
Bad Habits: Avoiding NULL in SQL Server
A long time ago, I answered a question about NULL on Stack Exchange entitled, “Why shouldn’t we allow NULLs?” I have my share of pet peeves and passions, and the fear of NULLs is pretty high up on my list. A colleague recently said to me, after expressing a preference to force an empty string instead of allowing NULL:
"I don't like dealing with nulls in code."
I’m sorry, but that’s not a good reason. How the presentation layer deals with empty strings or NULLs shouldn’t be the driver for your table design and data model. And if you’re allowing a “lack of value” in some column, does it matter to you from a logical standpoint whether the “lack of value” is represented by a zero-length string or a NULL? Or worse, a token value like 0 or -1 for integers, or 1900-01-01 for dates?
Itzik Ben-Gan recently wrote a whole series on NULLs, and I highly recommend going through it all:
- NULL complexities – Part 1
- NULL complexities – Part 2
- NULL complexities – Part 3, Missing standard features and T-SQL alternatives
- NULL complexities – Part 4, Missing standard unique constraint
But my aim here is a little less complicated than that, after the topic came up in a different Stack Exchange question: “Add an auto now field to an existing table.” There, the user was adding a new column to an existing table, with the intention of auto-populating it with the current date/time. They wondered if they should leave NULLs in that column for all the existing rows or set a default value (like 1900-01-01, presumably, though they weren’t explicit).
It may be easy for someone in the know to filter out old rows based on a token value—after all, how could anyone believe some kind of Bluetooth doodad was manufactured or purchased on 1900-01-01? Well, I’ve seen this in current systems where they use some arbitrary-sounding date in views to act as a magic filter, only presenting rows where the value can be trusted. In fact, in every case I’ve seen so far, the date in the WHERE clause is the date/time when the column (or its default constraint) was added. Which is all fine; it’s maybe not the best way to solve the problem, but it’s a way.
If you’re not accessing the table through the view, though, this implication of a known value can still cause both logical and result-related problems. The logical problem is simply that someone interacting with the table has to know 1900-01-01 is a bogus, token value representing “unknown” or “not relevant.” For a real-world example, what was the average release speed, in seconds, for a quarterback who played in the 1970s, before we measured or tracked such a thing? Is 0 a good token value for “unknown”? How about -1? Or 100? Getting back to dates, if a patient without ID gets admitted to the hospital and is unconscious, what should they enter as date of birth? I don’t think 1900-01-01 is a good idea, and it certainly wasn’t a good idea back when that was more likely to be a real birthdate.
Performance Implications of Token Values
From a performance perspective, fake or “token” values like 1900-01-01 or 9999-21-31 can introduce problems. Let’s look at a couple of these with an example based loosely on the recent question mentioned above. We have a Widgets table and, after some warranty returns, we’ve decided to add an EnteredService column where we’ll enter the current date/time for new rows. In one case we’ll leave all the existing rows as NULL, and in the other we’ll update the value to our magical 1900-01-01 date. (We’ll leave any sort of compression out of the conversation for now.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
);Now we’ll insert the same 100,000 rows into each table:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL;Then we can add the new column and update 10% of the existing values with a distribution of current-ish dates, and the other 90% to our token date only in one of the tables:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000;Finally, we can add indexes:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService);
CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);Space Used
I always hear “disk space is cheap” when we talk about data type choices, fragmentation, and token values vs. NULL. My concern isn’t so much with the disk space these extra meaningless values take up. It’s more that, when the table is queried, it’s wasting memory. Here we can get a quick idea of how much space our token values consume before and after the column and index are added:
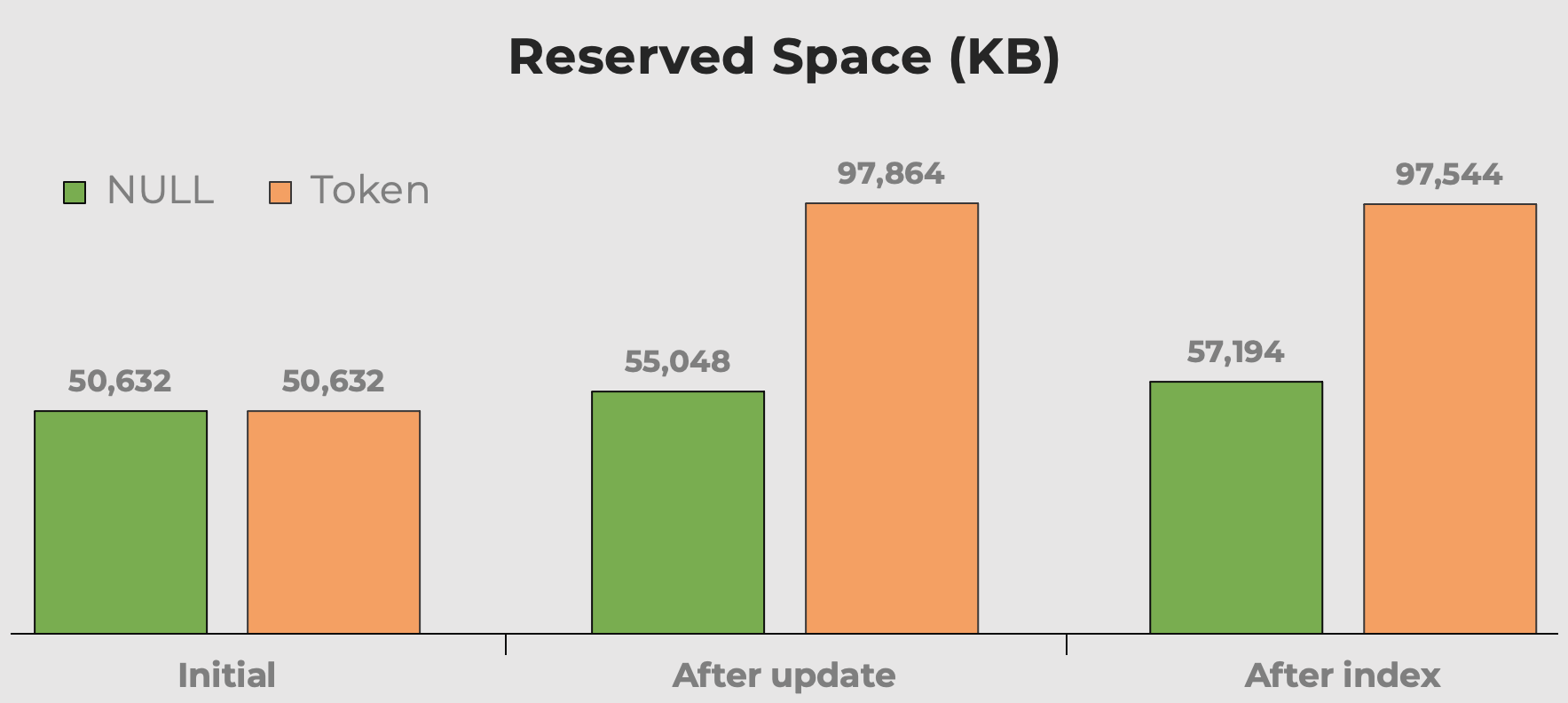 Reserved space of table after adding a column and adding an index. Space almost doubles with token values.
Reserved space of table after adding a column and adding an index. Space almost doubles with token values.
Query Execution
Inevitably, someone is going to make assumptions about the data in the table and query against the EnteredService column as if all the values there are legitimate. For example:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101';The token values can mess with estimates in some cases but, more importantly, they’re going to produce incorrect (or at least unexpected) results. Here is the execution plan for the query against the table with token values:
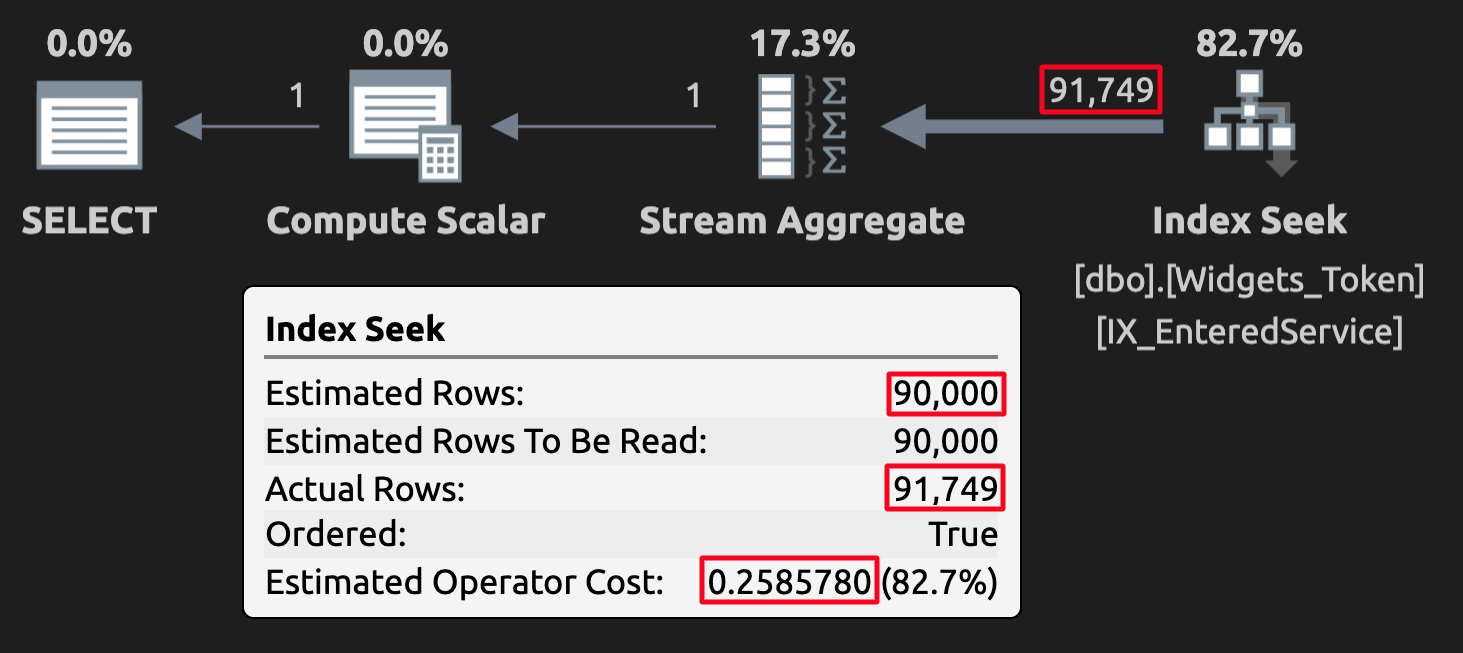 Execution plan for the token table; note the high cost.
Execution plan for the token table; note the high cost.
And here’s the execution plan for the query against the table with NULLs:
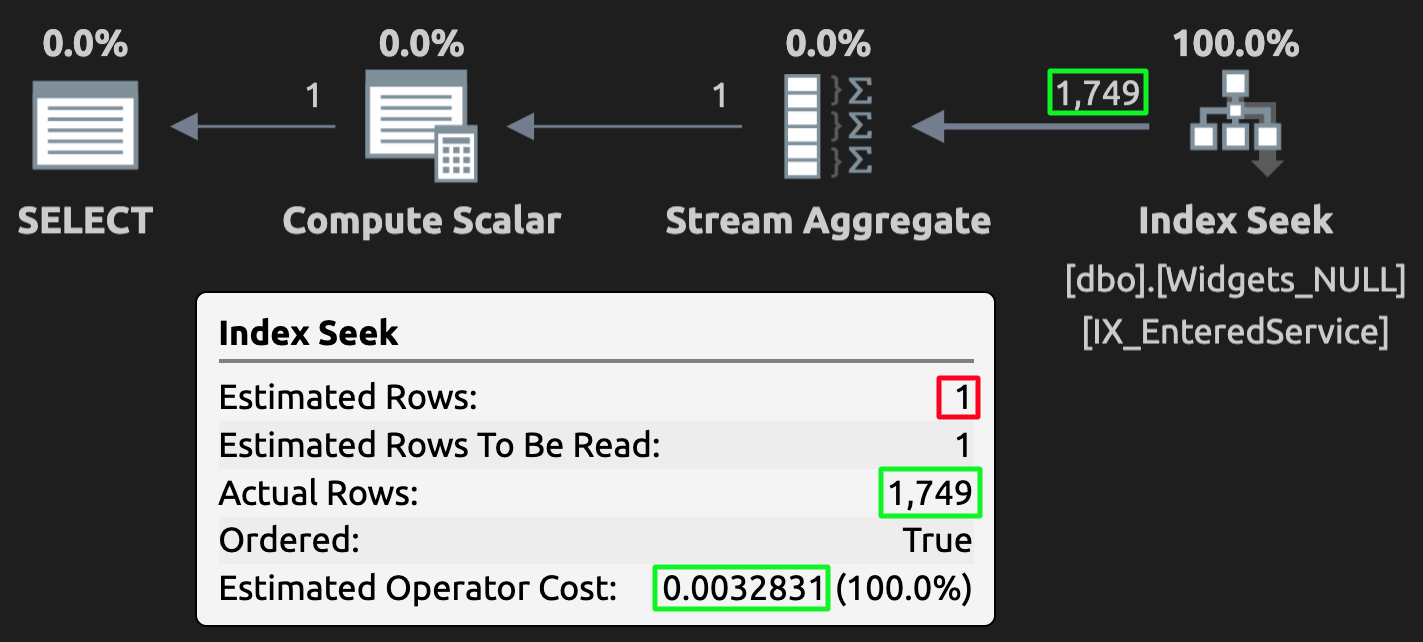 Execution plan for the NULL table; wrong estimate, but much lower cost.
Execution plan for the NULL table; wrong estimate, but much lower cost.
The same would happen the other way if the query asked for >= {some date} and 9999-12-31 was used as the magic value representing unknown.
Again, for the people who happen to know the results are wrong specifically because you’ve used token values, this isn’t an issue. But everyone else who doesn’t know that—including future colleagues, other inheritors and maintainers of the code, and even future you with memory challenges—is probably going to stumble.
Conclusion
The choice to allow NULLs in a column (or to avoid NULLs entirely) shouldn’t be reduced to an ideological or fear-based decision. There are real, tangible downsides to architecting your data model to make sure no value can be NULL, or using meaningless values to represent something that could easily have been not stored at all. I’m not suggesting every column in your model should allow NULLs; just that you not be opposed to the idea of NULLs.

Great article.
It's a shame that SQL Server doesn't support NULLS LAST, as that would obviate the only need for marker values: performant querying on EndTime values in temporal-style tables.
I think you should write another on the opposite problem: nullable on every column, that's just as egregious….
What about adding an extra column? The problem with NULL is that is means “not known,” but in this scenario we DO know. My idea: add a Boolean column called “legacy” (and of course some other name could be used) that is set to true for all of the old data, false for any new data. Then put NULLs in the date columns of the old data. For any new data, put the date, and unless for some reason we don’t know the date, in which case put a NULL.