
Minimizing impact of widening an IDENTITY column – part 4
[ Part 1 | Part 2 | Part 3 | Part 4 ]
In part 3 of this series, I showed two workarounds to avoid widening an IDENTITY column – one that simply buys you time, and another that abandons IDENTITY altogether. The former prevents you from having to deal with external dependencies such as foreign keys, but the latter still doesn't address that issue. In this post, I wanted to detail the approach I would take if I absolutely needed to move to bigint, needed to minimize downtime, and had plenty of time for planning.
Because of all of the potential blockers and the need for minimal disruption, the approach might be seen as a little complex, and it only becomes more so if additional exotic features are being used (say, partitioning, In-Memory OLTP, or replication).
At a very high level, the approach is to create a set of shadow tables, where all the inserts are directed to a new copy of the table (with the larger data type), and the existence of the two sets of tables is as transparent as possible to the application and its users.
At a more granular level, the set of steps would be as follows:
- Create shadow copies of the tables, with the right data types.
- Alter the stored procedures (or ad hoc code) to use bigint for parameters. (This may require modification beyond the parameter list, such as local variables, temp tables, etc., but this is not the case here.)
- Rename the old tables, and create views with those names that union the old and new tables.
- Those views will have instead of triggers to properly direct DML operations to the appropriate table(s), so that data can still be modified during the migration.
- This also requires SCHEMABINDING to be dropped from any indexed views, existing views to have unions between new and old tables, and procedures relying on SCOPE_IDENTITY() to be modified.
- Migrate the old data to the new tables in chunks.
- Clean up, consisting of:
- Dropping the temporary views (which will drop the INSTEAD OF triggers).
- Renaming the new tables back to the original names.
- Fixing the stored procedures to revert to SCOPE_IDENTITY().
- Dropping the old, now-empty tables.
- Putting SCHEMABINDING back on indexed views and re-creating clustered indexes.
You can probably avoid much of the views and triggers if you can control all data access through stored procedures, but since that scenario is rare (and impossible to trust 100%), I'm going to show the harder route.
Initial Schema
In an effort to keep this approach as simple as possible, while still addressing many of the blockers I mentioned earlier in the series, let's assume we have this schema:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO
So a simple personnel table, with a clustered IDENTITY column, a non-clustered index, a computed column based on the IDENTITY column, an indexed view, and a separate HR/dirt table that has a foreign key back to the personnel table (I am not necessarily encouraging that design, just using it for this example). These are all things that make this problem more complicated than it would be if we had a standalone, independent table.
With that schema in place, we probably have some stored procedures that do things like CRUD. These are more for documentation's sake than anything; I'm going to make changes to the underlying schema such that changing these procedures should be minimal. This is to simulate the fact that changing ad hoc SQL from your applications may not be possible, and may not be necessary (well, as long as you're not using an ORM that can detect table vs. view).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO
Now, let's add 5 rows of data to the original tables:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best';
EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2';
EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out';
EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on';
EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Step 1 – new tables
Here we'll create a new pair of tables, mirroring the originals except for the data type of the EmployeeID columns, the initial seed for the IDENTITY column, and a temporary suffix on the names:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
);
Step 2 – fix procedure parameters
The procedures here (and potentially your ad hoc code, unless it's already using the larger integer type) will need a very minor change so that in the future they will be able to accept EmployeeID values beyond the upper bounds of an integer. While you could argue that if you're going to alter these procedures, you could simply point them at the new tables, I'm trying to make the case that you can achieve the ultimate goal with *minimal* intrusion into the existing, permanent code.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO
Step 3 – views and triggers
Unfortunately, this can't *all* be done silently. We can do most of the operations in parallel and without affecting concurrent usage, but because of the SCHEMABINDING, the indexed view has to be altered and the index later re-created.
This is true for any other objects that use SCHEMABINDING and reference either of our tables. I recommend changing it to be a non-indexed view at the beginning of the operation, and just rebuilding the index once after all the data has been migrated, rather than multiple times in the process (since tables will be renamed multiple times). In fact what I'm going to do is change the view to union the new and old versions of the Employees table for the duration of the process.
One other thing we need to do is to change the Employee_Add stored procedure to use @@IDENTITY instead of SCOPE_IDENTITY(), temporarily. This is because the INSTEAD OF trigger that will handle new updates to "Employees" will not have visibility of the SCOPE_IDENTITY() value. This, of course, assumes that the tables don't have after triggers that will affect @@IDENTITY. Hopefully you can either change these queries inside a stored procedure (where you could simply point the INSERT at the new table), or your application code does not need to rely on SCOPE_IDENTITY() in the first place.
We're going to do this under SERIALIZABLE so that no transactions try to sneak in while the objects are in flux. This is a set of largely metadata-only operations, so it should be quick.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION;
Step 4 – Migrate old data to new table
We're going to migrate data in chunks to minimize the impact on both concurrency and the transaction log, borrowing the basic technique from an old post of mine, "Break large delete operations into chunks." We're going to execute these batches in SERIALIZABLE as well, which means you'll want to be careful with batch size, and I've left out error handling for brevity.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches;
Results:
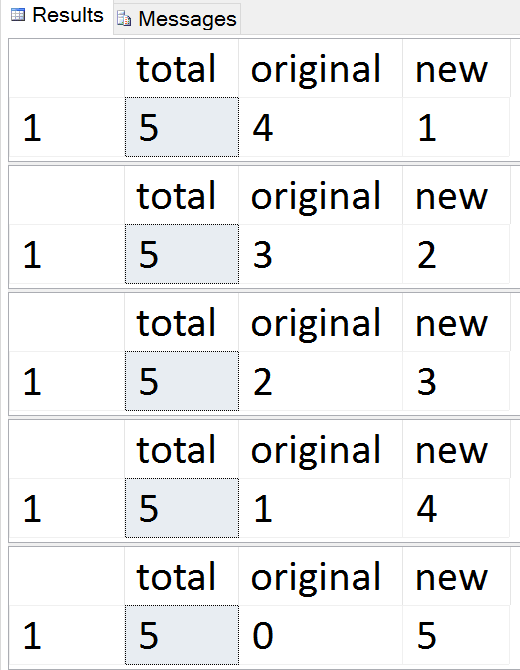 See the rows migrate one by one
See the rows migrate one by one
At any time during that sequence, you can test inserts, updates, and deletes, and they should be handled appropriately. Once the migration is complete, you can move on to the remainder of the process.
Step 5 – Clean Up
A series of steps is required to clean up the objects that were created temporarily and to restore Employees / EmployeeFile as proper, first class citizens. Much of these commands are simply metadata operations – with the exception of creating the clustered index on the indexed view, they should all be instantaneous.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
At this point, everything should be back to normal operation, though you may want to consider typical maintenance activities following major schema changes, such as updating statistics, rebuilding indexes, or evicting plans from the cache.
Conclusion
This is a pretty complex solution to what should be a simple problem. I hope that at some point SQL Server makes it possible to do things like add/remove the IDENTITY property, rebuild indexes with new target data types, and alter columns on both sides of a relationship without sacrificing the relationship. In the meantime, I'd be interested to hear if either this solution helps you, or if you have a different approach.
Big shout-out to James Lupolt (@jlupoltsql) for helping sanity check my approach, and put it to the ultimate test on one of his own, real tables. (It went well. Thanks James!)
—
3 thoughts on “Minimizing impact of widening an IDENTITY column – part 4”
Comments are closed.

I had looked at something like this after the earlier article, but found that it did not work for me.
I created the "Original" table (MyTable1), created create, select, update, and delete procs that worked fine, and inserted a few K rows. Fairly simple table, only Identity int, a varchar (100) data element, and inserted date (defaulted to getutcdate). I believe that's what caused part of the problem.
I created the "New" table (MyTable2), with the correct data types (including the default), and modified each of the four procs to use bigint.
Scripted the rename of the original table (to MyTable1_Old) and the create view (MyTable1) as a union of the two, ran it…. simple select went fine, TSQL inserts still good.
Then I set the batch record move process running and went to see how much performance impact it would have on inserts, surprisingly little. The problem came with running the UPDATE and DELETE stored procedures.
When I ran the UPDATE, I got an error: Update or insert of view or function 'dbo.MyTable1' failed because it contains a derived or constant field.
The delete proc gave a different error: View 'dbo.MyTable1' is not updatable because the definition contains a UNION operator.
Can you provide any suggestions as to how those issues could be addressed? I am working on SQL 2012 Developer edition, if that makes any difference.
Thanks for your time and interest.
Does your view use UNION ALL, like my example, or UNION?
I'd have to see your entire repro to understand why it's not working for you. A workaround could potentially be to have your stored procedure test the ID value, and if it's <= upper bound of int, update old table, otherwise update new table. Or just update both tables. A
Thanks for the response. Looking back, I think the problem with the DELETE probably WAS the use of UNION instead of UNION ALL. I think that getting around the problem of the default field in the base tables would probable have to be handled through use of a variable in the INSTEAD OF UPDATE trigger, unless I wanted to change app (stored procedure) code or modify the table definition. I will try posting the scripts here in the next couple days.