
SQL Server 2016 Temporal Table Query Plan Behaviour
 Isn’t it great to have a new version of SQL Server available? This is something that only happens every couple of years, and this month we saw one reach General Availability. (Ok, I know we get a new version of SQL Database in Azure almost continuously, but I count this as different.) Acknowledging this new release, this month’s T-SQL Tuesday (hosted by Michael Swart – @mjswart) is on the topic of all things SQL Server 2016!
Isn’t it great to have a new version of SQL Server available? This is something that only happens every couple of years, and this month we saw one reach General Availability. (Ok, I know we get a new version of SQL Database in Azure almost continuously, but I count this as different.) Acknowledging this new release, this month’s T-SQL Tuesday (hosted by Michael Swart – @mjswart) is on the topic of all things SQL Server 2016!
So today I want to look at SQL 2016’s Temporal Tables feature, and have a look at some query plan situations you could end up seeing. I love Temporal Tables, but have come across a bit of a gotcha that you might want to be aware of.
Now, despite the fact that SQL Server 2016 is now in RTM, I’m using AdventureWorks2016CTP3, which you can download here – but don’t just download AdventureWorks2016CTP3.bak, also grab SQLServer2016CTP3Samples.zip from the same site.
You see, in the Samples archive, there are some useful scripts for trying out new features, including some for Temporal Tables. It’s win-win – you get to try a bunch of new features, and I don’t have to repeat so much script in this post. Anyway, go and grab the two scripts about Temporal Tables, running AW 2016 CTP3 Temporal Setup.sql, followed by Temporal System-Versioning Sample.sql.
These scripts set up temporal versions of a few tables, including HumanResources.Employee. It creates HumanResources.Employee_Temporal (although, technically, it could’ve been called anything). At the end of the CREATE TABLE statement, this bit appears, adding two hidden columns to use to indicate when the row is valid, and indicating that a table should be created called HumanResources.Employee_Temporal_History to store the old versions.
...
ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL,
ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL,
PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
) WITH (SYSTEM_VERSIONING = ON
(HISTORY_TABLE = [HumanResources].[Employee_Temporal_History])
);
What I want to explore in this post is what happens with query plans when the history is used.
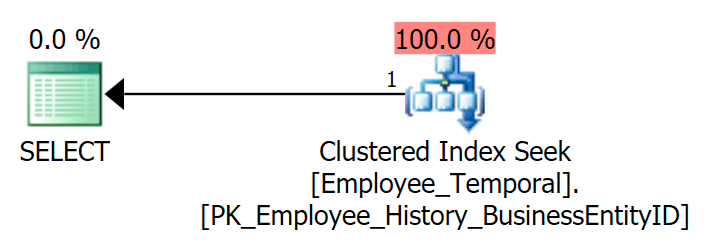
If I query the table to see the latest row for a particular BusinessEntityID, I get a Clustered Index Seek, as expected.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo
FROM HumanResources.Employee_Temporal AS e
WHERE e.BusinessEntityID = 4;
I’m sure I could query this table using other indexes, if it had any. But in this case, it doesn’t. Let’s create one.
CREATE UNIQUE INDEX rf_ix_Login
on HumanResources.Employee_Temporal(LoginID);
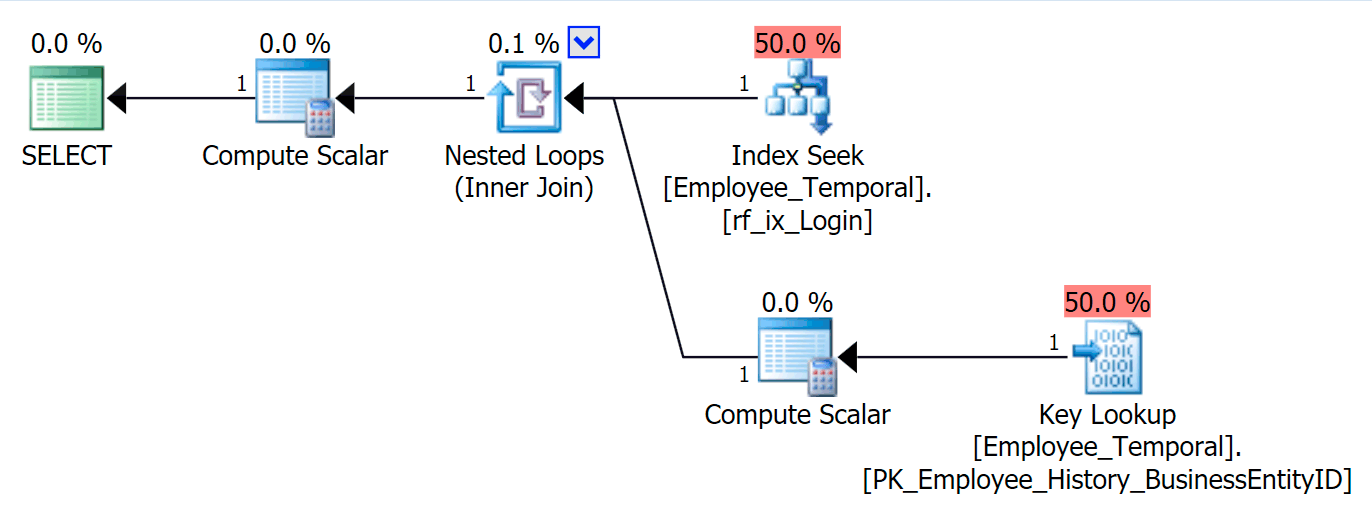
Now I can query the table by LoginID, and will see a Key Lookup if I ask for columns other than Loginid or BusinessEntityID. None of this is surprising.
SELECT * FROM HumanResources.Employee_Temporal e
WHERE e.LoginID = N'adventure-works\rob0';
Let’s use SQL Server Management Studio for a minute, and have a look at how this table looks in Object Explorer.

We can see the History table mentioned under HumanResources.Employee_Temporal, and the columns and indexes from both the table itself and the history table. But while the indexes on the proper table are the Primary Key (on BusinessEntityID) and the index I had just created, the History table doesn’t have matching indexes.
The index on the history table is on ValidTo and ValidFrom. We can right-click the index and select Properties, and we see this dialog:
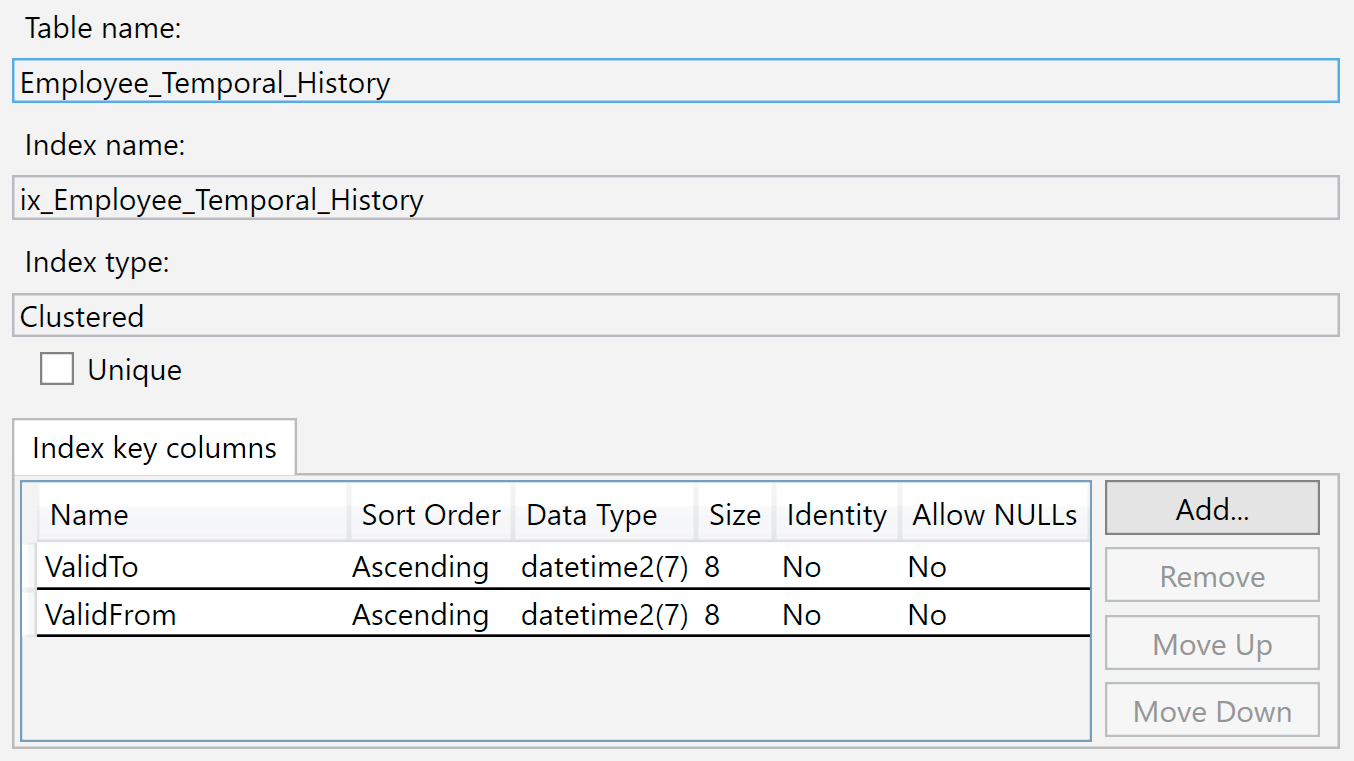
A new row is inserted into this History table when it is no longer valid in the main table, because it has just been deleted or changed. The values in the ValidTo column are naturally populated with the current time, so ValidTo acts as an ascending key, like an identity column, so that new inserts appear at the end of the b-tree structure.
But how does this perform when you want to query the table?
If we want to query our table for what was current at a particular point in time, then we should use a query structure such as:
SELECT * FROM HumanResources.Employee_Temporal
FOR SYSTEM_TIME AS OF '20160612 11:22';
This query needs to concatenate the appropriate rows from the main table with the appropriate rows from the history table.
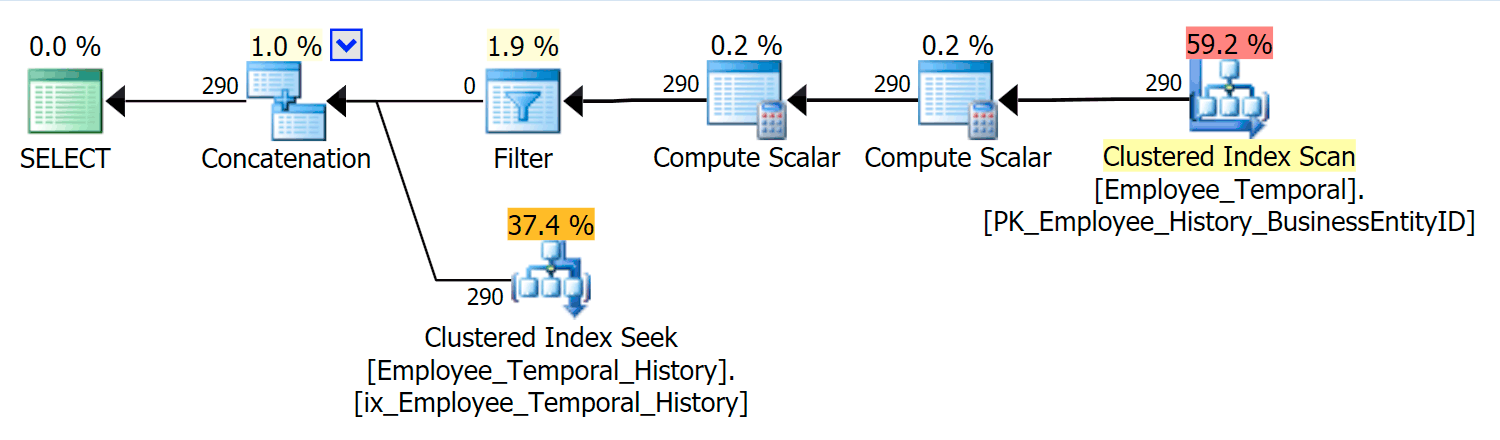
In this scenario, the rows that were valid for the moment I picked were all from the history table, but nonetheless, we see a Clustered Index Scan against the main table, which was filtered by a Filter operator. The predicate of this filter is:
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000'
AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
Let’s revisit this in a moment.
The Clustered Index Seek on the History table must clearly be leveraging a Seek Predicate on ValidTo. The Start of the Seek’s Range Scan is HumanResources.Employee_Temporal_History.ValidTo > Scalar Operator('2016-06-12 11:22:00'), but there is no End, because every row that has a ValidTo after the time we care about is a candidate row, and must be tested for an appropriate ValidFrom value by the Residual Predicate, which is HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00'.
Now, intervals are hard to index for; that’s a known thing that has been discussed on many blogs. Most effective solutions consider creative ways to write queries, but no such smarts have been built into Temporal Tables. You can, though, put indexes on other columns too, such as on ValidFrom, or even have indexes that match the types of queries you might have on the main table. With a clustered index being a composite key on both ValidTo and ValidFrom, these two columns get included on every other column, providing a good opportunity for some Residual Predicate testing.
If I know which loginid I’m interested in, my plan forms a different shape.
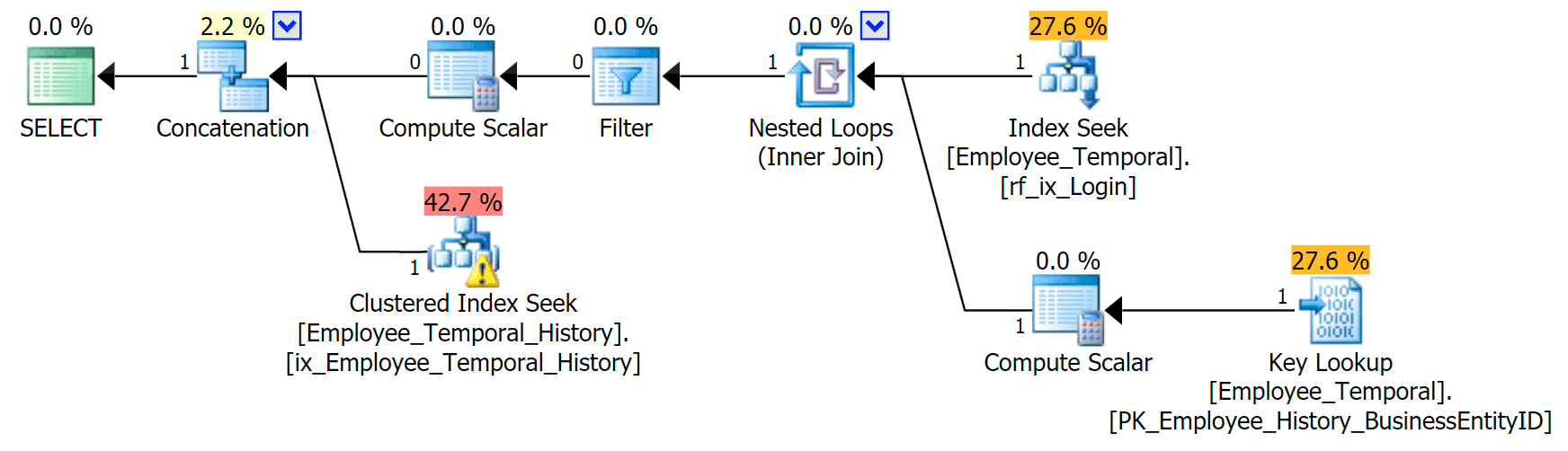
The top branch of the Concatenation operator looks similar to before, although that Filter operator has entered the fray to remove any rows that are not valid, but the Clustered Index Seek on the lower branch has a Warning. This is a Residual Predicate warning, like the examples in an earlier post of mine. It’s able to filter to entries that are valid until some point after the time we care about, but the Residual Predicate now filters to the LoginID as well as ValidFrom.
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000'
AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
Changes to rob0’s rows are going to be a tiny proportion of the rows in the History. This column won’t be unique like in the main table, because the row may have been changed multiple times, but there is still a good candidate for indexing.
CREATE INDEX rf_ixHist_loginid
ON HumanResources.Employee_Temporal_History(LoginID);
This new index has a notable effect on our plan.
It’s now changed our Clustered Index Seek into a Clustered Index Scan!!
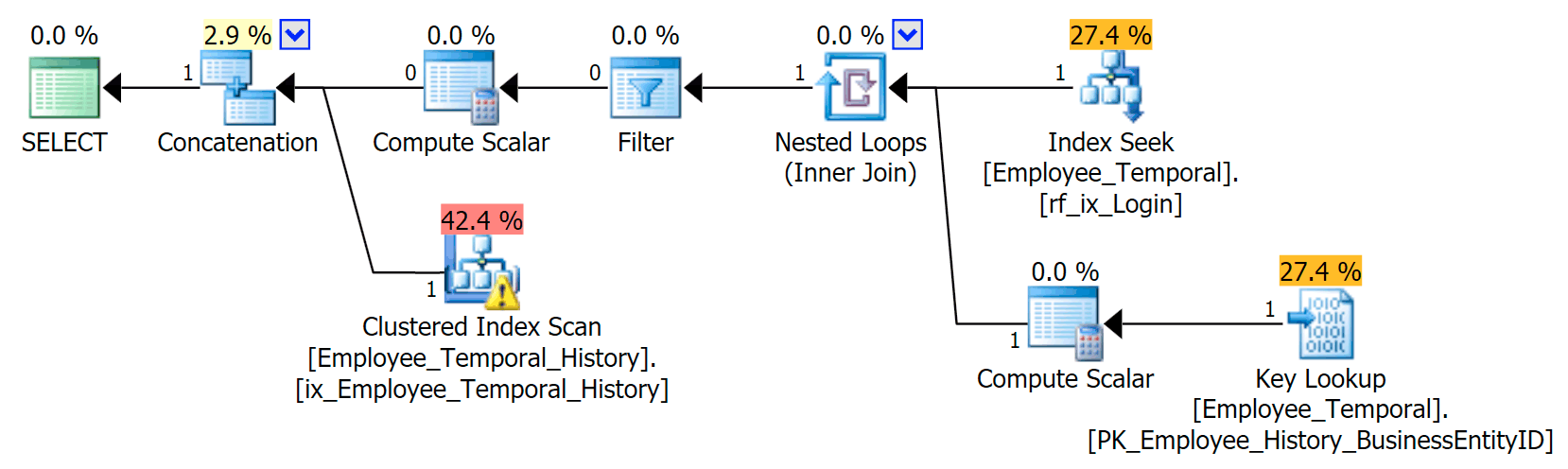
You see, the Query Optimizer now works out that the best thing to do would be to use the new index. But it also decides that the effort in having to do lookups to get all the other columns (because I was asking for all columns) would be simply too much work. The tipping point was reached (sadly an incorrect assumption in this case), and a Clustered Index SCAN chosen instead. Even though without the non-clustered index, the best option would have been to use a Clustered Index Seek, when the non-clustered index has been considered and rejected for tipping-point reasons, it chooses to scan.
Frustratingly, I’ve only just created this index and its statistics should be good. It should know that a Seek that requires exactly one lookup should be better than a Clustered Index Scan (only by statistics – if you were thinking it should know this because LoginID is unique in the main table, remember that it may not always have been). So I suspect that lookups should be avoided in history tables, although I haven’t done quite enough research into this yet.
Now were we to only query columns that appear in our non-clustered index, we would get much better behaviour. Now that no lookup is required, our new index on the history table is happily used. It still needs to apply a Residual Predicate based on only being able to filter to LoginID and ValidTo, but it behaves much better than dropping into a Clustered Index Scan.
SELECT LoginID, ValidFrom, ValidTo
FROM HumanResources.Employee_Temporal
FOR SYSTEM_TIME AS OF '20160612 11:22'
WHERE LoginID = N'adventure-works\rob0'
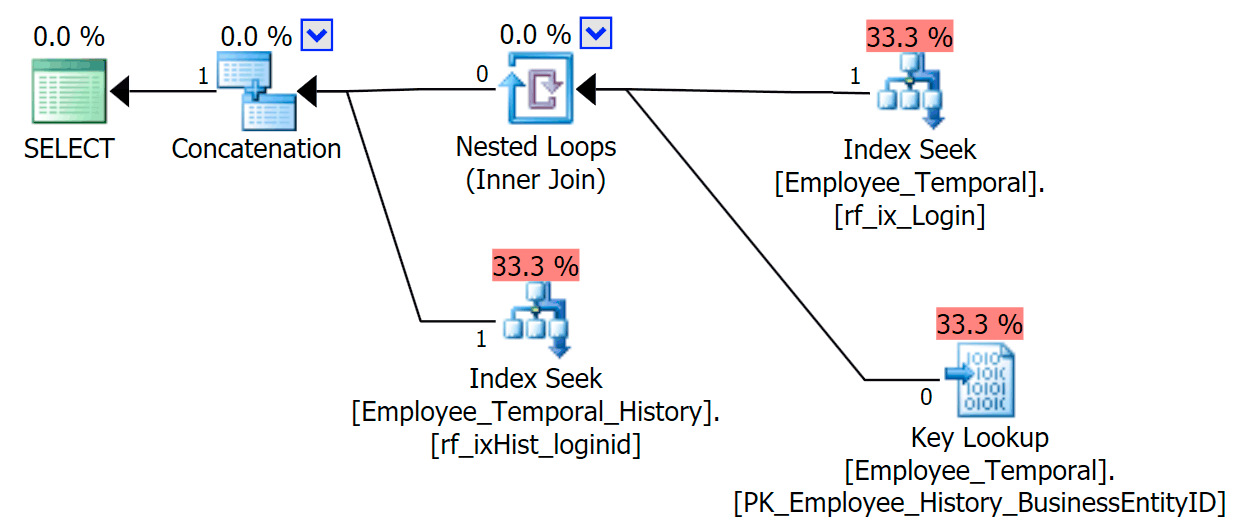
So do index your history tables in extra ways, considering how you will be querying them. Include the necessary columns to avoid lookups, because you’re really avoiding Scans.
These history tables can grow large if data is changing frequently. So be mindful of how they are being handled. This same situation occurs when using the other FOR SYSTEM_TIME constructs, so you should (as always) review the plans your queries are producing, and index to make sure that you are well positioned to leverage what is a very powerful feature of SQL Server 2016.
