
Closest Match, Part 3
In Closest Match, Part 1, I covered a T-SQL challenge that was provided to me by Karen Ly, a Jr. Fixed Income Analyst at RBC. The challenge involved two tables — T1 and T2, each with a key column (keycol), a value (val), and some other columns (represented with a column called othercols). The task was to match to each row from T1 the row from T2 where T2.val is closest to T1.val (the absolute difference is the lowest lowest), using the lowest T2.keycol value as a tiebreaker. I provided a couple of relational solutions, and discussed their performance characteristics. I also challenged you to try and find a reasonably performing solution in cases where you are not allowed/able to create supporting indexes. In Part 2, I demonstrated how this can be achieved by using iterative solutions. I got several very interesting reader solutions from Kamil Konsno, Alejandro Mesa and Radek Celuch, and those solutions are the focus of this month’s article.
Sample Data
As a reminder, I provided both small and large sets of sample data for you to work with. Small sets to check the validity of your solution and large sets to check its performance. Use the following code to create the sample database testdb and within it the sample tables T1 and T2:
-- Sample db
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
GO
-- Sample tables T1 and T2
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
);Use the following code to populate the tables with small sets of sample data:
-- Populate T1 and T2 with small sets of sample data
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19);I’ll use the small sets of sample data when describing the logic of the different solutions and provide intermediate result sets for the steps of the solutions.
Use the following code to create the helper function GetNums and to populate the tables with large sets of sample data:
-- Helper function to generate a sequence of integers
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- Populate T1 and T2 with large sets of sample data
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums;When you want to test your solution with supporting indexes, use the following code to create those indexes:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols);
CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols);
CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);When you want to test your solution without supporting indexes, use the following code to remove those indexes:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;Solution 1 by Kamil Kosno – Using a temporary table
Kamil Kosno submitted a few — two with his original ideas, and two variations on Alejandro’s and Radek’s solutions. Kamil’s first solution uses an indexed temporary table. Often it is the case that even if you’re not allowed to create supporting indexes on the original tables, you are allowed to work with temporary tables, and with temporary tables you can always create your own indexes.
Here’s the complete solution’s code:
DROP TABLE IF EXISTS #T2;
SELECT MIN(keycol) AS keycol, val
INTO #T2
FROM dbo.T2
GROUP BY val;
CREATE UNIQUE INDEX idx_nc_val_key ON #T2(val, keycol);
WITH bestvals AS
(
SELECT
keycol AS keycol1,
val AS val1,
othercols AS othercols1,
CASE
WHEN (prev + nxt IS NULL) THEN COALESCE(prev, nxt)
WHEN ABS(val - prev) < ABS(val - nxt) THEN prev
WHEN ABS(val - nxt) < ABS(val - prev) THEN nxt
ELSE (CASE WHEN nxt < prev THEN nxt ELSE prev END)
END AS val2
FROM dbo.T1
CROSS APPLY ( SELECT MAX(val) AS prev
FROM #T2
WHERE val <= T1.val ) AS prev
CROSS APPLY ( SELECT MIN(val) AS nxt
FROM #T2
WHERE T1.val <= val ) AS nxt
)
SELECT
keycol1, val1,
SUBSTRING(othercols1, 1, 1) AS othercols1,
tempT2.keycol AS keycol2, val2,
SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM bestvals AS B
INNER JOIN #T2 AS tempT2
ON tempT2.val = B.val2
INNER JOIN dbo.T2
ON T2.keycol = tempT2.keycol
DROP TABLE #T2;In Step 1 of the solution you store the minimum keycol for each unique val in a temporary table called #T2, and create a supporting index on (val, keycol). Here’s the code implementing this step:
DROP TABLE IF EXISTS #T2;
SELECT MIN(keycol) AS keycol, val
INTO #T2
FROM dbo.T2
GROUP BY val;
CREATE UNIQUE INDEX idx_nc_val_key ON #T2(val, keycol);
SELECT * FROM #T2;The temporary table is populated with the following data:
keycol val ----------- ---------- 1 2 4 3 3 7 6 11 8 13 9 17 10 19
In Step 2 of the solution you apply the following:
For each row in T1 compute prev and nxt values from #T2. Compute prev as the maximum val in #T2 that is less than or equal to val in T1. Compute nxt as the minimum val in #T2 that is greater than or equal to val in T1.
Use a CASE expression to compute val2 based on the following logic:
- When prev or nxt is null, return the first nonnull of the two, or NULL if both are NULL.
- When the absolute difference between val and prev is less than the absolute difference between val and nxt, return prev.
- When if the absolute difference between val and nxt is less than the absolute difference between val and prv, return nxt.
- Else, if nxt is less than prev, return nxt, otherwise return prev.
Here’s the code implementing this step:
SELECT
keycol AS keycol1,
val AS val1,
othercols AS othercols1,
CASE
WHEN (prev + nxt IS NULL) THEN COALESCE(prev, nxt)
WHEN ABS(val - prev) < ABS(val - nxt) THEN prev
WHEN ABS(val - nxt) < ABS(val - prev) THEN nxt
ELSE (CASE WHEN nxt < prev THEN nxt ELSE prev END)
END AS val2
FROM dbo.T1
CROSS APPLY ( SELECT MAX(val) AS prev
FROM #T2
WHERE val <= T1.val ) AS prev
CROSS APPLY ( SELECT MIN(val) AS nxt
FROM #T2
WHERE T1.val <= val ) AS nxt;This code generates the following output:
keycol1 val1 othercols1 val2 -------- ----- ----------- ----- 1 1 0xAA 2 2 1 0xAA 2 3 3 0xAA 3 4 3 0xAA 3 5 5 0xAA 3 6 8 0xAA 7 7 13 0xAA 13 8 16 0xAA 17 9 18 0xAA 17 10 20 0xAA 19 11 21 0xAA 19
In Step 3 of the solution, you define a CTE called bestvals based on the query from Step2. You then join bestvals with #T2 to get the keys, and join the result with T2 to get the rest of the data (othercols).
Here’s the code implementing this step:
SELECT
keycol1, val1,
SUBSTRING(othercols1, 1, 1) AS othercols1,
tempT2.keycol AS keycol2, val2,
SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM bestvals AS B
INNER JOIN #T2 AS tempT2
ON tempT2.val = B.val2
INNER JOIN dbo.T2
ON T2.keycol = tempT2.keycol;The plan for solution 1 by Kamil with supporting indexes is shown in Figure 1.
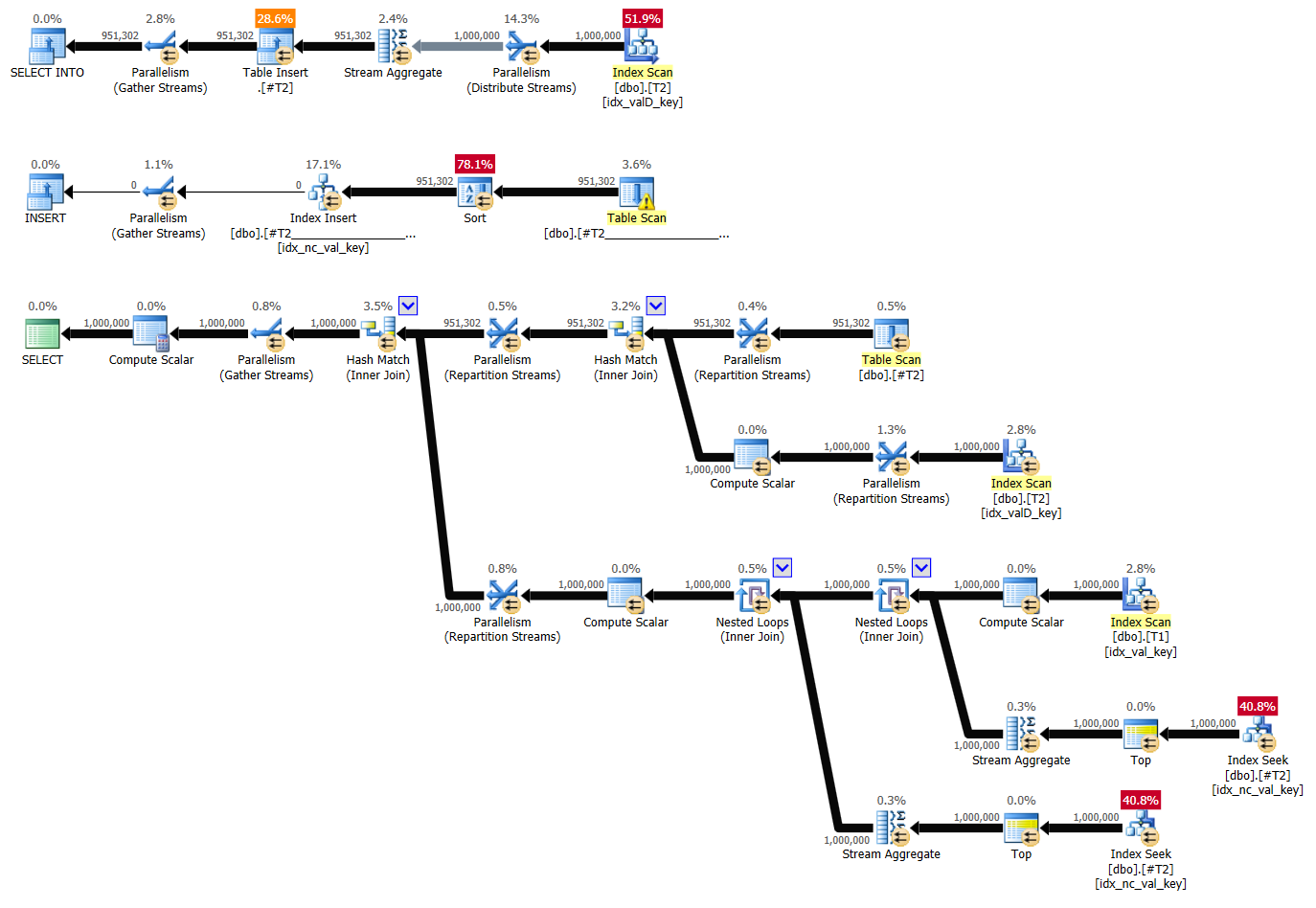 Figure 1: Plan for solution 1 by Kamil with indexes
Figure 1: Plan for solution 1 by Kamil with indexes
The first branch of the plan groups and aggregates the data from T2 and writes the result to the temporary table #T2. Notice that this branch uses a preordered Stream Aggregate algorithm that relies on an ordered scan of the index idx_valD_key on T2.
Here are the performance stats for this plan:
run time (sec): 5.55, CPU (sec): 16.6, logical reads: 6,687,172
The plan for solution 1 by Kamil without supporting indexes is shown in Figure 2.
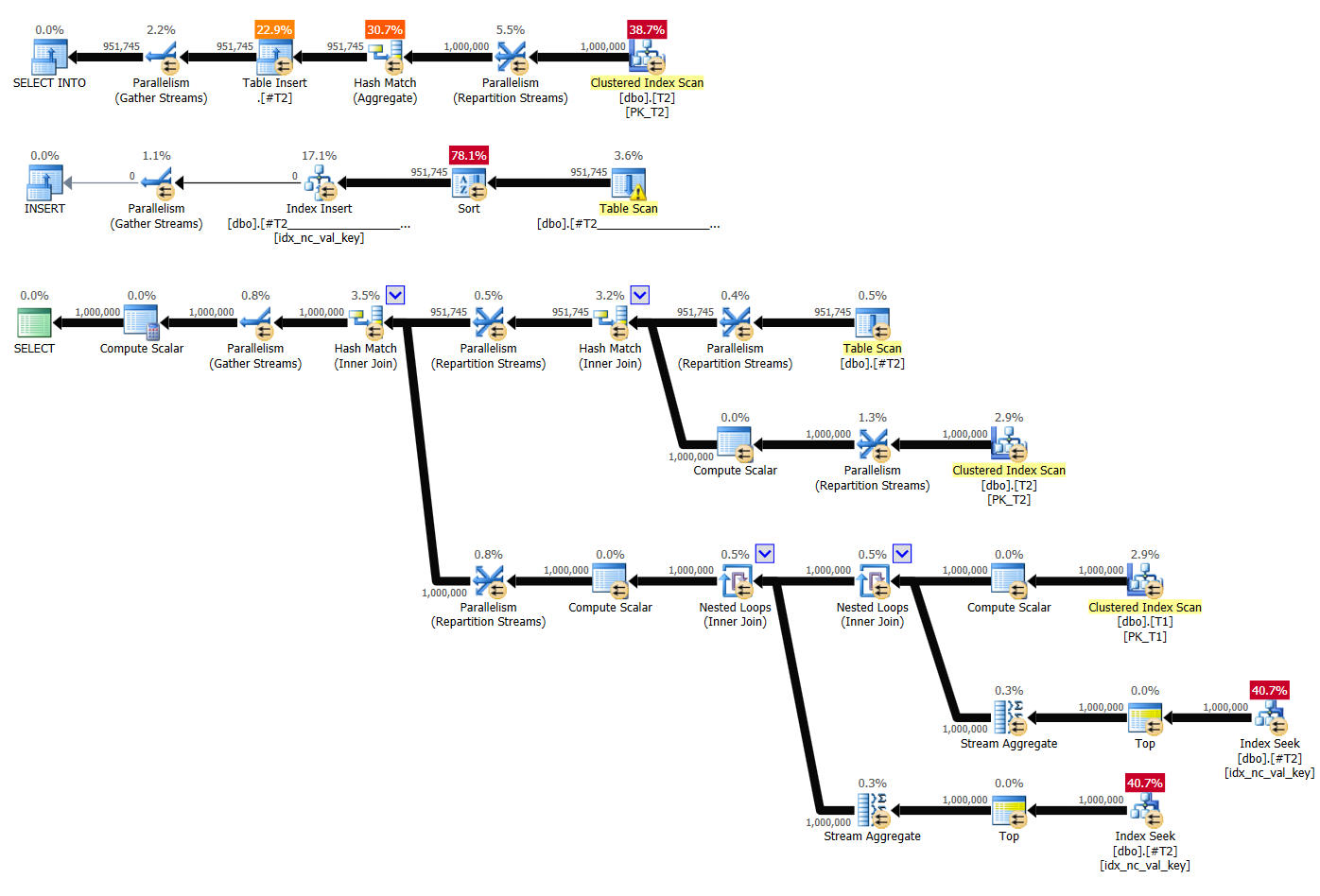 Figure 2: Plan for solution 1 by Kamil without indexes
Figure 2: Plan for solution 1 by Kamil without indexes
The main difference between this plan and the previous one is that the first branch of the plan, which handles the grouping and aggregation part in Step 1, this time cannot pull the data preordered from a supporting index, so it pulls it unordered from the clustered index on T2 and then uses a Hash Aggregate algorithm.
Here are the performance stats for this plan:
run time: 6.44, CPU: 19.3, logical reads: 6,688,277
Solution by Alejandro Mesa – Using last nonnull technique
Alejandro’s solution uses the last nonnull technique described here.
Here’s the complete solution’s code (provided here without returning othercols):
WITH R1 AS
(
SELECT keycol, val, tid,
MAX( CASE WHEN tid = 0 THEN CAST(val AS binary(4)) + CAST(keycol AS binary(4)) END )
OVER( ORDER BY val, tid, keycol
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING ) AS below_binstr,
MIN( CASE WHEN tid = 0 THEN CAST(val AS binary(4)) + CAST(keycol AS binary(4)) END )
OVER( ORDER BY val, tid, keycol
ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING ) AS above_binstr
FROM ( SELECT keycol, val, 1 AS tid
FROM dbo.T1
UNION ALL
SELECT MIN(keycol) AS keycol, val, 0 AS tid
FROM dbo.T2
GROUP BY val ) AS T
),
R2 AS
(
SELECT keycol, val,
CAST(SUBSTRING(below_binstr, 1, 4) AS int) AS below_T2_val,
CAST(SUBSTRING(below_binstr, 5, 4) AS int) AS below_T2_keycol,
CAST(SUBSTRING(above_binstr, 1, 4) AS int) AS above_T2_val,
CAST(SUBSTRING(above_binstr, 5, 4) AS int) AS above_T2_keycol
FROM R1
WHERE tid = 1
),
R3 AS
(
SELECT keycol, val,
COALESCE(below_T2_val, above_T2_val) AS below_T2_val,
COALESCE(below_T2_keycol, above_T2_keycol) AS below_T2_keycol,
COALESCE(above_T2_val, below_T2_val) AS above_T2_val,
COALESCE(above_T2_keycol, below_T2_keycol) AS above_T2_keycol
FROM R2
)
SELECT keycol AS keycol1, val AS val1,
CASE
WHEN ABS(val - below_T2_val) <= ABS(above_T2_val - val) THEN below_T2_keycol
ELSE above_T2_keycol
END AS keycol2,
CASE
WHEN ABS(val - below_T2_val) <= ABS(above_T2_val - val) THEN below_T2_val
ELSE above_T2_val
END AS val2
FROM R3;In Step 1 of the solution, you unify the rows from T1 (assigning a result column called tid to 1) with the rows from T2 (assigning tid = 0), and define a derived table called T based on the result. Using the last nonnull technique, based on the order of val, tid, keycol, for each current row, you retrieve the last tid = 0 row's values concatenated into a binary column called below_binstr. Similarly, you retrieve the next tid = 0 row's values concatenated into a binary column called above_binstr.
Here’s the code implementing this step:
SELECT keycol, val, tid,
MAX( CASE WHEN tid = 0 THEN CAST(val AS binary(4)) + CAST(keycol AS binary(4)) END )
OVER( ORDER BY val, tid, keycol
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING ) AS below_binstr,
MIN( CASE WHEN tid = 0 THEN CAST(val AS binary(4)) + CAST(keycol AS binary(4)) END )
OVER( ORDER BY val, tid, keycol
ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING ) AS above_binstr
FROM ( SELECT keycol, val, 1 AS tid
FROM dbo.T1
UNION ALL
SELECT MIN(keycol) AS keycol, val, 0 AS tid
FROM dbo.T2
GROUP BY val ) AS T;This code generates the following output:
keycol val tid below_binstr above_binstr ----------- ----------- ----------- ------------------ ------------------ 1 1 1 NULL 0x0000000200000001 2 1 1 NULL 0x0000000200000001 1 2 0 NULL 0x0000000300000004 4 3 0 0x0000000200000001 0x0000000700000003 3 3 1 0x0000000300000004 0x0000000700000003 4 3 1 0x0000000300000004 0x0000000700000003 5 5 1 0x0000000300000004 0x0000000700000003 3 7 0 0x0000000300000004 0x0000000B00000006 6 8 1 0x0000000700000003 0x0000000B00000006 6 11 0 0x0000000700000003 0x0000000D00000008 8 13 0 0x0000000B00000006 0x0000001100000009 7 13 1 0x0000000D00000008 0x0000001100000009 8 16 1 0x0000000D00000008 0x0000001100000009 9 17 0 0x0000000D00000008 0x000000130000000A 9 18 1 0x0000001100000009 0x000000130000000A 10 19 0 0x0000001100000009 NULL 10 20 1 0x000000130000000A NULL 11 21 1 0x000000130000000A NULL
In Step 2 of the solution you define a CTE called R1 based on the query from Step 1. You query R1, filter only rows where tid = 1, and extract the individual values from the concatenated binary strings.
Here’s the code implementing this step:
SELECT keycol, val,
CAST(SUBSTRING(below_binstr, 1, 4) AS int) AS below_T2_val,
CAST(SUBSTRING(below_binstr, 5, 4) AS int) AS below_T2_keycol,
CAST(SUBSTRING(above_binstr, 1, 4) AS int) AS above_T2_val,
CAST(SUBSTRING(above_binstr, 5, 4) AS int) AS above_T2_keycol
FROM R1
WHERE tid = 1;This code generates the following output:
keycol val below_T2_val below_T2_keycol above_T2_val above_T2_keycol ----------- ----------- ------------ --------------- ------------ --------------- 1 1 NULL NULL 2 1 2 1 NULL NULL 2 1 3 3 3 4 7 3 4 3 3 4 7 3 5 5 3 4 7 3 6 8 7 3 11 6 7 13 13 8 17 9 8 16 13 8 17 9 9 18 17 9 19 10 10 20 19 10 NULL NULL 11 21 19 10 NULL NULL
In Step 3 of the solution you define a CTE called R2 based on the query from Step 2. You then compute the following result columns:
- below_T2_val: the first nonnull between below_T2_val and above_T2_val
- below_T2_keycol: the first nonnull between below_T2_keycol and above_T2_keycol
- above_T2_val: the first nonnull between above_T2_val and below_T2_val
- above_T2_keycol: the first nonnull between above_T2_keycol and below_T2_keycol
Here’s the code implementing this step:
SELECT keycol, val,
COALESCE(below_T2_val, above_T2_val) AS below_T2_val,
COALESCE(below_T2_keycol, above_T2_keycol) AS below_T2_keycol,
COALESCE(above_T2_val, below_T2_val) AS above_T2_val,
COALESCE(above_T2_keycol, below_T2_keycol) AS above_T2_keycol
FROM R2;This code generates the following output:
keycol val below_T2_val below_T2_keycol above_T2_val above_T2_keycol ----------- ----------- ------------ --------------- ------------ --------------- 1 1 2 1 2 1 2 1 2 1 2 1 3 3 3 4 7 3 4 3 3 4 7 3 5 5 3 4 7 3 6 8 7 3 11 6 7 13 13 8 17 9 8 16 13 8 17 9 9 18 17 9 19 10 10 20 19 10 19 10 11 21 19 10 19 10
In Step 4 of the solution you define a CTE called R3 based on the query from Step 3. You return keycol aliased as T1_keycol and val aliased as T1_val. Compute the result column T2_keycol as: if the absolute difference between val and below_T2_val is less than or equal to the absolute difference between above_T2_val and val, return below_T2_keycol, otherwise above_T2_keycol. Compute the result column T2_val as: if the absolute difference between val and below_T2_val is less than or equal to the absolute difference between above_T2_val and val, return below_T2_val, otherwise above_T2_val.
Here’s the code implementing this step:
SELECT keycol AS keycol1, val AS val1,
CASE
WHEN ABS(val - below_T2_val) <= ABS(above_T2_val - val) THEN below_T2_keycol
ELSE above_T2_keycol
END AS keycol2,
CASE
WHEN ABS(val - below_T2_val) <= ABS(above_T2_val - val) THEN below_T2_val
ELSE above_T2_val
END AS val2
FROM R3;The plan for Alejandro’s solution with supporting indexes is shown in Figure 3.
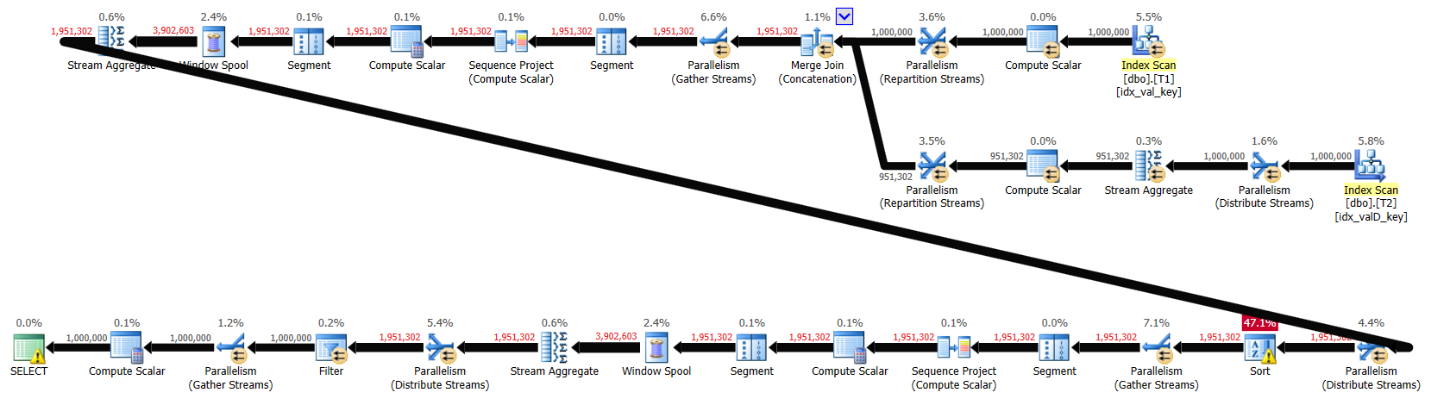 Figure 3: Plan for solution by Alejandro with indexes
Figure 3: Plan for solution by Alejandro with indexes
Here are the performance stats for this plan:
run time: 7.8, CPU: 12.6, logical reads: 35,886
The plan for Alejandro’s solution without supporting indexes is shown in Figure 4.
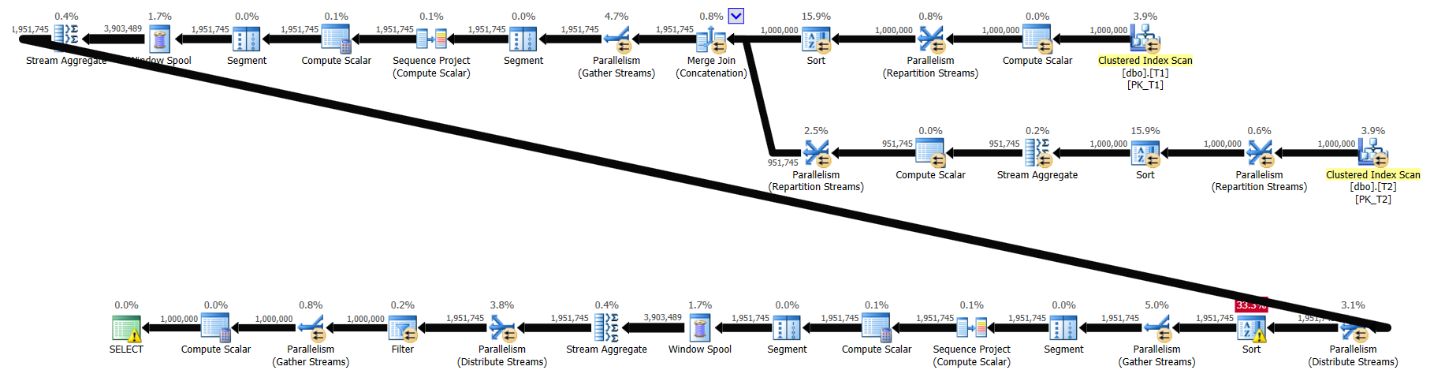 Figure 4: Plan for solution by Alejandro without indexes
Figure 4: Plan for solution by Alejandro without indexes
Here are the performance stats for this plan:
run time: 8.19, CPU: 14.8, logical reads: 37,091
Notice that in the first two branches of the plan in Figure 4 there are two sorts prior to the Merge Join (Concatenation) operator due to the lack of supporting indexes. Those sorts are not needed in the plan in Figure 3 since the data is retrieved preordered from the supporting indexes.
Kamil's variation on Alejandro's solution
In this solution, Kamil also relied on the last nonnull technique. Here’s the complete solution’s code:
WITH all_vals AS
(
SELECT keycol, val
FROM dbo.T1
UNION ALL
SELECT DISTINCT NULL, val
FROM dbo.T2
),
ranges AS
(
SELECT keycol, val,
MAX(CASE WHEN keycol IS NULL THEN val END) OVER (ORDER BY val, keycol ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS prev,
MIN(CASE WHEN keycol IS NULL THEN val END) OVER (ORDER BY val, keycol ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) AS nxt
FROM all_vals
),
matched_vals AS
(
SELECT keycol AS keycol1, val AS val1,
CASE
WHEN ABS(val - prev) <= ISNULL(ABS(val - nxt), prev) THEN prev
ELSE nxt
END AS val2
FROM ranges
WHERE keycol IS NOT NULL
)
SELECT
keycol1, val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
val2, T2.keycol AS keycol2, SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM matched_vals AS M
INNER JOIN ( SELECT *, ROW_NUMBER() OVER (PARTITION BY val ORDER BY keycol) AS rn
FROM dbo.T2 ) AS T2
ON T2.val = M.val2 AND rn = 1
INNER JOIN dbo.T1
ON T1.keycol = keycol1;In Step 1 of the solution you define CTEs called all_vals and ranges, where you use the last nonnull technique to identify for each value in T1 (where keycol is not NULL) ranges of below (prev) and above (nxt) values from T2 (where keycol is null).
Here’s the code implementing this step:
WITH all_vals AS
(
SELECT keycol, val
FROM dbo.T1
UNION ALL
SELECT DISTINCT NULL, val
FROM dbo.T2
),
ranges AS
(
SELECT keycol, val,
MAX(CASE WHEN keycol IS NULL THEN val END) OVER (ORDER BY val, keycol ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS prev,
MIN(CASE WHEN keycol IS NULL THEN val END) OVER (ORDER BY val, keycol ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) AS nxt
FROM all_vals
)
SELECT * FROM ranges;This code generates the following output:
keycol val prev nxt ----------- ----------- ----------- ----------- 1 1 NULL 2 2 1 NULL 2 NULL 2 NULL 3 NULL 3 2 7 3 3 3 7 4 3 3 7 5 5 3 7 NULL 7 3 11 6 8 7 11 NULL 11 7 13 NULL 13 11 17 7 13 13 17 8 16 13 17 NULL 17 13 19 9 18 17 19 NULL 19 17 NULL 10 20 19 NULL 11 21 19 NULL
In Step 2 of the solution you query the CTE ranges and filter only rows where keycol is not null. You return the keycol and val columns from T1 as keycol1 and val1, respectively. Then, between prev and nxt, you return the closest to val1 as val2.
Here’s the code implementing this step:
SELECT keycol AS keycol1, val AS val1,
CASE
WHEN ABS(val - prev) <= ISNULL(ABS(val - nxt), prev) THEN prev
ELSE nxt
END AS val2
FROM ranges
WHERE keycol IS NOT NULL;This code generates the following output:
keycol1 val1 val2 ----------- ----------- ----------- 1 1 2 2 1 2 3 3 3 4 3 3 5 5 3 6 8 7 7 13 13 8 16 17 9 18 17 10 20 19 11 21 19
In Step 3 of the solution you define a CTE called matched_vals based on the query from Step 2. You also define a derived table called T2 where using partitioned row numbers you handle the tiebreaking logic for the rows from dbo.T2. You then join matched_vals, the CTE T2 and the table T1 to handle the final matching logic.
Here’s the code implementing this step:
SELECT
keycol1, val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
val2, T2.keycol AS keycol2, SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM matched_vals AS M
INNER JOIN ( SELECT *, ROW_NUMBER() OVER (PARTITION BY val ORDER BY keycol) AS rn
FROM dbo.T2 ) AS T2
ON T2.val = M.val2 AND rn = 1
INNER JOIN dbo.T1
ON T1.keycol = keycol1;The plan for Kamil's variation on Alejandro's solution with supporting indexes is shown in Figure 5.
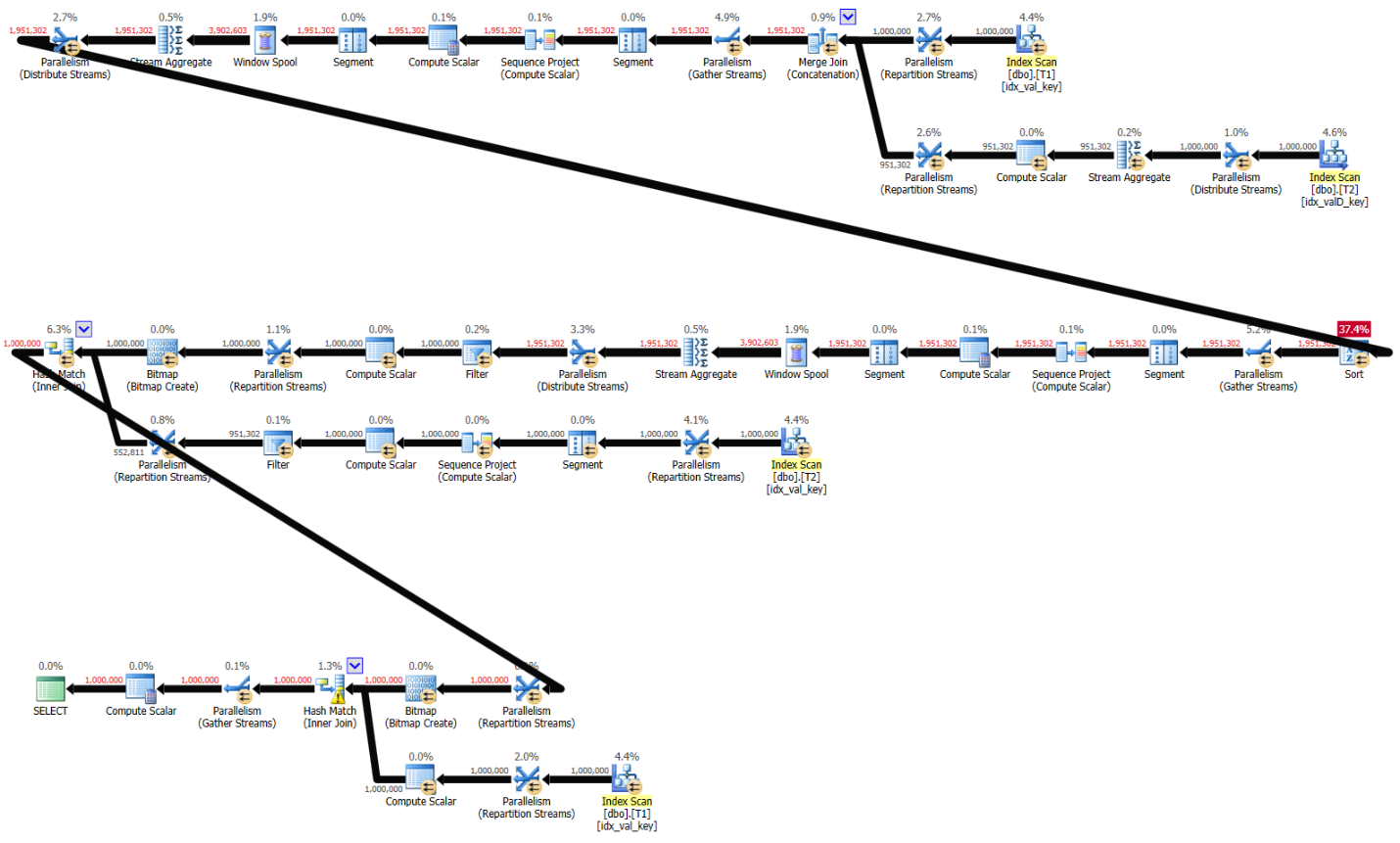 Figure 5: Plan for Kamil’s variation on Alejandro’s solution with indexes
Figure 5: Plan for Kamil’s variation on Alejandro’s solution with indexes
Here are the performance stats for this plan:
run time: 11.5, CPU: 18.3, logical reads: 59,218
The plan for Kamil's variation on Alejandro's solution without supporting indexes is shown in Figure 6.
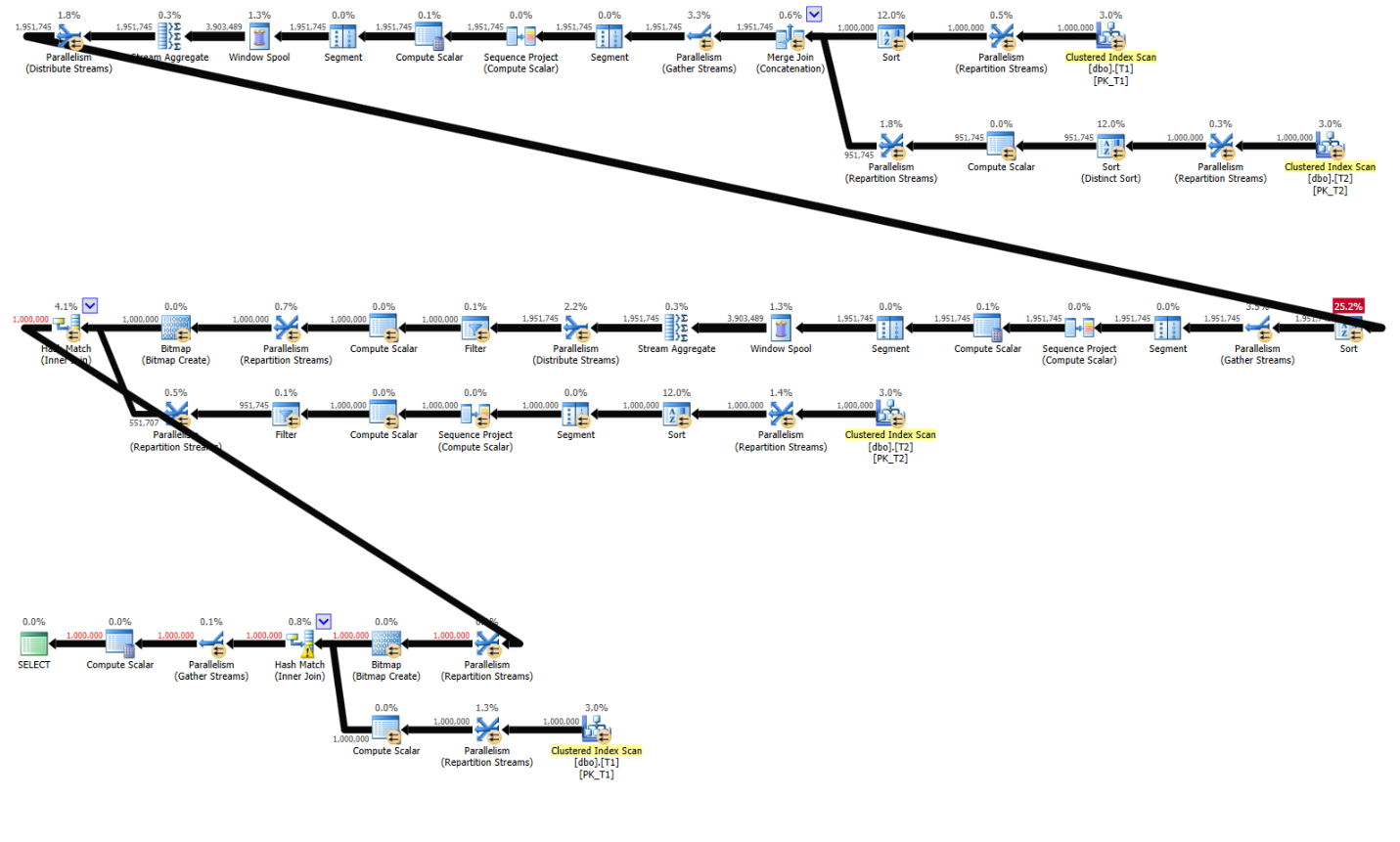 Figure 6: Plan for Kamil’s variation on Alejandro’s solution without indexes
Figure 6: Plan for Kamil’s variation on Alejandro’s solution without indexes
Here are the performance stats for this plan:
run time: 12.6, CPU: 23.5, logical reads: 61,432
Similar to the plans for Alejandro’s solution, also in this case the plan in Figure 5 doesn’t require explicit sorts prior to applying the Merge Join (concatenation) operator since the data is retrieved preordered from supporting indexes, and the plan in Figure 6 does require explicit sorts since there are no supporting indexes.
Solution by Radek Celuch – Using intervals
Radek came up with a simple and beautiful idea. For each distinct value in T2.val you compute an interval representing the range of values from T1.val that would match the current T2.val.
Here’s the complete solution’s code:
WITH Pre1 AS
(
SELECT keycol, val, othercols,
ROW_NUMBER() OVER(PARTITION BY val ORDER BY keycol) AS rn
FROM dbo.T2
),
Pre2 AS
(
SELECT keycol, val, othercols,
LAG(val) OVER(ORDER BY val) AS prev,
LEAD(val) OVER(ORDER BY val) AS next
FROM Pre1
WHERE rn = 1
),
T2 AS
(
SELECT keycol, val, othercols,
ISNULL(val - (val - prev) / 2 + (1 - (val - prev) % 2), 0) AS low,
ISNULL(val + (next - val) / 2, 2147483647) AS high
FROM Pre2
)
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
T2.keycol AS keycol2, T2.val AS val2, SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM dbo.T1
INNER JOIN T2
ON T1.val BETWEEN T2.low AND T2.high;In Step 1 of the solution you query T2 and compute row numbers (call the column rn), partitioned by val and ordered by keycol. You define a CTE called Pre1 based on this query. You then query Pre1 and filter only the rows where rn = 1. In the same query, using LAG and LEAD, you return for each row the value of the val column from the previous row (call it prev) and from the next row (call it next).
Here’s the code implementing this step:
WITH Pre1 AS
(
SELECT keycol, val, othercols,
ROW_NUMBER() OVER(PARTITION BY val ORDER BY keycol) AS rn
FROM dbo.T2
)
SELECT keycol, val, othercols,
LAG(val) OVER(ORDER BY val) AS prev,
LEAD(val) OVER(ORDER BY val) AS next
FROM Pre1
WHERE rn = 1;This code generates the following output:
keycol val othercols prev next ------- ---- ---------- ----------- ----------- 1 2 0xBB NULL 3 4 3 0xBB 2 7 3 7 0xBB 3 11 6 11 0xBB 7 13 8 13 0xBB 11 17 9 17 0xBB 13 19 10 19 0xBB 17 NULL
In Step 2 of the solution you define a CTE called Pre2 based on the query from Step 1. You query Pre2 and compute for each row an interval [low, high] where val from T1 would fall in. Here are the calculations for low and high:
- low = ISNULL(val - (val - prev) / 2 + (1 - (val - prev) % 2), 0)
- high = ISNULL(val + (next - val) / 2, 2147483647)
The mod 2 check on calculating the low boundary is used to meet the lower T2.val requirement, and the row number filter is used to meet the lower T2.keycol requirement. The values 0 and 2147483647 are used as the extreme lower and upper limits.
Here’s the code implementing this step:
SELECT keycol, val, othercols,
ISNULL(val - (val - prev) / 2 + (1 - (val - prev) % 2), 0) AS low,
ISNULL(val + (next - val) / 2, 2147483647) AS high
FROM Pre2;This code generates the following output:
keycol val othercols low high ------- ---- ---------- ---- ----------- 1 2 0xBB 0 2 4 3 0xBB 3 5 3 7 0xBB 6 9 6 11 0xBB 10 12 8 13 0xBB 13 15 9 17 0xBB 16 18 10 19 0xBB 19 2147483647
In Step 3 of the solution you define a CTE called T2 based on the query from Step 2. You Then join the table T1 with the CTE T2 matching rows based on val from T1 being within the interval [low, high] in T2.
Here’s the code implementing this step:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
T2.keycol AS keycol2, T2.val AS val2, SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM dbo.T1
INNER JOIN T2
ON T1.val BETWEEN T2.low AND T2.high;The plan for Radek’s solution with supporting indexes is shown in Figure 7.
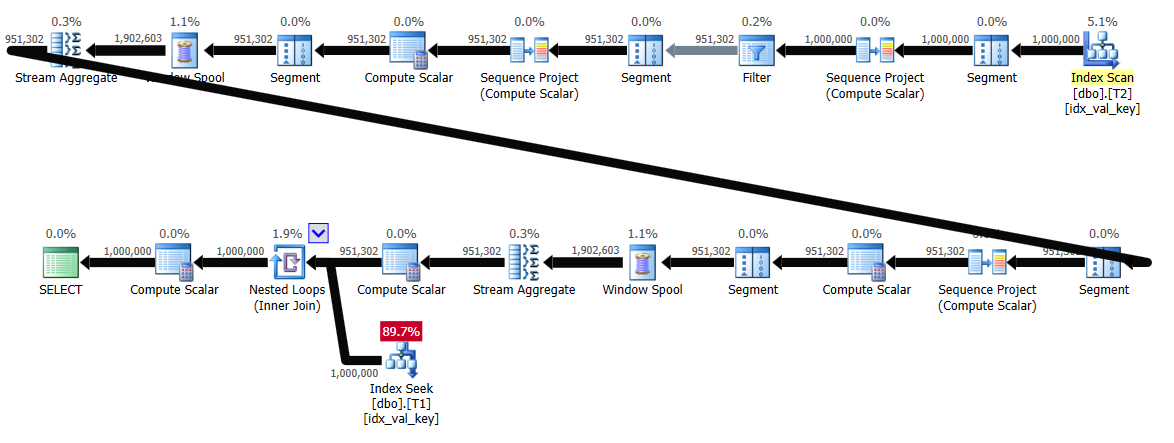 Figure 7: Plan for solution by Radek with indexes
Figure 7: Plan for solution by Radek with indexes
Here are the performance stats for this plan:
run time: 10.6, CPU: 7.63, logical reads: 3,193,125
The plan for Radek’s solution without supporting indexes is shown in Figure 8.
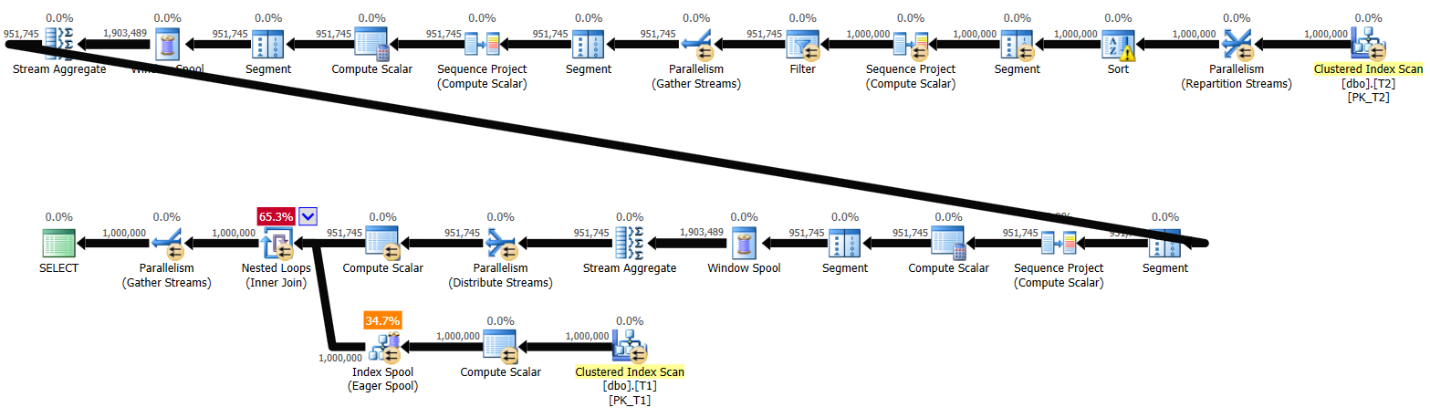 Figure 8: Plan for solution by Radek without indexes
Figure 8: Plan for solution by Radek without indexes
Here are the performance stats for this plan:
run time: 18.1, CPU: 27.4, logical reads: 5,827,360
Here the performance difference between the two plans is quite substantial. The plan in Figure 8 requires a preliminary sort before the computation of the row numbers, which the plan in Figure 7 doesn’t. More importantly, to match each interval with the respective rows from T1, the plan in Figure 8 creates an Index Spool essentially as an alternative to the missing index, whereas the plan in Figure 7 simply uses the existing index idx_val_key on T1. That’s the main reason for the big differences across all performance measures. Still, the performance without supporting indexes is reasonable.
Kamil's variation on Radek's solution
Kamil came up with a variation on Radek’s solution. Here’s the complete solution’s code:
WITH T2_collapsed AS
(
SELECT
keycol AS keycol2,
val AS val2 ,
ROW_NUMBER() OVER (PARTITION BY val ORDER BY keycol) AS rn
FROM dbo.T2
),
ranges AS
(
SELECT
keycol2 AS prevkey,
val2 AS prevval,
LEAD(keycol2) OVER (ORDER BY val2) AS nxtkey,
LEAD(val2) OVER (ORDER BY val2) AS nxtval
FROM T2_collapsed
WHERE rn = 1
),
bestmatches AS
(
SELECT
T1.keycol AS keycol1,
T1.val AS val1,
SUBSTRING(T1.othercols, 1, 1) AS othercols1,
CASE WHEN ABS(T1.val - prevval) <= ABS(T1.val - nxtval) THEN prevkey ELSE nxtkey END AS keycol2,
CASE WHEN ABS(T1.val - prevval) <= ABS(T1.val - nxtval) THEN prevval ELSE nxtval END AS val2
FROM ranges
INNER JOIN dbo.T1
ON prevval <= T1.val AND T1.val < nxtval
UNION ALL
SELECT
T1.keycol,
T1.val,
SUBSTRING(T1.othercols, 1, 1),
CASE WHEN T1.val < valmin THEN keycolmin ELSE keycolmax END AS keycol2,
CASE WHEN T1.val < valmin THEN valmin ELSE valmax END AS val2
FROM dbo.T1
CROSS APPLY(SELECT TOP(1) keycol AS keycolmin, val AS valmin
FROM dbo.T2
ORDER BY val, keycol) AS floorvals
CROSS APPLY(SELECT TOP(1) keycol AS keycolmax, val AS valmax
FROM dbo.T2
ORDER BY val DESC, keycol) AS ceilingvals
WHERE T1.val < floorvals.valmin OR ceilingvals.valmax <= T1.val
)
SELECT keycol1, val1, othercols1, keycol2, val2,
SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM bestmatches AS B
INNER JOIN dbo.T2
ON T2.keycol = B.keycol2;Here’s Kamil’s own description of this solution:
This solution is close to Radek's idea of checking against low and high range, although the ranges are based purely on actual T2 values. We get each row and the lead values only for each row in collapsed T2 (first step always gets rid of duplicate keys if found, by using row number or min(keycol) grouped by val on t2). The key concepts are how to check low and high range not to get duplicates – lower range inclusive, higher range exclusive, as well as handling the outliers (if present) by creating a separate set looking at the lowest and max values in T2 (UNION ALL bit). The check against the max value is done with inclusive range to complement the case of T1 vals being equal to the top T2 vals.
The plan for Kamil’s variation on Radek’s solution with supporting indexes is shown in Figure 9.
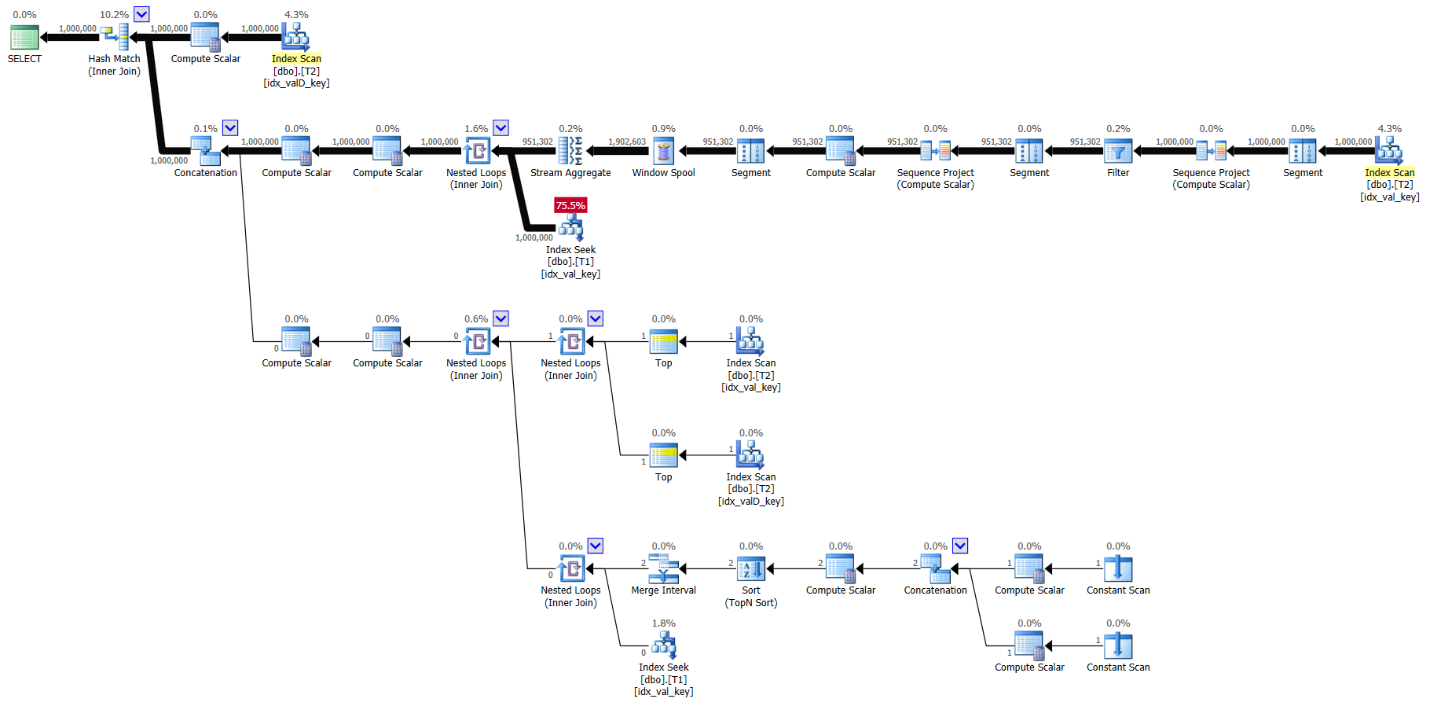 Figure 9: Plan for Kamil’s variation on Radek’s solution with indexes
Figure 9: Plan for Kamil’s variation on Radek’s solution with indexes
Here are the performance stats for this plan:
run time: 8.59, CPU: 8.5, logical reads: 3,206,849
The plan for Kamil’s variation on Radek’s solution without supporting indexes is shown in Figure 10.
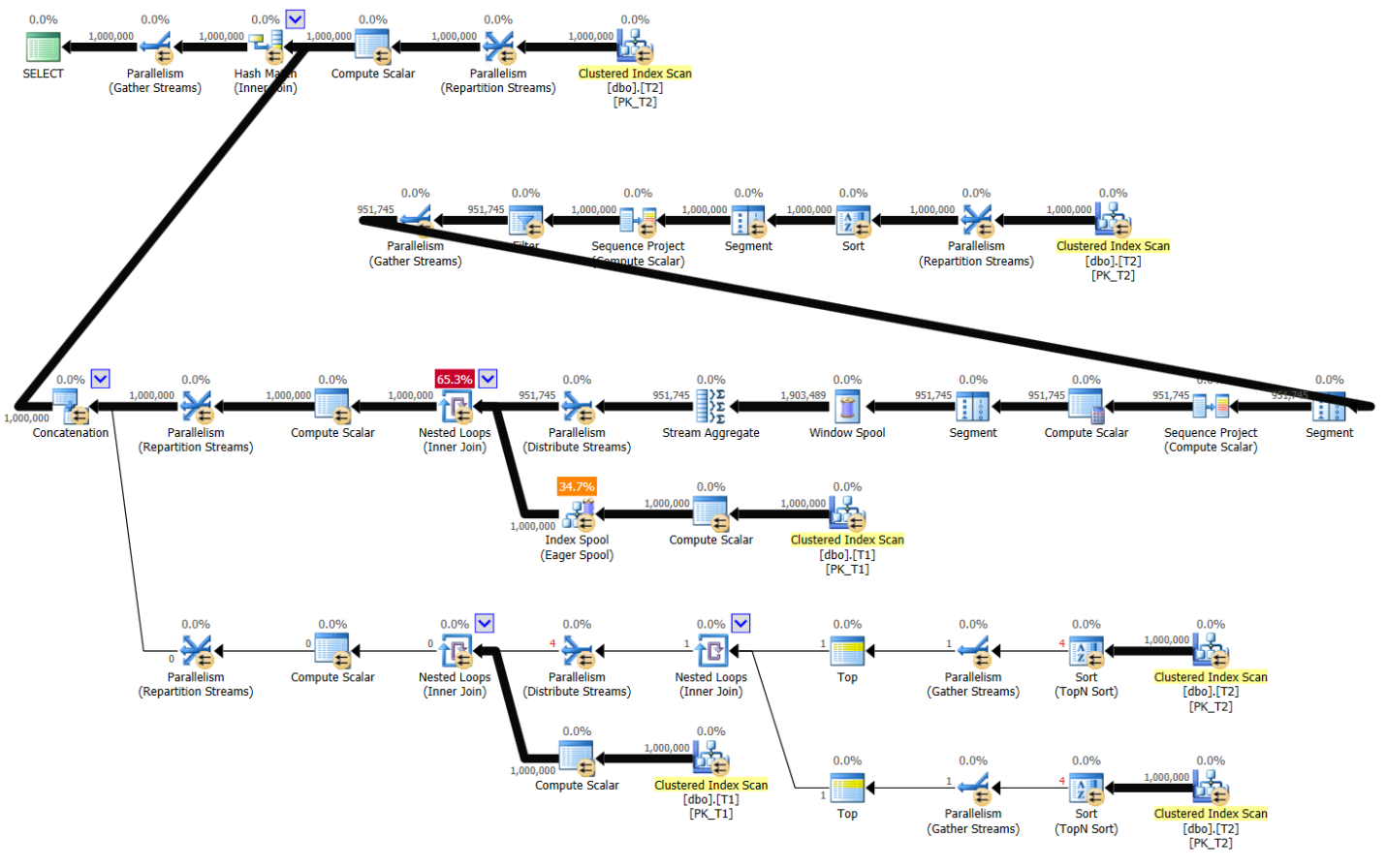 Figure 10: Plan for Kamil’s variation on Radek’s solution without indexes
Figure 10: Plan for Kamil’s variation on Radek’s solution without indexes
Here are the performance stats for this plan:
run time: 14, CPU: 24.5, logical reads: 5,870,596
The plan in Figure 9 is serial and most of the calculations are done based on preordered data obtained from the supporting indexes. The plan in Figure 10 is parallel, plus there are a few sorts, and even an index spool activity. The performance measures of the latter plan are substantially higher than the former plan, but the performance in both cases is reasonable.
Solution 2 by Kamil Kosno – Using ranking, offset and aggregate window functions
Kamil came up with another original approach that is based on a combination of ranking, offset and aggregate window functions. Here’s the complete solution’s code:
WITH A AS
(
SELECT 1 AS t, keycol,val,
DENSE_RANK() OVER(ORDER BY val) AS rnk
FROM dbo.T1
UNION ALL
SELECT NULL, MIN(keycol), val, 0
FROM dbo.T2
GROUP BY val
),
B AS
(
SELECT t, keycol, val,
CASE
WHEN t = 1 THEN DENSE_RANK() OVER (ORDER BY val, t) - rnk
ELSE 0
END AS grp,
LAG(CASE WHEN t IS NULL THEN val END) OVER(ORDER BY val, t) AS prev,
LAG(CASE WHEN t IS NULL THEN keycol END) OVER(ORDER BY val, t) AS prevkey,
LEAD(CASE WHEN t IS NULL THEN val END) OVER(ORDER BY val, t) AS nxt,
LEAD(CASE WHEN t IS NULL THEN keycol END) OVER(ORDER BY val, t) AS nxtkey
FROM A
),
C AS
(
SELECT keycol AS keycol1, val AS val1,
MAX (prev) OVER(PARTITION BY grp
ORDER BY prev DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS mxprev,
MAX (prevkey) OVER(PARTITION BY grp
ORDER BY prev DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS mxprevkey,
MAX (nxt) OVER(PARTITION BY grp
ORDER BY nxt
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS mxnxt,
MAX (nxtkey) OVER(PARTITION BY grp
ORDER BY nxt
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS mxnxtkey
FROM B
WHERE t = 1
),
D AS
(
SELECT keycol1, val1,
CASE WHEN ABS(val1 - mxprev) <= ISNULL(ABS(val1 - mxnxt), mxprev) THEN mxprevkey ELSE mxnxtkey END AS keycol2,
CASE WHEN ABS(val1 - mxprev) <= ISNULL(ABS(val1 - mxnxt), mxprev) THEN mxprev ELSE mxnxt END AS val2
FROM C
)
SELECT D.keycol1, D.val1, D.keycol2, D.val2,
SUBSTRING(T1.othercols, 1, 1) AS othercols1,
SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM D
INNER JOIN dbo.T1
ON T1.keycol = D.keycol1
INNER JOIN dbo.T2
ON T2.keycol = D.keycol2;In Step 1 of the solution you unify the following result sets:
- Rows from T1 with a result column called t assigned with the constant 1 and column rnk representing dense rank values ordered by val
- Group rows from T2 by val and return val and min keycol for each group, with the result column t assigned with NULL and rnk with 0
Here’s the code implementing this step:
SELECT 1 AS t, keycol,val,
DENSE_RANK() OVER(ORDER BY val) AS rnk
FROM dbo.T1
UNION ALL
SELECT NULL, MIN(keycol), val, 0
FROM dbo.T2
GROUP BY val;This code generates the following output:
t keycol val rnk ----------- ----------- ----------- -------------------- 1 1 1 1 1 2 1 1 1 3 3 2 1 4 3 2 1 5 5 3 1 6 8 4 1 7 13 5 1 8 16 6 1 9 18 7 1 10 20 8 1 11 21 9 NULL 1 2 0 NULL 4 3 0 NULL 3 7 0 NULL 6 11 0 NULL 8 13 0 NULL 9 17 0 NULL 10 19 0
In Step 2 of the solution you define a CTE called A based on the query from Step 1. You query A and compute group identifiers (grp) for T1 values that fall between ranges of distinct T2 values. This is done using an islands technique where you subtract rnk (dense ranks for only T1 values) from rnk2 (dense ranks for unified T1 values and distinct T2 values).
Using the LAG and LEAD functions, you compute for each T1 row the prev/next val and keycol values from T2, if present, and NULL otherwise. These calculations return values for the first and last rows in each group, if present, but NULLs for intermediate rows in groups.
Here’s the code implementing this step:
SELECT t, keycol, val, rnk,
DENSE_RANK() OVER (ORDER BY val) AS rnk2,
CASE
WHEN t = 1 THEN DENSE_RANK() OVER (ORDER BY val, t) - rnk
ELSE 0
END AS grp,
LAG(CASE WHEN t IS NULL THEN val END) OVER(ORDER BY val, t) AS prev,
LAG(CASE WHEN t IS NULL THEN keycol END) OVER(ORDER BY val, t) AS prevkey,
LEAD(CASE WHEN t IS NULL THEN val END) OVER(ORDER BY val, t) AS nxt,
LEAD(CASE WHEN t IS NULL THEN keycol END) OVER(ORDER BY val, t) AS nxtkey
FROM A;This code generates the following output:
t keycol val rnk rnk2 grp prev prevkey nxt nxtkey ----- ------ --- --- ---- --- ----- ------- ----- ------- 1 1 1 1 1 0 NULL NULL NULL NULL 1 2 1 1 1 0 NULL NULL 2 1 NULL 1 2 0 2 0 NULL NULL 3 4 NULL 4 3 0 3 0 2 1 NULL NULL 1 3 3 2 3 2 3 4 NULL NULL 1 4 3 2 3 2 NULL NULL NULL NULL 1 5 5 3 4 2 NULL NULL 7 3 NULL 3 7 0 5 0 NULL NULL NULL NULL 1 6 8 4 6 3 7 3 11 6 NULL 6 11 0 7 0 NULL NULL 13 8 NULL 8 13 0 8 0 11 6 NULL NULL 1 7 13 5 8 5 13 8 NULL NULL 1 8 16 6 9 5 NULL NULL 17 9 NULL 9 17 0 10 0 NULL NULL NULL NULL 1 9 18 7 11 6 17 9 19 10 NULL 10 19 0 12 0 NULL NULL NULL NULL 1 10 20 8 13 7 19 10 NULL NULL 1 11 21 9 14 7 NULL NULL NULL NULL
In Step 3 you define a CTE called B based on the query from Step 2. You Query B and filter only original T1 rows (where t = 1). In each group, you return the first row's prev and prevkey values, and last row's nxt and nxtkey values. Instead of just using a window partition clause, a window frame specification is used to define the minimal frame with the desired row to reduce I/O against the spool.
Here’s the code implementing this step:
SELECT keycol AS keycol1, val AS val1,
MAX (prev) OVER(PARTITION BY grp
ORDER BY prev DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS mxprev,
MAX (prevkey) OVER(PARTITION BY grp
ORDER BY prev DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS mxprevkey,
MAX (nxt) OVER(PARTITION BY grp
ORDER BY nxt
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS mxnxt,
MAX (nxtkey) OVER(PARTITION BY grp
ORDER BY nxt
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS mxnxtkey
FROM B
WHERE t = 1;This code generates the following output:
keycol1 val1 mxprev mxprevkey mxnxt mxnxtkey ----------- ----------- ----------- ----------- ----------- ----------- 2 1 NULL NULL 2 1 1 1 NULL NULL 2 1 5 5 3 4 7 3 3 3 3 4 7 3 4 3 3 4 7 3 6 8 7 3 11 6 8 16 13 8 17 9 7 13 13 8 17 9 9 18 17 9 19 10 10 20 19 10 NULL NULL 11 21 19 10 NULL NULL
In Step 4 you define a CTE called C based on the query from Step 3. You query C to compute keycol2 and val2 based on the closest match.
Here’s the code implementing this step:
SELECT keycol1, val1,
CASE WHEN ABS(val1 - mxprev) <= ISNULL(ABS(val1 - mxnxt), mxprev) THEN mxprevkey ELSE mxnxtkey END AS keycol2,
CASE WHEN ABS(val1 - mxprev) <= ISNULL(ABS(val1 - mxnxt), mxprev) THEN mxprev ELSE mxnxt END AS val2
FROM C;This code generates the following output:
keycol1 val1 keycol2 val2 ----------- ----------- ----------- ----------- 2 1 1 2 1 1 1 2 5 5 4 3 3 3 4 3 4 3 4 3 6 8 3 7 8 16 9 17 7 13 8 13 9 18 9 17 10 20 10 19 11 21 10 19
In Step 5 you define a CTE called D based on the query from Step 4. You then join D with T1 and T2 to get the other needed columns.
Here’s the code implementing this step:
SELECT D.keycol1, D.val1, D.keycol2, D.val2,
SUBSTRING(T1.othercols, 1, 1) AS othercols1,
SUBSTRING(T2.othercols, 1, 1) AS othercols2
FROM D
INNER JOIN dbo.T1
ON T1.keycol = D.keycol1
INNER JOIN dbo.T2
ON T2.keycol = D.keycol2;The plan for solution 2 by Kamil with supporting indexes is shown in Figure 11.
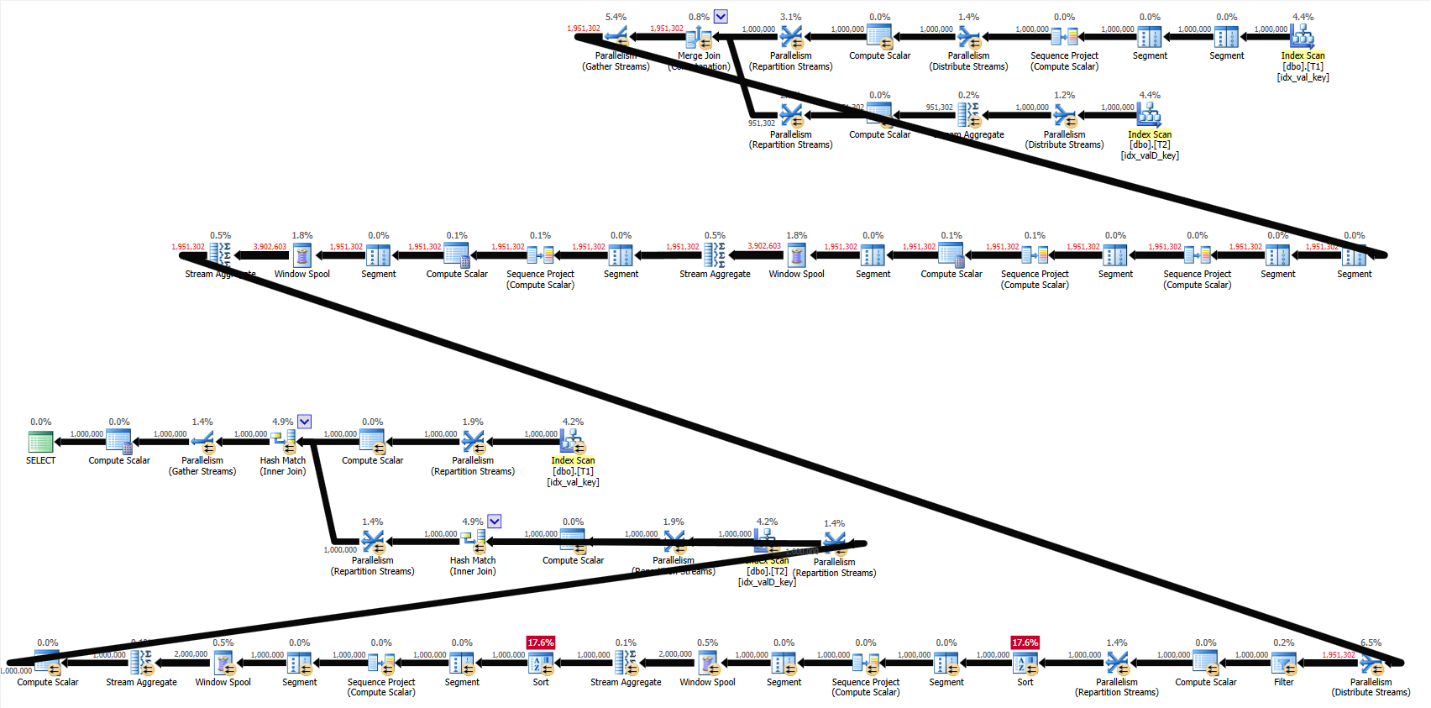 Figure 11: Plan for solution 2 by Kamil with indexes
Figure 11: Plan for solution 2 by Kamil with indexes
Here are the performance stats for this plan:
run time: 18.1, CPU: 34.4, logical reads: 56,736
The plan for solution 2 by Kamil without supporting indexes is shown in Figure 12.
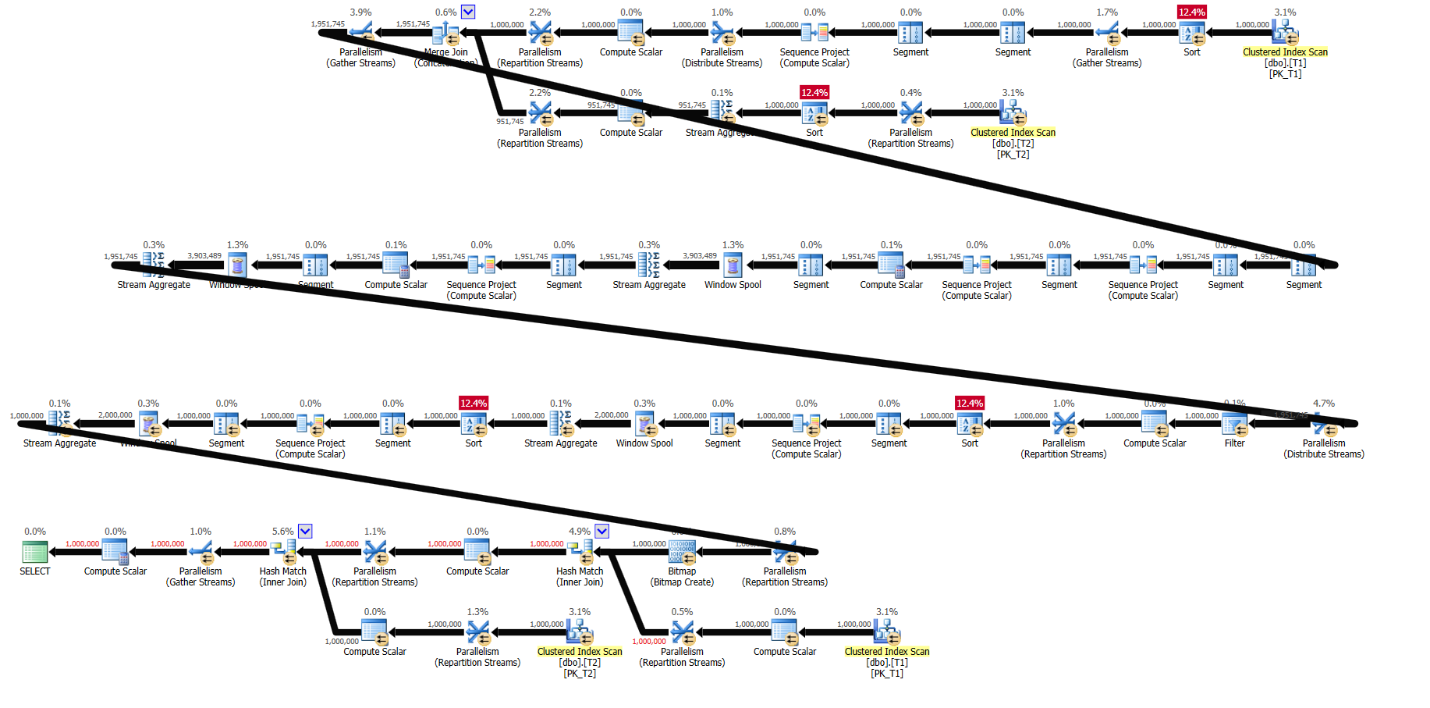 Figure 12: Plan for solution 2 by Kamil without indexes
Figure 12: Plan for solution 2 by Kamil without indexes
Here are the performance stats for this plan:
run time: 20.3, CPU: 38.9, logical reads: 59,012
As you can see, the Plan in Figure 12 involves a couple of extra sorts compared to the plan in Figure 1 to order the data for the two queries in the CTE A—one to support the dense rank calculation and the other to support the grouped query. Other than that, the rest of the work is similar in both. In the grand scheme of things, there’s a bit of extra CPU work and consequentially time penalty, but still both queries perform fairly reasonably.
Conclusion
This article concludes the series on the closest match challenge. It’s great to see the different creative ideas that Kamil, Alejandro and Radek came up with. Thanks to all of you for sending your solutions!
4 thoughts on “Closest Match, Part 3”
Comments are closed.

Thanks Itzik, challenges are the best way to learn sql, as you always underline in great books and articles on the subject. Have a great day!
Thanks for another great post with some great ideas.
Is there a book, series of blog posts or another source that enumerates these type of solutions/ideas?
I can think of Celko's Tree books (a bit too difficult), Numbers tables, Quirky Update, Dynamic pivot, but there are so many others that I don't even know that I don't know…
Best regards!
Thanks André!
I cover solutions of this type in T-SQL Querying 3rd Ed, as well as in High Performance T-SQL using Window Functions. In T-SQL Querying it's spread across the book. In High Performance T-SQL using Window Functions the last chapter is dedicated to solutions using window functions.
Thank you very much!
I had checked your T-SQL fundamentals & T-SQL Programming books some years ago (maybe 2005?). I'll definitely check those books and set some time aside to reading :)