY
case when (@SortCol = 0 and @SortDir='asc')
then name_voter
end asc,
case when (@SortCol = 0 and @SortDir='desc')
then name_voter
end desc,
case when (@SortCol = 1 and @SortDir='asc')
then home_street_address_1
end asc,
case when (@SortCol = 1 and @SortDir='desc')
then home_street_address_1
end desc,
case when (@SortCol = 2 and @SortDir='asc')
then home_address_city
end asc,
case when (@SortCol = 2 and @SortDir='desc')
then home_address_city
end desc
OPTION (RECOMPILE);
END
`
Here I have also created index as :
`
CREATE NONCLUSTERED INDEX FIBaseVoterWithDeletedAt
ON dbo.base_voter (name_voter asc,home_street_address_1 asc, home_address_city asc)
WHERE deleted_at IS NULL ;
GO
`
Now, whenever I query with low page number it works fine but with higher pagenumber the query time increases drastically. How can I deal with it. I am trying this with around 50M+ data.
Your 3rd approach is quite difficult to understand. Any help would be appreciated.
This is a very strange (and wrong) query.
– the index will not help, to use the index, you have to add at leaste a WHERE deleted_at IS NULL to your query
– the CTE (WITH pg AS)… makes absolut no sense in this case and will slow down the query
– the CTE will lead to wrong results, since you get only the first x IDs and order them depending on the parameter. But usually would like to have the first x Names in the list.
-> get rid of the CTE and place the OFFSET / FETCH at the end of your query
– the reason for the CTE in this article was to prevent unneccessary JOINs to be executed (for to many rows), but since you are not joining, it would harm more than be helpful
– @SortCol should defined as TINYINT and not as NVARCHAR
– OPTION (RECOMPILE) is correct in this case, but if the query would be used very often, it would make sense to create 6 different procedures (one for each sort order) and call them in the "main procedure" depending on the sort parameters
– you will need three indexes (one for name, one for the street and one for the city), which includes (!) the other fields.:
CREATE NONCLUSTERED INDEX FIBaseVoter_name_undeleted
ON dbo.base_voter (name_voter, ID) INCLUDE (home_street_address_1 , home_address_city)
WHERE deleted_at IS NULL ;
GO
CREATE NONCLUSTERED INDEX FIBaseVoter_street_undeleted
ON dbo.base_voter (home_street_address_1, ID) INCLUDE ( name_voter, home_address_city)
WHERE deleted_at IS NULL ;
GO
CREATE NONCLUSTERED INDEX FIBaseVoter_ciry_undeleted
ON dbo.base_voter (home_address_city, ID) INCLUDE (home_street_address_1 , name_voter)
WHERE deleted_at IS NULL ;
GO
– the result of your query may change depending on the actual execution plan (e.g. parallelisation). To have every time the same rows in the same order returned, you would have to add the ID as last ORDER BY field