
Closest Match, Part 1
Karen Ly, a Jr. Fixed Income Analyst at RBC, gave me a T-SQL challenge that involves finding the closest match, as opposed to finding an exact match. In this article I cover a generalized, simplistic, form of the challenge.
The challenge
The challenge involves matching rows from two tables, T1 and T2. Use the following code to create a sample database called testdb, and within it the tables T1 and T2:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
);
As you can see, both T1 and T2 have a numeric column (INT type in this example) called val. The challenge is to match to each row from T1 the row from T2 where the absolute difference between T2.val and T1.val is the lowest. In case of ties (multiple matching rows in T2), match the top row based on val ascending, keycol ascending order. That is, the row with the lowest value in the val column, and if you still have ties, the row with the lowest keycol value. The tiebreaker is used to guarantee determinism.
Use the following code to populate T1 and T2 with small sets of sample data in order to be able to check the correctness of your solutions:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19);Check the contents of T1:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols
FROM dbo.T1
ORDER BY val, keycol;This code generates the following output:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
Check the contents of T2:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols
FROM dbo.T2
ORDER BY val, keycol;This code generates the following output:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
Here’s the desired result for the given sample data:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
Before you start working on the challenge, examine the desired result and make sure you understand the matching logic, including the tiebreaking logic. For instance, consider the row in T1 where keycol is 5 and val is 5. This row has multiple closest matches in T2:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
In all these rows the absolute difference between T2.val and T1.val (5) is 2. Using the tiebreaking logic based on the order val ascending, keycol ascending the topmost row here is the one where val is 3 and keycol is 4.
You will use the small sets of sample data to check the validity of your solutions. To check performance, you need larger sets. Use the following code to create a helper function called GetNums, which generates a sequence of integers in a requested range:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GOUse the following code to populate T1 and T2 with large sets of sample data:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums;The variables @numrowsT1 and @numrowsT2 control the numbers of rows you want the tables to be populated with. The variables @maxvalT1 and @maxvalT2 control the range of distinct values in the val column, and therefore affect the density of the column. The above code fills the tables with 1,000,000 rows each, and uses the range of 1 – 10,000,000 for the val column in both tables. This results in low density in the column (large number of distinct values, with a small number of duplicates). Using lower maximum values will result in higher density (smaller number of distinct values, and hence more duplicates).
Solution 1, using one TOP subquery
The simplest and most obvious solution is probably one that queries T1, and using the CROSS APPLY operator applies a query with a TOP (1) filter, ordering the rows by the absolute difference between T1.val and T2.val, using T2.val, T2.keycol as the tiebreaker. Here’s the solution’s code:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A;Remember, there are 1,000,000 rows in each of the tables. And the density of the val column is low in both tables. Unfortunately, since there’s no filtering predicate in the applied query, and the ordering involves an expression that manipulates columns, there’s no potential here to create supporting indexes. This query generates the plan in Figure 1.
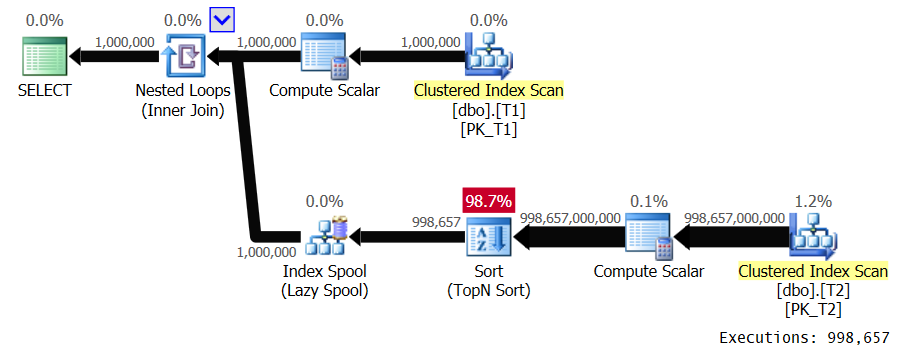 Figure 1: Plan for Solution 1
Figure 1: Plan for Solution 1
The outer input of the loop scans 1,000,000 rows from T1. The inner input of the loop performs a full scan of T2 and a TopN sort for each distinct T1.val value. In our plan this happens 998,657 times since we have very low density. It places the rows in an index spool, keyed by T1.val, so that it can reuse those for duplicate occurrences of T1.val values, but we have very few duplicates. This plan has quadratic complexity. Between all expected executions of the inner branch of the loop, it’s expected to process close to a trillion rows. When talking about large numbers of rows for a query to process, once you start mentioning billions of rows, people already know you’re dealing with an expensive query. Normally, people don’t utter terms like trillions, unless they’re discussing the US national debt, or stock market crashes. You usually don’t deal with such numbers in query processing context. But plans with quadratic complexity can quickly end up with such numbers. Running the query in SSMS with Include Live Query Statistics enabled took 39.6 seconds to process just 100 rows from T1 on my laptop. This means that it should take this query about 4.5 days to complete. The question is, are you really into binge-watching live query plans? Could be an interesting Guinness record to try and set.
Solution 2, using two TOP subqueries
Assuming you’re after a solution that takes seconds, not days, to complete, here’s an idea. In the applied table expression, unify two inner TOP (1) queries—one filtering a row where T2.val < T1.val (ordered by T2.val DESC, T2.keycol), and another filtering a row where T2.val >= T1.val (ordered by T2.val, T2.keycol). It’s easy to create indexes to support such queries by enabling a single-row seek. Still within the applied table expression, use an outer TOP (1) query against the two-row result, based on the order of ABS(D.val – T1.val), D.val, D.keycol. There will be a TopN sort involved, but it will be applied to two rows at a time.
Here are the recommended indexes to support this solution:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols);
CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols);
CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);Here’s the complete solution code:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A;Remember that we have 1,000,000 rows in each table, with the val column having values in the range 1 – 10,000,000 (low density), and optimal indexes in place.
The plan for this query is shown in Figure 2.
Observe the optimal use of the indexes on T2, resulting in a plan with linear scaling. This plan uses an index spool in the same manner the previous plan did, i.e., to avoid repeating the work in the inner branch of the loop for duplicate T1.val values. Here are the performance statistics that I got for the execution of this query on my system:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
Solution 2, with spooling disabled
You can’t help but wonder whether the index spool is really beneficial here. The point is to avoid repeating work for duplicate T1.val values, but in a situation like ours where we have very low density, there are very few duplicates. This means that most likely the work involved in spooling is greater than just repeating the work for duplicates. There’s a simple way to verify this—using trace flag 8690 you can disable spooling in the plan, like so:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690);I got the plan shown in Figure 3 for this execution:
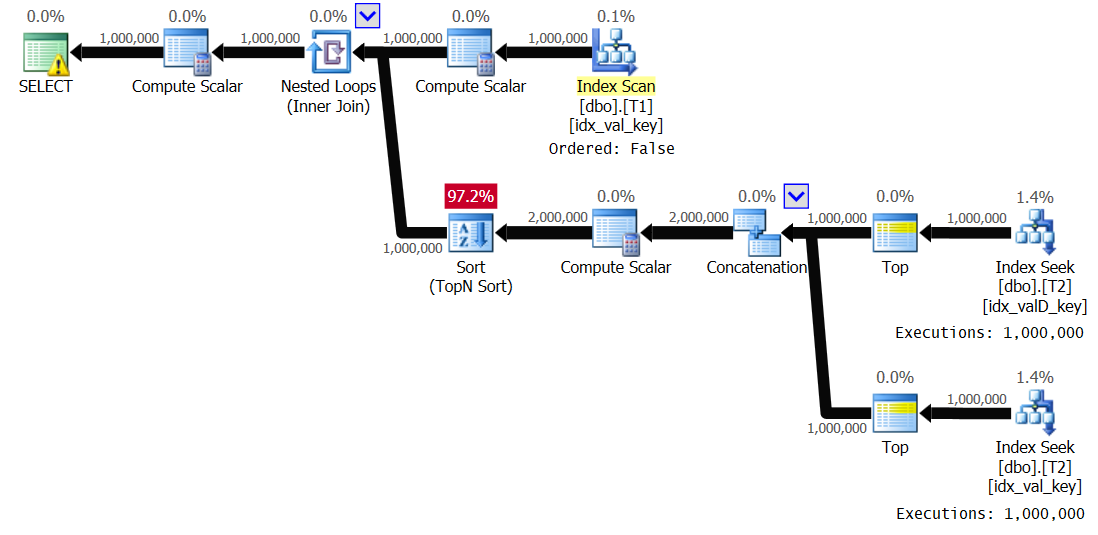 Figure 3: Plan for Solution 2, with spooling disabled
Figure 3: Plan for Solution 2, with spooling disabled
Observe that the index spool disappeared, and this time the inner branch of the loop gets executed 1,000,000 times. Here are the performance statistics that I got for this execution:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
That’s a reduction of 44 percent in the execution time.
Solution 2, with modified value range and indexing
Disabling spooling makes a lot of sense when you have low density in the T1.val values; however, the spooling can be very beneficial when you have high density. For example, run the following code to repopulate T1 and T2 with sample data setting @maxvalT1 and @maxvalT2 to 1000 (1,000 maximum distinct values):
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums;Rerun Solution 2, first without the trace flag:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A;The plan for this execution is shown in Figure 4:
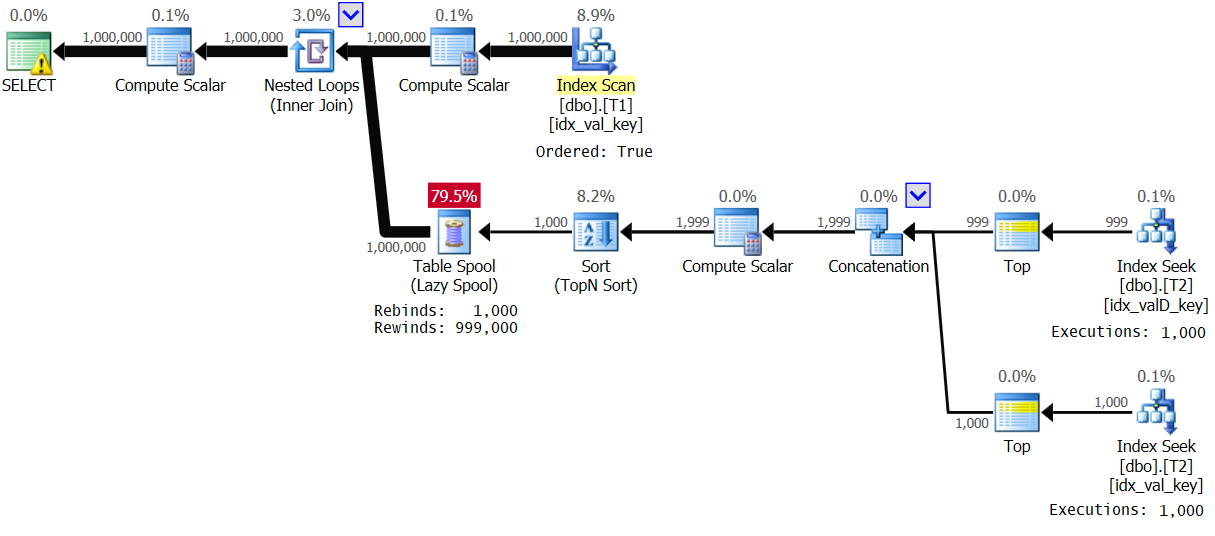 Figure 4: Plan for Solution 2, with value range 1 – 1000
Figure 4: Plan for Solution 2, with value range 1 – 1000
The optimizer decided to use a different plan due to the high density in T1.val. Observe that the index on T1 is scanned in key order. So, for each first occurrence of a distinct T1.val value the inner branch of the loop is executed, and the result is spooled in a regular table spool (rebind). Then, for each nonfirst occurrence of the value, a rewind is applied. With 1,000 distinct values, the inner branch is executed only 1,000 times. This results in excellent performance statistics:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
Now try running the solution with spooling disabled:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690);I got the plan shown in Figure 5.
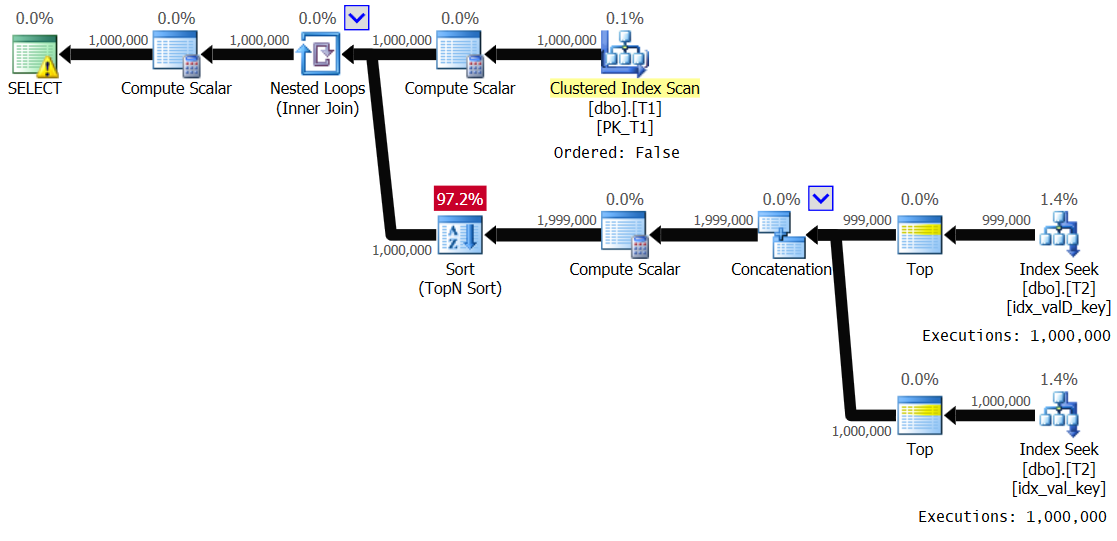 Figure 5: Plan for Solution 2, with value range 1 – 1,000 and spooling disabled
Figure 5: Plan for Solution 2, with value range 1 – 1,000 and spooling disabled
It’s essentially the same plan shown earlier in Figure 3. The inner branch of the loop gets executed 1,000,000 times. Here are the performance statistics that I got for this execution:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
Clearly, you want to be carful not to disable spooling when you have high density in T1.val.
Life is good when your situation is simple enough that you are able to create supporting indexes. The reality is that in some cases in practice, there’s enough additional logic in the query, that precludes the ability to create optimal supporting indexes. In such cases, Solution 2 will not do well.
To demonstrate the performance of Solution 2 without supporting indexes, repopulate T1 and T2 back with sample data setting @maxvalT1 and @maxvalT2 to 10000000 (value range 1 – 10M), and also remove the supporting indexes:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums;Rerun Solution 2, with Include Live Query Statistics enabled in SSMS:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A;I got the plan shown in Figure 6 for this query:
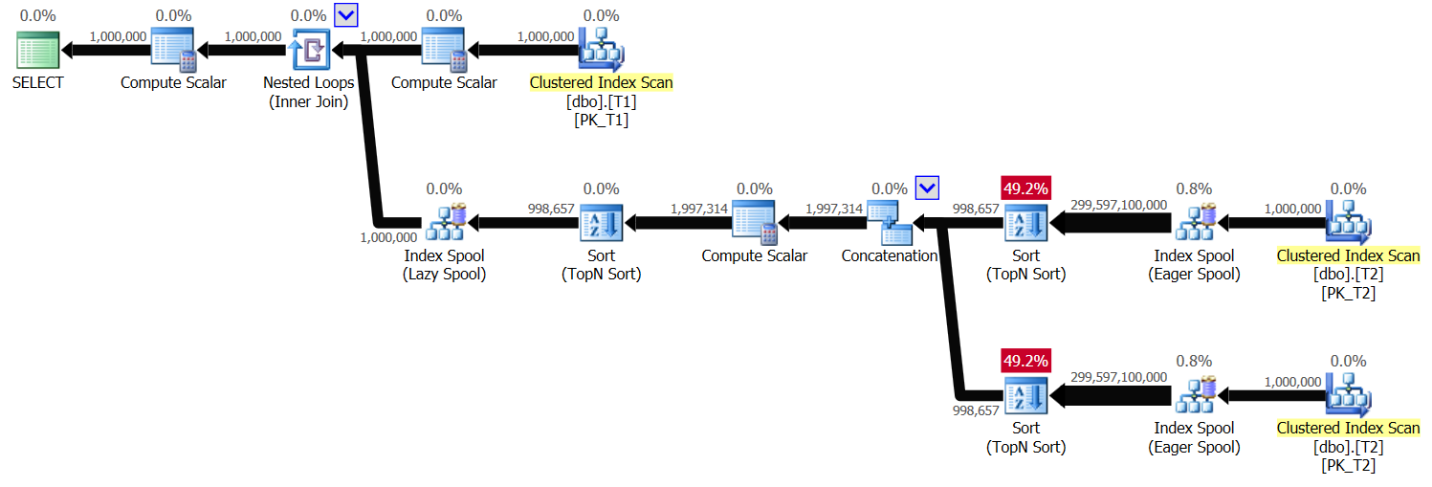 Figure 6: Plan for Solution 2, without indexing, with value range 1 – 1,000,000
Figure 6: Plan for Solution 2, without indexing, with value range 1 – 1,000,000
You can see a pattern very similar to the one shown earlier in Figure 1, only this time the plan scans T2 twice per distinct T1.val value. Again, the plan complexity goes quadratic. Running the query in SSMS with Include Live Query Statistics enabled took 49.6 seconds to process 100 rows from T1 on my laptop, meaning that it should take this query about 5.7 days to complete. This could of course mean good news if you’re trying to break the Guinness world record for binge-watching a live query plan.
Conclusion
I’d like to thank Karen Ly from RBC for presenting me with this nice closest match challenge. I was quite impressed with her code for handling it, which included a lot of extra logic that was specific to her system. In this article I showed reasonably performing solutions when you are able to create optimal supporting indexes. But as you could see, in cases where this is not an option, obviously the execution times that you get are abysmal. Can you think of solutions that will do well even without optimal supporting indexes? To be continued…
26 thoughts on “Closest Match, Part 1”
Comments are closed.

Hi Itzik,
Not sure if allowed, but I have tried a temp table approach (I create indexes on temp table):
by the way please replace > with > in SSMS if trying (used it to prevent text disappearing)
Hi Kamil,
Nice one!
Use of temp tables is often fair game in practice, so sure.
Here are the performance statistics that I get for your solution, without the original indexes on T1 and T2:
duration: 4.98 sec, cpu: 15.99 sec, logical reads: 6,748,489
Thanks!
Itzik
This is now fixed (thanks, Aaron!).
Hi Itzik,
Thanks.
I have revised my attempt, only slightly better – it looks cleaner though. I still haven't found anything reasonable without temp table.
drop table if exists #t2;
select min(keycol) as keycol,val into #t2 from T2 group by val;
create unique index idx_nc_val_key on #T2(val,keycol);
with bestvals as
(
select
keycol as keycol1,
val as val1,
othercols as othercols1,
case
when (prev + nxt is null) then coalesce(prev,nxt)
when abs(val-prev) < abs(val-nxt) then prev
when abs(val-nxt) < abs(val-prev) then nxt
else
(case when nxt < prev then nxt else prev end)
end as val2
from T1
cross apply(select max(val) as prev from #T2 where val <= T1.val) as prev
cross apply(select min(val) as nxt from #T2 where T1.val <= val) as nxt
)
select
keycol1,
val1,
SUBSTRING(othercols1,1,1) as othercols1,
tempt2.keycol as keycol2,
val2,
SUBSTRING(t2.othercols,1,1) as othercols2
from bestvals as b
inner join #t2 as tempt2 on tempt2.val = b.val2
inner join t2 on t2.keycol = tempt2.keycol
drop table #t2;
Hi Itzik,
Great article, as always, and an interesting challenge too.
Here is a possible solution that uses the following logic:
– Group T2 by [val] to get minimum [keycol] and make the solution deterministic
– Concatenate T1 and the set from the grouping, adding and extra column to differentiate the sets
– For each row in the final set calculate previous / next (val, keycol) if the row is part of the set coming from T1, otherwise NULL. For this, I used similar approach as when calculating "Last non-null", concatenating the binary values and finding MAX for previous rows and MIN for the following ones.
– The rest is to compare the closest from those values.
The solution performs the same with or without supporting indexes, and not to different for density of [val] in T2.
Looking forward for part two of the article.
Cheers,
Alejandro
WITH R1 AS (
SELECT
keycol, val, tid,
MAX(
CASE WHEN tid = 0 THEN CAST(val AS binary(4)) + CAST(keycol AS binary(4)) END
) OVER(
ORDER BY val, tid, keycol
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS below_binstr,
MIN(
CASE WHEN tid = 0 THEN CAST(val AS binary(4)) + CAST(keycol AS binary(4)) END
) OVER(
ORDER BY val, tid, keycol
ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING
) AS above_binstr
FROM
(
SELECT
keycol,
val,
1 AS tid
FROM
dbo.T1
UNION ALL
SELECT
MIN(keycol) AS keycol,
val,
0 AS tid
FROM
dbo.T2
GROUP BY
val
) AS T
)
, R2 AS (
SELECT
keycol,
val,
CAST(SUBSTRING(below_binstr, 1, 4) AS int) AS below_T2_val,
CAST(SUBSTRING(below_binstr, 5, 4) AS int) AS below_T2_keycol,
CAST(SUBSTRING(above_binstr, 1, 4) AS int) AS above_T2_val,
CAST(SUBSTRING(above_binstr, 5, 4) AS int) AS above_T2_keycol
FROM
R1
WHERE
tid = 1
)
, R3 AS (
SELECT
keycol,
val,
COALESCE(below_T2_val, above_T2_val) AS below_T2_val,
COALESCE(below_T2_keycol, above_T2_keycol) AS below_T2_keycol,
COALESCE(above_T2_val, below_T2_val) AS above_T2_val,
COALESCE(above_T2_keycol, below_T2_keycol) AS above_T2_keycol
FROM
R2
)
SELECT
keycol AS T1_keycol,
val AS T1_val,
CASE
WHEN ABS(val – below_T2_val) <= ABS(above_T2_val – val) THEN below_T2_keycol
ELSE above_T2_keycol
END AS T2_keycol,
CASE
WHEN ABS(val – below_T2_val) <= ABS(above_T2_val – val) THEN below_T2_val
ELSE above_T2_val
END AS T2_val
FROM
R3
OPTION (RECOMPILE);
GO
Thanks, Alejandro! Interesting solution.
Here are the performance statistics that I get for it:
with indexes: run time: 6.11 sec, logical reads: 29,516, cpu: 9.86 sec
without indexes: run time: 6.29 sec, logical reads: 29,516, cpu: 9.91 sec
Thanks, Kamil!
High, just read the article and can't wait what your approach is.
I have come with below query. However I can only test it on SQL Server 2012 and I am not entirely happy with performance. I will revise it on 2017 in few hour when I get back home.
The idea is to generate intervals in T2 where val from T1 would fall in and then join T1 on BETWEEN predicate. There is mod 2 check on calculating low boundary to meet lower T2.val requirement, and ROW_NUMBER() to meet lower T2.keycol requirement. I also added 0 and 2147483647 as lower and upper limits for lowest and highest boundary.
Hi Radek,
What an interesting concept; thanks for sharing this!
I get the following performance statistics for your solution:
with indexes: run time: 7.66 sec, logical reads: 3,192,808, cpu: 7.53 sec
without indexes: run time: 32.71 sec, logical reads: 5,826,706, cpu: 27.33 sec
Hi everyone,
This is a slight variation of Alejandro's solution which I find really cool. I wondered if you can get away without casting and getting all data by looking at val alone. Even though it is a bit slower than original, but it seems to be working very well despite lack of indexes (at least on my setup). I was especially surprised by a quick join on val to dbo.t2..
Hi Kamil,
I'm getting the following performance stats for this solution:
with indexes: run time: 9.22, logical reads: 71,059, cpu: 17.6
without indexes: run time: 9.71, logical reads: 85, 901, cpu: 19.31
without indexes 2019 with batch mode on rowstore: run time: 6.01, logical reads: 73,790, cpu: 9.97
Thanks for checking Itzik. In fact it could be shortened to this with less logical reads:
Oh either distinct or group by not needed in the first cte I was trying both options :-)
Hi Itzik,
I have something else, performing quite well although plenty logical reads on a worktable.
Here is the solution:
..a word of background – this is close to Radek's idea of checking against low and high range, although the ranges are based purely on actual t2 values. We get each row and the lead values only for each row in collapsed t2 (first step always gets rid of duplicate keys if found, by using row number or min(keycol) grouped by val on t2).
The key concepts are how to check low and high range not to get duplicates – lower range inclusive, higher range exclusive, as well as handling the outliers (if present) by creating a separate set looking at the lowest and max values in t2 (union all bit). The check against the max value is done with inclusive range to complement the case of t1 vals being equal to the top t2 vals.
Thanks
Kamil
Here is something with ranking functions.
The aim is to create groups of values in T1 that fall between T2 values. This is done using the dense_rank() technique.
Then, we take the last T2 value/key before and the first T2 value/key after each group, only for the edge values from T1(and T2 values as well, but those will be excluded later). The T1 values that lie in between get nulls (conditional lag/lead – lag(case when t is null then something end)). We end up with one value for prev and one value for nxt per group.
The last step is to populate prev and nxt for each value within group using window function version of max. The "rows between" construct reduces the number of logical reads although I don't see performance benefit(i.e. run time) on my system compare to not using it.
Not the best performance, but reasonable, regardless of presence of indexes.
Thanks for sending these solutions, Kamil. Lots of interesting ideas! Originally I planned to cover the challenge in two parts–one with my relational solutions and another with iterative solutions, but it looks like there's going to be a third part with reader solutions.
Thanks Itzik. To be fair only the last idea I sent is quite original (and first one with temp table), the between were more of variations of Alejandro's and Radek's ones, I was just playing to explore some options. In terms of articles I can't wait to see what you came up with, it's a really interesting topic. By the way – Happy New Year!
Kamil, within the CTE ranges, the window order clauses in both window functions should break ties by keycol, otherwise the choice is nondeterministic. Perhaps you don't see the bug with the small sets of sample data, but with the large sets you actually get incorrect results. Here's the solution with the fix:
WITH all_vals AS ( SELECT keycol, val FROM dbo.T1 UNION ALL SELECT DISTINCT NULL, val FROM dbo.T2 ), ranges AS ( SELECT keycol, val, MAX(CASE WHEN keycol IS NULL THEN val END) OVER (ORDER BY val, keycol ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS prev, MIN(CASE WHEN keycol IS NULL THEN val END) OVER (ORDER BY val, keycol ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) AS nxt FROM all_vals ), matched_vals AS ( SELECT keycol AS keycol1, val AS val1, CASE WHEN ABS(val - prev) <= ISNULL(ABS(val - nxt), prev) THEN prev ELSE nxt END AS val2 FROM ranges WHERE keycol IS NOT NULL ) SELECT keycol1, val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1, val2, T2.keycol AS keycol2, SUBSTRING(T2.othercols, 1, 1) AS othercols2 FROM matched_vals AS M INNER JOIN ( SELECT *, ROW_NUMBER() OVER (PARTITION BY val ORDER BY keycol) AS rn FROM dbo.T2 ) AS T2 ON T2.val = M.val2 AND rn = 1 INNER JOIN dbo.T1 ON T1.keycol = keycol1;Kamil, also here there are small bugs due to the nondeterministic nature of the calculations. In A, you need to break ties using keycol, and in B based on t, keycol. Here's the fixed solution:
WITH A AS ( SELECT 1 AS t, keycol,val, DENSE_RANK() OVER(ORDER BY val, keycol) AS rnk FROM dbo.T1 UNION ALL SELECT NULL, MIN(keycol), val, 0 FROM dbo.T2 GROUP BY val ), B AS ( SELECT t, keycol, val, CASE WHEN t = 1 THEN DENSE_RANK() OVER (ORDER BY val, t, keycol) - rnk ELSE 0 END AS grp, LAG(CASE WHEN t IS NULL THEN val END) OVER(ORDER BY val, t, keycol) AS prev, LAG(CASE WHEN t IS NULL THEN keycol END) OVER(ORDER BY val, t, keycol) AS prevkey, LEAD(CASE WHEN t IS NULL THEN val END) OVER(ORDER BY val, t, keycol) AS nxt, LEAD(CASE WHEN t IS NULL THEN keycol END) OVER(ORDER BY val, t, keycol) AS nxtkey FROM A ), C AS ( SELECT keycol AS keycol1, val AS val1, MAX (prev) OVER(PARTITION BY grp ORDER BY prev DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS mxprev, MAX (prevkey) OVER(PARTITION BY grp ORDER BY prev DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS mxprevkey, MAX (nxt) OVER(PARTITION BY grp ORDER BY nxt ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS mxnxt, MAX (nxtkey) OVER(PARTITION BY grp ORDER BY nxt ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS mxnxtkey FROM B WHERE t = 1 ), D AS ( SELECT keycol1, val1, CASE WHEN ABS(val1 - mxprev) <= ISNULL(ABS(val1 - mxnxt), mxprev) THEN mxprevkey ELSE mxnxtkey END AS keycol2, CASE WHEN ABS(val1 - mxprev) <= ISNULL(ABS(val1 - mxnxt), mxprev) THEN mxprev ELSE mxnxt END AS val2 FROM C ) SELECT D.keycol1, D.val1, D.keycol2, D.val2, SUBSTRING(T1.othercols, 1, 1) AS othercols1, SUBSTRING(T2.othercols, 1, 1) AS othercols2 FROM D INNER JOIN dbo.T1 ON T1.keycol = D.keycol1 INNER JOIN dbo.T2 ON T2.keycol = D.keycol2;Hi Itzik, I didn't realise there would be an issue. The reasoning behind what I did:
My understanding was that I don't need to look at keycol in T1, and that I need to match T2 values (with the smallest keycol) for each value (regardless of keycol) from T1. In other words, if there were 1 million rows in T1 I would expect 1 million results.
1. I used dense rank in both a and b only to ensure same values from table T1 end up in the same group regardless of order in which they are evaluated. I don't worry about groups from T2, and values from T2 are already filtered based on min keycol for each value anyway.
2. The lag/lead should get me prev and nxt for at least one/and only one value per each per group, even if there are two or more identical values coming from table T1 in bottom/top of any of the groups. Therefore I didn't use keycol as a tie-braker here either (whichever is served first is fine) – there can be multiple keys from T1 with the same value.
Is this logic flawed?
I have been testing this with big sample and so far I can see the bug, but so far here only – this in b:
WHEN t = 1 THEN DENSE_RANK() OVER (ORDER BY val) – rnk
should be:
WHEN t = 1 THEN DENSE_RANK() OVER (ORDER BY val, t) – rnk
still thinking…
You're right. The only required change is to add t to the window order clause in the dense rank calculation in b, setting it to DENSE_RANK() OVER (ORDER BY val, t) – rnk. No need to add keycol in either a or b.
Thank you for looking at this in detail, pointing out a problem and helping to improve.
Great article! I love your posts.
Have you got any thoughts on this one? Can I apply the same pattern? https://stackoverflow.com/questions/54624959/minimum-difference-between-timestamps-with-window-function
You answered my first question on lead/lag years ago here: https://stackoverflow.com/questions/31722337/lead-lag-sql-server-2012-gaps-and-islands
and it has stuck with me ever since!