
When DISTINCT <> GROUP BY
I wrote a post recently about DISTINCT and GROUP BY. It was a comparison that showed that GROUP BY is generally a better option than DISTINCT. It's on a different site, but be sure to come back to sqlperformance.com right after..
One of the query comparisons that I showed in that post was between a GROUP BY and DISTINCT for a sub-query, showing that the DISTINCT is a lot slower, because it has to fetch the Product Name for every row in the Sales table, rather than just for each different ProductID. This is quite plain from the query plans, where you can see that in the first query, the Aggregate operates on data from just one table, rather than on the results of the join. Oh, and both queries give the same 266 rows.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;
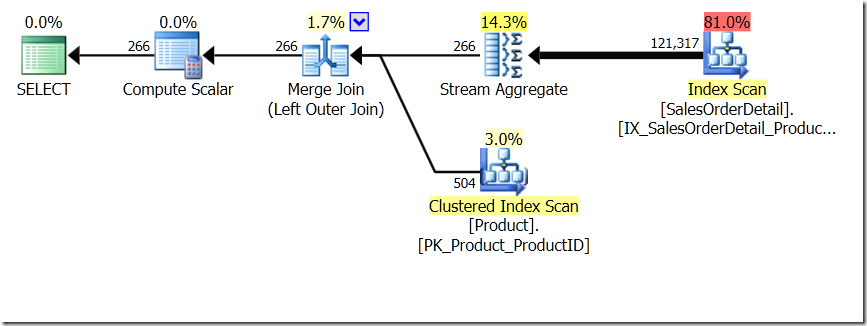
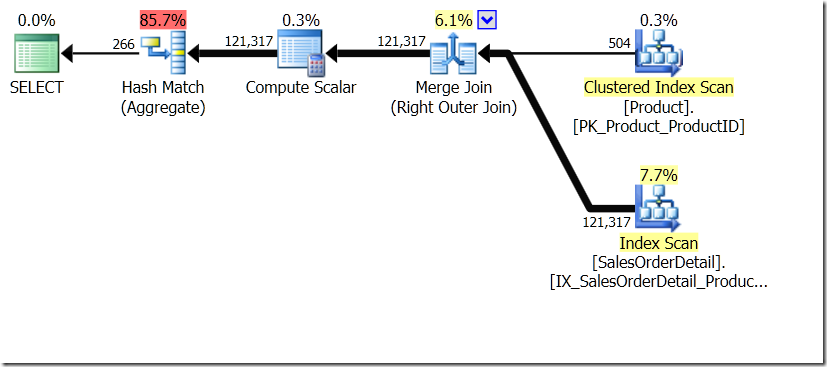
Now, it's been pointed out, including by Adam Machanic (@adammachanic) in a tweet referencing Aaron's post about GROUP BY v DISTINCT that the two queries are essentially different, that one is actually asking for the set of distinct combinations on the results of the sub-query, rather than running the sub-query across the distinct values that are passed in. It's what we see in the plan, and is the reason why the performance is so different.
The thing is that we would all assume that the results are going to be identical.
But that's an assumption, and isn't a good one.
I'm going to imagine for a moment that the Query Optimizer has come up with a different plan. I used hints for this, but as you would know, the Query Optimizer can choose to create plans in all kinds of shapes for all kinds of reasons.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);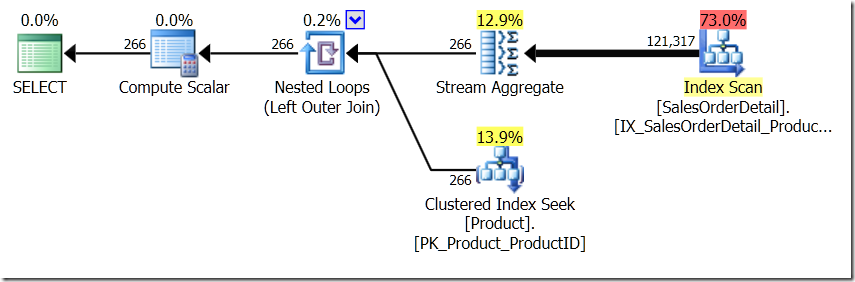
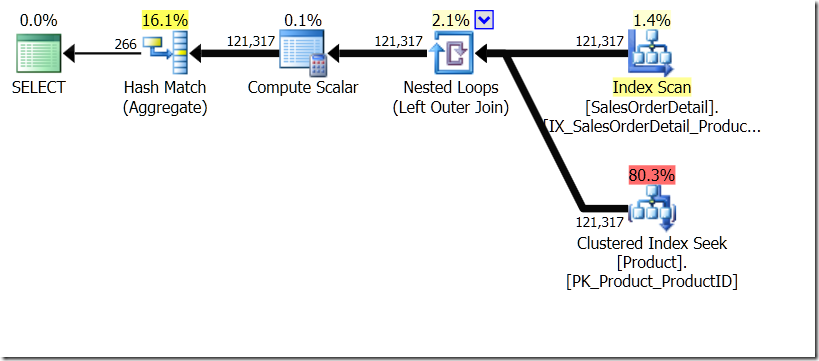
In this situation, we either do 266 Seeks into the Product table, one for each different ProductID that we're interested in, or 121,317 Seeks. So if we are thinking about a particular ProductID, we know that we're going to get a single Name back from the first one. And we assume that we're going to get a single Name back for that ProductID, even if we have to ask for it hundred times. We just assume we're going to get the same results back.
But what if we don't?
This sounds like a isolation level thing, so let's use NOLOCK when we hit the Product table. And let's run (in a different window) a script the changes the text in the Name columns. I'm going to do it over and over, to try to get some of the changes in between my query.
update Production.Product
set Name = cast(newid() as varchar(36));
go 1000Now, my results are different. The plans are the same (except for the number of rows coming out of the Hash Aggregate in the second query), but my results are different.
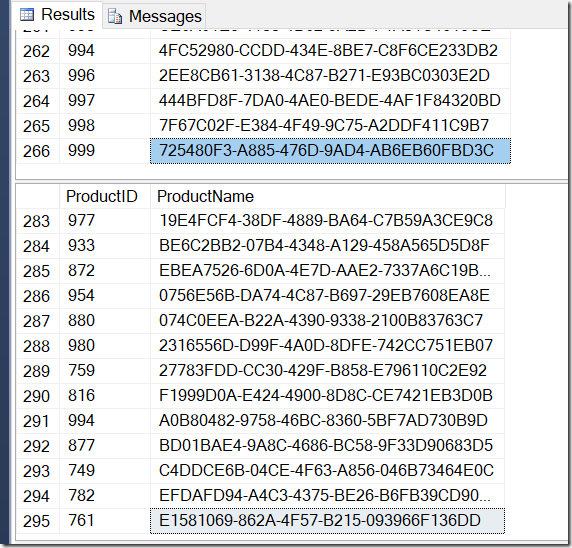
Sure enough, I have more rows with DISTINCT, because it finds different Name values for the same ProductID. And I don't necessarily have 295 rows. Another I run it, I might get 273, or 300, or possibly, 121,317.
It's not hard to find an example of a ProductID that shows multiple Name values, confirming what's going on.

Clearly, to ensure that we don't see these rows in the results, we would either need to NOT use DISTINCT, or else use a stricter isolation level.
The thing is that although I mentioned using NOLOCK for this example, I didn't need to. This situation occurs even with READ COMMITTED, which is the default isolation level on many SQL Server systems.
You see, we need the REPEATABLE READ isolation level to avoid this situation, to hold the locks on each row once it has been read. Otherwise, a separate thread might change the data, as we saw.
But… I can't show you that the results are fixed, because I couldn't manage to avoid a deadlock on the query.
So let's change the conditions, by making sure that our other query is less of a problem. Instead of updating the whole table at a time (which is far less likely in the real world anyway), let's just update a single row at a time.
declare @id int = 1;
declare @maxid int = (select count(*) from Production.Product);
while (@id < @maxid)
begin
with p as (select *, row_number() over (order by ProductID) as rn from Production.Product)
update p
set Name = cast(newid() as varchar(36))
where rn = @id;
set @id += 1;
end
go 100Now, we can still demonstrate the problem under a lesser isolation level, such as READ COMMITTED or READ UNCOMMITTED (although you may need to run the query multiple times if you get 266 the first time, because the chance of updating a row during the query is less), and now we can demonstrate that REPEATABLE READ fixes it (no matter how many times we run the query).
REPEATABLE READ does what it says on the tin. Once you read a row within a transaction, it's locked to make sure you can repeat the read and get the same results. The lesser isolation levels don't take out those locks until you try to change the data. If your query plan never needs to repeat a read (as is the case with the shape of our GROUP BY plans), then you're not going to need REPEATABLE READ.
Arguably, we should always use the higher isolation levels, such as REPEATABLE READ or SERIALIZABLE, but it all comes down to figuring out what our systems need. These levels can introduce unwanted locking, and SNAPSHOT isolation levels require versioning that comes with a price as well. For me, I think it's a trade-off. If I'm asking for a query that could be affected by changing data, then I might need to raise the isolation level for a while.
Ideally, you simply don't update data that has just been read and might need to be read again during the query, so that you don't need REPEATABLE READ. But it's definitely worth understanding what can happen, and recognising that this is the kind of scenario when DISTINCT and GROUP BY might not be the same.
