
Reader solutions to Special Islands challenge
Last month I covered a Special Islands challenge. The task was to identify periods of activity for each service ID, tolerating a gap of up to an input number of seconds (@allowedgap). The caveat was that the solution had to be pre-2012 compatible, so you couldn’t use functions like LAG and LEAD, or aggregate window functions with a frame. I got a number of very interesting solutions posted in the comments by Toby Ovod-Everett, Peter Larsson, and Kamil Kosno. Make sure to go over their solutions since they’re all quite creative.
Curiously, a number of the solutions ran slower with the recommended index than without it. In this article I propose an explanation for this.
Even though all solutions were interesting, here I wanted to focus on the solution by Kamil Kosno, who’s an ETL developer with Zopa. In his solution, Kamil used a very creative technique to emulate LAG and LEAD without LAG and LEAD. You will probably find the technique handy if you need to perform LAG/LEAD-like calculations using code that is pre-2012 compatible.
Why are some solutions faster without the recommended index?
As a reminder, I suggested using the following index to support the solutions to the challenge:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);My pre-2012-compatible solution was the following:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;Figure 1 has the plan for my solution with the recommended index in place.
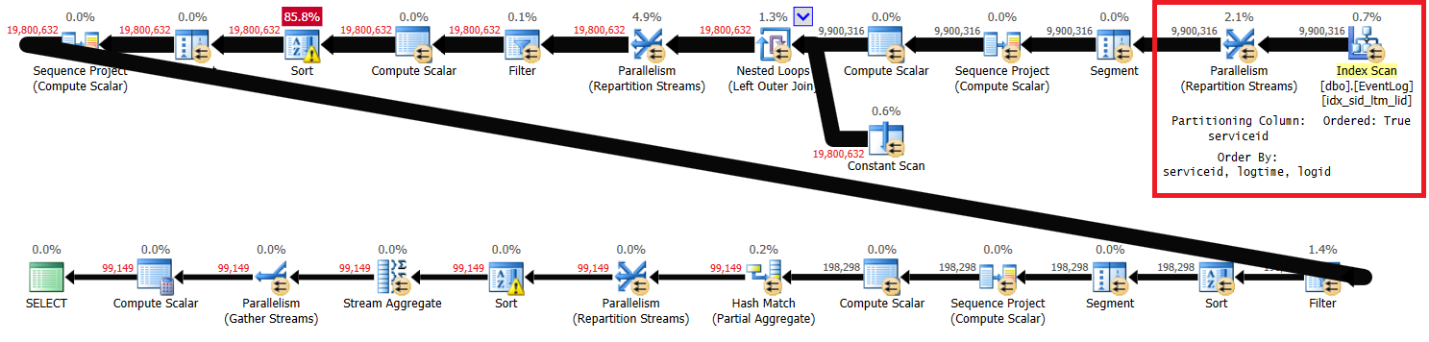 Figure 1: Plan for Itzik’s solution with recommended index
Figure 1: Plan for Itzik’s solution with recommended index
Notice that the plan scans the recommended index in key order (Ordered property is True), partitions the streams by serviceid using an order-preserving exchange, and then applies the initial calculation of row numbers relying on index order without the need for sorting. Following are the performance statistics that I got for this query execution on my laptop (elapsed time, CPU time and top wait expressed in seconds):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
I then dropped the recommended index and reran the solution:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;I got the plan shown in Figure 2.
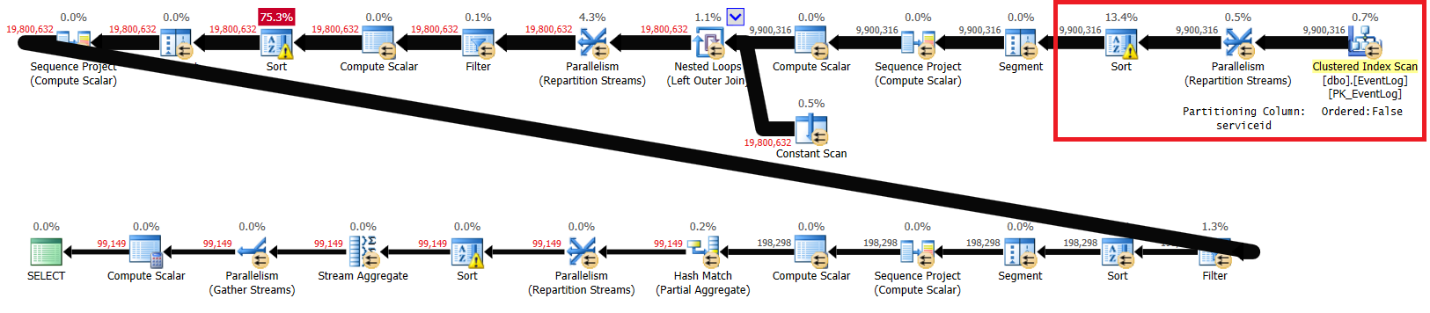 Figure 2: Plan for Itzik’s solution without recommended index
Figure 2: Plan for Itzik’s solution without recommended index
The highlighted sections in the two plans show the difference. The plan without the recommended index performs an unordered scan of the clustered index, partitions the streams by serviceid using a nonorder-preserving exchange, and then sorts the rows like the window function needs (by serviceid, logtime, logid). The rest of the work seems to be the same in both plans. You would think that the plan without the recommended index should be slower since it has an extra sort that the other plan doesn’t have. But here are the performance statistics that I got for this plan on my laptop:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
There’s more CPU time involved, which in part is due to the extra sort; there’s more I/O involved, probably due to additional sort spills; however, the elapsed time is about 30 percent faster. What could explain this? One way to try and figure this out is to run the query in SSMS with the Live Query Statistics option enabled. When I did this, the rightmost Parallelism (Repartition Streams) operator finished in 6 seconds without the recommended index and in 35 seconds with the recommended index. The key difference is that the former gets the data preordered from an index, and is an order-preserving exchange. The latter gets the data unordered, and isn’t an order-preserving exchange. Order-preserving exchanges tend to be more expensive than nonorder-preserving ones. Also, at least in the rightmost part of the plan until the first sort, the former delivers the rows in the same order as the exchange partitioning column, so you don’t get all threads to really process the rows in parallel. The later delivers the rows unordered, so you get all threads to process rows truly in parallel. You can see that the top wait in both plans is CXPACKET, but in the former case the wait time is double that of the latter, telling you that parallelism handling in the latter case is more optimal. There could be some other factors at play that I’m not thinking about. If you have additional ideas that could explain the surprising performance difference, please do share.
On my laptop this resulted in the execution without the recommended index being faster than the one with the recommended index. Still, on another test machine, it was the other way around. After all, you do have an extra sort, with spilling potential.
Out of curiosity, I tested a serial execution (with the MAXDOP 1 option) with the recommended index in place, and got the following performance stats on my laptop:
elapsed: 42, CPU: 40, logical reads: 143,519
As you can see, the run time is similar to the run time of the parallel execution with the recommended index in place. I have only 4 logical CPUs in my laptop. Of course, your mileage may vary with different hardware. The point is, it’s worthwhile testing different alternatives, including with and without the indexing that you would think that should help. The results are sometimes surprising and counterintuitive.
Kamil’s Solution
I was really intrigued by Kamil’s solution and especially liked the way he emulated LAG and LEAD with a pre-2012 compatible technique.
Here’s the code implementing the first step in the solution:
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog;This code generates the following output (showing only data for serviceid 1):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
This step computes two row numbers that are one apart for each row, partitioned by serviceid, and ordered by logtime. The current row number represents the end time (call it end_time), and the current row number minus one represents the start time (call it start_time).
The following code implements the second step of the solution:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U;This step generates the following output:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
This step unpivots each row into two rows, duplicating each log entry—once for time type start_time and another for end_time. As you can see, other than the minimum and maximum row numbers, each row number appears twice—once with the log time of the current event (start_time) and another with the log time of the previous event (end_time).
The following code implements the third step in the solution:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P;This code generates the following output:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
This step pivots the data, grouping pairs of rows with the same row number, and returning one column for the current event log time (start_time) and another for the previous event log time (end_time). This part effectively emulates a LAG function.
The following code implements the fourth step in the solution:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap;This code generates the following output:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
This step filters pairs where the difference between the previous end time and the current start time is greater than the allowed gap, and rows with only one event. Now you need to connect each current row’s start time with the next row’s end time. This requires a LEAD-like calculation. To achieve this, the code, again, creates row numbers that are one apart, only this time the current row number represents the start time (start_time_grp ) and the current row number minus one represents the end time (end_time_grp).
Like before, the next step (number 5) is to unpivot the rows. Here’s the code implementing this step:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U;Output:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
As you can see, the grp column is unique for each island within a service ID.
Step 6 is the final step in the solution. Here’s the code implementing this step, which is also the complete solution code:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL);This step generates the following output:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
This step groups the rows by serviceid and grp, filters only relevant groups, and returns the minimum start_time as the beginning of the island, and the maximum end time as the end of the island.
Figure 3 has the plan that I got for this solution with the recommended index in place:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);Plan with recommended index in Figure 3.
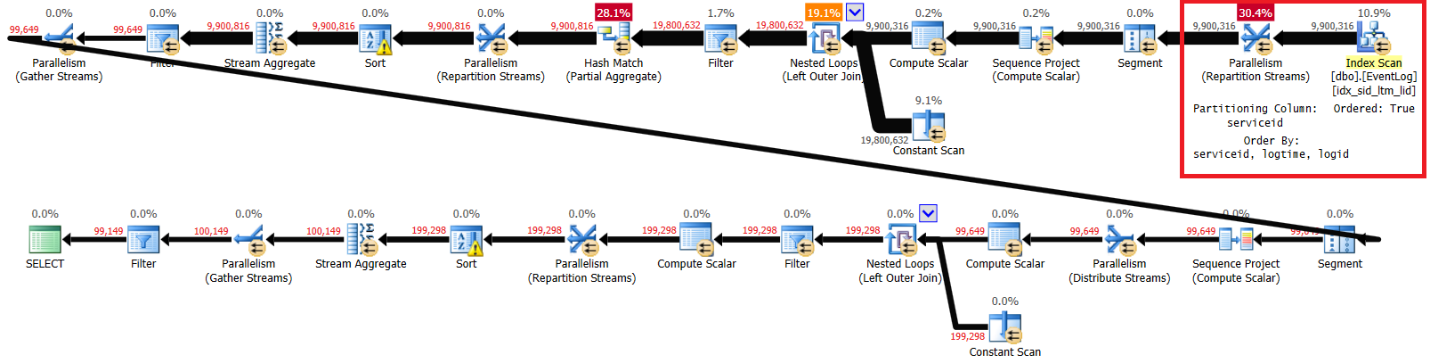 Figure 3: Plan for Kamil’s solution with recommended index
Figure 3: Plan for Kamil’s solution with recommended index
Here are the performance statistics that I got for this execution on my laptop:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
I then dropped the recommended index and reran the solution:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;I got the plan shown in Figure 4 for the execution without the recommended index.
 Figure 4: Plan for Kamil’s solution without recommended index
Figure 4: Plan for Kamil’s solution without recommended index
Here are the performance statistics that I got for this execution:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
The run times, CPU times, and CXPACKET wait times are very similar to my solution, although the logical reads are lower. Kamil’s solution also runs faster on my laptop without the recommended index, and it seems that it’s due to similar reasons.
Conclusion
Anomalies are a good thing. They make you curious and cause you to go and research the root cause of the problem, and as a result, learn new things. It is interesting to see that some queries, on certain machines, run faster without the recommended indexing.
Thanks again to Toby, Peter and Kamil for your solutions. In this article I covered Kamil’s solution, with his creative technique to emulate LAG and LEAD with row numbers, unpivoting and pivoting. You will find this technique useful when needing LAG- and LEAD-like calculations that have to be supported on pre-2012 environments.
