
String Aggregation Over the Years in SQL Server
Since SQL Server 2005, the trick of using FOR XML PATH to denormalize strings and combine them into a single (usually comma-separated) list has been very popular. In SQL Server 2017, however, STRING_AGG() finally answered long-standing and widespread pleas from the community to simulate GROUP_CONCAT() and similar functionality found in other platforms. I recently started modifying many of my Stack Overflow answers using the old method, both to improve the existing code and to add an additional example better suited for modern versions.
I was a little appalled at what I found.
On more than one occasion, I had to double-check the code was even mine.
A Quick Example
Let’s look at a simple demonstration of the problem. Someone has a table like this:
CREATE TABLE dbo.FavoriteBands
(
UserID int,
BandName nvarchar(255)
);
INSERT dbo.FavoriteBands
(
UserID,
BandName
)
VALUES
(1, N'Pink Floyd'), (1, N'New Order'), (1, N'The Hip'),
(2, N'Zamfir'), (2, N'ABBA');
On the page showing each user’s favorite bands, they want the output to look like this:
UserID Bands ------ --------------------------------------- 1 Pink Floyd, New Order, The Hip 2 Zamfir, ABBA
In the SQL Server 2005 days, I would have offered this solution:
SELECT DISTINCT UserID, Bands =
(SELECT BandName + ', '
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH(''))
FROM dbo.FavoriteBands AS fb;
But when I look back on this code now, I see many problems I can’t resist fixing.
STUFF
The most fatal flaw in the code above is it leaves a trailing comma:
UserID Bands ------ --------------------------------------- 1 Pink Floyd, New Order, The Hip, 2 Zamfir, ABBA,
To solve this, I often see people wrap the query inside another and then surround the Bands output with LEFT(Bands, LEN(Bands)-1). But this is needless additional computation; instead, we can move the comma to the beginning of the string and remove the first one or two characters using STUFF. Then, we don’t have to calculate the length of the string because it’s irrelevant.
SELECT DISTINCT UserID, Bands = STUFF(
--------------------------------^^^^^^
(SELECT ', ' + BandName
--------------^^^^^^
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH('')), 1, 2, '')
--------------------------^^^^^^^^^^^
FROM dbo.FavoriteBands AS fb;
You can adjust this further if you’re using a longer or conditional delimiter.
DISTINCT
The next problem is the use of DISTINCT. The way the code works is the derived table generates a comma-separated list for each UserID value, then the duplicates are removed. We can see this by looking at the plan and seeing the XML-related operator executes seven times, even though only three rows are ultimately returned:
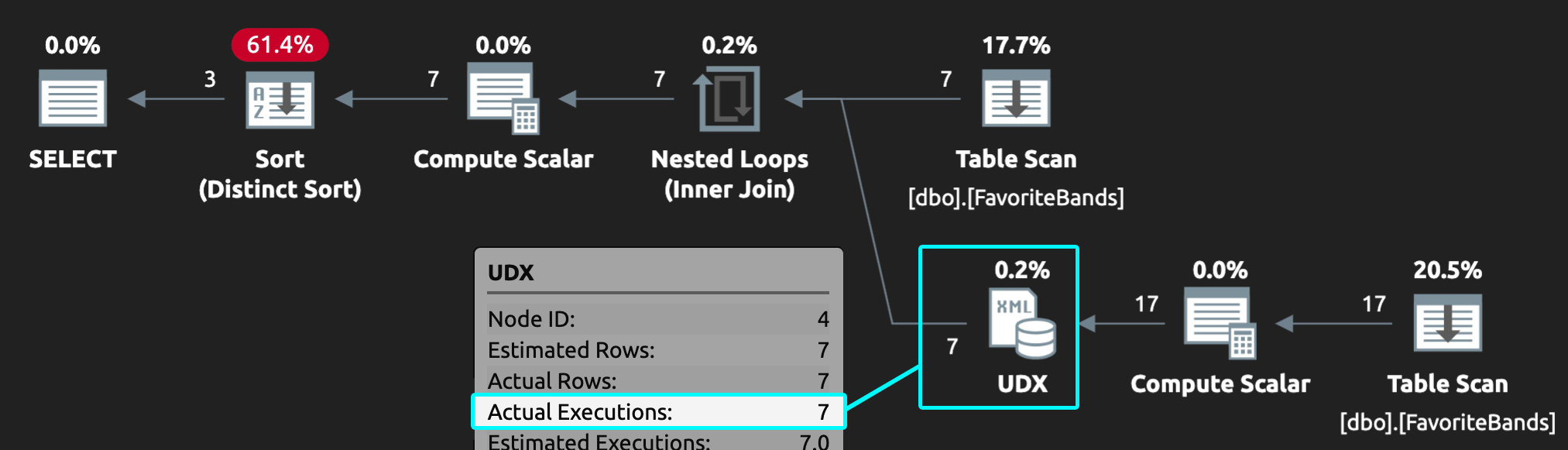 Figure 1: Plan showing filter after aggregation
Figure 1: Plan showing filter after aggregation
If we change the code to use GROUP BY instead of DISTINCT:
SELECT /* DISTINCT */ UserID, Bands = STUFF(
(SELECT ', ' + BandName
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH('')), 1, 2, '')
FROM dbo.FavoriteBands AS fb
GROUP BY UserID;
--^^^^^^^^^^^^^^^
It’s a subtle difference, and it doesn’t change the results, but we can see the plan improves. Basically, the XML operations are deferred until after the duplicates are removed:
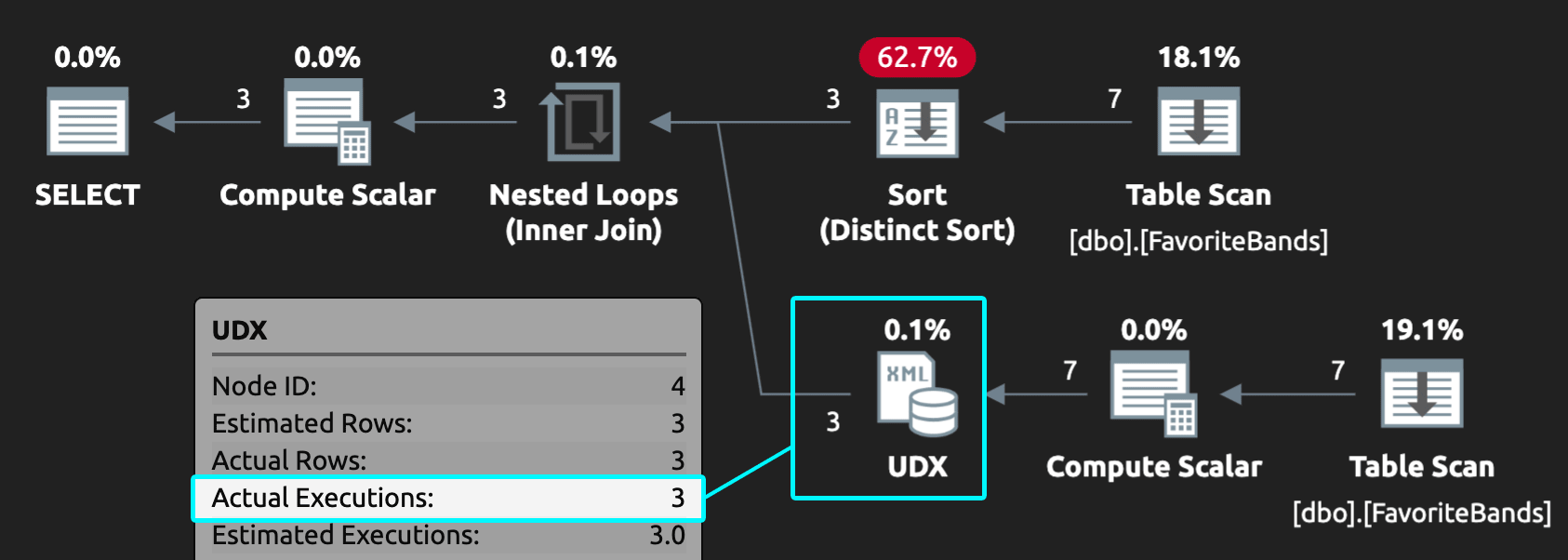 Figure 2: Plan showing filter before aggregation
Figure 2: Plan showing filter before aggregation
At this scale, the difference is immaterial. But what if we add some more data? On my system, this adds a little over 11,000 rows:
INSERT dbo.FavoriteBands(UserID, BandName)
SELECT [object_id], name FROM sys.all_columns;
If we run the two queries again, the differences in duration and CPU are immediately obvious:
 Figure 3: Runtime results comparing DISTINCT and GROUP BY
Figure 3: Runtime results comparing DISTINCT and GROUP BY
But other side effects are also obvious in the plans. In the case of DISTINCT, the UDX once again executes for every row in the table, there’s an excessively eager index spool, there’s a distinct sort (always a red flag for me), and the query has a high memory grant, which can put a serious dent in concurrency:
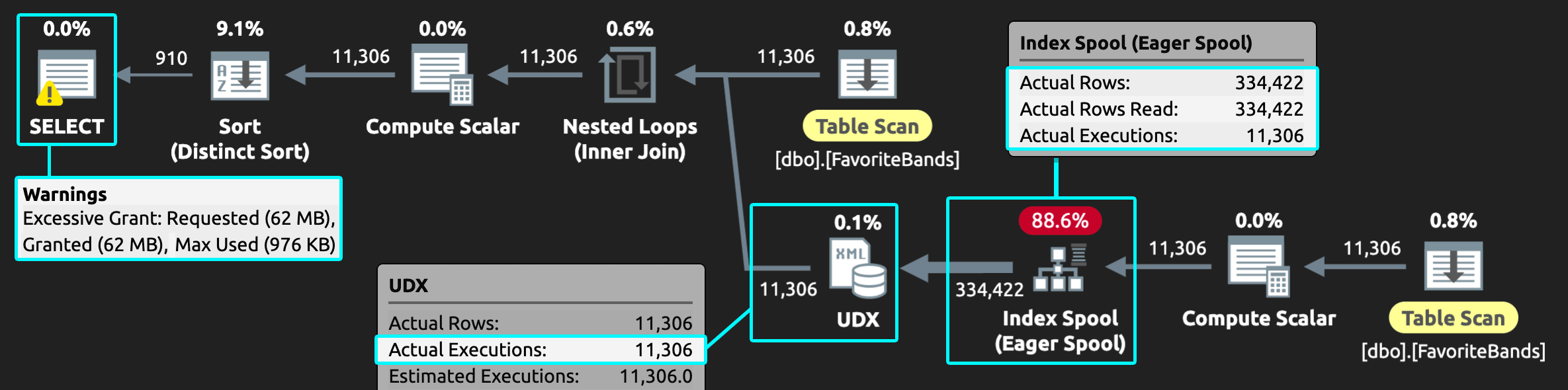 Figure 4: DISTINCT plan at scale
Figure 4: DISTINCT plan at scale
Meanwhile, in the GROUP BY query, the UDX only executes once for each unique UserID, the eager spool reads a much lower number of rows, there’s no distinct sort operator (it’s been replaced by a hash match), and the memory grant is tiny in comparison:
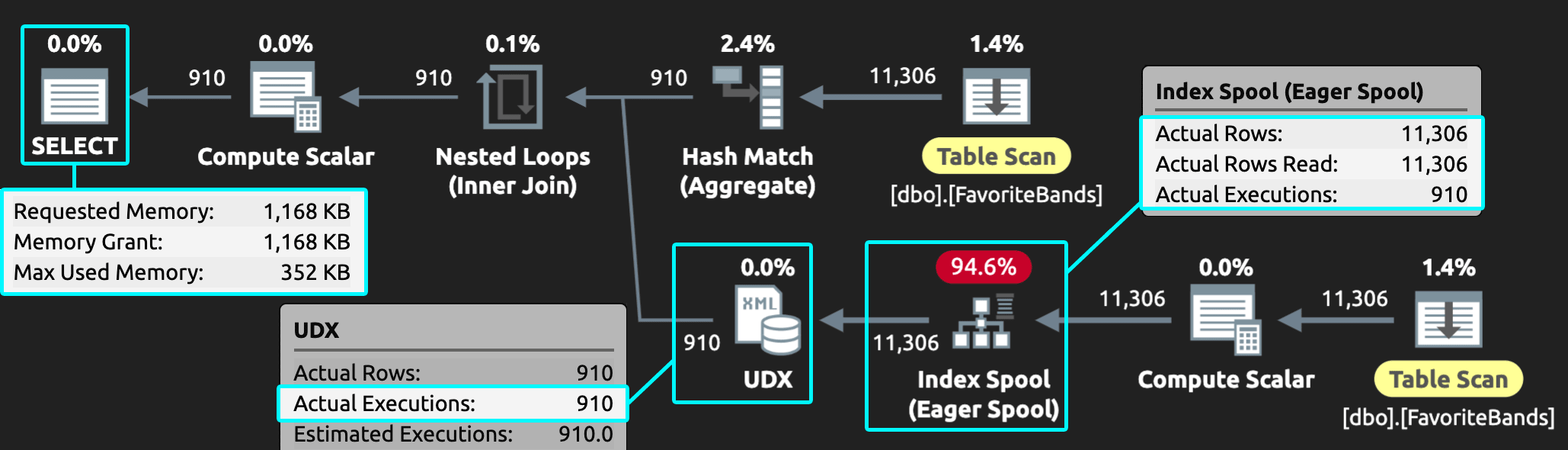 Figure 5: GROUP BY plan at scale
Figure 5: GROUP BY plan at scale
It takes a while to go back and fix old code like this, but for some time now, I’ve been very regimented about always using GROUP BY instead of DISTINCT.
N Prefix
Too many old code samples I came across assumed no Unicode characters would ever be in use, or at least the sample data didn’t suggest the possibility. I’d offer my solution as above, and then the user would come back and say, “but on one row I have 'просто красный', and it comes back as '?????? ???????'!” I often remind people they always need to prefix potential Unicode string literals with the N prefix unless they absolutely know they’ll only ever be dealing with varchar strings or integers. I started being very explicit and probably even overcautious about it:
SELECT UserID, Bands = STUFF(
(SELECT N', ' + BandName
--------------^
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH(N'')), 1, 2, N'')
----------------------^ -----------^
FROM dbo.FavoriteBands AS fb
GROUP BY UserID;
XML Entitization
Another “what if?” scenario not always present in a user’s sample data is XML characters. For example, what if my favorite band is named “Bob & Sheila <> Strawberries”? The output with the above query is made XML-safe, which isn’t what we always want (e.g., Bob & Sheila <> Strawberries). Google searches at the time would suggest “you need to add TYPE,” and I remember trying something like this:
SELECT UserID, Bands = STUFF(
(SELECT N', ' + BandName
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH(N''), TYPE), 1, 2, N'')
--------------------------^^^^^^
FROM dbo.FavoriteBands AS fb
GROUP BY UserID;
Unfortunately, the output data type from the subquery in this case is xml. This leads to the following error message:
Argument data type xml is invalid for argument 1 of stuff function.
You need to tell SQL Server you want to extract the resulting value as a string by indicating the data type and that you want the first element. Back then, I’d add this as the following:
SELECT UserID, Bands = STUFF(
(SELECT N', ' + BandName
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH(N''), TYPE).value(N'.', N'nvarchar(max)'),
--------------------------^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
1, 2, N'')
FROM dbo.FavoriteBands AS fb
GROUP BY UserID;
This would return the string without XML entitization. But is it the most efficient? Last year, Charlieface reminded me Mister Magoo performed some extensive testing and found ./text()[1] was faster than the other (shorter) approaches like . and .[1]. (I originally heard this from a comment Mikael Eriksson left for me here.) I once again adjusted my code to look like this:
SELECT UserID, Bands = STUFF(
(SELECT N', ' + BandName
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
FOR XML PATH(N''), TYPE).value(N'./text()[1]', N'nvarchar(max)'),
------------------------------------------^^^^^^^^^^^
1, 2, N'')
FROM dbo.FavoriteBands AS fb
GROUP BY UserID;
You might observe extracting the value in this way leads to a slightly more complex plan (you wouldn’t know it just from looking at duration, which stays pretty constant throughout the above changes):
![Figure 6: Plan with ./text()[1]](/wp-content/uploads/2022/02/a-screenshot-of-a-computer-description-automatica.png) Figure 6: Plan with ./text()[1]
Figure 6: Plan with ./text()[1]
The warning on the root SELECT operator comes from the explicit conversion to nvarchar(max).
Order
Occasionally, users would express ordering is important. Often, this is simply ordering by the column you’re appending—but sometimes, it can be added somewhere else. People tend to believe if they saw a specific order come out of SQL Server once, it’s the order they’ll always see, but there’s no reliability here. Order is never guaranteed unless you say so. In this case, let’s say we want to order by BandName alphabetically. We can add this instruction inside the subquery:
SELECT UserID, Bands = STUFF(
(SELECT N', ' + BandName
FROM dbo.FavoriteBands
WHERE UserID = fb.UserID
ORDER BY BandName
---------^^^^^^^^^^^^^^^^^
FOR XML PATH(N''),
TYPE).value(N'./text()[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.FavoriteBands AS fb
GROUP BY UserID;
Note this may add a little execution time because of the additional sort operator, depending on whether there’s a supporting index.
STRING_AGG()
As I update my old answers, which should still work on the version that was relevant at the time of the question, the final snippet above (with or without the ORDER BY) is the form you’ll likely see. But you might see an additional update for the more modern form, too.
STRING_AGG() is arguably one of the best features added in SQL Server 2017. It’s both simpler and far more efficient than any of the above approaches, leading to tidy, well-performing queries like this:
SELECT UserID, Bands = STRING_AGG(BandName, N', ')
FROM dbo.FavoriteBands
GROUP BY UserID;
This isn’t a joke; that’s it. Here’s the plan—most importantly, there’s only a single scan against the table:
 Figure 7: STRING_AGG() plan
Figure 7: STRING_AGG() plan
If you want ordering, STRING_AGG() supports this, too (as long as you are in compatibility level 110 or greater, as Martin Smith points out here):
SELECT UserID, Bands = STRING_AGG(BandName, N', ')
WITHIN GROUP (ORDER BY BandName)
----^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FROM dbo.FavoriteBands
GROUP BY UserID;
The plan looks the same as the one without sorting, but the query is a smidge slower in my tests. It’s still way faster than any of the FOR XML PATH variations.
Indexes
A heap is hardly fair. If you have even a nonclustered index the query can use, the plan looks even better. For example:
CREATE INDEX ix_FavoriteBands ON dbo.FavoriteBands(UserID, BandName);
Here’s the plan for the same ordered query using STRING_AGG()—note the lack of a sort operator, since the scan can be ordered:
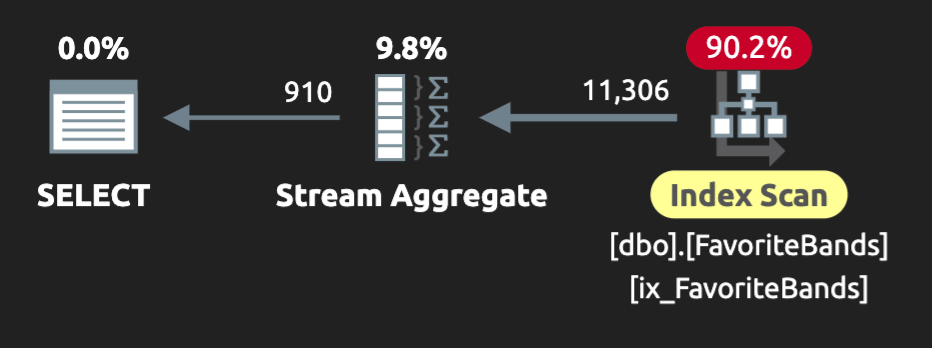 Figure 8: STRING_AGG() plan with a supporting index
Figure 8: STRING_AGG() plan with a supporting index
This shaves some time off, too—but to be fair, this index helps the FOR XML PATH variations as well. Here’s the new plan for the ordered version of that query:
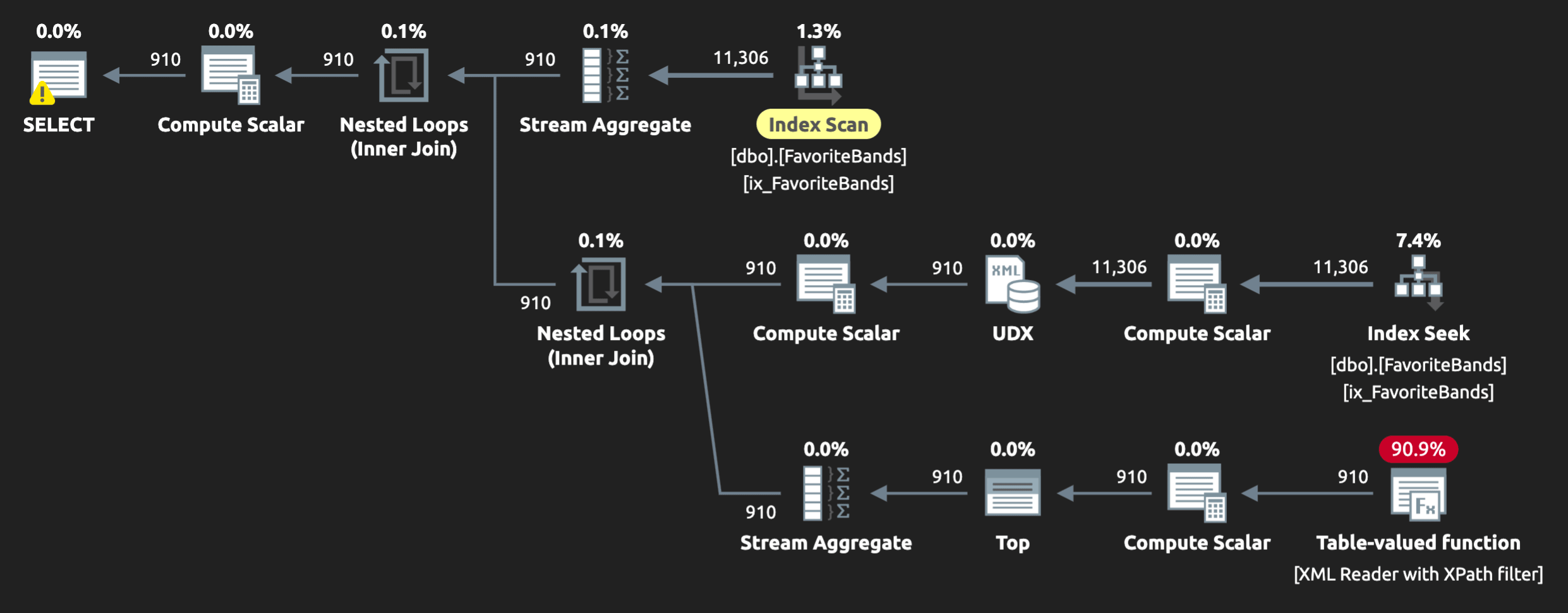 Figure 9: FOR XML PATH plan with a supporting index
Figure 9: FOR XML PATH plan with a supporting index
The plan is a little friendlier than before, including a seek instead of a scan in one spot, but this approach is still significantly slower than STRING_AGG().
A Caveat
There’s a little trick to using STRING_AGG() where, if the resulting string is more than 8,000 bytes, you’ll receive this error message:
STRING_AGG aggregation result exceeded the limit of 8000 bytes. Use LOB types to avoid result truncation.
To avoid this issue, you can inject an explicit conversion:
SELECT UserID,
Bands = STRING_AGG(CONVERT(nvarchar(max), BandName), N', ')
--------------------------^^^^^^^^^^^^^^^^^^^^^^
FROM dbo.FavoriteBands
GROUP BY UserID;
This adds a compute scalar operation to the plan—and an unsurprising CONVERT warning on the root SELECT operator—but otherwise, it has little impact on performance.
Conclusion
If you’re on SQL Server 2017+ and you have any FOR XML PATH string aggregation in your codebase, I highly recommend switching over to the new approach. I did perform some more thorough performance testing back during the SQL Server 2017 public preview here and here you may want to revisit.
A common objection I’ve heard is people are on SQL Server 2017 or greater but still on an older compatibility level. It seems the apprehension is because STRING_SPLIT() is invalid on compatibility levels lower than 130, so they think STRING_AGG() works this way too, but it is a bit more lenient. It is only a problem if you are using WITHIN GROUP and a compat level lower than 110. So improve away!

Nice post!
This is a great reference post.
I usually shorten slightly to 'text()[1]' as the ./ is unnecessary.
Another mistake to trip people up: the third parameter of STUFF is the separator length, so I always replace it with LEN(', ').
Re STRING_SPLIT, there is a way to get it onto lower compat levels: put it into a iTVF on the master DB, and use sp_ms_marksystemobject. Undocumented obviously. See https://stackoverflow.com/a/69928018/14868997
Nice to get a mention, thanks.
Hey Charlie, I talked about a couple ways to work around the compat level issue here:
https://www.mssqltips.com/sqlservertip/6390/sql-server-split-string-replacement-code-with-stringsplit/