
Analyzing "death by a thousand cuts" workloads
There are multiple methods to look at poorly performing queries in SQL Server, notably Query Store, Extended Events, and dynamic management views (DMVs). Each option has pros and cons. Extended Events provides data about the individual execution of queries, while Query Store and the DMVs aggregate performance data. In order to use Query Store and Extended Events, you have to configure them in advance – either enabling Query Store for your database(s), or setting up an XE session and starting it. DMV data is always available, so very often it’s the easiest method to get a quick first look at query performance. This is where Glenn’s DMV queries come in handy – within his script he has multiple queries that you can use to find the top queries for the instance based on CPU, logical I/O, and duration. Targeting the highest resource-consuming queries is often a good start when troubleshooting, but we can’t forget about the “death by a thousand cuts” scenario – the query or set of queries that run VERY frequently – maybe hundreds or thousands of times a minute. Glenn has a query in his set that lists top queries for a database based on execution count, but in my experience it doesn’t give you a complete picture of your workload.
The main DMV that is used to look at query performance metrics is sys.dm_exec_query_stats. Additional data specific to stored procedures (sys.dm_exec_procedure_stats), functions (sys.dm_exec_function_stats), and triggers (sys.dm_exec_trigger_stats) is available as well, but consider a workload that isn’t purely stored procedures, functions, and triggers. Consider a mixed workload that has some ad hoc queries, or maybe is entirely ad hoc.
Example Scenario
Borrowing and adapting code from a previous post, Examining the Performance Impact of an Adhoc Workload, we will first create two stored procedures. The first, dbo.RandomSelects, generates and executes an ad hoc statement, and the second, dbo.SPRandomSelects, generates and executes a parameterized query.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GONow we’ll execute both stored procedures 1000 times, using the same method outlined in my previous post with .cmd files calling .sql files with the following statements:
Adhoc.sql file contents:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;Parameterized.sql file contents:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;Example syntax in .cmd file that calls the .sql file:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql"
exitIf we use a variation of Glenn’s Top Worker Time query to look at the top queries based on worker time (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries)
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name],
REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text],
qs.total_worker_time AS [Total Worker Time],
qs.execution_count AS [Execution Count],
qs.total_worker_time/qs.execution_count AS [Avg Worker Time],
qs.creation_time AS [Creation Time]
FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);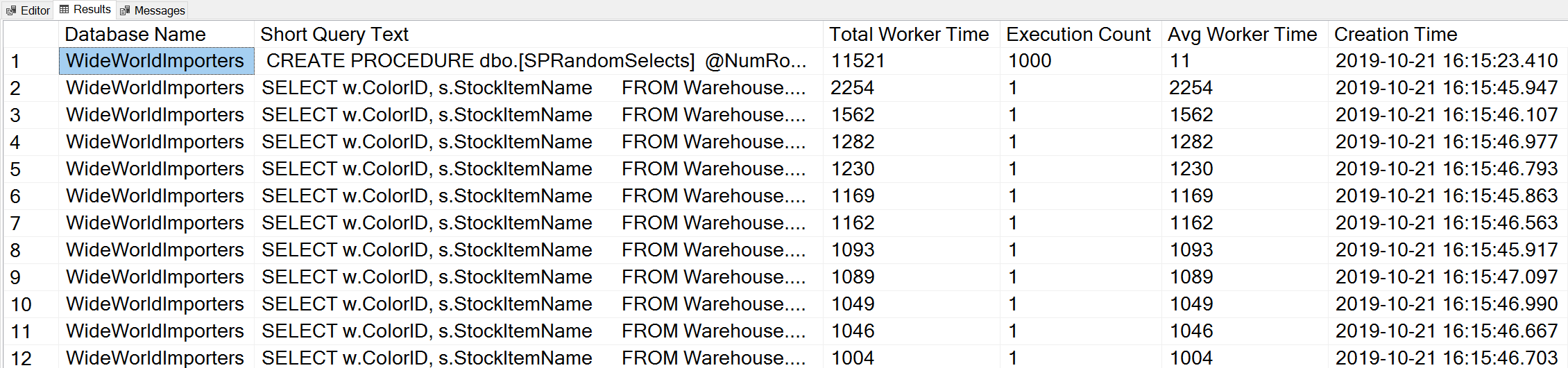
We see the statement from our stored procedure as the query that executes with the highest amount of cumulative CPU.
If we run a variation of Glenn’s Query Execution Counts query against the WideWorldImporters database:
USE [WideWorldImporters];
GO
-- Get most frequently executed queries for this database (Query 57) (Query Execution Counts)
SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count],
qs.total_logical_reads AS [Total Logical Reads],
qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads],
qs.total_worker_time AS [Total Worker Time],
qs.total_worker_time/qs.execution_count AS [Avg Worker Time],
qs.total_elapsed_time AS [Total Elapsed Time],
qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time]
FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
WHERE t.dbid = DB_ID()
ORDER BY qs.execution_count DESC OPTION (RECOMPILE);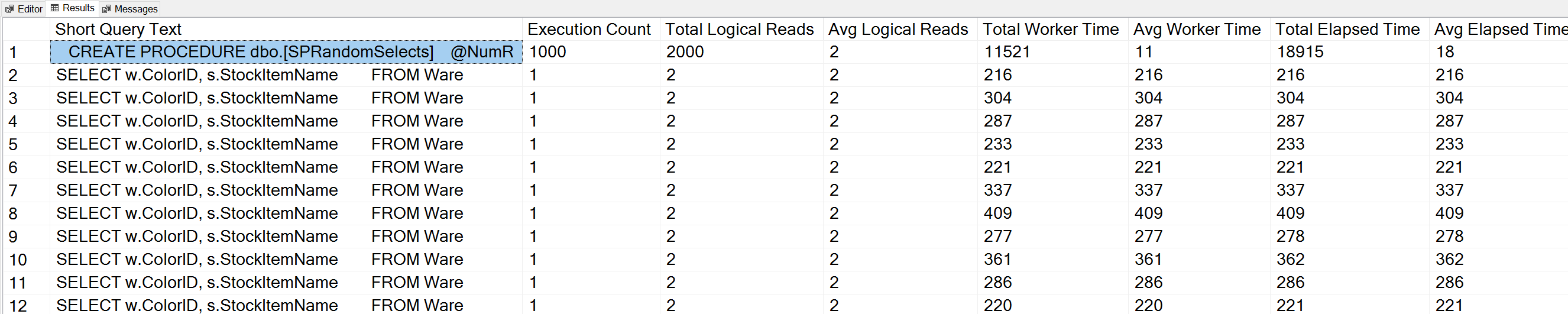
We also see our stored procedure statement at the top of the list.
But the ad hoc query that we executed, even though it has different literal values, was essentially the same statement executed repeatedly, as we can see by looking at the query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name],
REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text],
qs.query_hash AS [query_hash],
qs.creation_time AS [Creation Time]
FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
ORDER BY [Short Query Text];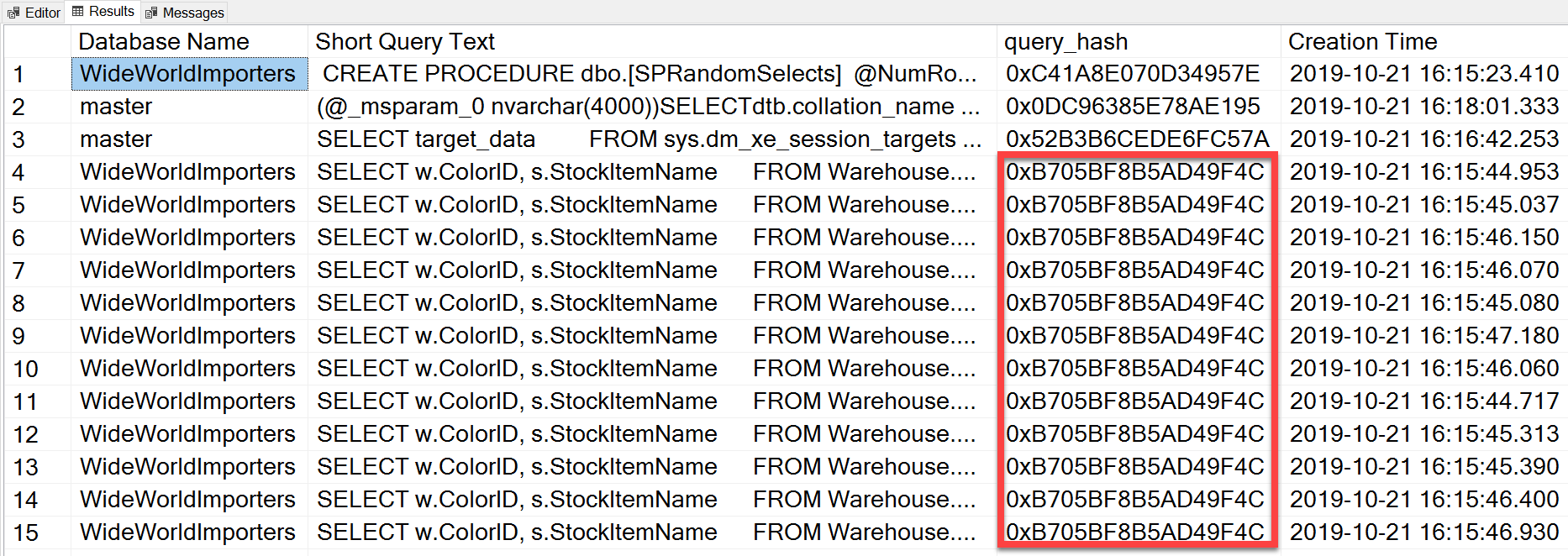
The query_hash was added in SQL Server 2008, and is based on the tree of the logical operators generated by the Query Optimizer for the statement text. Queries that have a similar statement text which generate the same tree of logical operators will have the same query_hash, even if the literal values in the query predicate are different. While the literal values can be different, the objects and their aliases must be the same, as well as query hints and potentially the SET options. The RandomSelects stored procedure generates queries with different literal values:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897';But every execution has the exact same value for the query_hash, 0xB705BF8B5AD49F4C. In order to understand how frequently an ad hoc query – and those that are the same in terms of query_hash – executes, we have to group by the query_hash order on that count, rather than looking at execution_count in sys.dm_exec_query_stats (which often shows a value of 1).
If we change context to the WideWorldImporters database and look for top queries based on execution count, where we group on query_hash, we can now see both the stored procedure and our ad hoc query:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;
Note: The sys.dm_exec_function_stats DMV was added in SQL Server 2016. Running this query on SQL Server 2014 and earlier requires removing reference to this DMV.
This output provides a much more comprehensive understanding of what queries truly execute most frequently, as it aggregates based on the query_hash, not by simply looking at the execution_count in sys.dm_exec_query_stats, which can have multiple entries for the same query_hash when different literal values are used. The query output also includes query_plan_hash, which can be different for queries with the same query_hash. This additional information is useful when evaluating plan performance for a query. In the example above, every query has the same query_plan_hash, 0x299275DD475C4B17, demonstrating that even with different input values, the Query Optimizer generates the same plan – it’s stable. When multiple query_plan_hash values exist for the same query_hash, plan variability exists. In a scenario where the same query, based on query_hash, executes thousands of times, a general recommendation is to parameterize the query. If you can verify that no plan variability exists, then parameterizing the query removes the optimization and compilation time for each execution, and can reduce overall CPU. In some scenarios, parameterizing five to 10 ad hoc queries can improve system performance as a whole.
Summary
For any environment, it’s important to understand what queries are most expensive in terms of resource use, and what queries run most frequently. The same set of queries can show up for both types of analysis when using Glenn’s DMV script, which can be misleading. As such, it’s important to establish whether the workload is mostly procedural, mostly ad hoc, or a mix. While there is much documented about the benefits of stored procedures, I find that mixed or highly ad hoc workloads are very common, particularly with solutions that use object-relational mappers (ORMs) such as Entity Framework, NHibernate, and LINQ to SQL. If you’re unclear about the type of workload for a server, running the above query to look at the most-executed queries based on a query_hash is a good start. As you begin to understand the workload and what exists for both the heavy hitters and the death by a thousand cuts queries, you can move on to truly understanding resource use and the impact these queries have on system performance, and target your efforts for tuning.
1 thought on “Analyzing "death by a thousand cuts" workloads”
Comments are closed.

Good, Average and sometime Best can be used for articles by some authors.
But Your articles are always THE BEST.