
UI Design Patterns That Don't Scale
Guest Author : Michael J Swart (@MJSwart)
I spend a large amount of time translating software requirements into schema and queries. These requirements are sometimes easy to implement but are often difficult. I want to talk about UI design choices that lead to data access patterns that are awkward to implement using SQL Server.
Sort By Column
Sort-By-Column is such a familiar pattern that we can take it for granted. Every time we interact with software that displays a table, we can expect the columns to be sortable like this:
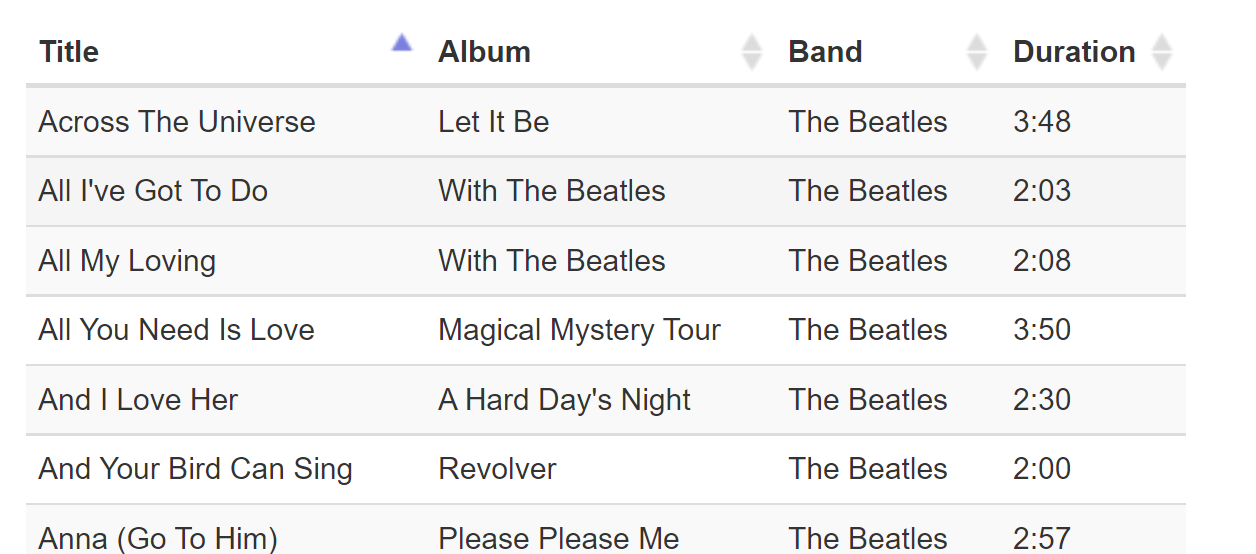
Sort-By-Colunn is a great pattern when all the data can fit in the browser. But if the data set is billions of rows large this can get awkward even if the web page only requires one page of data. Consider this table of songs:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band);
And consider these four queries sorted by each column:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title;
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album;
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band;
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
Even for a query this simple, there are different query plans. The first two queries use covering indexes:

The third query needs to do a key lookup which is not ideal:

But the worst is the fourth query which needs to scan the whole table and do a sort in order to return the first 20 rows:
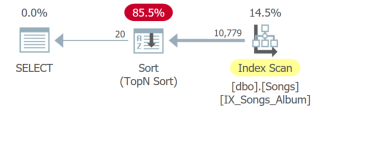
The point is that even though the only difference is the ORDER BY clause, those queries have to be analyzed separately. The basic unit of SQL tuning is the query. So if you show me UI requirements with ten sortable columns, I’ll show you ten queries to analyze.
When does this get awkward?
The Sort-By-Column feature is a great UI pattern, but it can get awkward if the data comes from a huge growing table with many, many columns. It may be tempting to create covering indexes on every column, but that has other tradeoffs. Columnstore indexes may help in some circumstances, but that introduces another level of awkwardness. There’s not always an easy alternative.
Paged Results
Using paged results is a good way to not overwhelm the user with too much information all at once. It’s also a good way to not overwhelm the database servers … usually.
Consider this design:

The data behind this example requires counting and processing the entire dataset in order to report the number of results. The query for this example might use syntax like this:
...
ORDER BY LastModifiedTime
OFFSET @N ROWS
FETCH NEXT 25 ROWS ONLY;
It’s convenient syntax, and the query only produces 25 rows. But just because the result set is small, it doesn’t necessarily mean that it’s cheap. Just like we saw with the Sort-By-Column pattern, a TOP operator is only cheap if it doesn’t need to sort a lot of data first.
Asynchronous Page Requests
As a user navigates from one page of results to the next, the web requests involved can be separated by seconds or minutes. This leads to issues that look a lot like the pitfalls that are seen when using NOLOCK. For example:
SELECT [Some Columns]
FROM [Some Table]
ORDER BY [Sort Value]
OFFSET 0 ROWS
FETCH NEXT 25 ROWS ONLY;
-- wait a little bit
SELECT [Some Columns]
FROM [Some Table]
ORDER BY [Sort Value]
OFFSET 25 ROWS
FETCH NEXT 25 ROWS ONLY;
When a row is added in between the two requests, the user might see the same row twice. And if a row is removed, the user might miss a row as they navigate the pages. This Paged-Results pattern is equivalent to “Give me rows 26-50”. When the real question should be “Give me the next 25 rows”. The difference is subtle.
Better Patterns
With Paged-Results, that “OFFSET @N ROWS” may take longer and longer as @N grows. Instead consider Load-More buttons or Infinite-Scrolling. With Load-More paging, there’s at least a chance to make efficient use of an index. The query would look something like:
SELECT [Some Columns]
FROM [Some Table]
WHERE [Sort Value] > @Bookmark
ORDER BY [Sort Value]
FETCH NEXT 25 ROWS ONLY;
It still suffers from some of the pitfalls of asynchronous page requests, but because of the bookmark, the user will pick up where they left off.
Searching Text For Substring
Searching is everywhere on the internet. But what solution should be used on the back end? I want to warn against searching for a substring using SQL Server’s LIKE filter with wildcards like this:
SELECT Title, Category
FROM MyContent
WHERE Title LIKE '%' + @SearchTerm + '%';
It can lead to awkward results like this:
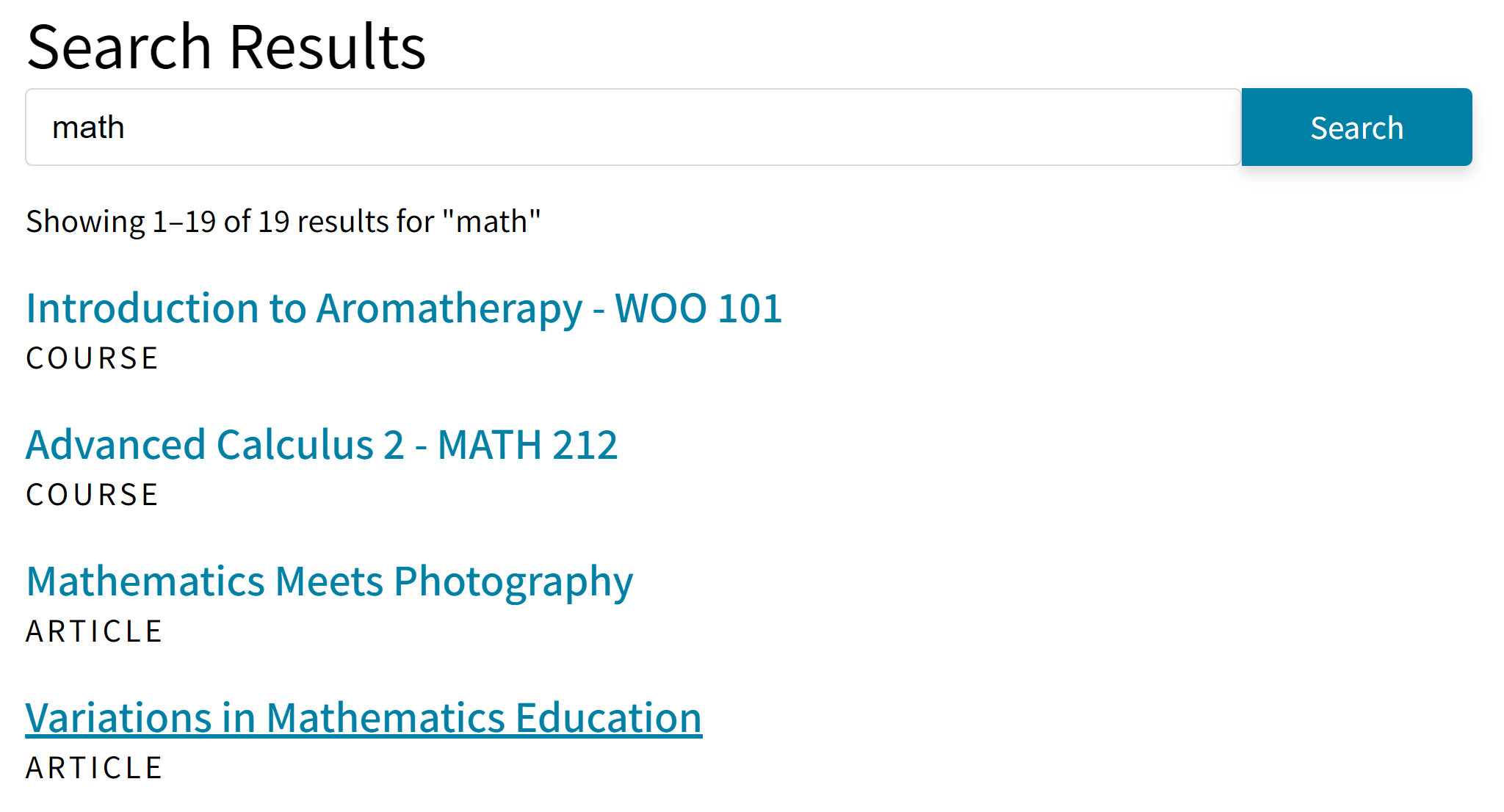
“Aromatherapy” is probably not a good hit for the search term “math.” Meanwhile, the search results are missing articles that only mention Algebra or Trigonometry.
It can also be very difficult to pull off efficiently using SQL Server. There’s no straightforward index that supports this kind of search. Paul White gave one tricky solution with Trigram Wildcard String Search in SQL Server. There are also difficulties that can occur with collations and Unicode. It can become an expensive solution for a not-so-good user experience.
What To Use Instead
SQL Server’s Full-Text Search seems like it could help, but I’ve personally never used it. In practice, I’ve only seen success in solutions outside of SQL Server (e.g. Elasticsearch).
Conclusion
In my experience I’ve found that software designers are often very receptive to feedback that their designs are sometimes going to be awkward to implement. When they’re not, I’ve found it useful to highlight the pitfalls, the costs, and the time to delivery. That kind of feedback is necessary to help build maintainable, scalable solutions.
About the Author
 Michael J Swart is a passionate database professional and blogger who focuses on database development and software architecture. He enjoys speaking about anything data related, contributing to community projects. Michael blogs as "Database Whisperer" at michaeljswart.com.
Michael J Swart is a passionate database professional and blogger who focuses on database development and software architecture. He enjoys speaking about anything data related, contributing to community projects. Michael blogs as "Database Whisperer" at michaeljswart.com.
One pattern I see often is a query that takes a generic @SearchString
— usually nvarchar(max) — and that gets used to search across many columns via a series of OR filters. Quite a mess, that. Numbers, names, dates, etc. Ick.