
Number of Rows Read / Actual Rows Read warnings in Plan Explorer
The new property “Actual Rows Read” in execution plans (which in SQL Server Management Studio is displayed as “Number of Rows Read”) was a welcome addition to performance tuners. It’s like having a new superpower, to be able to tell the significance of the Seek Predicate v the Residual Predicate within a Seek operator. I love this, because it can be really significant to querying.
Let’s look at two queries, which I’m running against AdventureWorks2012. They’re very simple – one lists people called John S, and the other lists people called J Smith. Like all good phonebooks, we have an index on LastName, FirstName.
select FirstName, LastName
from Person.Person
where LastName like 'S%'
and FirstName = 'John';
select FirstName, LastName
from Person.Person
where LastName = 'Smith'
and FirstName like 'J%';
In case you’re curious, I get 2 rows back from the first one, and 14 rows back from the second. I’m not actually that interested in the results, I’m interested in the execution plans.
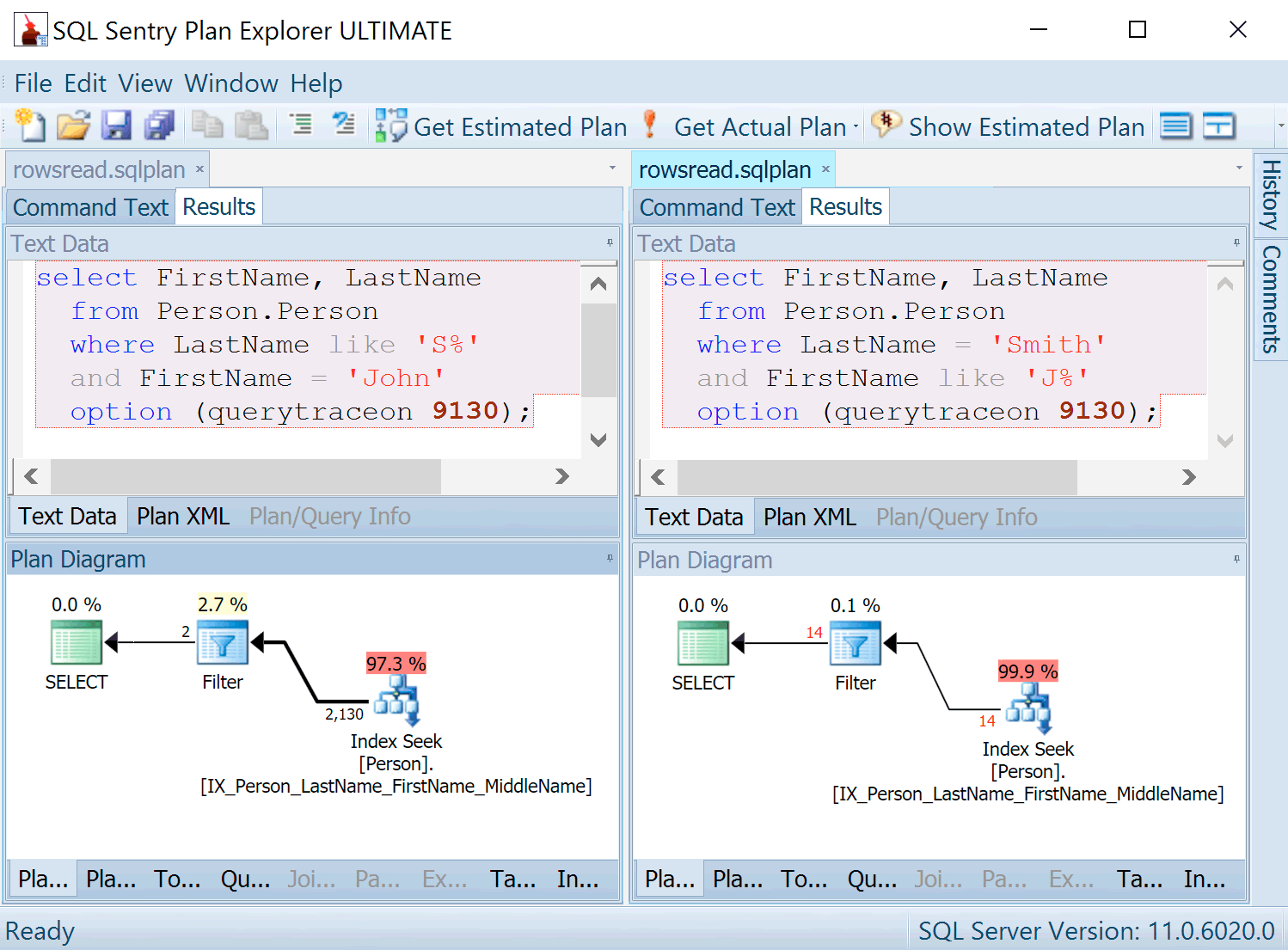
Let’s see what’s going on. I opened up an older copy of SQL Sentry Plan Explorer, and open my plans side by side. Incidentally – I had run both queries together and so both plans were in the same .sqlplan file. But I could open the same file twice in PE, and happily sit them side by side in tab groups.

Great. They look the same! I can see that the Seek on the left is producing two rows instead of fourteen – obviously this is the better query.
But with a larger window, I would’ve seen more information, and it’s lucky that I had run the two queries in the same batch.
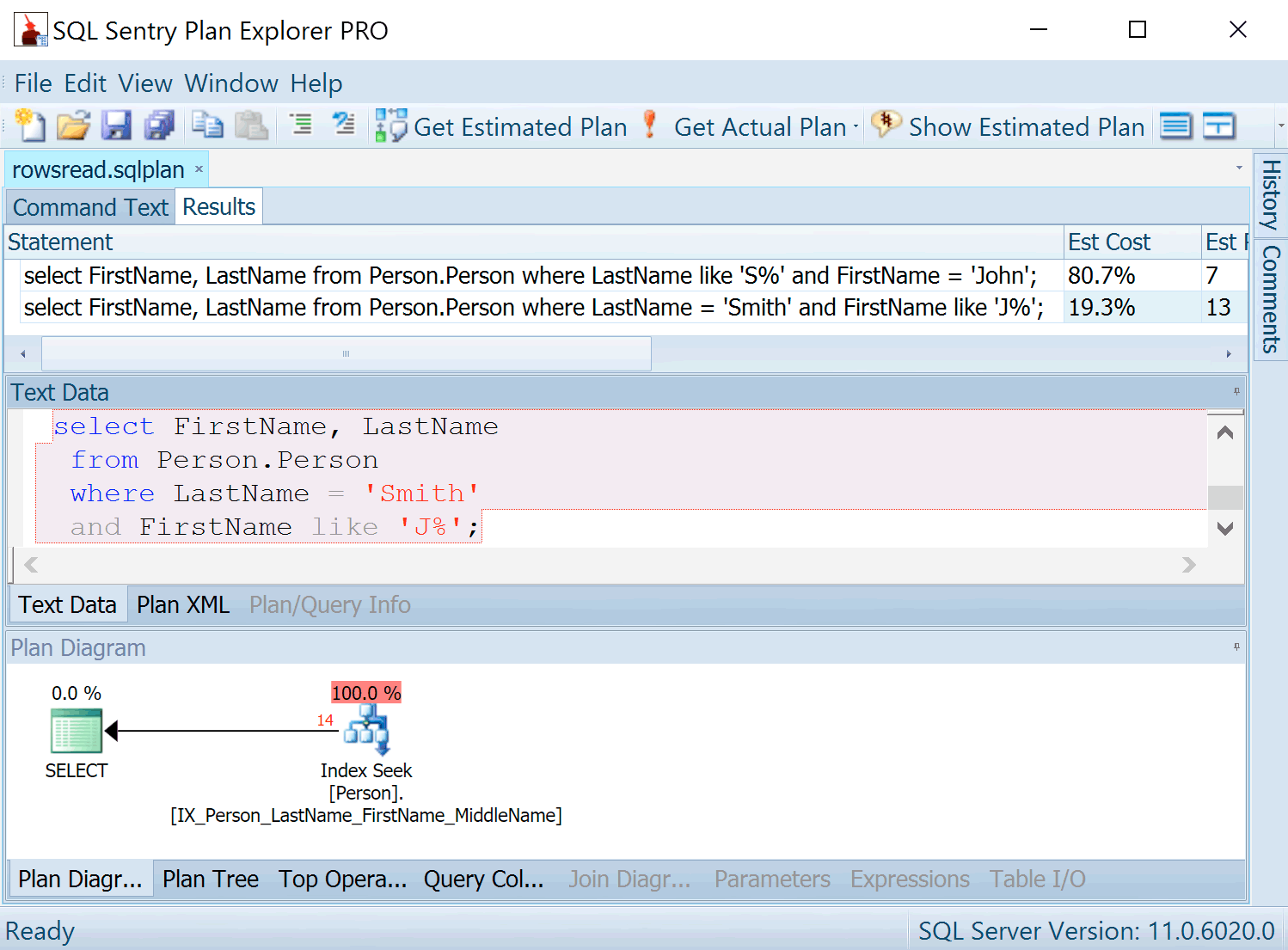
You can see that the second query, which produced 14 rows rather than 2 rows was estimated to take over 80% of the cost! If I’d run the queries separately, each would be showing me 100%.
Now let’s compare with the latest release of Plan Explorer.
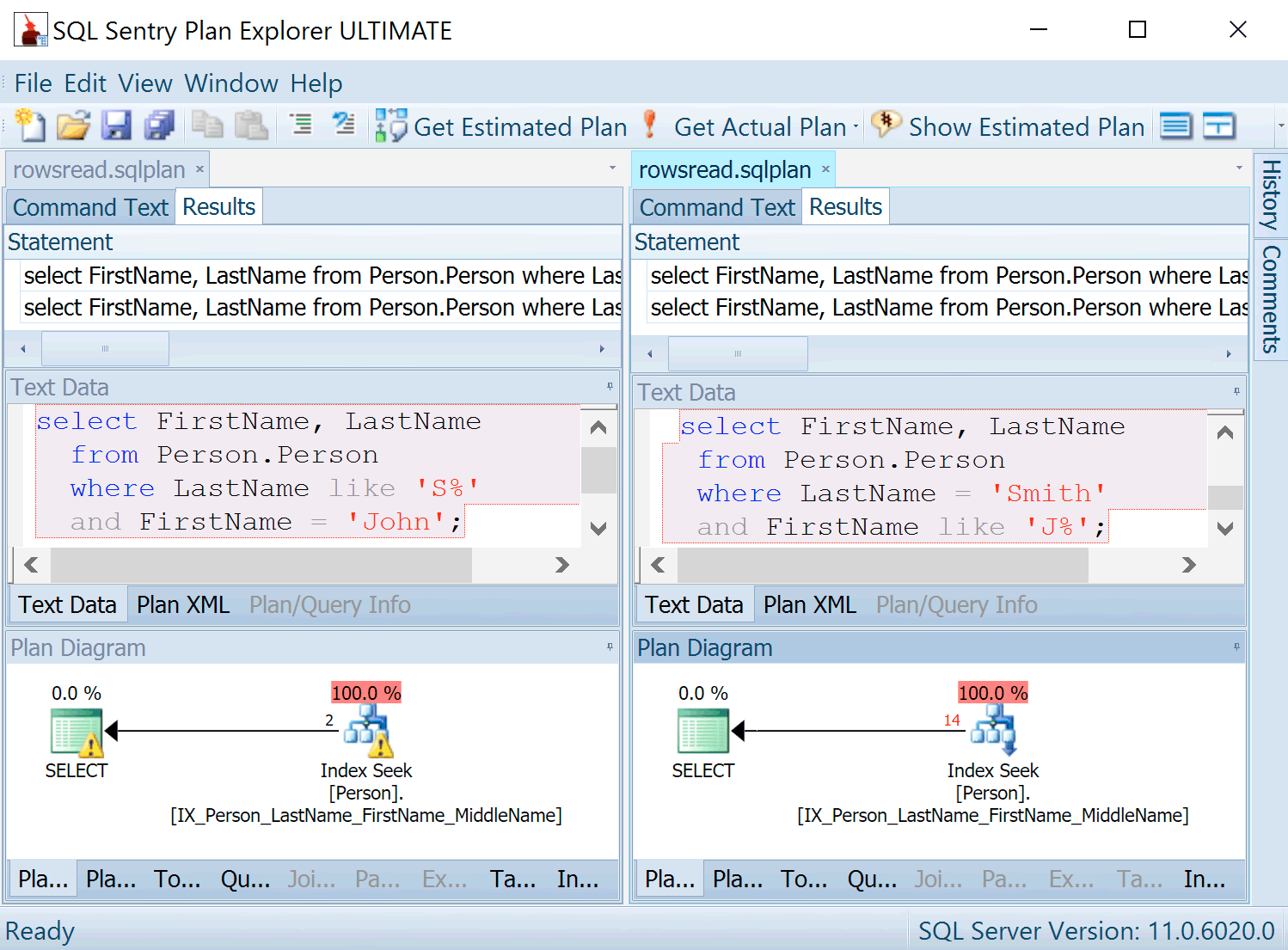
The thing that jumps out to me immediately is the warning. Let’s look a bit closer.

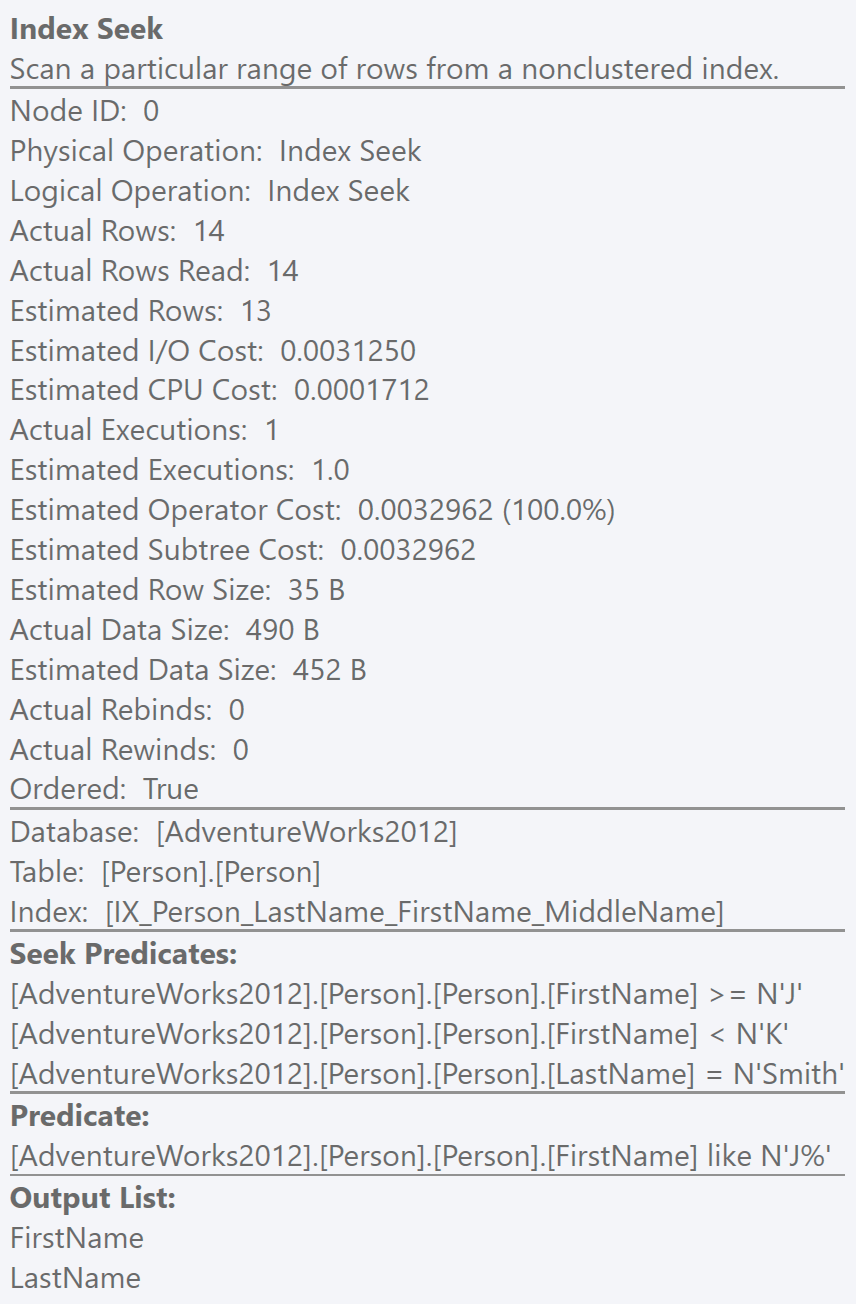
The warning says “Operation caused residual IO. The actual number of rows read was 2,130, but the number of rows returned was 2.” Sure enough, further up we see “Actual Rows Read” saying 2,130, and Actual Rows at 2.
Whoa! To find those rows, we had to look through 2,130?
You see, the way that the Seek runs is to start by thinking about the Seek Predicate. That’s the one that leverages the index nicely, and which actually causes the operation to be a Seek. Without a Seek Predicate, the operation becomes a Scan. Now, if this Seek Predicate is guaranteed to be at most one row (such as when it has an equality operator on a unique index), then we have a Singleton seek. Otherwise, we have a Range Scan, and this range can have a Prefix, a Start, and an End (but not necessarily both a Start and an End). This defines the rows in the table that we’re interested in for the Seek.
But ‘interested in’ doesn’t necessarily mean ‘returned’, because we might have more work to do. That work is described in the other Predicate, which is often known as the Residual Predicate.
Now that Residual Predicate might actually be doing most of the work. It certainly is here – it’s filtering things down from 2,130 rows to just 2.
The Range Scan starts in the index at “John S”. We know that if there is a “John S”, this must be the first row that can satisfy the whole thing. “Ian S” can’t. So we can search into the index at that point to start our Range Scan. If we look at the Plan XML we can see this explicitly.
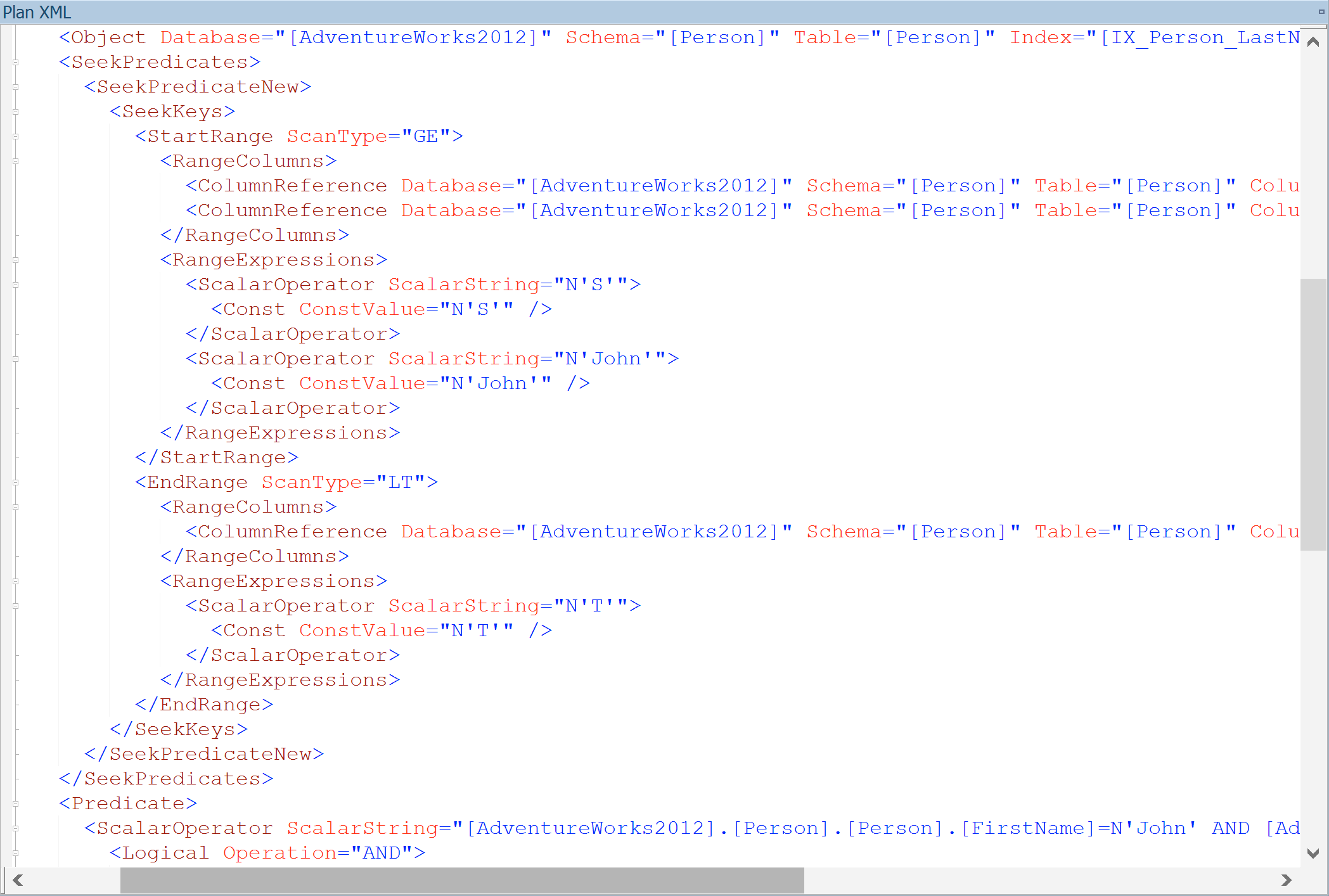
Notice that we don’t have a Prefix. That applies when you have an equality in the first column within the index. We just have StartRange and EndRange. The Start of the range is “Greater Than or Equal” (GE) ScanType, at the value “S, John” (the column references off-screen are LastName, FirstName), and the End of the range is “Less Than” (LT) the value T. When the scan hits T, it’s done. Nothing more to do. The Seek has now completed its Range Scan. And in this case, it returns 2,130 rows!
Except that it doesn’t actually return 2,130 rows, it just reads 2,130 rows. Names like Barry Sai and Ken Sánchez are read, but only the names that satisfy the next check are returned – the Residual Predicate that makes sure that the FirstName is John.
The Actual Rows Read entry in the Index Seek operator’s properties shows us this value of 2,130. And while it’s visible in earlier releases of Plan Explorer, we don’t get a warning about it. That’s relatively new.
Our second query (looking for J Smith) is much nicer, and there’s a reason why it was estimated to be more than 4 times cheaper.
Here we know the LastName exactly (Smith), and the Range Scan is on the FirstName (J%).
This is where the Prefix comes in.
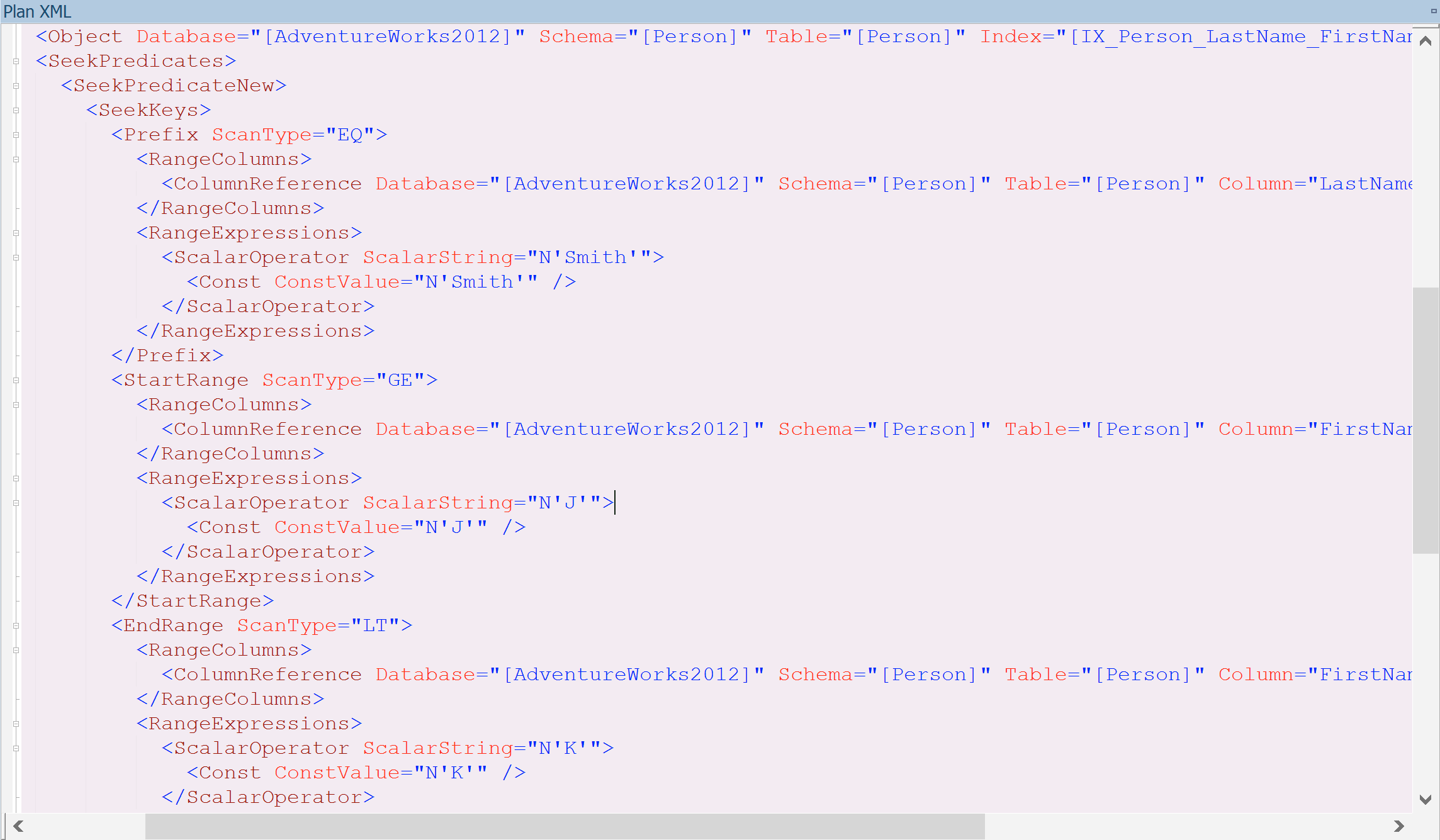
We see that our Prefix is an Equality operator (=, ScanType=”EQ”), and that LastName must be Smith. We haven’t even considered the Start or End of the range yet, but the Prefix tells us that the range is included within the portion of the index where LastName is Smith. Now we can find the rows >= J and < K.
There is still a Residual Predicate here, but this is only make sure that “LIKE J%” is actually tested. While it seems intuitive to us that “LIKE J%” is exactly equivalent to “>= J and < K”, the system doesn’t guarantee that and wants to do an extra check. Importantly, we see the Actual Rows (returned) being the same as Actual Rows Read. They’re both 14, and we’re not wasting any resources looking at rows that we don’t want.
Before Service Pack 3 of SQL Server 2012, we didn’t have this property, and to get a feel for the difference between the Actual Rows Read and the Actual Rows, we’d need to use trace flag 9130. Here are those two plans with that TF turned on:
You can see there’s no warning this time, because the Seek operator is returning all 2130 rows. I think if you’re using a version of SQL Server that supports this Actual Rows Read, you should stop using the trace flag 9130 in your investigations, and start looking at the warnings in Plan Explorer instead. But most of all, understand what how your operators do their stuff, because then you’ll be able to interpret whether you’re happy with the plan, or whether you need to take action.
In another post, I’ll show you a situation when you may prefer to see Actual Rows Read be higher than Actual Rows.
8 thoughts on “Number of Rows Read / Actual Rows Read warnings in Plan Explorer”
Comments are closed.

Thanks for the article. Good stuff I never knew about. Has me thinking about old queries and plans that were not performing good.
Excellent post Rob!
Thanks – I'm pleased you both liked it.
Nicely explained. Thanks for going to the trouble to write & post it.
I stumbled upon this six months after your post, but it clarified it so nicely, that I had to say:
thanks for the nice post. :)
Thanks Milan. :)
I know this is old post, but is this warning info only or is there a way to fix the first query?
Hi Zikato,
An index on (FirstName, LastName) would do it.
Rob