
T-SQL Tuesday #106 : INSTEAD OF triggers

For this month's T-SQL Tuesday, Steve Jones (@way0utwest) asked us to talk about our best or worst trigger experiences. While it's true that triggers are often frowned upon, and even feared, they do have several valid use cases, including:
- Auditing (before 2016 SP1, when this feature became free in all editions)
- Enforcement of business rules and data integrity, when they can't easily be implemented in constraints, and you don't want them dependent on application code or the DML queries themselves
- Maintaining historical versions of data (before Change Data Capture, Change Tracking, and Temporal Tables)
- Queueing alerts or asynchronous processing in response to a specific change
- Allowing modifications to views (via INSTEAD OF triggers)
That is not an exhaustive list, just a quick recap of a few scenarios I have experienced where triggers were the right answer at the time.
When triggers are necessary, I always like to explore the use of INSTEAD OF triggers rather than AFTER triggers. Yes, they are a little bit more up-front work*, but they have some pretty important benefits. In theory, at least, the prospect of preventing an action (and its log consequences) from happening seems a lot more efficient than letting it all happen and then undoing it.
*I say this because you have to code the DML statement again within the trigger; this is why they are not called BEFORE triggers. The distinction is important here, since some systems implement true BEFORE triggers, which simply run first. In SQL Server, an INSTEAD OF trigger effectively cancels the statement that caused it to fire.
Let's pretend we have a simple table to store account names. In this example we'll create two tables, so we can compare two different triggers and their impact on query duration and log usage. The concept is we have a business rule: the account name is not present in another table, which represents "bad" names, and the trigger is used to enforce this rule. Here is the database:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GOAnd the tables:
USE [tr];
GO
CREATE TABLE dbo.Accounts_After
(
AccountID int PRIMARY KEY,
name sysname UNIQUE,
filler char(255) NOT NULL DEFAULT ''
);
CREATE TABLE dbo.Accounts_Instead
(
AccountID int PRIMARY KEY,
name sysname UNIQUE,
filler char(255) NOT NULL DEFAULT ''
);
CREATE TABLE dbo.InvalidNames
(
name sysname PRIMARY KEY
);
INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');And, finally, the triggers. For simplicity, we're only dealing with inserts, and in both the after and the instead of case, we're just going to abort the whole batch if any single name violates our rule:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GONow, to test performance, we'll just try to insert 100,000 names into each table, with a predictable failure rate of 10%. In other words, 90,000 are okay names, the other 10,000 fail the test and cause the trigger to either rollback or not insert depending on the batch.
First, we need to do some cleanup before each batch:
TRUNCATE TABLE dbo.Accounts_Instead;
TRUNCATE TABLE dbo.Accounts_After;
GO
CHECKPOINT;
CHECKPOINT;
BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION;
GOBefore we start the meat of each batch, we'll count the rows in the transaction log, and measure the size and free space. Then we'll go through a cursor to process the 100,000 rows in random order, attempting to insert each name into the appropriate table. When we're done, we'll measure the row counts and size of the log again, and check the duration.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c;Results (averaged over 5 runs of each batch):
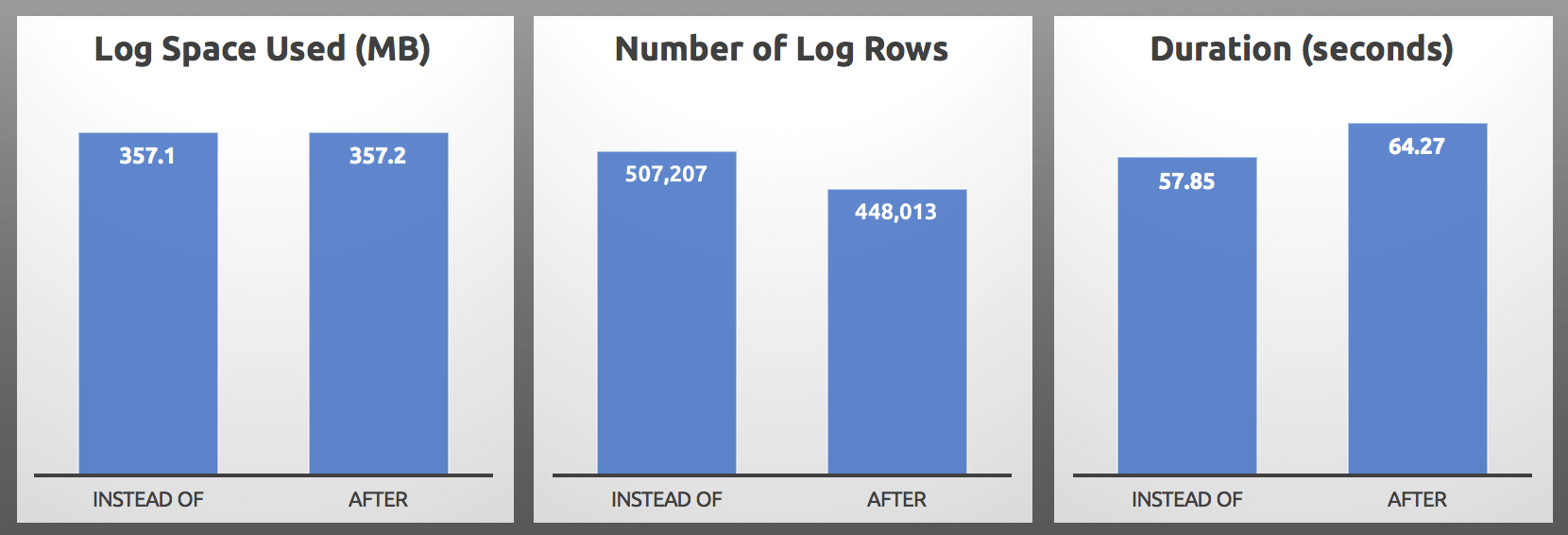 AFTER vs. INSTEAD OF : Results
AFTER vs. INSTEAD OF : Results
In my tests, the log usage was almost identical in size, with over 10% more log rows generated by the INSTEAD OF trigger. I did some digging at the end of each batch:
SELECT [Operation], COUNT(*)
FROM sys.fn_dblog(NULL, NULL)
GROUP BY [Operation]
ORDER BY [Operation];And here was a typical result (I highlighted the major deltas):
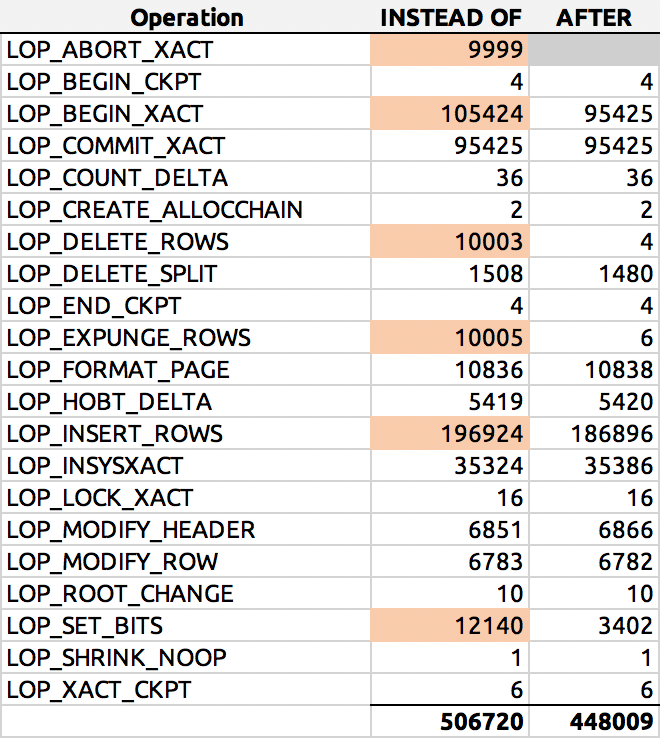 Log row distribution
Log row distribution
I'll dig into that more deeply another time.
But when you get right down to it…
…the most important metric is almost always going to be duration, and in my case the INSTEAD OF trigger performed at least 5 seconds faster in every single head-to-head test. In case this all sounds familiar, yeah, I've talked about it before, but back then I didn't observe these same symptoms with the log rows.
Note that this might not be your exact schema or workload, you may have very different hardware, your concurrency may be higher, and your failure rate may be much higher (or lower). My tests were performed on an isolated machine with plenty of memory and very fast PCIe SSDs. If your log is on a slower drive, then the differences in log usage might outweigh the other metrics and change durations significantly. All of these factors (and more!) can affect your results, so you should test in your environment.
The point, though, is that INSTEAD OF triggers might be a better fit. Now if only we could get INSTEAD OF DDL triggers…
1 thought on “T-SQL Tuesday #106 : INSTEAD OF triggers”
Comments are closed.

When Instead-Of-Triggers would not be so clumpsy (think of a table with 50 columns and you have only to set a single column to another value depending on whatever) and errorprone (as soon you start adding columns to the table and forgot the trigger and wonder, why the column will not be filled …)
They would be my favorit, when they would support some sort of inheriting and let me run an insert / update / delete to the INSERTED table and proceeds with the (remaining / new / modified) stuff in it after the trigger ends.