
T-SQL bugs, pitfalls, and best practices – pivoting and unpivoting
This article is the fifth part in a series about T-SQL bugs, pitfalls and best practices. Previously I covered determinism, subqueries, joins, and windowing. This month, I cover pivoting and unpivoting. Thanks Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man and Paul White for sharing your suggestions!
In my examples, I’ll use a sample database called TSQLV5. You can find the script that creates and populates this database here, and its ER diagram here.
Implicit grouping with PIVOT
When people want to pivot data using T-SQL, they either use a standard solution with a grouped query and CASE expressions, or the proprietary PIVOT table operator. The main benefit of the PIVOT operator is that it tends to result in shorter code. However, this operator has a few shortcomings, among them an inherent design trap that can result in bugs in your code. Here I’ll describe the trap, the potential bug, and a best practice that prevents the bug. I’ll also describe a suggestion to enhance the PIVOT operator’s syntax in a way that helps avoid the bug.
When you pivot data there are three steps that are involved in the solution, with three associated elements:
- Group based on a grouping/on rows element
- Spread based on a spreading/on cols element
- Aggregate based on an aggregation/data element
Following is the syntax of the PIVOT operator:
SELECT
FROM
PIVOT( ()
FOR IN() ) AS ;
The design of the PIVOT operator requires you to explicitly specify the aggregation and spreading elements, but lets SQL Server implicitly figure out the grouping element by elimination. Whichever columns appear in the source table that is provided as the input to the PIVOT operator, they implicitly become the grouping element.
Suppose for example that you want to query the Sales.Orders table in the TSQLV5 sample database. You want to return shipper IDs on rows, shipped years on columns, and the count of orders per shipper and year as the aggregate.
Many people have a hard time figuring out the PIVOT operator’s syntax, and this often results in grouping the data by undesired elements. As an example with our task, suppose that you don’t realize that the grouping element is determined implicitly, and you come up with the following query:
SELECT shipperid, [2017], [2018], [2019]
FROM Sales.Orders
CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)
PIVOT( COUNT(shippeddate) FOR shippedyear IN([2017], [2018], [2019]) ) AS P;
There are only three shippers present in the data, with shipper IDs 1, 2 and 3. So you’re expecting to see only three rows in the result. However, the actual query output shows many more rows:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 1 0 0 1 1 0 0 2 1 0 0 1 1 0 0 2 1 0 0 2 1 0 0 2 1 0 0 3 1 0 0 2 1 0 0 3 1 0 0 ... 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 ... 3 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 3 0 0 1 3 0 0 1 2 0 1 0 ... (830 rows affected)
What happened?
You can find a clue that will help you figure out the bug in the code by looking at the query plan shown in Figure 1.
 Figure 1: Plan for pivot query with implicit grouping
Figure 1: Plan for pivot query with implicit grouping
Don’t let the use of the CROSS APPLY operator with the VALUES clause in the query confuse you. This is done simply to compute the result column shippedyear based on the source shippeddate column, and is handled by the first Compute Scalar operator in the plan.
The input table to the PIVOT operator contains all columns from the Sales.Orders table, plus the result column shippedyear. As mentioned, SQL Server determines the grouping element implicitly by elimination based on what you didn’t specify as the aggregation (shippeddate) and spreading (shippedyear) elements. Perhaps you intuitively expected the shipperid column to be the grouping column because it appears in the SELECT list, but as you can see in the plan, in practice you got a much longer list of columns, including orderid, which is the primary key column in the source table. This means that instead of getting a row per shipper, you’re getting a row per order. Since in the SELECT list you specified only the columns shipperid, [2017], [2018] and [2019], you don’t see the rest, which adds to the confusion. But the rest did take part in the implied grouping.
What could be great is if the syntax of the PIVOT operator supported a clause where you can explicitly indicate the grouping/on rows element. Something like this:
SELECT
FROM
PIVOT( ()
FOR IN()
ON ROWS ) AS ;
Based on this syntax you would use the following code to handle our task:
SELECT shipperid, [2017], [2018], [2019]
FROM Sales.Orders
CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019])
ON ROWS shipperid ) AS P;
You can find a feedback item with a suggestion to improve the PIVOT operator’s syntax here. To make this improvement a nonbreaking change, this clause can be made optional, with the default being the existing behavior. There are other suggestions to improve the PIVOT operator’s syntax by making it more dynamic and by supporting multiple aggregates.
In the meanwhile, there’s a best practice that can help you avoid the bug. Use a table expression such as a CTE or a derived table where you project only the three elements that you need to be involved in the pivot operation, and then use the table expression as the input to the PIVOT operator. This way, you fully control the grouping element. Here’s the general syntax following this best practice:
WITH AS
(
SELECT , ,
FROM
)
SELECT
FROM
PIVOT( ()
FOR IN() ) AS ;
Applied to our task, you use the following code:
WITH C AS
(
SELECT shipperid, YEAR(shippeddate) AS shippedyear, shippeddate
FROM Sales.Orders
)
SELECT shipperid, [2017], [2018], [2019]
FROM C
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019]) ) AS P;
This time you get only three result rows as expected:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 51 125 73 1 36 130 79 2 56 143 116
Another option is to use the old and classic standard solution for pivoting using a grouped query and CASE expressions, like so:
SELECT shipperid,
COUNT(CASE WHEN shippedyear = 2017 THEN 1 END) AS [2017],
COUNT(CASE WHEN shippedyear = 2018 THEN 1 END) AS [2018],
COUNT(CASE WHEN shippedyear = 2019 THEN 1 END) AS [2019]
FROM Sales.Orders
CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)
WHERE shippeddate IS NOT NULL
GROUP BY shipperid;
With this syntax all three pivoting steps and their associated elements have to be explicit in the code. However, when you have a large number of spreading values, this syntax tends to be verbose. In such cases, people often prefer to use the PIVOT operator.
Implicit removal of NULLs with UNPIVOT
The next item in this article is more of a pitfall than a bug. It has to do with the proprietary T-SQL UNPIVOT operator, which lets you unpivot data from a state of columns to a state of rows.
I’ll use a table called CustOrders as my sample data. Use the following code to create, populate and query this table to show its content:
DROP TABLE IF EXISTS dbo.CustOrders;
GO
WITH C AS
(
SELECT custid, YEAR(orderdate) AS orderyearyear, val
FROM Sales.OrderValues
)
SELECT custid, [2017], [2018], [2019]
INTO dbo.CustOrders
FROM C
PIVOT( SUM(val)
FOR orderyearyear IN([2017], [2018], [2019]) ) AS P;
SELECT * FROM dbo.CustOrders;
This code generates the following output:
custid 2017 2018 2019 ------- ---------- ---------- ---------- 1 NULL 2022.50 2250.50 2 88.80 799.75 514.40 3 403.20 5960.78 660.00 4 1379.00 6406.90 5604.75 5 4324.40 13849.02 6754.16 6 NULL 1079.80 2160.00 7 9986.20 7817.88 730.00 8 982.00 3026.85 224.00 9 4074.28 11208.36 6680.61 10 1832.80 7630.25 11338.56 11 479.40 3179.50 2431.00 12 NULL 238.00 1576.80 13 100.80 NULL NULL 14 1674.22 6516.40 4158.26 15 2169.00 1128.00 513.75 16 NULL 787.60 931.50 17 533.60 420.00 2809.61 18 268.80 487.00 860.10 19 950.00 4514.35 9296.69 20 15568.07 48096.27 41210.65 ...
This table holds the total order values per customer and year. NULLs represent cases where a customer didn’t have any order activity in the target year.
Suppose that you want to unpivot the data from the CustOrders table, returning a row per customer and year, with a result column called val holding the total order value for the current customer and year. Any unpivoting task generally involves three elements:
- The names of the existing source columns that you are unpivoting: [2017], [2018], [2019] in our case
- A name you assign to the target column that will hold the source column names: orderyear in our case
- A name you assign to the target column that will hold the source column values: val in our case
If you decide to use the UNPIVOT operator to handle the unpivoting task, you first figure out the above three elements, and then use the following syntax:
SELECT , ,
FROM
UNPIVOT( FOR IN() ) AS ;
Applied to our task, you use the following query:
SELECT custid, orderyear, val
FROM dbo.CustOrders
UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
This query generates the following output:
custid orderyear val ------- ---------- ---------- 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
Looking at the source data and the query result, do you notice what’s missing?
The design of the UNPIVOT operator involves an implicit elimination of result rows that have a NULL in the values column—val in our case. Looking at the execution plan for this query shown in Figure 2, you can see the Filter operator removing the rows with the NULLs in the val column (Expr1007 in the plan).
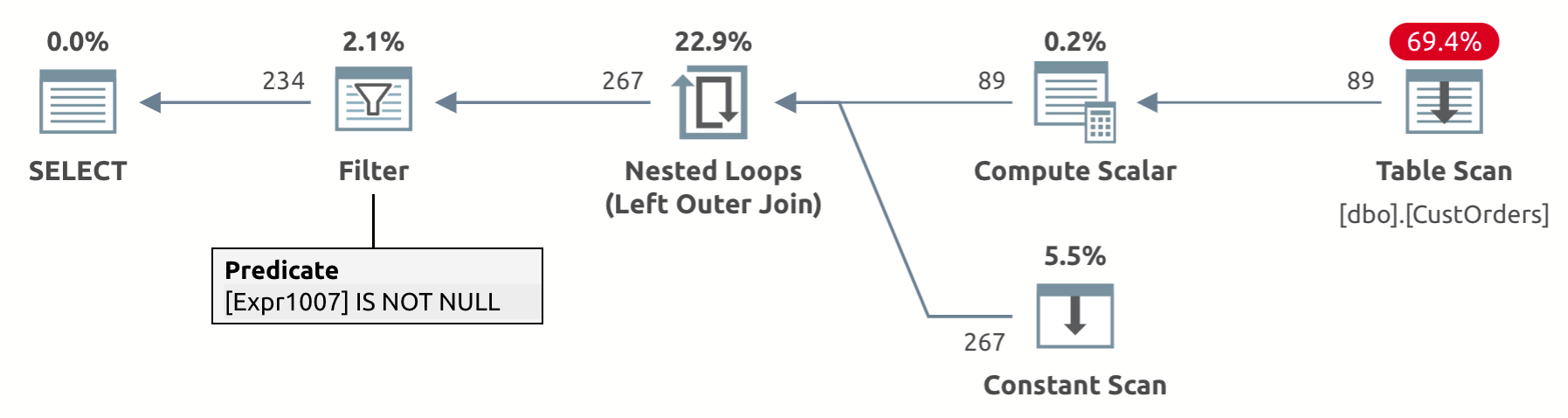 Figure 2: Plan for unpivot query with implicit removal of NULLs
Figure 2: Plan for unpivot query with implicit removal of NULLs
Sometimes this behavior is desirable, in which case you don’t need to do anything special. The problem is that sometimes you want to keep the rows with the NULLs. The pitfall is when you want to keep the NULLs and you don’t even realize that the UNPIVOT operator is designed to remove them.
What could be great is if the UNPIVOT operator had an optional clause that allowed you to specify whether you want to remove or keep NULLs, with the former being the default for backward compatibility. Here’s an example for what this syntax might look like:
SELECT , ,
FROM
UNPIVOT( FOR IN()
[REMOVE NULLS | KEEP NULLS] ) AS ;
If you wanted to keep NULLs, based on this syntax you would use the following query:
SELECT custid, orderyear, val
FROM dbo.CustOrders
UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
You can find a feedback item with a suggestion to improve the UNPIVOT operator’s syntax in this way here.
In the meanwhile, if you want to keep the rows with the NULLs, you have to come up with a workaround. If you insist on using the UNPIVOT operator, you need to apply two steps. In the first step you define a table expression based on a query that uses the ISNULL or COALESCE function to replace NULLs in all unpivoted columns with a value that normally cannot appear in the data, e.g., -1 in our case. In the second step you use the NULLIF function in the outer query against the values column to replace the -1 back with a NULL. Here’s the complete solution code:
WITH C AS
(
SELECT custid,
ISNULL([2017], -1.0) AS [2017],
ISNULL([2018], -1.0) AS [2018],
ISNULL([2019], -1.0) AS [2019]
FROM dbo.CustOrders
)
SELECT custid, orderyear, NULLIF(val, -1.0) AS val
FROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Here’s the output of this query showing that rows with NULLs in the val column are preserved:
custid orderyear val ------- ---------- ---------- 1 2017 NULL 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2017 NULL 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
This approach is awkward, especially when you have a large number of columns to unpivot.
An alternative solution uses a combination of the APPLY operator and the VALUES clause. You construct a row for each unpivoted column, with one column representing the target names column (orderyear in our case), and another representing the target values column (val in our case). You provide the constant year for the names column, and the relevant correlated source column for the values column. Here’s the complete solution code:
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val);
The nice thing here is that unless you’re interested in the removal of the rows with the NULLs in the val column, you don’t need to do anything special. There’s no implicit step here that removes the rows with the NULLS. Moreover, since the val column alias is created as part of the FROM clause, it’s accessible to the WHERE clause. So, if you are interested in the removal of the NULLs, you can be explicit about it in the WHERE clause by directly interacting with the values column alias, like so:
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val)
WHERE val IS NOT NULL;
The point is that this syntax gives you control of whether you want to keep or remove NULLs. It’s more flexible than the UNPIVOT operator in another way, letting you handle multiple unpivoted measures such as both val and qty. My focus in this article though was the pitfall involving NULLs so I didn’t get into this aspect.
Conclusion
The design of the PIVOT and UNPIVOT operators sometimes leads to bugs and pitfalls in your code. The PIVOT operator’s syntax doesn’t let you explicitly indicate the grouping element. If you don’t realize this, you can end up with undesired grouping elements. As a best practice, it’s recommended that you use a table expression as an input to the PIVOT operator, and this why explicitly control what’s the grouping element.
The UNPIVOT operator’s syntax doesn’t let you control whether to remove or keep rows with NULLs in the result values column. As a workaround, you either use an awkward solution with the ISNULL and NULLIF functions, or a solution based on the APPLY operator and the VALUES clause.
I also mentioned two feedback items with suggestions to improve the PIVOT and UNPIVOT operators with more explicit options to control the behavior of the operator and its elements.
2 thoughts on “T-SQL bugs, pitfalls, and best practices – pivoting and unpivoting”
Comments are closed.

Itzik,
It is always a pleasure reading your articles.
Thanks!
Thanks Mickey!