
Serializing Deletes From Clustered Columnstore Indexes
At Stack Overflow, we have some tables using clustered columnstore indexes, and these work great for the majority of our workload. But we recently came across a situation where “perfect storms” — multiple processes all trying to delete from the same CCI — would overwhelm the CPU as they all went widely parallel and fought to complete their operation. Here's what it looked like in SolarWinds® SQL Sentry®:
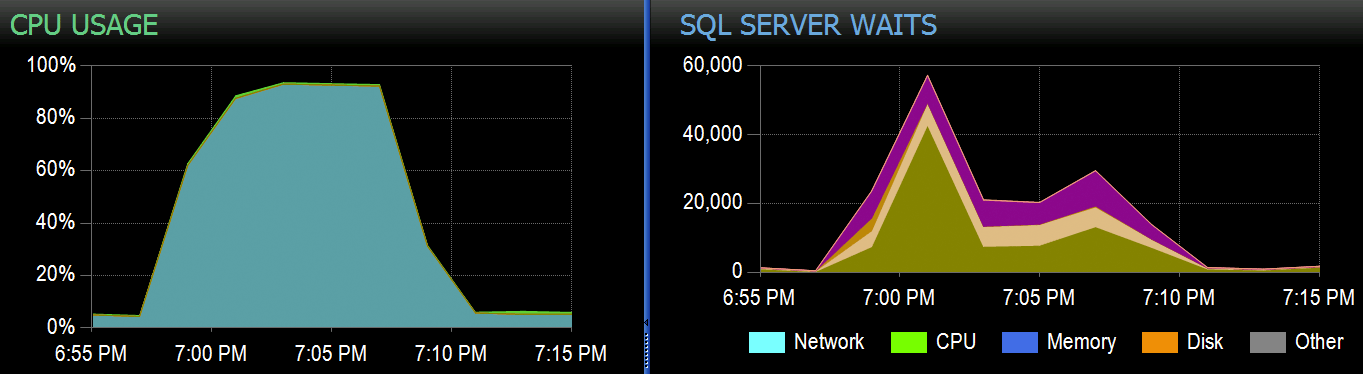
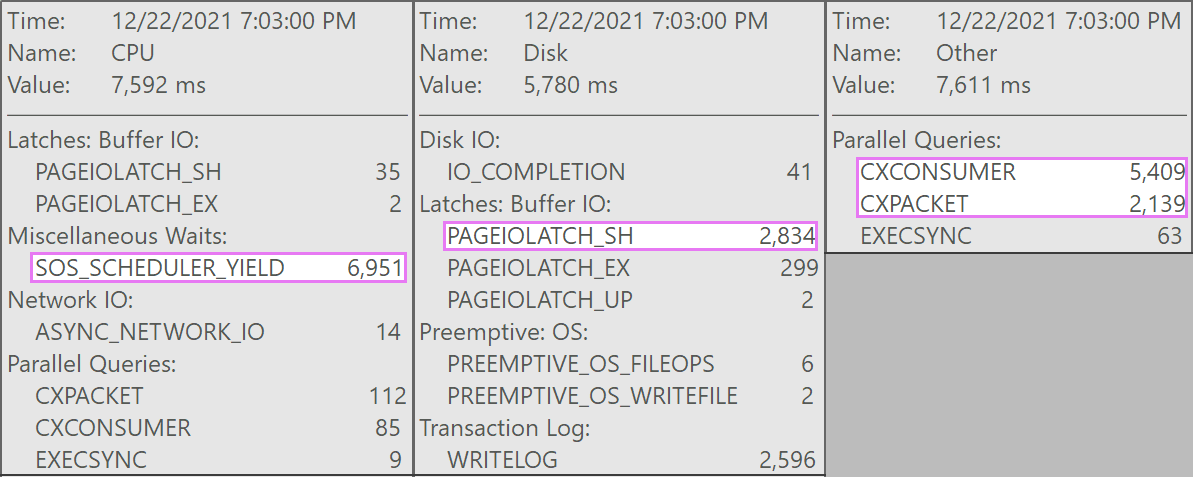
And here are the interesting waits associated with these queries:
The queries competing were all of this form:
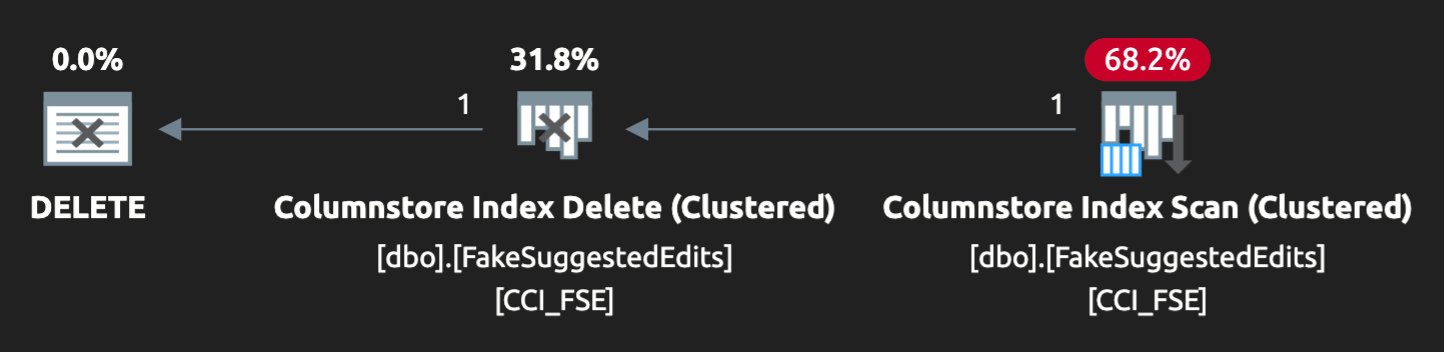
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;The plan looked like this:

And the warning on the scan advised us of some pretty extreme residual I/O:

The table has 1.9 billion rows but is only 32GB (thank you, columnar storage!). Still, these single-row deletes would take 10 – 15 seconds each, with most of this time being spent on SOS_SCHEDULER_YIELD.
Thankfully, since in this scenario the delete operation could be asynchronous, we were able to solve the problem with two changes (though I’m grossly oversimplifying here):
- We limited
MAXDOPat the database level so these deletes can't go quite so parallel - We improved serialization of the processes coming from the application (basically, we queued deletes through a single dispatcher)
As a DBA, we can easily control MAXDOP, unless it’s overridden at the query level (another rabbit hole for another day). We can't necessarily control the application to this extent, especially if it’s distributed or not ours. How can we serialize the writes in this case without drastically changing the application logic?
A Mock Setup
I'm not going to try to create a two billion-row table locally — never mind the exact table — but we can approximate something on a smaller scale and try to reproduce the same issue.
Let's pretend this is the SuggestedEdits table (in reality, it's not). But it's an easy example to use because we can pull the schema from the Stack Exchange Data Explorer. Using this as a base, we can create an equivalent table (with a few minor changes to make it easier to populate) and throw a clustered columnstore index on it:
CREATE TABLE dbo.FakeSuggestedEdits
(
Id int IDENTITY(1,1),
PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200,
CreationDate datetime2 NOT NULL DEFAULT sysdatetime(),
ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(),
RejectionDate datetime2 NULL,
OwnerUserId int NOT NULL DEFAULT 7,
Comment nvarchar (800) NOT NULL DEFAULT NEWID(),
Text nvarchar (max) NOT NULL DEFAULT NEWID(),
Title nvarchar (250) NOT NULL DEFAULT NEWID(),
Tags nvarchar (250) NOT NULL DEFAULT NEWID(),
RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(),
INDEX CCI_FSE CLUSTERED COLUMNSTORE
);To populate it with 100 million rows, we can cross join sys.all_objects and sys.all_columns five times (on my system, this will produce 2.68 million rows each time, but YMMV):
-- 2680350 * 5 ~ 3 minutes
INSERT dbo.FakeSuggestedEdits(CreationDate)
SELECT TOP (10) /*(2000000) */ modify_date
FROM sys.all_objects AS o
CROSS JOIN sys.columns AS c;
GO 5Then, we can check the space:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';It's only 1.3GB, but this should be sufficient:

Mimicking Our Clustered Columnstore Delete
Here’s a simple query roughly matching what our application was doing to the table:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7;
DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;The plan isn't quite a perfect match, though:
To get it to go parallel and produce similar contention on my meager laptop, I had to coerce the optimizer a little with this hint:
OPTION (QUERYTRACEON 8649);Now, it looks right:

Reproducing the Problem
Then, we can create a surge of concurrent delete activity using SqlStressCmd to delete 1,000 random rows using 16 and 32 threads:
sqlstresscmd -s docs/ColumnStore.json -t 16
sqlstresscmd -s docs/ColumnStore.json -t 32We can observe the strain this puts on CPU:
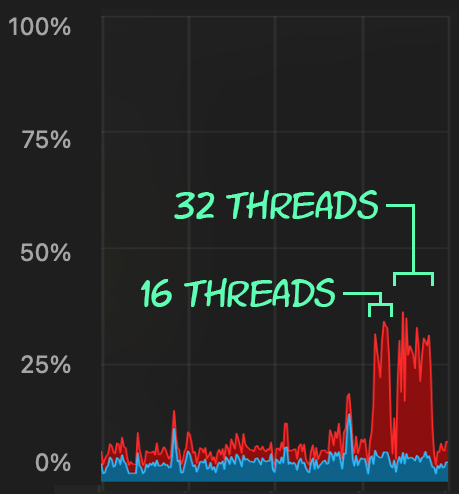
The strain on CPU lasts throughout the batches of about 64 and 130 seconds, respectively:
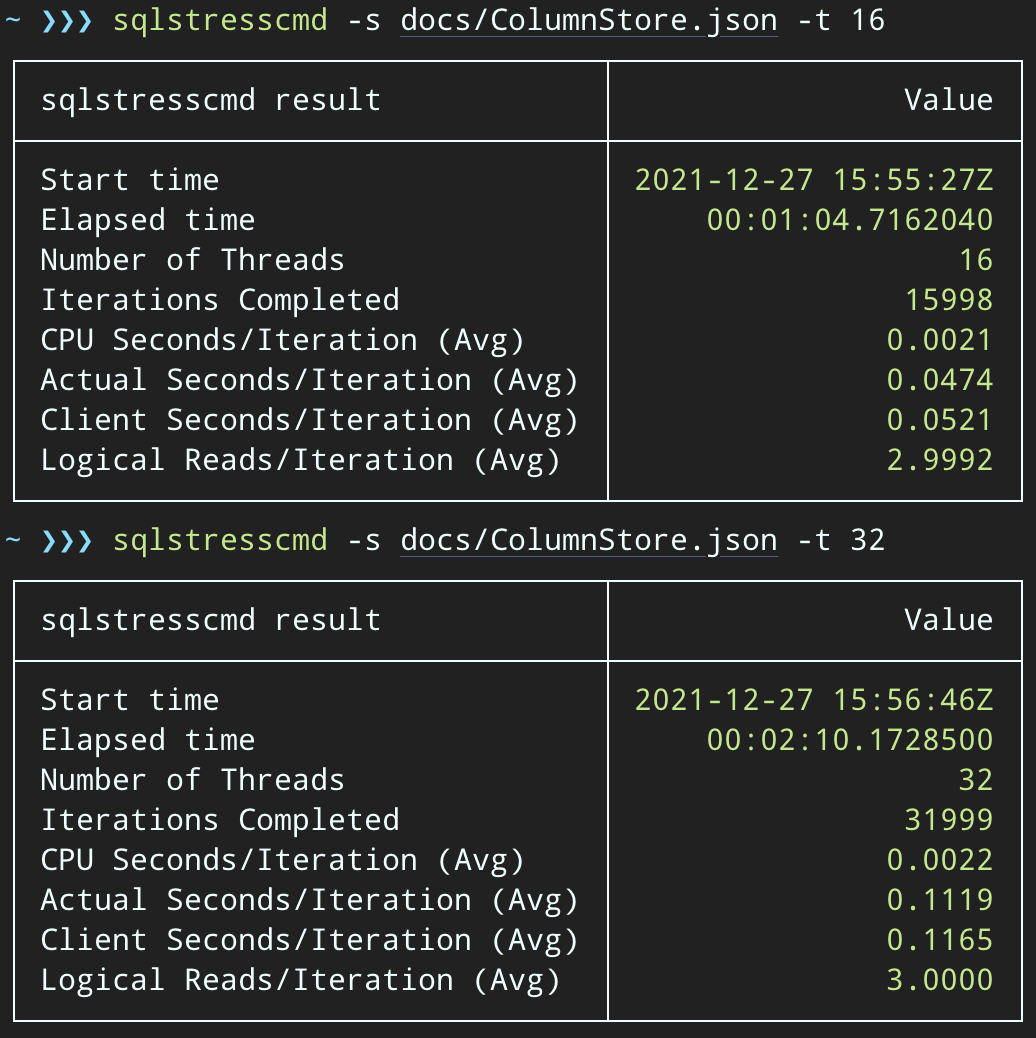
Note: The output from SQLQueryStress is sometimes a little off on iterations, but I’ve confirmed the work you ask it to do gets done precisely.
A Potential Workaround: A Delete Queue
Initially, I thought about introducing a queue table in the database, which we could use to offload delete activity:
CREATE TABLE dbo.SuggestedEditDeleteQueue
(
QueueID int IDENTITY(1,1) PRIMARY KEY,
EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(),
ProcessedDate datetime2 NULL,
Id int NOT NULL,
OwnerUserId int NOT NULL
);All we need is an INSTEAD OF trigger to intercept these rogue deletes coming from the application and place them on the queue for background processing. Unfortunately, you can't create a trigger on a table with a clustered columnstore index:
CREATE TRIGGER on table 'dbo.FakeSuggestedEdits' failed because you cannot create a trigger on a table with a clustered columnstore index. Consider enforcing the logic of the trigger in some other way, or if you must use a trigger, use a heap or B-tree index instead.
We'll need a minimal change to the application code, so that it calls a stored procedure to handle the delete:
CREATE PROCEDURE dbo.DeleteSuggestedEdit
@Id int,
@OwnerUserId int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.FakeSuggestedEdits
WHERE Id = @Id AND OwnerUserId = @OwnerUserId;
ENDThis isn't a permanent state; this is just to keep the behavior the same while changing only one thing in the app. Once the app is changed and is successfully calling this stored procedure instead of submitting ad hoc delete queries, the stored procedure can change:
CREATE PROCEDURE dbo.DeleteSuggestedEdit
@Id int,
@OwnerUserId int
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId)
SELECT @Id, @OwnerUserId;
ENDTesting the Impact of the Queue
Now, if we change SqlQueryStress to call the stored procedure instead:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7;
EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;And submit similar batches (placing 16K or 32K rows on the queue):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7;
EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;The CPU impact is slightly higher:
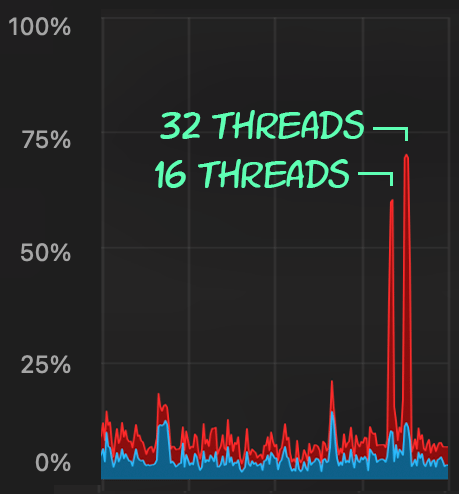
But the workloads finish much more quickly — 16 and 23 seconds, respectively:
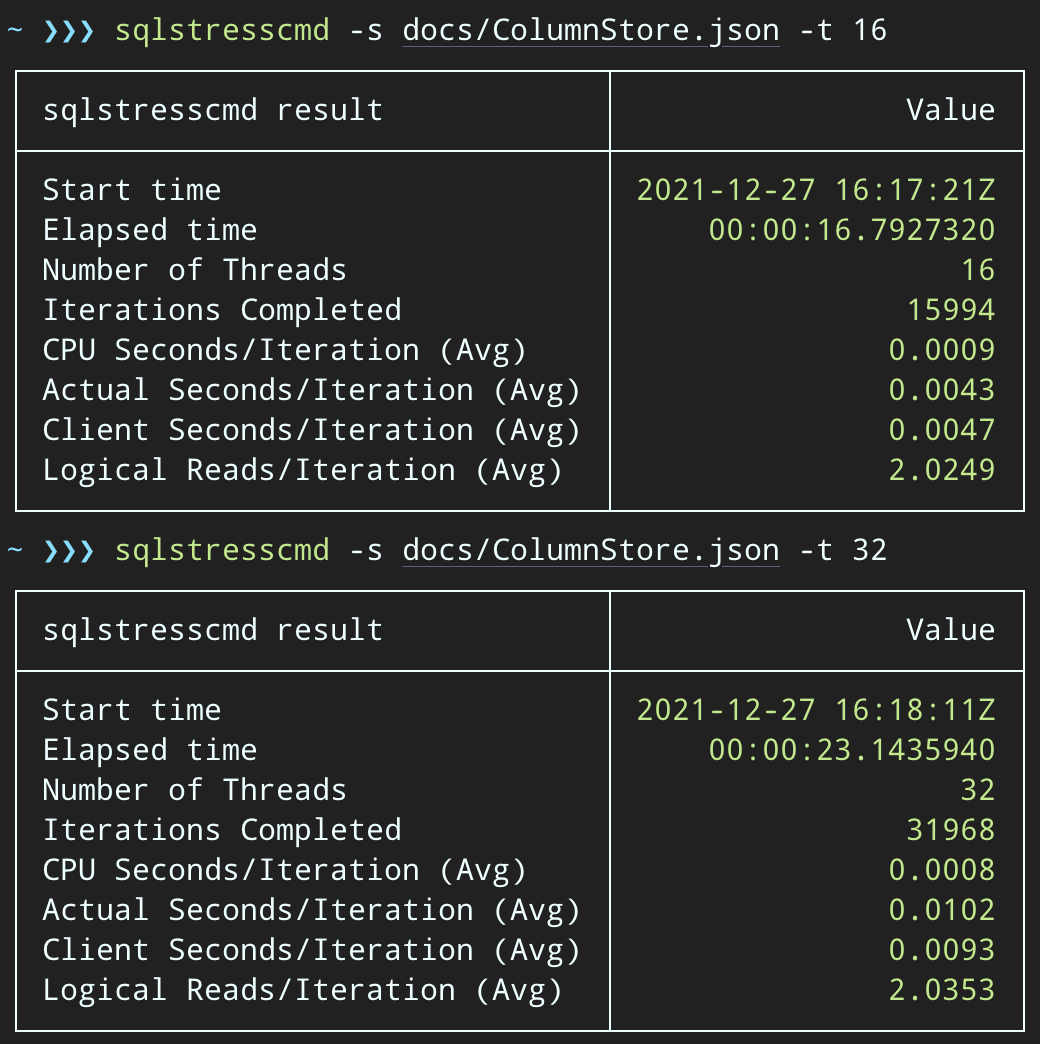
This is a significant reduction in the pain the applications will feel as they get into periods of high concurrency.
We Still Have to Perform the Delete, Though
We still have to process those deletes in the background, but we can now introduce batching and have full control over the rate and any delays we want to inject between operations. Here’s the very basic structure of a stored procedure to process the queue (admittedly without fully vested transactional control, error handling, or queue table cleanup):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
ENDNow, deleting rows will take longer — the average for 10,000 rows is 223 seconds, ~100 of which is intentional delay. But no user is waiting, so who cares? The CPU profile is almost zero, and the app can continue adding items on the queue as highly concurrent as it wants, with almost zero conflict with the background job. While processing 10,000 rows, I added another 16K rows to the queue, and it used the same CPU as before — taking only a second longer than when the job wasn't running:
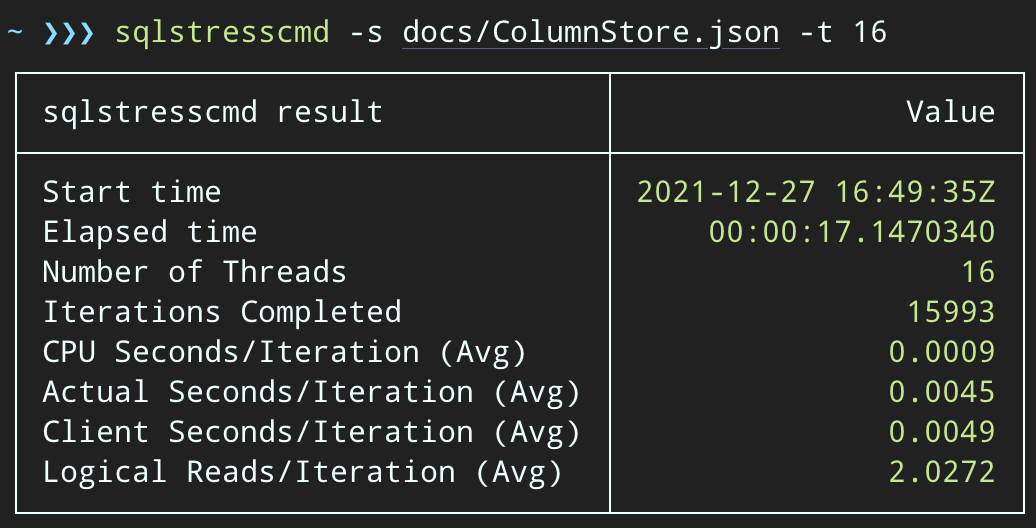
And the plan now looks like this, with much better estimated / actual rows:
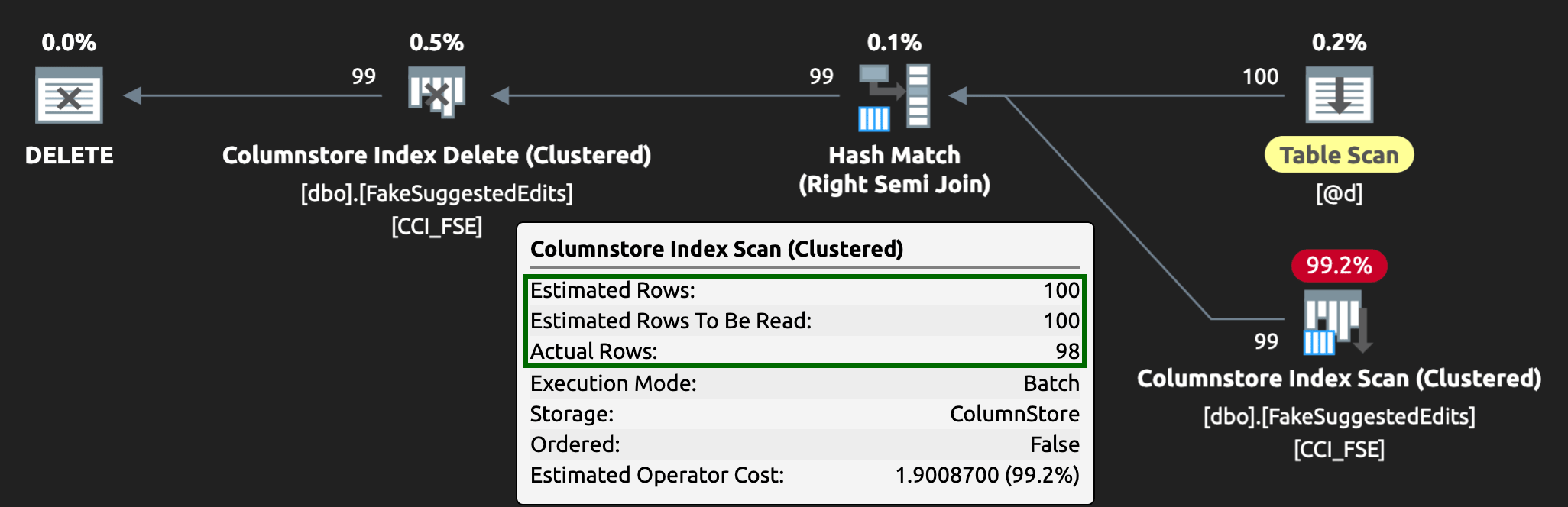
I can see this queue table approach being an effective way to deal with high DML concurrency, but it does require at least a little bit of flexibility with the applications submitting DML — this is one reason I really like having applications call stored procedures, as they give us much more control closer to the data.
Other Options
If you don’t have the ability to change the delete queries coming from the application — or, if you can’t defer the deletes to a background process — you can consider other options to reduce the impact of the deletes:
- A nonclustered index on the predicate columns to support point lookups (we can do this in isolation without changing the application)
- Using soft deletes only (still requires changes to the application)
It’ll be interesting to see if these options offer similar benefits, but I’ll save them for a future post.

hello Aaron,
As a workaround to the trigger issue, would it be possible to create a view on top of that table and then create instead of trigger on the view?
Hey Kamil, I considered that, but the only thing that made the trigger an attractive option in the first place was to avoid changing the app. Since I have to change the app in either case (to delete from the view or call the stored procedure), the stored procedure is much more appealing – both because it is more visible and it feels less sneaky. The only way to use a view + trigger *and* not change the app would be to swap names and that is even less appealing (and would affect a lot of other application code too).
Yes so what I had in mind was the latter i.e. renaming the original table and then renaming the view to output all of the fields, and avoid changing the application, but I assumed there would only be some simple operations on the view like inserts and deletes
Of course I agree that calling stored procedure is a very clean and more transparent option.
Did you consider using a plan guide to force it to MAXDOP 1?
Charlie, not really, as they resolved the issue from the app side before I got to PoC anything. But I would need a plan guide for every database / schema, and in the Teams side we have 10,000 schemas per database. Plan guides are a pain to manage one at a time, IMHO, never mind 10,000.
It's a trivial thing, but one of my pet peeves.
You define the 3 "date" columns as datetime, but populate them with a datetime2.
Am I interpreting this correctly, in that a DELETE of 1 (to N) rows all require/execute a table scan of the CCI table? And also that the exclusive lock taken for a DELETE is non-affecting from the application side? If so, why limit the number of rows being DELETEd? You have restricted the CPU hit via MAXDOP, so just delete all currently-queued rows one pass and you are done. I know you are incredibly sharp Aaron, so I am wondering what I am missing here! :-D
Kevin, you could certainly ignore the job size / batch size parameters and just delete with a join to the queue table. However the goal of the queue is not to get things done faster, it is to minimize impact. If there are 500 million rows on the queue I certainly don't want to pay the log and modify columnstore penalties for all that in a single transaction, just like I wouldn't want all of the app servers to suddenly try to delete 50 million rows each at the same time. If the app puts those on a queue I can pace them, defer, suspend during maintenance, etc.
Toby, how would you create a default value for a date column?
or
or
or
At what point does this conversion matter, whether it's explicit or implicit?