
Number series generator challenge solutions – Part 2
This is the second part in a series about solutions to the number series generator challenge. Last month I covered solutions that generate the rows on the fly using a table value constructor with rows based on constants. There were no I/O operations involved in those solutions. This month I focus on solutions that query a physical base table that you pre-populate with rows. For this reason, beyond reporting the time profile of the solutions like I did last month, I’ll also report the I/O profile of the new solutions. Thanks again to Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 and Ed Wagner for sharing your ideas and comments.
Fastest solution so far
First, as a quick reminder, let’s review the fastest solution from last month’s article, implemented as an inline TVF called dbo.GetNumsAlanCharlieItzikBatch.
I’ll do my testing in tempdb, enabling IO and TIME statistics:
SET NOCOUNT ON;
USE tempdb;
SET STATISTICS IO, TIME ON;
The fastest solution from last month applies a join with a dummy table that has a columnstore index to get batch processing. Here’s the code to create the dummy table:
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
And here’s the code with the definition of the dbo.GetNumsAlanCharlieItzikBatch function:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO
Last month I used the following code to test the function's performance with 100M rows, after enabling the Discard results after execution in SSMS to suppress returning the output rows:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Here are the time statistics that I got for this execution:
Joe Obbish correctly noted that this test could be lacking in its reflection of some real-life scenarios in the sense that a big chunk of the run time is due to async network I/O waits (ASYNC_NETWORK_IO wait type). You can observe the highest waits by looking at the properties page of the root node of the actual query plan, or run an extended events session with wait info. The fact that you enable Discard results after execution in SSMS doesn’t prevent SQL Server from sending the result rows to SSMS; it just prevents SSMS from printing them. The question is, how likely is it that you will return large result sets to the client in real life scenarios even when you do use the function to produce a large number series? Perhaps more often you write the query results to a table, or use the result of the function as part of a query that eventually produces a small result set. You need to figure this out. You could write the result set into a temporary table using the SELECT INTO statement, or, you could use Alan Burstein’s trick with an assignment SELECT statement, which assigns the result column value to a variable.
Here’s how you would change the last test to use the variable assignment option:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Here are the time statistics that I got for this test:
This time the wait info has no async network I/O waits, and you can see the significant drop in run time.
Test the function again, this time adding ordering:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
I got the following performance stats for this execution:
Recall that there’s no need for a Sort operator in the plan for this query since the column n is based on an expression that is order preserving with respect to the column rownum. That’s thanks to Charli’s constant folding trick, which I covered last month. The plans for both queries—the one without ordering and the one with ordering are the same, so performance tends to be similar.
Figure 1 summarizes the performance numbers that I got for last month’s solutions, only this time using variable assignment in the tests instead of discarding results after execution.
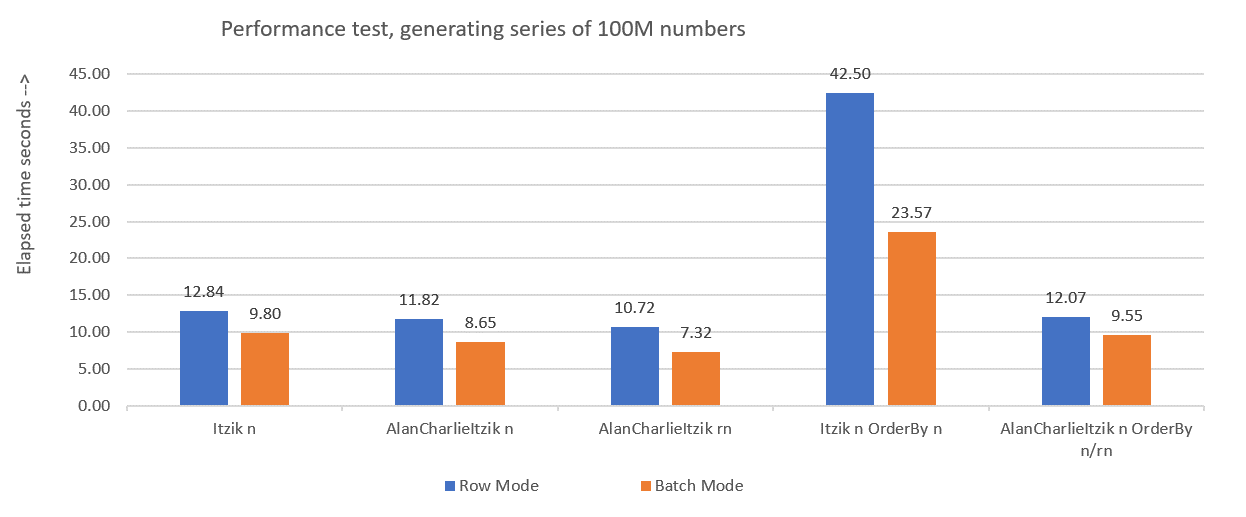 Figure 1: Performance summary so far with variable assignment
Figure 1: Performance summary so far with variable assignment
I’ll use the variable assignment technique to test the rest of the solutions that I’ll present in this article. Make sure that you adjust your tests to reflect best your real-life situation, using variable assignment, SELECT INTO, Discard results after execution or any other technique.
Tip for forcing serial plans without MAXDOP 1
Before I present new solutions, I just wanted to cover a small tip. Recall that some of the solutions perform best when using a serial plan. The obvious way to force this is with a MAXDOP 1 query hint. And that’s the right way to go if sometimes you’ll want to enable parallelism and sometimes not. However, what if you always want to force a serial plan when using the function, albeit a less likely scenario?
There’s a trick to achieving this. Use of a noninlineable scalar UDF in the query is a parallelism inhibitor. One of the scalar UDF inlining inhibitors is invoking an intrinsic function that is time-dependent, such as SYSDATETIME. So here’s an example for a noninlineable scalar UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME()
RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO
Another option is to define a UDF with just some constant as the returned value, and use the INLINE = OFF option in its header. But this option is available only starting with SQL Server 2019, which introduced scalar UDF inlining. With the above suggested function, you can create it as is with older versions of SQL Server.
Next, alter the definition of the dbo.GetNumsAlanCharlieItzikBatch function to have a dummy call to dbo.MySYSDATETIME (define a column based on it but don’t refer to the column in the returned query), like so:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO
You can now rerun the performance test without specifying MAXDOP 1, and still get a serial plan:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
It’s important to stress though that any query using this function will now get a serial plan. If there’s any chance that the function will be used in queries that will benefit from parallel plans, better not use this trick, and when you need a serial plan, simply use MAXDOP 1.
Solution by Joe Obbish
Joe’s solution is pretty creative. Here’s his own description of the solution:
As mentioned earlier, Joe also noted that my original performance testing was significantly skewed due to the async network I/O waits generated by transmitting the rows to SSMS. So all of the tests that I’ll perform here will be using Alan’s idea with the variable assignment. Be sure to adjust your tests based on what most closely reflects your real-life situation.
Here’s the code Joe used to create the table dbo.GetNumsObbishTable and populate it with 134,217,728 rows:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable;
CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE);
GO
SET NOCOUNT ON;
DECLARE @c INT = 0;
WHILE @c < 128
BEGIN
INSERT INTO dbo.GetNumsObbishTable
SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
OPTION (MAXDOP 1);
SET @c = @c + 1;
END;
GO
It took this code 1:04 minutes to complete on my machine.
You can check the space usage of this table by running the following code:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
I got about 350 MB of space used. Compared to the other solutions that I’ll present in this article, this one uses significantly more space.
In SQL Server’s columnstore architecture, a row group is limited to 2^20 = 1,048,576 rows. You can check how many row groups were created for this table using the following code:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable');
I got 128 row groups.
Here’s the code with the definition of the dbo.GetNumsObbish function:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
SELECT @low + ID AS n
FROM dbo.GetNumsObbishTable
WHERE ID <= @high - @low
UNION ALL
SELECT @low + ID + CAST(134217728 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(134217728 AS BIGINT)
AND ID <= @high - @low - CAST(134217728 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(268435456 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(268435456 AS BIGINT)
AND ID <= @high - @low - CAST(268435456 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(402653184 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(402653184 AS BIGINT)
AND ID <= @high - @low - CAST(402653184 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(536870912 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(536870912 AS BIGINT)
AND ID <= @high - @low - CAST(536870912 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(671088640 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(671088640 AS BIGINT)
AND ID <= @high - @low - CAST(671088640 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(805306368 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(805306368 AS BIGINT)
AND ID <= @high - @low - CAST(805306368 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(939524096 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(939524096 AS BIGINT)
AND ID <= @high - @low - CAST(939524096 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT)
AND ID <= @high - @low - CAST(1073741824 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT)
AND ID <= @high - @low - CAST(1207959552 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT)
AND ID <= @high - @low - CAST(1342177280 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT)
AND ID <= @high - @low - CAST(1476395008 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT)
AND ID <= @high - @low - CAST(1610612736 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT)
AND ID <= @high - @low - CAST(1744830464 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT)
AND ID <= @high - @low - CAST(1879048192 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT)
AND ID <= @high - @low - CAST(2013265920 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT)
AND ID <= @high - @low - CAST(2147483648 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT)
AND ID <= @high - @low - CAST(2281701376 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT)
AND ID <= @high - @low - CAST(2415919104 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT)
AND ID <= @high - @low - CAST(2550136832 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT)
AND ID <= @high - @low - CAST(2684354560 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT)
AND ID <= @high - @low - CAST(2818572288 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT)
AND ID <= @high - @low - CAST(2952790016 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT)
AND ID <= @high - @low - CAST(3087007744 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT)
AND ID <= @high - @low - CAST(3221225472 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT)
AND ID <= @high - @low - CAST(3355443200 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT)
AND ID <= @high - @low - CAST(3489660928 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT)
AND ID <= @high - @low - CAST(3623878656 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT)
AND ID <= @high - @low - CAST(3758096384 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT)
AND ID <= @high - @low - CAST(3892314112 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT)
AND ID <= @high - @low - CAST(4026531840 AS BIGINT)
UNION ALL
SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n
FROM dbo.GetNumsObbishTable
WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT)
AND ID <= @high - @low - CAST(4160749568 AS BIGINT);
GO
The 32 individual queries generate the disjoint 134,217,728-integer subranges that, when unified, produce the complete uninterrupted range 1 through 4,294,967,296. What’s really smart about this solution is the WHERE filter predicates that the individual queries use. Recall that when SQL Server processes an inline TVF, it first applies parameter embedding, substituting the parameters with the input constants. SQL Server can then optimize out the queries that produce subranges that don’t intersect with the input range. For instance, when you request the input range 1 to 100,000,000, only the first query is relevant, and all the rest get optimized out. The plan then in this case will involve a reference to only one instance of the table. That’s pretty brilliant!
Let’s test the function’s performance with the range 1 to 100,000,000:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
The plan for this query is shown in Figure 2.
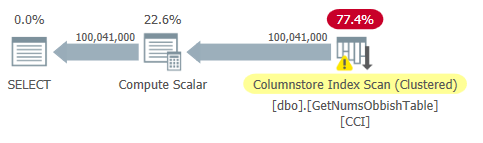 Figure 2: Plan for dbo.GetNumsObbish, 100M rows, unordered
Figure 2: Plan for dbo.GetNumsObbish, 100M rows, unordered
Observe that indeed only one reference to the table’s CCI is needed in this plan.
I got the following time statistics for this execution:
That’s pretty impressive, and by far faster than anything else that I’ve tested.
Here are the I/O stats that I got for this execution:
Table 'GetNumsObbishTable'. Segment reads 96, segment skipped 32.
The I/O profile of this solution is one of its downsides compared to the others, incurring over 30K lob logical reads for this execution.
To see that when you cross multiple 134,217,728-integer subranges the plan will involve multiple references to the table, query the function with the range 1 to 400,000,000, for example:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
The plan for this execution is shown in Figure 3.
 Figure 3: Plan for dbo.GetNumsObbish, 400M rows, unordered
Figure 3: Plan for dbo.GetNumsObbish, 400M rows, unordered
The requested range crossed three 134,217,728-integer subranges, hence the plan shows three references to the table’s CCI.
Here are the time statistics that I got for this execution:
And here are its I/O statistics:
Table 'GetNumsObbishTable'. Segment reads 382, segment skipped 2.
This time the query execution resulted in over 130K lob logical reads.
If you can stomach the I/O costs, and do not need to process the number series in an ordered fashion, this is a great solution. However, if you do need to process the series in order, this solution will result in a Sort operator in the plan. Here’s a test requesting the result ordered:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
The plan for this execution is shown in Figure 4.
 Figure 4: Plan for dbo.GetNumsObbish, 100M rows, ordered
Figure 4: Plan for dbo.GetNumsObbish, 100M rows, ordered
Here are the time statistics that I got for this execution:
As you can see, performance degraded significantly with the run time increasing by an order of magnitude due to the explicit sorting.
Here are the I/O statistics that I got for this execution:
Table 'GetNumsObbishTable'. Segment reads 96, segment skipped 32.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Observe that a Worktable showed up in the output of STATISTICS IO. That’s because a sort can potentially spill to tempdb, in which case it would use a worktable. This execution did not spill, hence the numbers are all zeros in this entry.
Solution by John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 posted a solution that is just beautiful in its simplicity. Plus, it includes ideas and suggestions from the other solutions by Dave, Joe, Alan, Charlie and myself.
Like with Joe’s solution, John decided to use a CCI to get a high level of compression and “free” batch processing. Only John decided to fill the table with 4B rows with some dummy NULL marker in a bit column, and have the ROW_NUMBER function generate the numbers. Since the stored values are all the same, with compression of repeating values you need significantly less space, resulting in significantly less I/Os compared to Joe’s solution. Columnstore compression handles repeating values very well since it can represent each such consecutive section within a row group’s column segment only once along with the count of consecutively repeating occurrences. Since all rows have the same value (the NULL marker), theoretically you need only one occurrence per row group. With 4B rows, you should end up with 4,096 row groups. Each should have a single columns segment, with very little space usage requirement.
Here’s the code to create and populate the table, implemented as a CCI with archival compression:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO
The main downside of this solution is the time it takes to populate this table. It took this code 12:32 minutes to complete on my machine when allowing parallelism, and 15:17 minutes when forcing a serial plan.
Note that you could work on optimizing the data load. For example, John tested a solution that loaded the rows using 32 simultaneous connections with OSTRESS.EXE, each running 128 rounds of insertions of 2^20 rows (max row group size). This solution dropped John’s load time to a third. Here’s the code John used:
Still, the load time is in minutes. The good news is that you need to perform this data load only once.
The great news is the small amount of space needed by the table. Use the following code to check the space usage:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
I got 1.64 MB. That’s amazing considering the fact that the table has 4B rows!
Use the following code the check how many row groups were created:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B');
As expected, the number of row groups is 4,096.
The dbo.GetNumsJohn2DaveObbishAlanCharlieItzik function definition then becomes pretty simple:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
As you can see, a simple query against the table uses the ROW_NUMBER function to compute the base row numbers (rownum column), and then the outer query uses the same expressions as in dbo.GetNumsAlanCharlieItzikBatch to compute rn, op and n. Also here, both rn and n are order preserving with respect to rownum.
Let’s test the function's performance:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
I got the plan shown in Figure 5 for this execution.
 Figure 5: Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figure 5: Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Here are the time statistics that I got for this test:
As you can see, the execution time is not as fast as with Joe’s solution, but it’s still faster than all other solutions that I’ve tested.
Here are the I/O stats that I got for this test:
Table 'NullBits4B'. Segment reads 96, segment skipped 0
Observe that the I/O requirements are significantly lower than with Joe’s solution.
The other great thing about this solution is that when you do need to process the number series ordered, you don’t pay any extra. That’s since it won’t result in an explicit sort operation in the plan, irrespective of whether you order the result by rn or n.
Here’s a test to demonstrate this:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
You get the same plan as shown earlier in Figure 5.
Here are the time statistics that I got for this test;
And here are the I/O stats:
Table 'NullBits4B'. Segment reads 96, segment skipped 0.
They are basically the same as in the test without the ordering.
Solution 2 by John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
John’s solution is fast and simple. That’s fantastic. The one downside is the load time. Sometimes this won’t be an issue since the loading happens only once. But if it is an issue, you could populate the table with 102,400 rows instead of 4B rows, and use a cross join between two instances of the table and a TOP filter to generate the desired maximum of 4B rows. Note that to get 4B rows it would suffice to populate the table with 65,536 rows and then apply a cross join; however, in order to get the data to be compressed immediately—as opposed to being loaded into a rowstore-based delta store—you need to load the table with a minimum of 102,400 rows.
Here’s the code to create and populate the table:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO
The load time is negligible — 43 ms on my machine.
Check the size of the table on disk:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
I got 56 KB space needed for the data.
Check the number of rowgroups, their state (compressed or open) and their size:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400');
I got the following output:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Only one row group is needed here; it’s compressed, and the size is a negligible 293 bytes.
If you populate the table with one row less (102,399), you get a rowstore-based uncompressed open delta store. In such a case sp_spaceused reports data size on disk of over 1MB, and sys.column_store_row_groups reports the following info:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
So make sure you populate the table with 102,400 rows!
Here’s the definition of the function dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Let’s test the function's performance:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
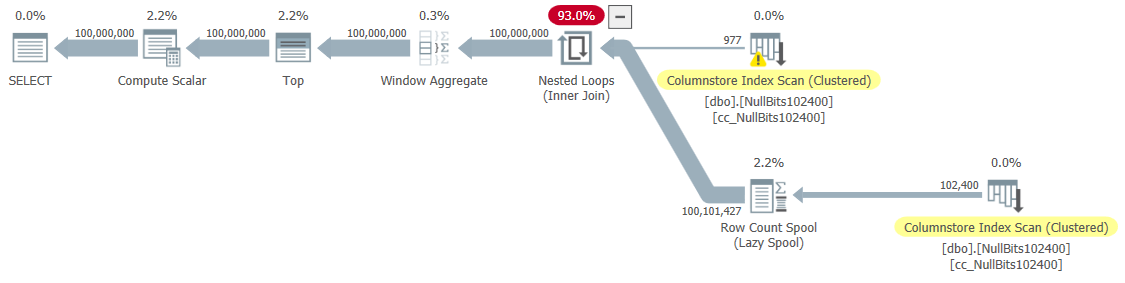 Figure 6: Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6: Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
And the following I/O stats:
Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
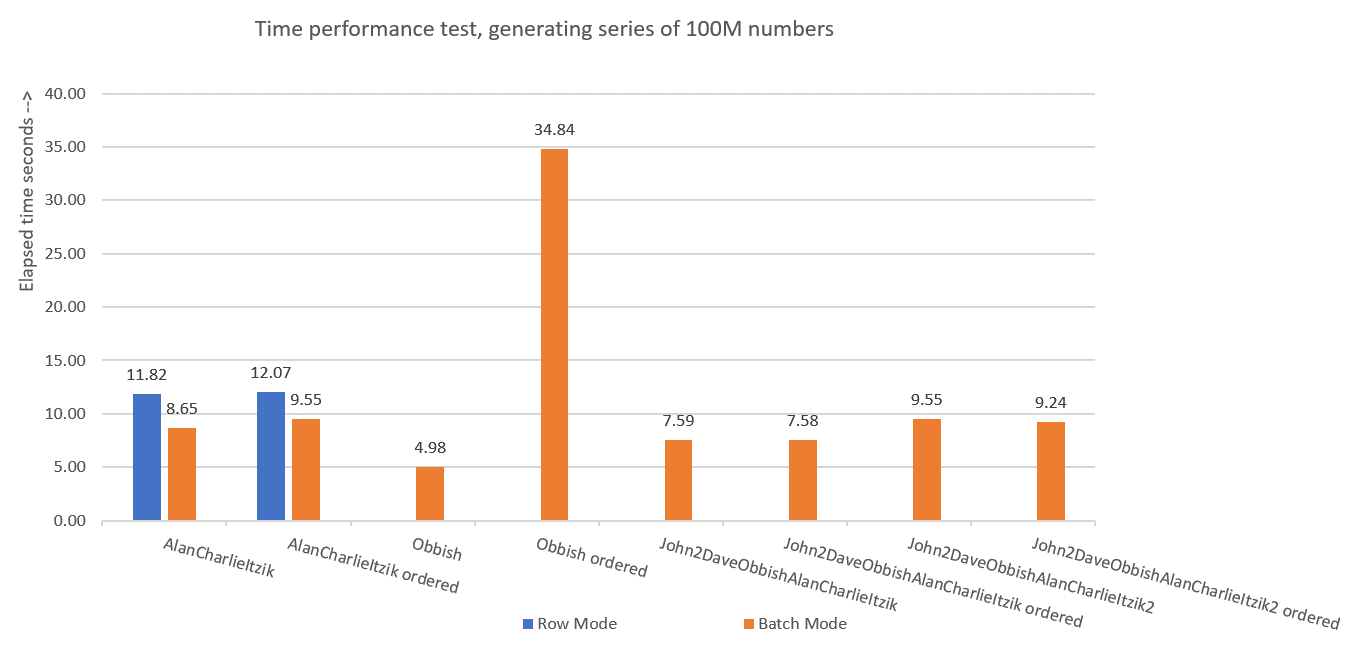 Figure 7: Time performance summary of solutions
Figure 7: Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
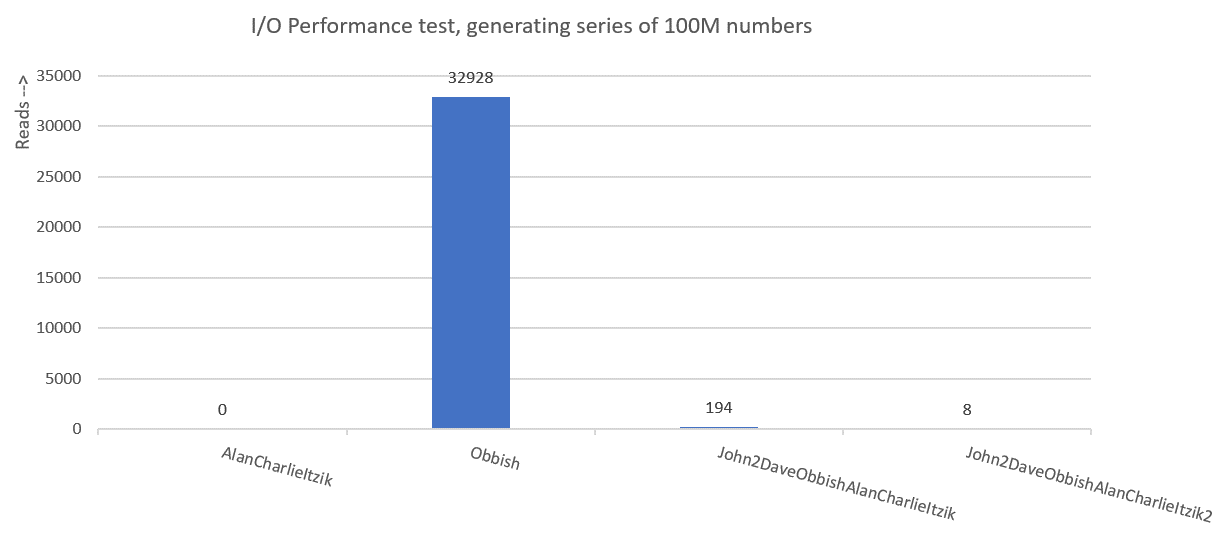 Figure 8: I/O performance summary of solutions
Figure 8: I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.

None of us is as bright as all of us. Loved being a part of this discussion!
That's true, John. I loved it too!
Would there be any benefit (or detriment) in the NullBits102400 solution to include a WHERE clause in the cross apply like in the Obbish solution? That way when @LOW and @HIGH are < 102400 rows it won't attempt to cross join/UNION?
I think a big question, given the fact that I'm often using these functions in real code against much smaller cardinalities, is what happens if we execute the whole function say 1m times, generating 100 or 255 rows each time, the equivalent of cross applying a small cardinality against a much larger base table.
I use this technique very often when doing string parsing or generating dates, so the cardinalities are much lower. i can't think of an instance where I would need to go beyond a couple million generated rows
John, since the solution with NullBits102400 uses a cross join and not a union, you would have to include both instances of the table and not eliminate them. If you use the elimination technique for one of the instances when the requested number of rows is no larger than the table's cardinality, the outcome of the cross join becomes an empty set.
Charlie, agreed. And for such use cases naturally the solutions that have very low compilation + execution times are preferred, as we discussed in previous conversations.
Hey Itzik,
Loving your work here.
This seems like a useful improvement on my machine:
-- Helper columnstore table DROP TABLE IF EXISTS dbo.CS; -- 64K rows (enough for 4B rows when cross joined) -- column 1 is always zero -- column 2 is (1...65536) SELECT -- type as integer NOT NULL -- (everything is normalized to 64 bits in columnstore/batch mode anyway) n1 = ISNULL(CONVERT(integer, 0), 0), n2 = ISNULL(CONVERT(integer, N.rn), 0) INTO dbo.CS FROM ( SELECT rn = ROW_NUMBER() OVER (ORDER BY @@SPID) FROM master.dbo.spt_values AS SV1 CROSS JOIN master.dbo.spt_values AS SV2 ORDER BY rn ASC OFFSET 0 ROWS FETCH NEXT 65536 ROWS ONLY ) AS N; -- Single compressed rowgroup of 65,536 rows CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS WITH (MAXDOP = 1); GO -- The function CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi ( @low bigint = 1, @high bigint ) RETURNS table AS RETURN SELECT N.rn, n = @low - 1 + N.rn, op = @high + 1 - N.rn FROM ( SELECT -- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC) FROM dbo.CS AS N1 JOIN dbo.CS AS N2 -- Batch mode hash cross join -- Integer not null data type avoid hash probe residual -- This is always 0 = 0 ON N2.n1 = N1.n1 WHERE -- Try to avoid SQRT on negative numbers and enable simplification -- to single constant scan if @low > @high (with literals) -- No start-up filters in batch mode @high >= @low -- Coarse filter: -- Limit each side of the cross join to SQRT(target number of rows) -- IIF avoids SQRT on negative numbers with parameters AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0))))) AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0))))) ) AS N WHERE -- Precise filter: -- Batch mode filter the limited cross join to the exact number of rows needed -- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar @low - 2 + N.rn < @high; GOThat's pretty cool, Paul! Here are the numbers that I get on my machine for your solution:
DECLARE @n AS BIGINT;
SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
CPU time = 6875 ms, elapsed time = 6938 ms.
Yes that seems about right; though it seems you have a machine with somewhat better single-core performance than I do.
You'll notice the plan operators are all batch mode, but the elapsed times don't add up to anything like the elapsed time for the whole query. For example, on a typical run for me, the sum of the operator times is around 2,600ms. The rest of the time is associated with pulling 100,000,000 rows out of batches for the final row-mode variable assignment.
One way to see how fast the batch mode operations are: Replace the final variable assignment with an aggregate like
MAX. There is no early-aggregation trickery; the batch mode plan really will find the maximum among 100M rows in a shade over two seconds.You may also find performance of the exact same query improves a bit over time. This may be due to memory grant feedback (I have not checked yet).
@PaulWhite
I was wondering why you didn't use a batch mode cross join without the need for the extra column. Then I tested and realized it goes for a row-mode nested loops and a rowcount spool, or with TF8690 just the row mode NL. Any idea why?
To avoid the negative issue, you could change your WHERE to
WHERE
( @high >= @low
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high – @low + 1))))
AND N2.n2 @high
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @low – @high + 1))))
AND N2.n2 = @low, @low, @high), IIF(@high >= @low, @high, @low)) ) AS v(high, low)
CROSS APPLY
(
SELECT
……..
Sorry not sure what happened to that comment, half of it got lost.
I was saying that you could use dynamic slicing, with two parts to the WHERE.
WHERE
( @high >= @low
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high – @low + 1))))
AND N2.n2 @high
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @low – @high + 1))))
AND N2.n2 = @low, @low, @high), IIF(@high >= @low, @high, @low)) ) v(low, high)
CROSS APPLY
(
SELECT
……
Also, I can't test because I'm on 2016, but what about a computed column for n1?
Got lost again, not sure whats going on, it's bodged together the two versions.
Version 1 has both sides of the WHERE, high >= low and low < high.
The other option is to presort the values and apply the rest of the function
Hey Charlie,
There's no native batch mode cross join. The extra column is a trick to generate a cross join that is compatible with hash join (where batch mode is available), without the optimizer realizing what I am up to.
Indeed, adding a check constraint to the base table ensuring is enough to let the optimizer see I am joining on
0 = 0. That makes it a cross join, resulting in row mode nested loops join (the only available implementation for cross join).A computed column would have the same issue (plus it would need to be persisted to be in column store, which rather defeats the object). You should be able to test on SQL Server 2019 Express?
I can't see the code you tried to post, but I'm not concerned about the current arrangement. It applies to a maximum of 64K rows in batch mode. There's just nothing to be gained there.
The big win is in staying in batch mode for the whole plan, and avoiding unnecessary row/batch transitions. It might be nice to reduce the size of the column store table a bit, but it is already pretty tiny so I kinda lost interest at that point.
Maybe one could get by with column
n1alone and use an extra row number. It just doesn't seem worth pursuing. As I say, all the runtime is spent in the 'cross join' and later operators processing 100M rows.