
T-SQL bugs, pitfalls, and best practices – joins
This article is the third installment in a series about T-SQL bugs, pitfalls and best practices. Previously I covered determinism and subqueries. This time I focus on joins. Some of the bugs and best practices that I cover here are a result of a survey I did among fellow MVPs. Thanks Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man and Paul White for offering your insights!
In my examples I’ll use a sample database called TSQLV5. You can find the script that creates and populates this database here, and its ER diagram here.
In this article I focus on four classic common bugs: COUNT(*) in outer joins, double-dipping aggregates, ON-WHERE contradiction and OUTER-INNER join contradiction. All of these bugs are related to T-SQL querying fundamentals, and are easy to avoid if you follow simple best-practices.
COUNT(*) in outer joins
Our first bug has to do with incorrect counts reported for empty groups as a result of using an outer join and the COUNT(*) aggregate. Consider the following query computing the number of orders and total freight per customer:
USE TSQLV5; -- http://tsql.solidq.com/SampleDatabases/TSQLV5.zip
SELECT custid, COUNT(*) AS numorders, SUM(freight) AS totalfreight
FROM Sales.Orders
GROUP BY custid
ORDER BY custid;This query generates the following output (abbreviated):
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 23 5 637.94 ... 56 10 862.74 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (89 rows affected)
There are 91 customers currently present in the Customers table, out of which 89 placed orders; hence the output of this query shows 89 customer groups and their correct order count and total freight aggregates. Customers with IDs 22 and 57 are present in the Customers table but have not placed any orders and therefore they don’t show up in the result.
Suppose that you are requested to include customers who don’t have any related orders in the query result. The natural thing to do in such a case is to perform a left outer join between Customers and Orders to preserve customers without orders. However, a typical bug when converting the existing solution to one that applies the join is to leave the computation of the order count as COUNT(*), as shown in the following query (call it Query 1):
SELECT C.custid, COUNT(*) AS numorders, SUM(O.freight) AS totalfreight
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
GROUP BY C.custid
ORDER BY C.custid;This query generates the following output:
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 1 NULL 23 5 637.94 ... 56 10 862.74 57 1 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rows affected)
Observe that customers 22 and 57 this time appear in the result, but their order count shows 1 instead of 0 because COUNT(*) counts rows and not orders. The total freight is reported correctly because SUM(freight) ignores NULL inputs.
The plan for this query is shown in Figure 1.
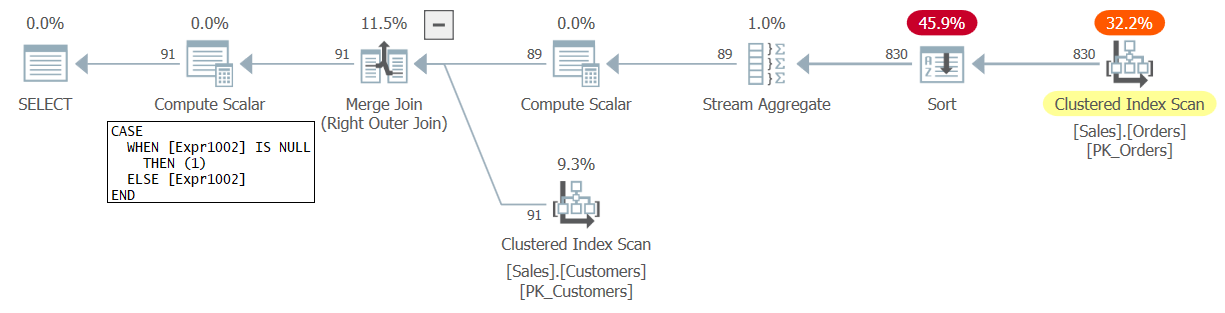 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
In this plan Expr1002 represent the count of rows per group, which as a result of the outer join, is initially set to NULL for customers with no matching orders. The Compute Scalar operator right below the root SELECT node then converts the NULL to 1. That’s the result of counting rows as opposed to counting orders.
To fix this bug, you want to apply the COUNT aggregate to an element from the nonpreserved side of the outer join, and you want to make sure that use a non-NULLable column as input. The primary key column would be a good choice. Here’s the solution query (call it Query 2) with the bug fixed:
SELECT C.custid, COUNT(O.orderid) AS numorders, SUM(O.freight) AS totalfreight
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
GROUP BY C.custid
ORDER BY C.custid;Here’s the output of this query:
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 0 NULL 23 5 637.94 ... 56 10 862.74 57 0 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rows affected)
Observe that this time customers 22 and 57 show the correct count of zero.
The plan for this query is shown in Figure 2.
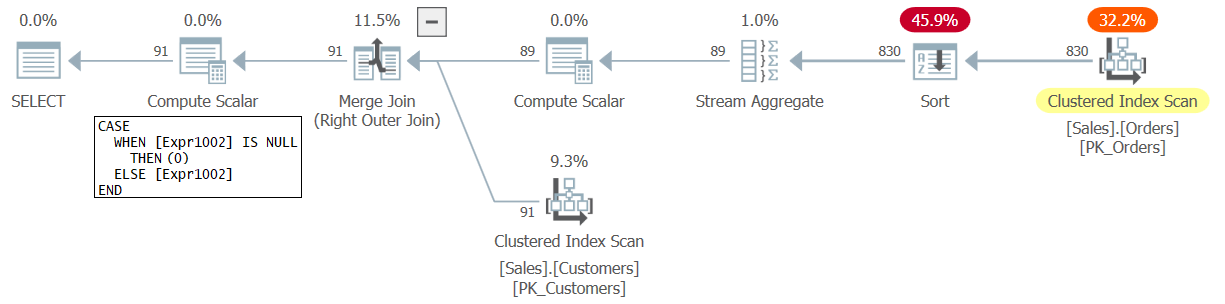 Figure 2: Plan for Query 2
Figure 2: Plan for Query 2
You can also see the change in the plan, where a NULL representing the count for a customer with no matching orders is converted to 0 and not 1 this time.
When using joins, be wary of applying the COUNT(*) aggregate. When using outer joins, it’s usually a bug. The best practice is to apply the COUNT aggregate to a non-NULLable column from the many side of the one-to-many join. The primary key column is a good choice for this purpose since it doesn’t allow NULLs. This could be a good practice even when using inner joins, since you never know if at a later point you will need to change an inner join to an outer one due to a change in requirements.
Double-dipping aggregates
Our second bug also involves mixing joins and aggregates, this time taking source values into account multiple times. Consider the following query as an example:
SELECT C.custid, COUNT(O.orderid) AS numorders, SUM(O.freight) AS totalfreight,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid;This query joins Customers, Orders and OrderDetails, groups the rows by custid, and is supposed to compute aggregates like the order count, total freight and total value per customer. This query generates the following output:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 12 419.60 4273.00 2 10 306.59 1402.95 3 17 667.29 7023.98 4 30 1447.14 13390.65 5 52 4835.18 24927.58 ... 87 37 2611.93 15648.70 88 19 546.96 6068.20 89 40 4017.32 27363.61 90 17 262.16 3161.35 91 16 461.53 3531.95
Can you spot the bug here?
Order headers are stored in the Orders table, and their respective order lines are stored in the OrderDetails table. When you join order headers with their respective order lines, the header is repeated in the result of the join per line. As a result, the COUNT(O.orderid) aggregate incorrectly reflects the count of order lines and not the count of orders. Similarly, the SUM(O.freight) incorrectly takes into account the freight multiple times per order—as many as the number of order lines within the order. The only correct aggregate computation in this query is the one used to compute the total value since it’s applied to attributes of the order lines: SUM(OD.qty * OD.unitprice * (1 – OD.discount).
To get the correct order count, it’s enough to use a distinct count aggregate: COUNT(DISTINCT O.orderid). You might think that the same fix can be applied to the computation of the total freight, but this would only introduce a new bug. Here’s our query with distinct aggregates applied to the order header’s measures:
SELECT C.custid, COUNT(DISTINCT O.orderid) AS numorders, SUM(DISTINCT O.freight) AS totalfreight,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid;This query generates the following output:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 6 225.58 4273.00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 448.23 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 87.66 3161.35 ***** 91 7 175.74 3531.95
The order counts are now correct, but the total freight values are not. Can you spot the new bug?
The new bug is more elusive because it manifests itself only when the same customer has at least one case where multiple orders happen to have the exact same freight values. In such a case, you are now taking the freight into account only once per customer, and not once per order as you should.
Use the following query (requires SQL Server 2017 or above) to identify nondistinct freight values for the same customer:
WITH C AS
(
SELECT custid, freight,
STRING_AGG(CAST(orderid AS VARCHAR(MAX)), ', ')
WITHIN GROUP(ORDER BY orderid) AS orders
FROM Sales.Orders
GROUP BY custid, freight
HAVING COUNT(*) > 1
)
SELECT custid,
STRING_AGG(CONCAT('(freight: ', freight, ', orders: ', orders, ')'), ', ') as duplicates
FROM C
GROUP BY custid;This query generates the following output:
custid duplicates ------- --------------------------------------- 4 (freight: 23.72, orders: 10743, 10953) 90 (freight: 0.75, orders: 10615, 11005)
With these findings, you realize that the query with the bug reported incorrect total freight values for customers 4 and 90. The query reported correct total freight values for the rest of the customers since their freight values happened to be unique.
To fix the bug you need to separate the computation of aggregates of orders and of order lines to different steps using table expressions, like so:
WITH O AS
(
SELECT custid, COUNT(orderid) AS numorders, SUM(freight) AS totalfreight
FROM Sales.Orders
GROUP BY custid
),
OD AS
(
SELECT O.custid,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY O.custid
)
SELECT C.custid, O.numorders, O.totalfreight, OD.totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN O
ON C.custid = O.custid
LEFT OUTER JOIN OD
ON C.custid = OD.custid
ORDER BY C.custid;This query generates the following output:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 6 225.58 4273.00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 471.95 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 88.41 3161.35 ***** 91 7 175.74 3531.95
Observe the total freight values for customers 4 and 90 are now higher. These are the correct numbers.
The best practice here is to be mindful when joining and aggregating data. You want to be alert to such cases when joining multiple tables, and applying aggregates to measures from a table that is not an edge, or leaf, table in the joins. In such a case, you usually need to apply the aggregate computations within table expressions and then join the table expressions.
So the double-dipping aggregates bug is fixed. However, there is potentially another bug in this query. Can you spot it? I’ll provide the details about such a potential bug as the fourth case I’ll cover later under “OUTER-INNER join contradiction.”
ON-WHERE contradiction
Our third bug is a result of confusing the roles that the ON and WHERE clauses are supposed to play. As an example, suppose that you were given a task to match customers and orders that they placed since February 12, 2019, but also include in the output customers who did not place orders since then. You attempt to solve the task using the following query (call it Query 3):
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
WHERE O.orderdate >= '20190212';When using an inner join, both ON and WHERE play the same filtering roles, and therefore it doesn’t matter how you organize the predicates between these clauses. However, when using an outer join like in our case, these clauses have different meanings.
The ON clause plays a matching role, meaning that all rows from the preserved side of the join (Customers in our case) are going to be returned. The ones that have matches based on the ON predicate are connected with their matches, and as a result, repeated per match. The ones that don’t have any matches are returned with NULLs as placeholders in the nonpreserved side’s attributes.
Conversely, the WHERE clause, plays a simpler filtering role—always. This means that rows for which the filtering predicate evaluates to true are returned, and all the rest are discarded. As a result, some of the rows from the preserved side of the join can be removed altogether.
Remember that attributes from the nonpreserved side of the outer join (Orders in our case) are marked as NULLs for outer rows (nonmatches). Whenever you apply a filter involving an element from the nonpreserved side of the join, the filter predicate evaluates to unknown for all outer rows, resulting in their removal. This is in accord with the three-valued predicate logic that SQL follows. Effectively, the join becomes an inner join as a result. The one exception to this rule is when you specifically look for a NULL in an element from the nonpreserved side to identify nonmatches (element IS NULL).
Our buggy query generates the following output:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (195 rows affected)
The desired output is supposed to have 213 rows including 195 rows representing orders that were placed since February 12, 2019, and 18 additional rows representing customers who haven’t placed orders since then. As you can see, the actual output doesn’t include the customers who haven’t placed orders since the specified date.
The plan for this query is shown in Figure 3.
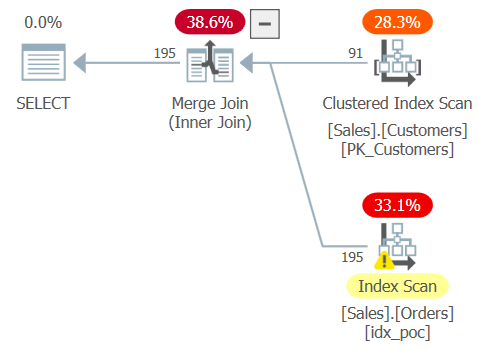 Figure 3: Plan for Query 3
Figure 3: Plan for Query 3
Observe that the optimizer detected the contradiction, and internally converted the outer join to an inner join. That’s good to see, but at the same time it is a clear indication that there’s a bug in the query.
I’ve seen cases where people tried to fix the bug by adding the predicate OR O.orderid IS NULL to the WHERE clause, like so:
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
WHERE O.orderdate >= '20190212'
OR O.orderid IS NULL;The only matching predicate is the one comparing the customer IDs from the two sides. So the join itself returns customers who placed orders in general, along with their matching orders, as well as customers who didn’t place orders at all, with NULLs in their order attributes. Then the filtering predicates filter customers who placed orders since the specified date, as well as customers who haven’t placed orders at all (customers 22 and 57). The query is missing customers who placed some orders, but not since the specified date!
This query generates the following output:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 22 Customer DTDMN NULL NULL 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (197 rows affected)
To correctly fix the bug, you need both the predicate that compares the customer IDs from the two sides, and the one against the order date to be considered matching predicates. To achieve this, both need to be specified in the ON clause, like so (call this Query 4):
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
AND O.orderdate >= '20190212';This query generates the following output:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 3 Customer KBUDE NULL NULL 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 7 Customer QXVLA NULL NULL 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 21 Customer KIDPX NULL NULL 22 Customer DTDMN NULL NULL 23 Customer WVFAF NULL NULL 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (213 rows affected)
The plan for this query is shown in Figure 4.
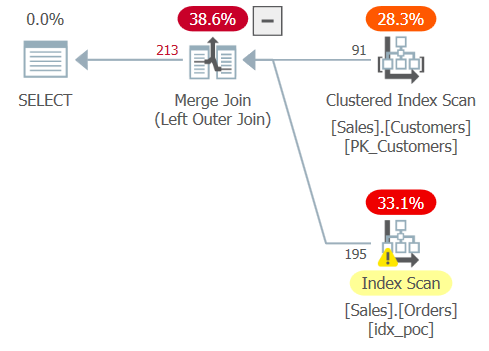 Figure 4: Plan for Query 4
Figure 4: Plan for Query 4
As you can see, the optimizer handled the join as an outer join this time.
This is a very simple query that I used for illustration purposes. With much more elaborate and complex queries, even experienced developers can have a hard time figuring out whether a predicate belongs in the ON clause or in the WHERE clause. What makes things easy for me is to simply ask myself whether the predicate is a matching predicate or a filtering one. If the former, it belongs in the ON clause; if the latter, it belongs in the WHERE clause.
OUTER-INNER join contradiction
Our fourth and last bug is in a way a variation of the third bug. It typically happens in multi-join queries where you mix join types. As an example, suppose that you need to join the tables Customers, Orders, OrderDetails, Products and Suppliers to identify customer-supplier pairs that had joint activity. You write the following query (call it Query 5):
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
INNER JOIN Sales.Orders AS O
ON O.custid = C.custid
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid;This query generates the following output with 1,236 rows:
custid customer supplierid supplier ------- --------------- ----------- --------------- 1 Customer NRZBB 1 Supplier SWRXU 1 Customer NRZBB 3 Supplier STUAZ 1 Customer NRZBB 7 Supplier GQRCV ... 21 Customer KIDPX 24 Supplier JNNES 21 Customer KIDPX 25 Supplier ERVYZ 21 Customer KIDPX 28 Supplier OAVQT 23 Customer WVFAF 3 Supplier STUAZ 23 Customer WVFAF 7 Supplier GQRCV 23 Customer WVFAF 8 Supplier BWGYE ... 56 Customer QNIVZ 26 Supplier ZWZDM 56 Customer QNIVZ 28 Supplier OAVQT 56 Customer QNIVZ 29 Supplier OGLRK 58 Customer AHXHT 1 Supplier SWRXU 58 Customer AHXHT 5 Supplier EQPNC 58 Customer AHXHT 6 Supplier QWUSF ... (1236 rows affected)
The plan for this query is shown in Figure 5.
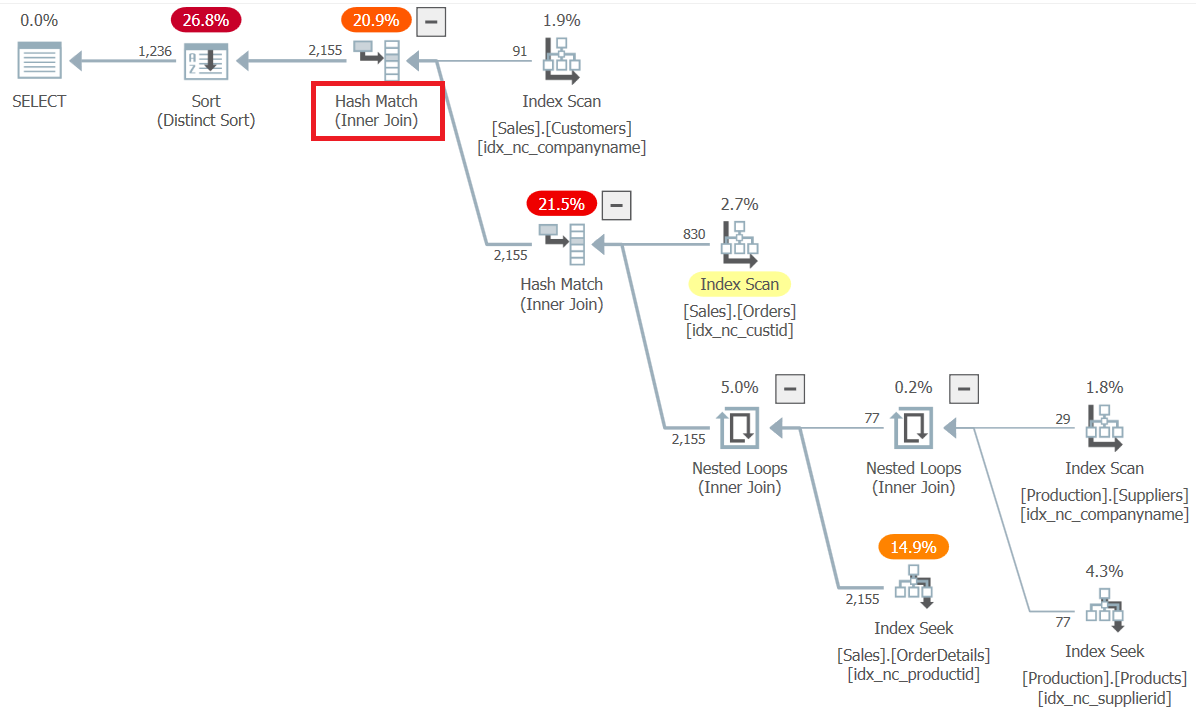 Figure 5: Plan for Query 5
Figure 5: Plan for Query 5
All joins in the plan are processed as inner joins as you would expect.
You can also observe in the plan that the optimizer applied join-ordering optimization. With inner joins, the optimizer knows that it can rearrange the physical order of the joins in any way that it likes while preserving the original query’s meaning, so it has a lot of flexibility. Here, its cost-based optimization resulted in the order: join(Customers, join(Orders, join(join(Suppliers, Products), OrderDetails))).
Suppose that you get a requirement to change the query such that it includes customers who haven’t placed orders. Recall that we currently have two such customers (with IDs 22 and 57), so the desired result is supposed to have 1,238 rows. A common bug in such a case is to change the inner join between Customers and Orders to a left outer join, but to leave all the rest of the joins as inner ones, like so:
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid;When a left outer join is subsequently followed by inner or right outer joins, and the join predicate compares something from the nonpreserved side of the left outer join with some other element, the outcome of the predicate is the logical value unknown, and the original outer rows are discarded. The left outer join effectively becomes an inner join.
As a result, this query generates the same output like for Query 5, returning only 1,236 rows. Also here the optimizer detects the contradiction, and converts the outer join to an inner join, generating the same plan shown earlier in Figure 5.
A common attempt to fix the bug is to make all joins left outer join, like so:
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
LEFT OUTER JOIN Production.Products AS P
ON P.productid = OD.productid
LEFT OUTER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid;This query generates the following output, which does include customers 22 and 57:
custid customer supplierid supplier ------- --------------- ----------- --------------- 1 Customer NRZBB 1 Supplier SWRXU 1 Customer NRZBB 3 Supplier STUAZ 1 Customer NRZBB 7 Supplier GQRCV ... 21 Customer KIDPX 24 Supplier JNNES 21 Customer KIDPX 25 Supplier ERVYZ 21 Customer KIDPX 28 Supplier OAVQT 22 Customer DTDMN NULL NULL 23 Customer WVFAF 3 Supplier STUAZ 23 Customer WVFAF 7 Supplier GQRCV 23 Customer WVFAF 8 Supplier BWGYE ... 56 Customer QNIVZ 26 Supplier ZWZDM 56 Customer QNIVZ 28 Supplier OAVQT 56 Customer QNIVZ 29 Supplier OGLRK 57 Customer WVAXS NULL NULL 58 Customer AHXHT 1 Supplier SWRXU 58 Customer AHXHT 5 Supplier EQPNC 58 Customer AHXHT 6 Supplier QWUSF ... (1238 rows affected)
However, there are two problems with this solution. Suppose that besides Customers you could have rows in another table in the query with no matching rows in a subsequent table, and that in such a case you don’t want to keep those outer rows. For example, what if in your environment it was allowed to create a header for an order, and at a later point fill it with order lines. Suppose that in such a case, the query isn’t supposed to return such empty order headers. Still, the query is supposed to return customers without orders. Since the join between Orders and OrderDetails is a left outer join, this query will return such empty orders, even though it shouldn’t.
Another problem is that when using outer joins, you impose more restrictions on the optimizer in terms of the rearrangements that it is allowed to explore as part of its join-ordering optimization. The optimizer can rearrange the join A LEFT OUTER JOIN B to B RIGHT OUTER JOIN A, but that’s pretty much the only rearrangement it’s allowed to explore. With inner joins, the optimizer can also reorder tables beyond just flipping sides, for example, it can reorder join(join(join(join(A, B), C), D), E)))) to join(A, join(B, join(join(E, D), C))) as shown earlier in Figure 5.
If you think about it, what you’re really after is to left-join Customers with the result of the inner joins between the rest of the tables. Obviously, you can achieve this with table expressions. However, T-SQL supports another trick. What truly determines logical join ordering is not exactly the order of the tables in the FROM clause, rather the order of the ON clauses. However, in order for the query to be valid, each ON clause must appear right below the two units that it’s joining. So, in order to consider the join between Customers and the rest as last, all you need to do is to move the ON clause that connects Customers and the rest to appear last, like so:
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
-- move from here -----------------------
INNER JOIN Sales.OrderDetails AS OD --
ON OD.orderid = O.orderid --
INNER JOIN Production.Products AS P --
ON P.productid = OD.productid --
INNER JOIN Production.Suppliers AS S --
ON S.supplierid = P.supplierid --
ON O.custid = C.custid; -- <-- to here --Now the logical join ordering is: leftjoin(Customers, join(join(join(Orders, OrderDetails), Products), Suppliers)). This time, you will keep customers who haven’t placed orders, but you won’t keep order headers that don’t have matching order lines. Also, you allow the optimizer full join-ordering flexibility in the inner joins between Orders, OrderDetails, Products and Suppliers.
The one drawback of this syntax is readability. The good news is that this can be easily fixed by using parentheses, like so (call this Query 6):
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN
( Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid )
ON O.custid = C.custid;Don’t confuse the use of parentheses here with a derived table. This isn’t a derived table, rather just a way to separate some of the table operators to their own unit, for clarity. The language doesn’t really need these parentheses, but they are strongly recommended for readability.
The plan for this query is shown in Figure 6.
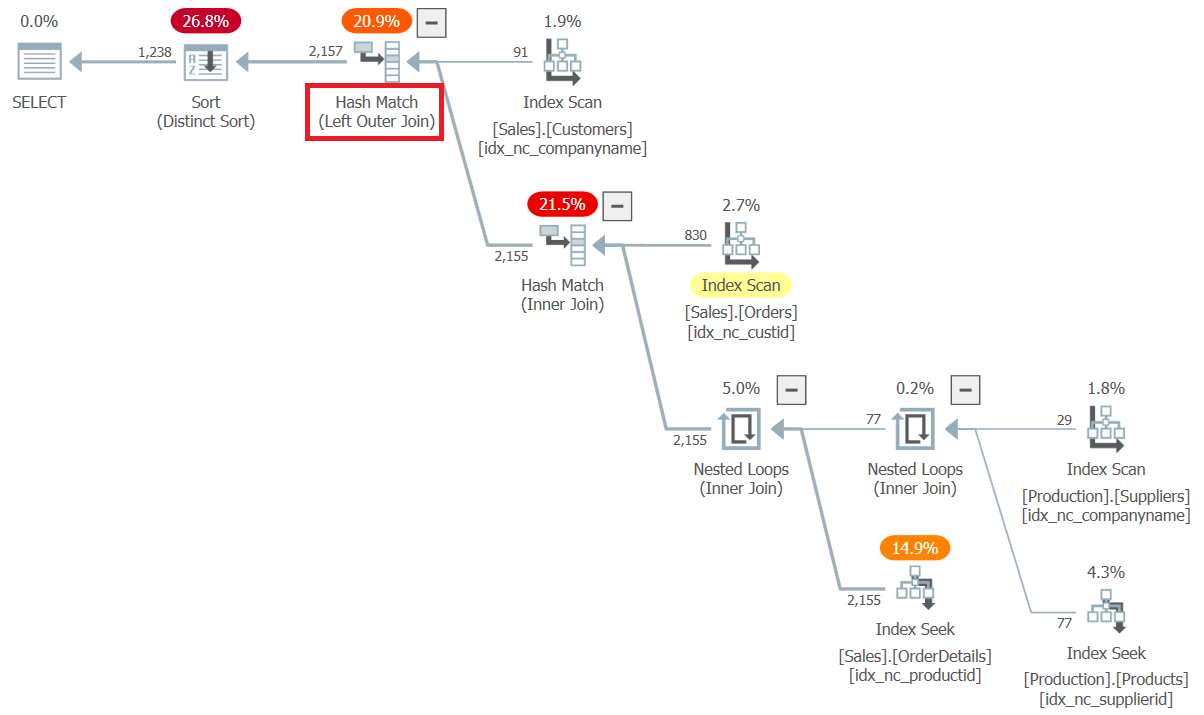 Figure 6: Plan for Query 6
Figure 6: Plan for Query 6
Observe that this time the join between Customers and the rest is processed as an outer join, and that the optimizer applied join-ordering optimization.
Conclusion
In this article I covered four classic bugs related to joins. When using outer joins, computing the COUNT(*) aggregate typically results in a bug. The best practice is to apply the aggregate to a non-NULLable column from the nonpreserved side of the join.
When joining multiple tables and involving aggregate calculations, if you apply the aggregates to a nonleaf table in the joins, it’s usually a bug resulting in double-dipping aggregates. The best practice is then to apply the aggregates within table expressions and joining the table expressions.
It’s common to confuse the meanings of the ON and WHERE clauses. With inner joins, they’re both filters, so it doesn’t really matter how you organize your predicates within these clauses. However, with outer joins the ON clause serves a matching role whereas the WHERE clause serves a filtering role. Understanding this helps you figure out how to organize your predicates within these clauses.
In multi-join queries, a left outer join that is subsequently followed by an inner join, or a right outer join, where you compare an element from the nonpreserved side of the join with others (other than the IS NULL test), the outer rows of the left outer join are discarded. To avoid this bug, you want to apply the left outer join last, and this can be achieved by shifting the ON clause that connects the preserved side of this join with the rest to appear last. Use parentheses for clarity even though they are not required.
9 thoughts on “T-SQL bugs, pitfalls, and best practices – joins”
Comments are closed.

{kind=link}
On Double-dipping aggregates, any benefit on doing aggregation by OrderID and custID , joining by OrderID, then aggregation only by custID?
with o AS
(
SELECT o.custid, o.orderid , count(o.orderID) as numOrders ,
sum(o.freight) as totalFreight
FROM sales.Orders as o
GROUP BY o.orderid,o.custid
)
, od As
(
SELECT od.orderid ,CAST(SUM(OD.qty * OD.unitprice * (1 – OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM sales.OrderDetails as od
GROUP BY od.orderid
)
SELECT C.custid
, COUNT(O.orderid) AS numorders
, SUM(o.totalFreight) AS totalfreight,
CAST(SUM(OD.totalval) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN o
ON C.custid = O.custid
LEFT OUTER JOIN od
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid;
It's another solution. The more the merrier. :) When querying large tables, I'd certainly try more than one option.
Thanks for sending this,
Itzik
Thank you for the knowledge you pass with every post
My pleasure!
Remarkable post, Thanks a lot!
Thanks Mickey!
As far as I can see, the last version of the "ON-WHERE contradiction" query still returns the customers who never placed orders. Shouldn't it contain an additional condition like this one: "WHERE EXISTS (SELECT * FROM Sales.Orders AS O2 WHERE O2.custid = C.custid)" ?
Hi Dmitry,
The task is: "match customers and orders that they placed since February 12, 2019, but also include in the output customers who did not place orders since then." This implicitly includes customers who never placed orders. Therefore the existing solution is correct. If the task added "excluding customers who never placed orders," you would need the addition you suggested.
Regards,
Itzik
Hi Itzik.
It was not quite clear for me that including customers without orders was implied, thanks for clarification.
Such misunderstanding is probably worth a separate article, something like "Implied conditions: pitfalls of collecting requirements" :).
Thanks again,
Dmitriy