
Special Islands
Gaps and Islands tasks are classic querying challenges where you need to identify ranges of missing values and ranges of existing values in a sequence. The sequence is often based on some date, or date and time values, that should normally appear in regular intervals, but some entries are missing. The gaps task looks for the missing periods and the islands task looks for the existing periods. I covered many solutions to gaps and islands tasks in my books and articles in the past. Recently I was presented with a new special islands challenge by my friend, Adam Machanic, and solving it required a bit of creativity. In this article I present the challenge and the solution I came up with.
The challenge
In your database you keep track of services your company supports in a table called CompanyServices, and each service normally reports about once a minute that it’s online in a table called EventLog. The following code creates these tables and populates them with small sets of sample data:
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog;
IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices;
CREATE TABLE dbo.CompanyServices
(
serviceid INT NOT NULL,
CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid)
);
GO
INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3);
CREATE TABLE dbo.EventLog
(
logid INT NOT NULL IDENTITY,
serviceid INT NOT NULL,
logtime DATETIME2(0) NOT NULL,
CONSTRAINT PK_EventLog PRIMARY KEY(logid)
);
GO
INSERT INTO dbo.EventLog(serviceid, logtime) VALUES
(1, '20180912 08:00:00'),
(1, '20180912 08:01:01'),
(1, '20180912 08:01:59'),
(1, '20180912 08:03:00'),
(1, '20180912 08:05:00'),
(1, '20180912 08:06:02'),
(2, '20180912 08:00:02'),
(2, '20180912 08:01:03'),
(2, '20180912 08:02:01'),
(2, '20180912 08:03:00'),
(2, '20180912 08:03:59'),
(2, '20180912 08:05:01'),
(2, '20180912 08:06:01'),
(3, '20180912 08:00:01'),
(3, '20180912 08:03:01'),
(3, '20180912 08:04:02'),
(3, '20180912 08:06:00');
SELECT * FROM dbo.EventLog;The EventLog table is currently populated with the following data:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
The special islands task is to identify the availability periods (serviced, starttime, endtime). One catch is that there’s no assurance that a service will report that it’s online exactly every minute; you’re supposed to tolerate an interval of up to, say, 66 seconds from the previous log entry and still consider it part of the same availability period (island). Beyond 66 seconds, the new log entry starts a new availability period. So, for the input sample data above, your solution is supposed to return the following result set (not necessarily in this order):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Notice, for instance, how log entry 5 starts a new island since the interval from the previous log entry is 120 seconds (> 66), whereas log entry 6 does not start a new island since the interval from the previous entry is 62 seconds (<= 66). Another catch is that Adam wanted the solution to be compatible with pre-SQL Server 2012 environments, which makes it a much harder challenge, since you cannot use window aggregate functions with a frame to compute running totals and offset window functions like LAG and LEAD. As usual, I suggest trying to solve the challenge yourself before looking at my solutions. Use the small sets of sample data to check the validity of your solutions. Use the following code to populate your tables with large sets of sample data (500 services, ~10M log entries to test the performance of your solutions):
Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high @low + 1) @low + rownum 1 AS n
FROM Nums
ORDER BY rownum;
GO
~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, seconds
@normdifferential AS INT = 3, seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing;The outputs that I’ll provide for the steps of my solutions will assume the small sets of sample data, and the performance numbers that I’ll provide will assume the large sets.
All of the solutions that I’ll present benefit from the following index:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);Good luck!
Solution 1 for SQL Server 2012+
Before I cover a solution that is compatible with pre-SQL Server 2012 environments, I’ll cover one that does require a minimum of SQL Server 2012. I’ll call it Solution 1.
The first step in the solution is to compute a flag called isstart that is 0 if the event does not start a new island, and 1 otherwise. This can be achieved by using the LAG function to obtain the log time of the previous event and checking if the time difference in seconds between the previous and current events is less than or equal to the allowed gap. Here’s the code implementing this step:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog;This code generates the following output:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Next, a simple running total of the isstart flag produces an island identifier (I’ll call it grp). Here’s the code implementing this step:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1;This code generates the following output:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Lastly, you group the rows by service ID and the island identifier and return the minimum and maximum log times as the start time and end time of each island. Here’s the complete solution:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp;This solution took 41 seconds to complete on my system, and produced the plan shown in Figure 1.
 Figure 1: Plan for Solution 1
Figure 1: Plan for Solution 1
As you can see, both window functions are computed based on index order, without the need for explicit sorting.
If you are using SQL Server 2016 or later, you can use the trick I cover here to enable the batch mode Window Aggregate operator by creating an empty filtered columnstore index, like so:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs
ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;The same solution now takes only 5 seconds to complete on my system, producing the plan shown in Figure 2.
 Figure 2: Plan for Solution 1 using the batch mode Window Aggregate operator
Figure 2: Plan for Solution 1 using the batch mode Window Aggregate operator
This is all great, but as mentioned, Adam was looking for a solution that can run on pre-2012 environments.
Before you continue, make sure you drop the columnstore index for cleanup:
DROP INDEX idx_cs ON dbo.EventLog;Solution 2 for pre-SQL Server 2012 environments
Unfortunately, prior to SQL Server 2012, we didn’t have support for offset window functions like LAG, nor did we have support for computing running totals with window aggregate functions with a frame. This means that you’ll need to work much harder in order to come up with a reasonable solution.
The trick I used is to turn each log entry into an artificial interval whose start time is the entry’s log time and whose end time is the entry’s log time plus the allowed gap. You can then treat the task as a classic interval packing task.
The first step in the solution computes the artificial interval delimiters, and row numbers marking the positions of each of the event kinds (counteach). Here’s the code implementing this step:
DECLARE @allowedgap AS INT = 66;
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog;This code generates the following output:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
The next step is to unpivot the intervals into a chronological sequence of start and end events, identified as event types 's' and 'e', respectively. Note that the choice of letters s and e is important ('s' > 'e'). This step computes row numbers marking the correct chronological order of both of the event kinds, which are now interleaved (countboth). In case one interval ends exactly where another starts, by positioning the start event before the end event, you’ll pack them together. Here’s the code implementing this step:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U;This code generates the following output:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
As mentioned, counteach marks the position of the event among only the events of the same kind, and countboth marks the position of the event among the combined, interleaved, events of both kinds.
The magic is then handled by the next step—computing the count of active intervals after every event based on counteach and countboth. The number of active intervals is the number of start events that happened so far minus the number of end events that happened so far. For start events, counteach tells you how many start events happened so far, and you can figure out how many ended so far by subtracting counteach from countboth. So, the complete expression telling you how many intervals are active is then:
counteach - (countboth - counteach)
For end events, counteach tells you how many end events happened so far, and you can figure out how many started so far by subtracting counteach from countboth. So, the complete expression telling you how many intervals are active is then:
(countboth - counteach) - counteach
Using the following CASE expression, you compute the countactive column based on the event type:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
ENDIn the same step you filter only events representing starts and ends of packed intervals. Starts of packed intervals have a type 's' and a countactive 1. Ends of packed intervals have a type 'e' and a countactive 0.
After filtering, you’re left with pairs of start-end events of packed intervals, but each pair is split into two rows—one for the start event and another for the end event. Therefore, the same step computes pair identifier by using row numbers, with the formula (rownum - 1) / 2 + 1.
Here’s the code implementing this step:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0);This code generates the following output:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
The last step pivots the pairs of events into a row per interval, and subtracts the allowed gap from the end time to regenerate the correct event time. Here’s the complete solution’s code:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;This solution took 43 seconds to complete on my system and generated the plan shown in Figure 3.
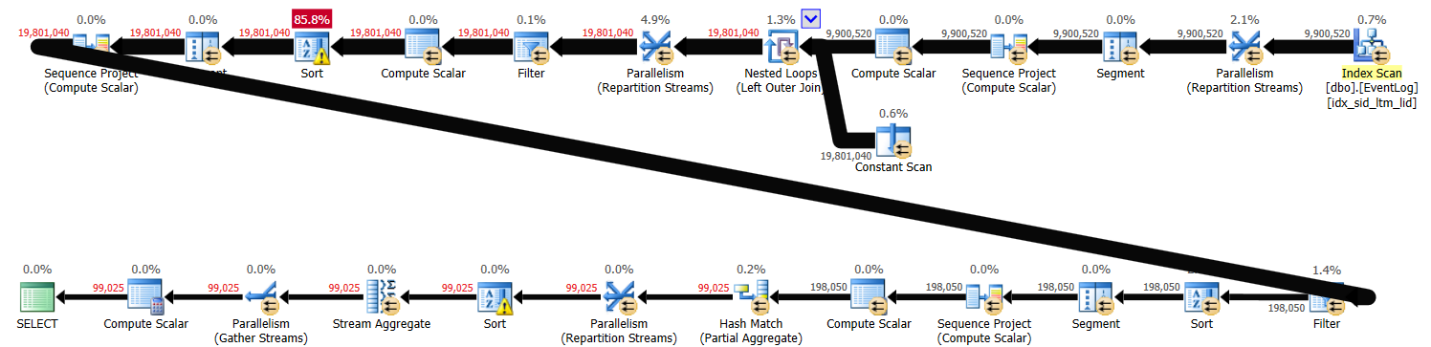 Figure 3: Plan for Solution 2
Figure 3: Plan for Solution 2
As you can see, the first row number calculation is computed based on index order, but the next two do involve explicit sorting. Still, the performance is not that bad considering there are about 10,000,000 rows involved.
Even though the point about this solution is to use a pre-SQL Server 2012 environment, just for fun, I tested its performance after creating a filtered columnstore index to see how it does with batch processing enabled:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs
ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;With batch processing enabled, this solution took 29 seconds to finish on my system, producing the plan shown in Figure 4.
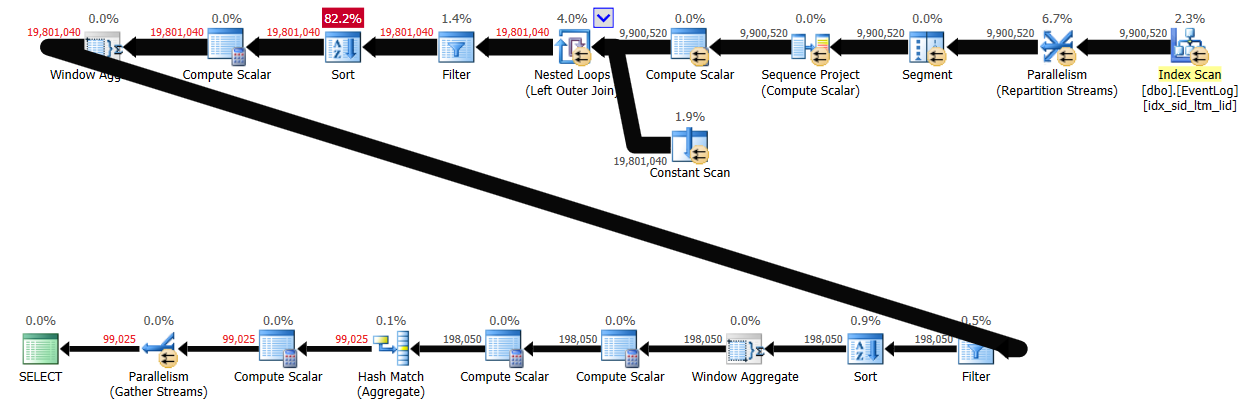
Conclusion
It’s natural that the more limited your environment is, the more challenging it becomes to solve querying tasks. Adam’s special Islands challenge is much easier to solve on newer versions of SQL Server than on older ones. But then you force yourself to use more creative techniques. So as an exercise, to improve your querying skills, you could tackle challenges that you’re already familiar with, but intentionally impose certain restrictions. You never know what kinds of interesting ideas you might stumble into!
25 thoughts on “Special Islands”
Comments are closed.
Here is my approach. It has 1/6 of the cost and 1/2 of the memory grant than posted in article.
Hi Peter,
That's pretty cool.
Indeed, the estimated subtree cost and memory grant are higher in my solution than yours, but on the system I'm currently using to test them, mine runs for 57 seconds and yours for 93 seconds. What are the execution times that you're getting for both solutions?
Cheers,
Itzik
I am getting 11.7 seconds for yours and 6.9 seconds for mine.
Laptop, 16GB, SSD, 8 GB dedicated to SQL Server.
That's a fast laptop my friend!
I came up with an alternate approach to Itzik's and Peter's using OUTER APPLY and TOP (1). On a dual-core VM running SQL 2016 Std, this approach has similar overall execution times to Itzik's and Peter's, but uses twice as much CPU because it appears to parallelize better. I suspect that on a quad-core VM, it would still use twice as much CPU but would execute in half the elapsed time.
It doesn't touch worktables or use much of a memory grant. I didn't do much work on this to attempt to optimize it – this was my first stab, and there is plenty of redundant calculation going on.
Here's another approach that combines both the APPLY TOP(1) approach with ROW_NUMBER and a VALUES clause to avoid duplicate calculations.
It got a little tricky to ensure that the final island for each serviceid got the correct results.
One last tweak – I wanted to see if I could take my final query and get it to parallelize. In order to accomplish that, I needed to do two things. First, I had to give the optimizer a chance to parallelize. An obvious way to parallelize is to compute the islands in a per serviceid fashion, and luckily we have the CompanyServices table to make that feasible. Second, I used the ENABLE_PARALLEL_PLAN_PREFERENCE hint to force the optimizer to select the parallel plan.
The following query has comparable overall CPU usage to my previous one, but will efficiently use more than one core and thus reduce the overall execution time.
DECLARE @allowedgap AS INT = 66; SELECT S.serviceid, R.starttime, R.endtime FROM dbo.CompanyServices AS S CROSS APPLY ( SELECT MIN(P.logtime) AS starttime, CASE WHEN COUNT(1) = 1 THEN ( SELECT MAX(EL.logtime) FROM dbo.EventLog AS EL WHERE S.serviceid = EL.serviceid ) ELSE MAX(P.logtime) END AS endtime FROM ( SELECT ELS.serviceid, ELS.logtime AS starttime, ELP.logtime AS prevendtime, ROW_NUMBER() OVER ( ORDER BY ELS.logtime ) AS RowN FROM dbo.EventLog AS ELS OUTER APPLY ( SELECT TOP(1) EL.logtime FROM dbo.EventLog AS EL WHERE ELS.serviceid = EL.serviceid AND ELS.logtime > EL.logtime ORDER BY EL.logtime DESC ) AS ELP WHERE S.serviceid = ELS.serviceid AND ( DATEADD(second, -1 * @allowedgap, ELS.logtime) > ELP.logtime OR ELP.logtime IS NULL ) ) AS I CROSS APPLY ( SELECT V.RowN, V.logtime FROM ( VALUES ( I.RowN, I.starttime), ( I.RowN - 1, I.prevendtime) ) AS V(RowN, logtime) WHERE V.logtime IS NOT NULL ) AS P GROUP BY P.RowN ) AS R OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Hi Toby,
This solution doesn't parse due to the expression:
AND S.logtime EL.logtime
It's missing an operator.
Also, EL.logtime cannot be bound in that scope.
Could you send the runnable version and also verify that it returns the correct result?
Thanks!
Itzik
Thanks for sending your solutions, Toby!
Here are the performance numbers that I got for the various pre-2012 supported solutions on my laptop (not as fast as peter's laptop!) :
solution run time sec net CPU time logical reads estimated subtree cost memory grant MB
————— ————- ————- ————– ———————– —————
Itzik pre-2012 50 70 24855 3255 1813
Peter 55 75 24855 219 10
Toby 1 doesn't parse
Toby 2 27 26 31583997 1717 1
Toby 3 13 48 31584697 1727 4
As you can see, your solutions are the fastest, they use less CPU and a lower memory grant than mine and Peters. They do perform more I/O, though.
Cheers,
Itzik
I have run the solutions a few times and occasionally I get better times for Itzik than mine. It seems to do with how many numbers of islands there are.
My first query got partially eaten when this comment system saw a less than sign and paired it with a greater than sign and eliminated all of the intervening SQL!
I have swapped all less than inequalities so that they are greater than inequalities, so hopefully the code will survive this time.
My approaches use more I/O because they do lots of single-record lookups using the idx_sid_ltm_lid index to identify the previous entry. However, it's pretty much all logical reads since the index fits in the cache, and even if the index didn't fit in the cache the locality of entries in the index should ensure that there aren't a huge number of physical reads. At that point, the real question is which uses more CPU – the I/O requests that navigate the index pages, or the in-memory calculations that perform the transforms to do the island identification.
Here is my first version, although I think the subsequent versions are definitely better.
Which version of SQL Server are you guys using?
I still get 7 and 12 seconds for mine and Itzik solutions, but had to kill Toby 3 after 7 minutes.
Microsoft SQL Server 2017 (RTM-CU10) (KB4342123) – 14.0.3037.1 (X64)
Jul 27 2018 09:40:27
Copyright (C) 2017 Microsoft Corporation
Developer Edition (64-bit) on Windows 10 Pro 10.0 (Build 17758: ) (Hypervisor)
I'm using Microsoft SQL Server 2017 (RTM-CU10) as well.
swePeso (without index idx_sid_ltm_lid) – 7 seconds
swePeso (with index idx_sid_ltm_lid) – 13 seconds
Itzik (without index idx_sid_ltm_lid) – 11 seconds
Itzik (with index idx_sid_ltm_lid) – 20 seconds
Toby 3 (without index idx_sid_ltm_lid) – Killed after 7 minutes
Toby 3 (with index idx_sid_ltm_lid) – 5 seconds
So it was the lack of index that made Toby's solution 3 so slow in your execution…
Interesting that some of the solutions actually run faster without the index!
I did notice yesterday that, at least on my test bed, Itzik’s solution was fairly index agnostic, whereas mine are very index dependent. Mine become O(n^2) in the absence of the index because the index is what permits each of the n SELECT TOP(1) queries to execute in log(n) time. Peter’s and Itzik’s solutions are streaming solutions, and so the absence of the index only results in an extra sort operation, which is O(n log(n)).
Out of curiosity, I did some testing under 2008 R2. This is on a VM on VSphere, dual-core, SQL Server has 5 GB of RAM. Note that for Toby 3, I had to replace the parallelization hint with QUERYTRACEON 8649.
Itzik w/out index: 55 sec CPU, 39 sec Elapsed
Itzik w/index: 42 sec CPU, 32 sec Elapsed
Peter w/out index: 71 sec CPU, 87 sec Elapsed
Peter w/index: 58 sec CPU, 77 sec Elapsed
Toby 3 w/out index: didn't even bother (probably days)
Toby 3 w/index: 25 sec CPU, 13 sec Elapsed
It looks like Peter's solution on 2008 R2 is making really heavy use of a Worktable. Here are the I/O results for the three approaches with the index present.
Itzik:
Table 'EventLog'. Scan count 1, logical reads 20862, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Peter:
Table 'EventLog'. Scan count 1, logical reads 20862, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 6037209, logical reads 22259529, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Toby 3:
Table 'CompanyServices'. Scan count 3, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'EventLog'. Scan count 9901450, logical reads 31582101, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Very interesting discussion. I have something as well, but don't expect miracles :-).
Solution:
Some system specs:
SQL Server 2014 Dev edition, 8gb ram, core i7 2600k (quad core) processor, Windows 7 Professional
Results returned by the query: 99459 (it differs whenever I build the table so I provide the number for this particular test)
no index (except pk) – 12-13 secs:
Table 'EventLog'. Scan count 9, logical reads 28304, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 75632, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 69824 ms, elapsed time = 12492 ms.
nc Index present – 25 secs:
Table 'EventLog'. Scan count 9, logical reads 24879, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 154088, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 40555 ms, elapsed time = 25087 ms.
Now for other solutions if you are interested:
No index:
Peter 12-13 secs:
Table 'EventLog'. Scan count 9, logical reads 28304, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 75784, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 70309 ms, elapsed time = 12732 ms.
Itzik 14-15 secs:
Table 'EventLog'. Scan count 9, logical reads 28312, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 127783, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 79106 ms, elapsed time = 14677 ms.
Toby 1: Stopped after 1 minute (relies heavily on the missing index)
Toby 2: Stopped after 1 minute (relies heavily on the missing index)
Toby 3: Stopped after 1 minute (relies heavily on the missing index) – note – I had to take out the hint (I believe it's a 2016 version feature)
With index
Peter – 24secs:
Table 'EventLog'. Scan count 9, logical reads 24879, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 173539, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 44287 ms, elapsed time = 24075 ms.
Itzik (ranging from 24-30secs, below is one of the best runs):
Table 'EventLog'. Scan count 9, logical reads 24879, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 105723, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 45914 ms, elapsed time = 24824 ms.
Toby 1 – 15 secs:
Table 'EventLog'. Scan count 19998439, logical reads 63913629, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 114755 ms, elapsed time = 15041 ms.
Toby 2 – 24-25 secs:
Table 'EventLog'. Scan count 9900515, logical reads 31582848, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 978, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 27253 ms, elapsed time = 24694 ms.
Toby 3 (no hint) – 26 – 27 secs:
Table 'EventLog'. Scan count 9901006, logical reads 31584393, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'CompanyServices'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 26801 ms, elapsed time = 26808 ms.
I ran each query multiple times and I tried to include the best times. I had to run Itzik's query with nc index the most times, because for some reason the time range was quite significant. For the most part the query would run into 30 secs, but I got 23-24 a couple times so I included one of those better runs. Toby's 1st solution was a winner on my set up. So I think Toby wins no matter how we slice it :) (at least with the index present)
Thanks for sharing this, Kamil. It's a pretty cool solution! I really like the way you emulate LAG/LEAD with rownum, rownum – 1, unpivot and pivot!
Kamil – if you're interested in running Toby 3 with parallelism forced on pre-2016 SP1 CU2 (which is when the hint was introduced), substitute "OPTION(QUERYTRACEON 8649)" – that is an undocumented trace flag that forces parallelism. I suspect your system is hyper-threaded (given the result with 115 secs of CPU in 15 secs elapsed). With that set up, I'm curious to see how Toby 3 will run with parallelism forced.
Indeed with this trace flag it's 7 seconds (99168 results at this time):
Toby 3:
Table 'CompanyServices'. Scan count 9, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'EventLog'. Scan count 9901321, logical reads 31585580, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 52915 ms, elapsed time = 7312 ms.
Very impressive. For my peace of mind, I have added a hint myself to the first subquery in my solution:
"(…)from dbo.EventLog WITH (INDEX(PK_EventLog))(…)"
and now it always runs in 12-13 secs :)
Similar times with Peter's and Itzik's solutions. Our next challenge is to find out why not using the nc index yields good results for those examples…
Thanks Itzik. Unpivot and pivot operators are really good tools we sometimes forget. I saw you used them both in your solution and it inspired me to do something with it.
Hey Toby, I have looked at your solution in more details and I came up with something like this, I borrowed a concept from yours with outer apply to get previous logtime and combined with part of mine with pivot/unpivot fun:
It runs a bit slower than the 3rd one, but it's very competitive (on my system).
Table 'EventLog'. Scan count 9900062, logical reads 31606234, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 70358 ms, elapsed time = 10466 ms.
I wonder if you would get similar results, it seems we all have different depending on the setup..
Hey Peter,
On my laptop I get the following stats for this solution:
Elapsed time: 45 sec, CPU time: 61 sec, logical reads: 24855.
Cheers,
Itzik