
NULL complexities – Part 1
NULL handling is one of the trickier aspects of data modeling and data manipulation with SQL. Let’s start with the fact that an attempt to explain exactly what a NULL is is not trivial in and of itself. Even among people who do have a good grasp of relational theory and SQL, you will hear very strong opinions both in favor and against using NULLs in your database. Like them or not, as a database practitioner you often have to deal with them, and given that NULLs do add complexity to your SQL code writing, it’s a good idea to make it a priority to understand them well. This way you can avoid unnecessary bugs and pitfalls.
This article is the first in a series about NULL complexities. I start with coverage of what NULLs are and how they behave in comparisons. I then cover NULL treatment inconsistencies in different language elements. Finally, I cover missing standard features related to NULL handling in T-SQL and suggest alternatives that are available in T-SQL.
Most of the coverage is relevant to any platform that implements a dialect of SQL, but in some cases I do mention aspects that are specific to T-SQL.
In my examples I’ll use a sample database called TSQLV5. You can find the script that creates and populates this database here, and its ER diagram here.
NULL as a marker for a missing value
Let’s start with understanding what NULLs are. In SQL, a NULL is a marker, or a placeholder, for a missing value. It is SQL’s attempt at representing in your database a reality where a certain attribute value is sometimes present and sometimes missing. For example, suppose that you need to store employee data in an Employees table. You have attributes for firstname, middlename and lastname. The firstname and lastname attributes are mandatory, and therefore you define them as not allowing NULLs. The middlename attribute is optional, and therefore you define it as allowing NULLs.
If you’re wondering what does the relational model have to say about missing values, the model’s creator Edgar F. Codd did believe in them. In fact, he even made a distinction between two kinds of missing values: Missing But Applicable (A-Values marker), and Missing But Inapplicable (I-Values marker). If we take the middlename attribute as an example, in a case where an employee has a middle name, but for privacy reasons chooses not to share the information, you would use the A-Values marker. In a case where an employee doesn’t have a middle name at all you would use the I-Values marker. Here, the very same attribute could sometimes be relevant and present, sometimes Missing But Applicable and sometimes Missing But Inapplicable. Other cases could be clearer cut, supporting only one kind of missing values. For instance, suppose that you have an Orders table with an attribute called shippeddate holding the order’s shipping date. An order that was shipped will always have a present and relevant shipped date. The only case for not having a known shipping date would be for orders that were not shipped yet. So here, either a relevant shippeddate value must be present, or the I-Values marker should be used.
The designers of SQL chose not to get into the distinction of applicable versus inapplicable missing values, and provided us with the NULL as a marker for any kind of missing value. For the most part, SQL was designed to assume that NULLs represent the Missing But Applicable kind of missing value. Consequently, especially when your use of the NULL is as a placeholder for an inapplicable value, the default SQL NULL handling may not be the one that you perceive as correct. Sometimes you will need to add explicit NULL handling logic to get the treatment that you consider as the correct one for you.
As a best practice, if you know that an attribute is not supposed to allow NULLs, make sure you enforce it with a NOT NULL constraint as part of the column definition. There are a couple of important reasons for this. One reason is that if you don’t enforce this, at one point or another, NULLs will get there. It could be the result of a bug in the application or importing bad data. Using a constraint, you know that NULLs will never make it to the table. Another reason is that the optimizer evaluates constraints like NOT NULL for better optimization, avoiding unnecessary work looking for NULLs, and enabling certain transformations rules.
Comparisons involving NULLs
There’s some trickiness in SQL’s evaluation of predicates when NULLs are involved. I’ll first cover comparisons involving constants. Later I’ll cover comparisons involving variables, parameters and columns.
When you use predicates that compare operands in query elements like WHERE, ON and HAVING, the possible outcomes of the comparison depend on whether any of the operands can be a NULL. If you know with certainty that none of the operands can be a NULL, the predicate’s outcome will always be either TRUE or FALSE. This is what’s known as the two-valued predicate logic, or in short, simply two-valued logic. This is the case, for example, when you’re comparing a column that is defined as not allowing NULLs with some other non-NULL operand.
If any of the operands in the comparison may be a NULL, say, a column that allows NULLs, using both equality (=) and inequality (<>, >, <, >=, <=, etc.) operators, you are now at the mercy of three-valued predicate logic. If in a given comparison the two operands happen to be non-NULL values, you still get either TRUE or FALSE as the outcome. However, if any of the operands is NULL, you get a third logical value called UNKNOWN. Note that that’s the case even when comparing two NULLs. The treatment of TRUE and FALSE by most elements of SQL is pretty intuitive. The treatment of UNKNOWN is not always that intuitive. Moreover, different elements of SQL handle the UNKNOWN case differently, as I’ll explain in detail later in the article under “NULL treatment inconsistencies.”
As an example, suppose that you need to query the Sales.Orders table in the TSQLV5 sample database, and return orders that were shipped on January 2nd, 2019. You use the following query:
USE TSQLV5;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate = '20190102';It’s clear that the filter predicate evaluates to TRUE for rows where the shipped date is January 2nd, 2019, and that those rows should be returned. It’s also clear that the predicate evaluates to FALSE for rows where the shipped date is present, but isn’t January 2nd, 2019, and that those rows should be discarded. But what about rows with a NULL shipped date? Remember that both equality-based predicates and inequality-based predicates return UNKNOWN if any of the operands is NULL. The WHERE filter is designed to discard such rows. You need to remember that the WHERE filter returns rows for which the filter predicate evaluates to TRUE, and discards rows for which the predicate evaluates to FALSE or UNKNOWN.
This query generates the following output:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Suppose that you need to return orders that were not shipped on January 2nd, 2019. As far as you are concerned, orders that were not shipped yet are supposed to be included in the output. You use a query similar to the last, only negating the predicate, like so:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE NOT (shippeddate = '20190102');This query returns the following output:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
The output naturally excludes the rows with the shipped date January 2nd, 2019, but also excludes the rows with a NULL shipped date. What could be counter intuitive here is what happens when you use the NOT operator to negate a predicate that evaluates to UNKNOWN. Obviously, NOT TRUE is FALSE and NOT FALSE is TRUE. However, NOT UNKNOWN remains UNKNOWN. SQL’s logic behind this design is that if you don’t know whether a proposition is true, you also don’t know whether the proposition isn’t true. This means that when using equality and inequality operators in the filter predicate, neither the positive nor the negative forms of the predicate return the rows with the NULLs.
This example is pretty simple. There are trickier cases involving subqueries. There’s a common bug when you use the NOT IN predicate with a subquery, when the subquery returns a NULL among the returned values. The query always returns an empty result. The reason is that the positive form of the predicate (the IN part) returns a TRUE when the outer value is found, and UNKNOWN when it’s not found due to the comparison with the NULL. Then the negation of the predicate with the NOT operator always returns FALSE or UNKNOWN, respectively—never a TRUE. I cover this bug in detail in T-SQL bugs, pitfalls, and best practices – subqueries, including suggested solutions, optimization considerations and best practices. If you’re not already familiar with this classic bug, make sure you check this article since the bug is quite common, and there are simple measures that you can take to avoid it.
Back to our need, what about attempting to return orders with a shipped date that is different than January 2nd, 2019, using the different than (<>) operator:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate <> '20190102';Unfortunately, both equality and inequality operators yield UNKNOWN when any of the operands is NULL, so this query generates the following output like the previous query, excluding the NULLs:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
To isolate the issue of comparisons with NULLs yielding UNKNOWN using equality, inequality and negation of the two kinds of operators, all of the following queries return an empty result set:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate = NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE NOT (shippeddate = NULL);
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate <> NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE NOT (shippeddate <> NULL);According to SQL, you’re not supposed to check if something is equal to a NULL or different than a NULL, rather if something is a NULL or is not a NULL, using the special operators IS NULL and IS NOT NULL, respectively. These operators use two-valued logic, always returning either TRUE or FALSE. For example, use the IS NULL operator to return unshipped orders, like so:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate IS NULL;This query generates the following output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Use the IS NOT NULL operator to return shipped orders, like so:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate IS NOT NULL;This query generates the following output:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Use the following code to return orders that were shipped on a date that is different than January 2nd, 2019, as well as unshipped orders:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate <> '20190102'
OR shippeddate IS NULL;This query generates the following output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
In a later part in the series I cover standard features for NULL treatment that are currently missing in T-SQL, including the DISTINCT predicate, that have the potential to simplify NULL handling a great deal.
Comparisons with variables, parameters and columns
The previous section focused on predicates that compare a column with a constant. In reality, though, you will mostly compare a column with variables/parameters or with other columns. Such comparisons involve further complexities.
From a NULL-handling standpoint, variables and parameters are treated the same. I’ll use variables in my examples, but the points I make about their handling are just as relevant to parameters.
Consider the following basic query (I’ll call it Query 1), which filters orders that were shipped on a given date:
DECLARE @dt AS DATE = '20190212';
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate = @dt;I use a variable in this example and initialize it with some sample date, but this just as well could have been a parameterized query in a stored procedure or a user-defined function.
This query execution generates the following output:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
The plan for Query 1 is shown in Figure 1.
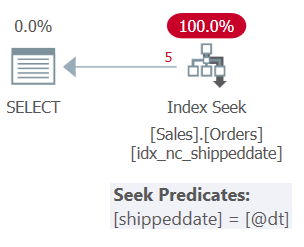 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
The table has a covering index to support this query. The index is called idx_nc_shippeddate, and it’s defined with the key-list (shippeddate, orderid). The query’s filter predicate is expressed as a search argument (SARG), meaning that it enables the optimizer to consider applying a seek operation in the supporting index, going straight to the range of qualifying rows. What makes the filter predicate SARGable is that it uses an operator that represents a consecutive range of qualifying rows in the index, and that it doesn’t apply manipulation to the filtered column. The plan that you get is the optimal plan for this query.
But what if you want to allow users to ask for unshipped orders? Such orders have a NULL shipped date. Here’s an attempt to pass a NULL as the input date:
DECLARE @dt AS DATE = NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate = @dt;As you already know, a predicate using an equality operator produces UNKNOWN when any of the operands is a NULL. Consequently, this query returns an empty result:
orderid shippeddate ----------- ----------- (0 rows affected)
Even though T-SQL does support an IS NULL operator, it does not support an explicit IS <expression> operator. So you cannot use a filter predicate such as WHERE shippeddate IS @dt. Again, I’ll talk about the unsupported standard alternative in a future article. What many people do to solve this need in T-SQL is to use the ISNULL or COALESCE functions to replace a NULL with a value that cannot normally appear in the data in both sides, like so (I’ll call this Query 2):
DECLARE @dt AS DATE = NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');This query does generate the correct output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
But the plan for this query, as shown in Figure 2, is not optimal.
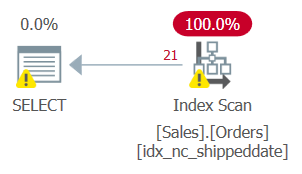 Figure 2: Plan for Query 2
Figure 2: Plan for Query 2
Since you applied manipulation to the filtered column, the filter predicate is not considered a SARG anymore. The index is still covering, so it can be used; but instead of applying a seek in the index going straight to the range of qualifying rows, the entire index leaf is scanned. Suppose that the table had 50,000,000 orders, with only 1,000 being unshipped orders. This plan would scan all 50,000,000 rows instead of doing a seek that goes straight to the qualifying 1,000 rows.
One form of a filter predicate that both has the correct meaning that we are after and is considered a search argument is (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL)). Here’s a query using this SARGable predicate (we’ll call it Query 3):
DECLARE @dt AS DATE = NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));The plan for this query is shown in Figure 3.
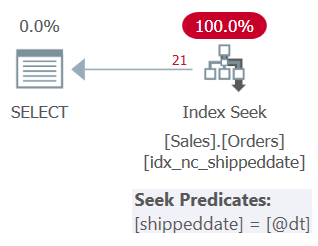 Figure 3: Plan for Query 3
Figure 3: Plan for Query 3
As you can see, the plan applies a seek in the supporting index. The seek predicate says shippeddate = @dt, but it’s internally designed to handle NULLs just like non-NULL values for the sake of the comparison.
This solution is generally considered a reasonable one. It is standard, optimal and correct. Its main drawback is that it’s verbose. What if you had multiple filter predicates based on NULLable columns? You would quickly end up with a lengthy and cumbersome WHERE clause. And it gets much worse when you need to write a filter predicate involving a NULLable column looking for rows where the column is different than the input parameter. The predicate then becomes: (shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate IS NOT NULL and @dt IS NULL))).
You can clearly see the need for a more elegant solution that is both concise and optimal. Unfortunately, some resort to a nonstandard solution where you turn off the ANSI_NULLS session option. This option causes SQL Server to use nonstandard handling of the equality (=) and different than (<>) operators with two-valued logic instead of three-valued logic, treating NULLs just like non-NULL values for comparison purposes. That’s at least the case as long as one of the operands is a parameter/variable or a literal.
Run the following code to turn the ANSI_NULLS option off in the session:
SET ANSI_NULLS OFF;Run the following query using a simple equality-based predicate:
DECLARE @dt AS DATE = NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate = @dt;This query returns the 21 unshipped orders. You get the same plan shown earlier in Figure 3, showing a seek in the index.
Run the following code to switch back to standard behavior where ANSI_NULLS is on:
SET ANSI_NULLS ON;Relying on such nonstandard behavior is strongly discouraged. The documentation also states that support for this option will be removed in some future version of SQL Server. Moreover, many don’t realize that this option is only applicable when at least one of the operands is a parameter/variable or a constant, even though the documentation is quite clear about it. It does not apply when comparing two columns such as in a join.
So how do you handle joins involving NULLable join columns if you want to get a match when the two sides are NULLs? As an example, use the following code to create and populate the tables T1 and T2:
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
GO
CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL,
val1 VARCHAR(10) NOT NULL,
CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3));
CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL,
val2 VARCHAR(10) NOT NULL,
CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3));
INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES
(1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F');
INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES
(0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');The code creates covering indexes on both tables to support a join based on the join keys (k1, k2, k3) in both sides.
Use the following code to update the cardinality statistics, inflating the numbers so that the optimizer would think that you’re dealing with larger tables:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000;
UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;Use the following code in an attempt to join the two tables using simple equality-based predicates:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3;Just like with earlier filtering examples, also here comparisons between NULLs using an equality operator yield UNKNOWN, resulting in nonmatches. This query generates an empty output:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
Using ISNULL or COALESCE like in an earlier filtering example, replacing a NULL with a value that can’t normally appear in the data in both sides, does result in a correct query (I’ll refer to this query as Query 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648);This query generates the following output:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
However, just like manipulating a filtered column breaks the filter predicate’s SARGability, manipulation of a join column prevents the ability to rely on index order. This can be seen in the plan for this query as shown in Figure 4.
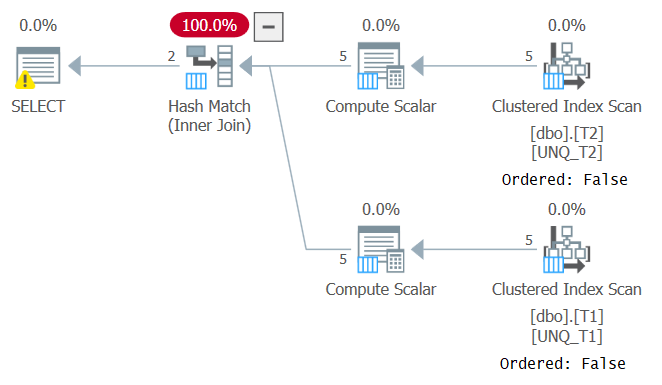 Figure 4: Plan for Query 4
Figure 4: Plan for Query 4
An optimal plan for this query is one that applies ordered scans of the two covering indexes followed by a Merge Join algorithm, with no explicit sorting. The optimizer chose a different plan since it couldn’t rely on index order. If you attempt to force a Merge Join algorithm using INNER MERGE JOIN, the plan would still rely on unordered scans of the indexes, followed by explicit sorting. Try it!
Of course you can use the lengthy predicates similar to the SARGable predicates shown earlier for filtering tasks:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL));This query does produce the desired result and enables the optimizer to rely on index order. However, our hope is to find a solution that is both optimal and concise.
There’s a little-known elegant and concise technique that you can use in both joins and filters, both for the purpose of identifying matches and for identifying nonmatches. This technique was discovered and documented already years ago, such as in Paul White’s excellent writeup Undocumented Query Plans: Equality Comparisons from 2011. But for some reason it seems like still many people are unaware of it, and unfortunately end up using suboptimal, lengthy and nonstandard solutions. It certainly deserves more exposure and love.
The technique relies on the fact that set operators like INTERSECT and EXCEPT use a distinctness-based comparison approach when comparing values, and not an equality- or inequality-based comparison approach.
Consider our join task as an example. If we didn't need to return columns other than the join keys, we would have used a simple query (I’ll refer to it as Query 5) with an INTERSECT operator, like so:
SELECT k1, k2, k3 FROM dbo.T1
INTERSECT
SELECT k1, k2, k3 FROM dbo.T2;This query generates the following output:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
The plan for this query is shown in Figure 5, confirming that the optimizer was able to rely on index order and use a Merge Join algorithm.
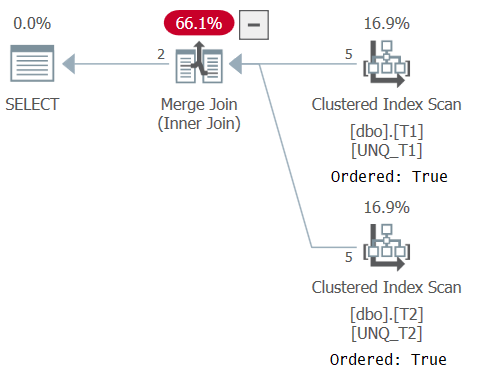 Figure 5: Plan for Query 5
Figure 5: Plan for Query 5
As Paul notes in his article, the XML plan for the set operator uses an implicit IS comparison operator (CompareOp="IS") as opposed to the EQ comparison operator used in a normal join (CompareOp="EQ"). The problem with a solution that relies solely on a set operator is that it limits you to returning only the columns that you’re comparing. What we really need is sort of a hybrid between a join and a set operator, allowing you to compare a subset of the elements while returning additional ones like a join does, and using distinctness-based comparison (IS) like a set operator does. This is achievable by using a join as the outer construct, and an EXISTS predicate in the join’s ON clause based on a query with an INTERSECT operator comparing the join keys from the two sides, like so (I’ll refer to this solution as Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);The INTERSECT operator operates on two queries, each forming a set of one row based on the join keys from either side. When the two rows are the same, the INTERSECT query returns one row; the EXISTS predicate returns TRUE, resulting in a match. When the two rows are not the same, the INTERSECT query returns an empty set; the EXISTS predicate returns FALSE, resulting in a nonmatch.
This solution generates the desired output:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
The plan for this query is shown in Figure 6, confirming that the optimizer was able to rely on index order.
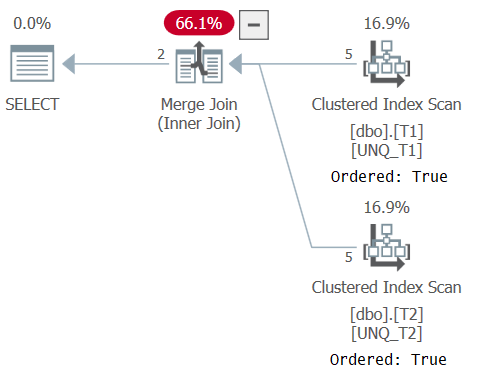 Figure 6: Plan for Query 6
Figure 6: Plan for Query 6
You can use a similar construction as a filter predicate involving a column and a parameter/variable to look for matches based on distinctness, like so:
DECLARE @dt AS DATE = NULL;
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);The plan is the same as the one shown earlier in Figure 3.
You can also negate the predicate to look for nonmatches, like so:
DECLARE @dt AS DATE = '20190212';
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);This query generates the following output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
Alternatively, you can use a positive predicate, but replace INTERSECT with EXCEPT, like so:
DECLARE @dt AS DATE = '20190212';
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);Note that the plans in the two cases could be different, so make sure to experiment both ways with large amounts of data.
Conclusion
NULLs add their share of complexity to your SQL code writing. You always want to think about the potential for the presence of NULLs in the data, and make sure that you use the right query constructs, and add the relevant logic to your solutions to handle NULLs correctly. Ignoring them is a sure way to end up with bugs in your code. This month I focused on what NULLs are and how they are handled in comparisons involving constants, variables, parameters and columns. Next month I’ll continue the coverage by discussing NULL treatment inconsistencies in different language elements, and missing standard features for NULL handling.
8 thoughts on “NULL complexities – Part 1”
Comments are closed.

Great post. I wish the SQL designers had either implemented NULL completely or not at all. We're left with something that makes theoretical sense but has been an ongoing nuisance from a practical standpoint. While the suggestion to use INTERSECT is very clever, I doubt this is the kind of "structured query" that anyone had in mind.
Curious to see Part 2 even if it's only a "what could have been" of missing standard features.
T-SQL and SQL Server is lacking A LOT of useful features, Itzik tirelessly show them, and Microsoft is best known for ignoring them for years.
I would love if sql server would adopt the standard IS (NOT) DISTINCT FROM (https://wiki.postgresql.org/wiki/Is_distinct_from)
However, in a pinch I've used there where exists (select intersect select)
Personally I've always thought IS [NOT] DISTINCT FROM is typical ANSI-SQL verbose daftness.
A much better syntax would be just IS [NOT], so: t1.A IS [NOT] t2.A, which is the reverse of the other syntax, and much more readable.
Would it conflict with another syntax? I really can't see how.
An interesting point not made entirely clear in this article, but more clearly documented in Paul White's article, is the optimizer *completely* elides the whole EXISTS/INTERSECT, which would normally be fed through as a very inefficient cross join followed with a correlated apply, and just does a straight join comparison instead.
I have found in testing that the optimizer can't do it anyway sometimes, especially in complex joins, and I also can't get it to work properly with an iTVF that does the same trick (like CROSS APPLY EqNull (a, b)). So it's worth checking the plan with these queries.
Nice post, seriously ;) I am dealing with this kind of stuff on my daily basis and I have other strange null scenarios ;)
Imagine table of objects that have parent and grandparent defined in the same table. Structure like:
|
|__grandparent
|___parent
|___object
|___object
|___parent
|___object
|__grandparent
|___parent
|___object
|___object
|___object
if object_id('tempdb.dbo.#base_objects') is not null drop table #base_objects
create table #base_objects ( id_grandparent int not null — NOT NULL
, id_parent int not null — NOT NULL
, id int not null primary key — NOT NULL
)
And you have the other table where you can define what object from that first table are you going to deal with in the rest of script:
if object_id('tempdb.dbo.#group_definitions') is not null drop table #group_definitions
create table #group_definitions (id_unnecessary_group int primary key not null identity(1,1)
, id_grandparent int null — caution! nullable
, id_parent int null — caution! nullable
, id int null — caution! nullable
)
When in #group_definitions there is only id_parent defined then you are taking all objects from #base_objects with that id_parent. Easy peasy ;)
Let's populate these tables with some data:
insert #base_objects (id_grandparent, id_parent, id)
select 999,99,9
union all
select 999,99,8
union all
select 999,88,7
union all
select 999,88,6
union all
select 777,66,2
union all
select 777,55,1
insert #group_definitions (id_grandparent, id_parent, id)
select null, 88,null
union all
select null, null, 2
And querying tables:
select OB.*
from #base_objects as OB
cross join #group_definitions as DEF
where (
DEF.id_grandparent is null
or (DEF.id_grandparent = OB.id_grandparent)
)
and (
DEF.id_parent is null
or (DEF.id_parent = OB.id_parent)
)
and (
DEF.id is null
or (DEF.id = OB.id)
)
order by OB.id
Is there a way to change this "awesome" query to sth more intersectish or extinctish? ;) Any thoughts?
Nice article Itzik. Thank you.
I learn something new whenever I read your or Paul White's posts.
Thank you Itzik