
Performance Myths : Clustered vs. Non-Clustered Indexes

I was recently scolded for suggesting that, in some cases, a non-clustered index will perform better for a particular query than the clustered index. This person stated that the clustered index is always best because it is always covering by definition, and that any non-clustered index with some or all of the same key columns was always redundant.
I will happily agree that the clustered index is always covering (and to avoid any ambiguity here, we're going to stick to disk-based tables with traditional B-tree indexes).
 I disagree, though, that a clustered index is always faster than a non-clustered index. I also disagree that it is always redundant to create a non-clustered index or unique constraint consisting of the same (or some of the same) columns in the clustering key.
I disagree, though, that a clustered index is always faster than a non-clustered index. I also disagree that it is always redundant to create a non-clustered index or unique constraint consisting of the same (or some of the same) columns in the clustering key.
Let's take this example, Warehouse.StockItemTransactions, from WideWorldImporters. The clustered index is implemented through a primary key on just the StockItemTransactionID column (pretty typical when you have some kind of surrogate ID generated by an IDENTITY or a SEQUENCE).
It's a pretty common thing to require a count of the whole table (though in many cases there are better ways). This can be for casual inspection or as part of a pagination procedure. Most people will do it this way:
SELECT COUNT(*)
FROM Warehouse.StockItemTransactions;With the current schema, this will use a non-clustered index:
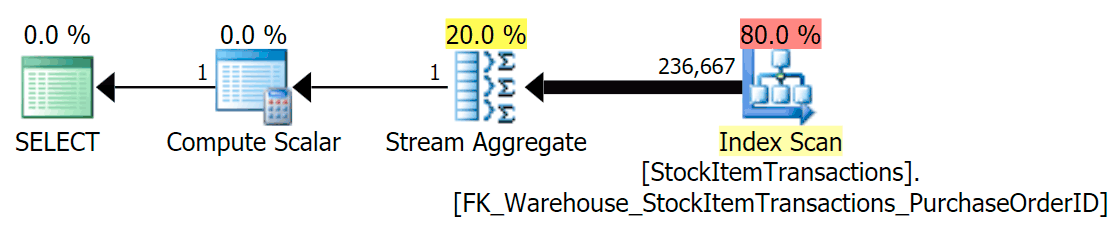
We know that the non-clustered index does not contain all of the columns in the clustered index. The count operation only needs to be sure that all rows are included, without caring about which columns are present, so SQL Server will usually choose the index with the smallest number of pages (in this case, the index chosen has ~414 pages).
Now let's run the query again, this time comparing it to a hinted query that forces the use of the clustered index.
SELECT COUNT(*)
FROM Warehouse.StockItemTransactions;
SELECT COUNT(*) /* with hint */
FROM Warehouse.StockItemTransactions WITH (INDEX(1));We get an almost identical plan shape, but we can see a huge difference in reads (414 for the chosen index vs. 1,982 for the clustered index):
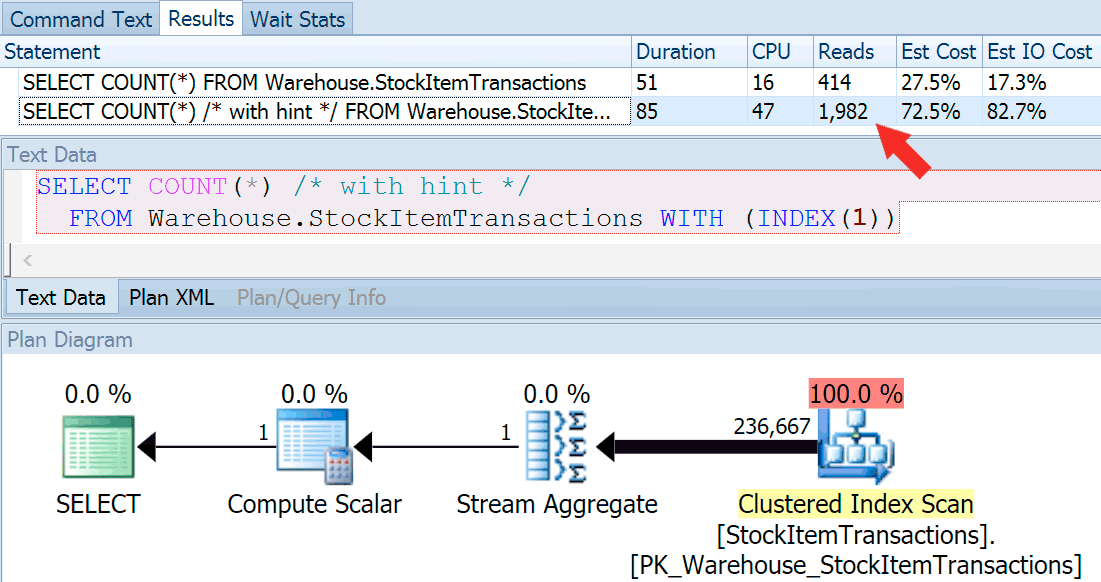
Duration is slightly higher for the clustered index, but the difference is negligible when we're dealing with a small amount of cached data on a fast disk. That discrepancy would be much more pronounced with more data, on a slow disk, or on a system with memory pressure.
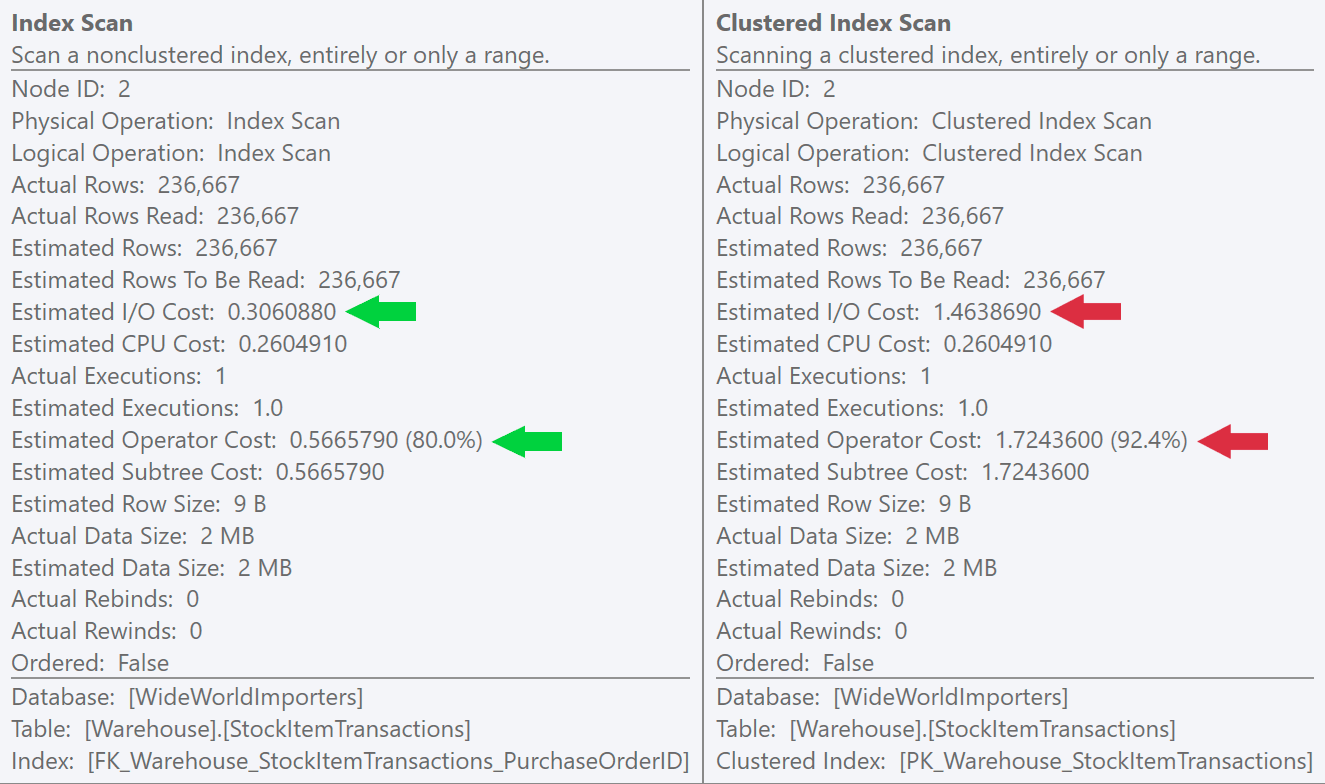
If we look at the tooltips for the scan operations, we can see that while the number of rows and estimated CPU costs are identical, the big difference comes from the estimated I/O cost (because SQL Server knows that there are more pages in the clustered index than the non-clustered index):
We can see this difference even more clearly if we create a new, unique index on just the ID column (making it "redundant" with the clustered index, right?):
CREATE UNIQUE INDEX NewUniqueNCIIndex
ON Warehouse.StockItemTransactions(StockItemTransactionID);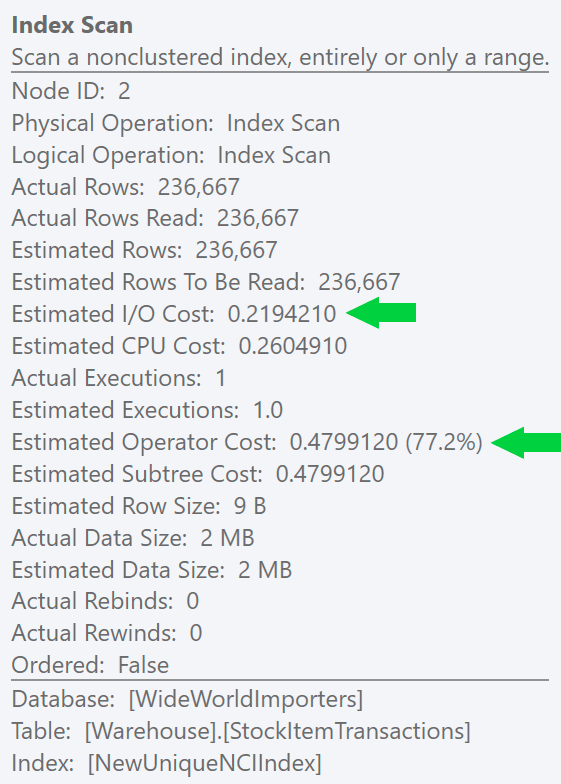 Running a similar query with an explicit index hint produces the same plan shape, but an even lower estimated I/O cost (and even lower durations) – see image at right. And if you run the original query without the hint, you'll see that SQL Server now chooses this index too.
Running a similar query with an explicit index hint produces the same plan shape, but an even lower estimated I/O cost (and even lower durations) – see image at right. And if you run the original query without the hint, you'll see that SQL Server now chooses this index too.
It might seem obvious, but a lot of people would believe that the clustered index is the best choice here. SQL Server is almost always going to heavily favor whatever method will provide the cheapest way to perform all of the I/O, and in the case of a full scan, that's going to be the "skinniest" index. This can also happen with both types of seeks (singleton and range scans), at least when the index is covering.
Now, as always, that does not in any way mean that you should go and create additional indexes on all of your tables to satisfy count queries. Not only is that an inefficient way to check table size (again, see this article), but an index to support that would have to mean that you're running that query more often than you're updating the data. Remember that every index requires space on disk, space on memory, and all of the writes against the table must also touch every index (filtered indexes aside).
Summary
I could come up with many other examples that show when a non-clustered can be useful and worth the cost of maintenance, even when duplicating the key column(s) of the clustered index. Non-clustered indexes can be created with the same key columns but in a different key order, or with different ASC/DESC on the columns themselves to better support an alternate presentation order. You can also have non-clustered indexes that only carry a small subset of the rows through the use of a filter. Finally, if you can satisfy your most common queries with skinnier, non-clustered indexes, that is better for memory consumption as well.
But really, my point of this series is merely to show a counter-example that illustrates the folly of making blanket statements like this one. I'll leave you with an explanation from Paul White who, in a DBA.SE answer, explains why such a non-clustered index can in fact perform much better than a clustered index. This is true even when both use either type of seek:
16 thoughts on “Performance Myths : Clustered vs. Non-Clustered Indexes”
Comments are closed.

I recently did something like this in a series of tables that include large (but not quite large enough to be off page) text fields. To satisfy analysis queries I created a non-clustered index with the same key as the clustered index and included all columns except the varchar(xxxx) columns.
Maybe the same effect could have been achieved by forcing the text to be stored off row, but we decided for the sake of the small percent of queries which want to search through the text that would not be desirable.
Excellent article, Aaron, especially this part:-
"I disagree, though, that a clustered index is always faster than a non-clustered index. I also disagree that it is always redundant to create a non-clustered index or unique constraint consisting of the same (or some of the same) columns in the clustering key."
I wish more people stated both of these more often. There are SO MANY times when they're both not true, and, as usual, the "it depends" answer applies to how to go about indexing.
I find the biggest problem is that many people seem to just want a silver bullet, and be told what to do rather than thinking about their problem and working out what the best solution is; which results in "rules" that are then abused.
Exactly for COUNT(*) we have much more powerfull way – use system tables.
You don't need to think up a query self – simly copy query (use profiler) from standard DB-Report in SSMS: "Disk Usage by Table".
This Report (query) calculates row counts for all tables in DB in millyseconds!!!
In all our projects we everytime create table_stat VIEW with this query and than:
SELECT row_count FROM table_stat WHERE table_name='MyTable'
Of course, and I talk about this here:
This was just an example. The concept remains true for all kinds of other queries, including COUNT with a where clause (where you can't create a filtered index for every possible combination of where clauses), and queries that aren't looking for COUNT at all…
On one of my tables (used for scheduling ServerJobs) I have a nonclustered index that contains all columns of the table (as the clustered).
This makes sense, since this index is filtered for jobs that are not started yet and the application does a SELECT * FROM ServerJobs WHERE … Without the filtered index it would have to scan the whole table every x seconds, and when the filtered index would contain only the ID column it would need to do Key Lookups. Since there are typically only very few not started jobs, this index would be usually very small (only one data page) -> even such strange constructs can be the best solution in some situations.
We had a case where we had a temp table with just 3 columns and we had a covering nonclustered index. First we changed it to a clustered index; then restored the nonclustered index so we had two identical indexes and let SQL Server choose which one to use. Then we got rid of the clustered index so we are back to where we started and not sure if that is best or not. But never mind, here come memory-optimized tables.
Any examples of differences if the table has a clustered index already vs a heap for the speed of non-clustered indexes?
I can't imagine anyone saying that a clustered index will "always" beat a nonclustered for any given query. Obviously creating additional tables that exactly match the query(ies) — which is effectively what covering nonclus indexes are — can save some overhead for that specific query.
However, far too many people believe the egregious myth that an identity column is (almost) "always" the best clustering index, and all other needs should be handled by covering nonclustered indexes. Just automatically slap an identity column on the table and all's good, since that column is "narrow, ever-ascending, etc.". That's just false and most often creates vastly more overhead *overall*. If you tune one query at a time, you'll inevitably end up with vast amounts of covering indexes, and that's often not the best choice.
" people seem to just want a silver bullet, and be told what to do rather than thinking about their problem and working out what the best solution is"
This has been my observation as well and seems to have only got worse over the years. School is one big multiple choice test and Google will tell you which green thingy to push. Critical thinking and problem solving are esoteric art forms now.
I really look forward to this series. Thanks Aaron.
> I can't imagine anyone saying that a clustered index will "always" beat a nonclustered for any given query.
I couldn't either. Until it happened.
When you have an clustered index and identical covering nonclustered index, SQL Server will (always) use the NCI, since it is narrower (contains e.g. 5 columns while the clustered index contains all 50 columns). HEAPs (that is what you get when you have no clustered index) are not bad – as long you do not update columns. If you do this, you could have forwarding records which will kill performance.
For insert-only tables a heap could be ok, but when you have to create nonclustered indexes on it – why do you not just create the most used index as clustered (or at least the index starting with the ID / orderdate / insertdate column)?
And it's not just clustered indexes in the mix. Seemingly overlapping/redundant indexes can be useful.
Index 1 on col A
Index 2 on col A include (Things)
If a query is only selective on A, and not selecting the included Things, the optimiser rightfully chooses Index 1.
It's only recently I spotted this.
I think in this case the "devil is in the detail". As you know with SQL the column projection is quite an important [hidden] factor. Have you tried the above queries by specifying which column the count() function should operate on? by specifying asterisk [all], SQL assumes you want to perform a count across the whole breadth of the table which in effect will cause it to read the full data row in turn producing more I/O. If you specify a single explicit column I think you will notice that it will then choose an index based on the column choice. e.g. if you were to choose a column not present in the unique index you will notice a key lookup take place further increasing the I/O.
when you are selecting a COUNT(*) the SQL Server will use the smallest non filtered index.
When you query COUNT() then it uses an index scan on the smallest index, which includes this column (except it is an non nullable column)
Counting rows in a table isn't a very good real world use case. I have never seen row counting in any real world production application. I have used row counting many times manually but all those times added together is about nothing as far as a server is concerned. And as others have pointed out, table statistics provide the ultimate speedy way to get row counts. Plus, even if it is slower, it still such a trivial operation compared with queries with a bunch of joins that it just doesn't matter. You're not making a good argument because your only example isn't realistic.
Stop thinking about counting rows. This is an obvious example because it requires reading all the rows, and it demonstrates the exact same problem that will happen in *any* scenario where you have to read a lot of rows. The non-clustered index will be faster, and will be better as long as it provides all the columns necessary for output, order, filtering, etc. And a clustered index will be no faster for things like point lookups, again, provided the non-clustered index with the same key covers and supports other query semantics. Joins as well. Basically anything where not all the columns in the table are needed, the clustered index is (almost always) wider, and certainly never skinnier, therefore requires more reads to support the same types of queries. Surely you can see beyond "count(*)" to see how this applies to many other types of queries where the optimizer can choose between a clustered index and a non-clustered index with the same key.