


Over three years ago now, I posted a three-part series on splitting strings:
- Split strings the right way – or the next best way
- Splitting Strings : A Follow-Up
- Splitting Strings : Now with less T-SQL
Then back in January, I took on a slightly more elaborate problem:
Throughout, my conclusion has been: STOP DOING THIS IN T-SQL. Use CLR or, better yet, pass structured parameters like DataTables from your application to table-valued parameters (TVPs) in your procedures, avoiding all the string construction and deconstruction altogether – which is really the part of the solution that causes performance problems.
And then SQL Server 2016 came along…
When RC0 was released, a new function was documented without a lot of fanfare: STRING_SPLIT. A quick example:
SELECT * FROM STRING_SPLIT('a,b,cd', ',');
/* result:
value
--------
a
b
cd
*/
It caught the eyes of a few colleagues, including Dave Ballantyne, who wrote about the main features – but was kind enough to offer me first right of refusal on a performance comparison.
This is mostly an academic exercise, because with a hefty set of limitations in the first iteration of the feature, it is probably not going to be feasible for a large number of use cases. Here is the list of the observations that Dave and I have made, some of which may be deal-breakers in certain scenarios:
- the function requires the database to be in compatibility level 130;
- it only accepts single-character delimiters;
- there is no way to add output columns (like a column indicating ordinal position within the string);
- related, there is no way to control sorting – the only options are arbitrary and alphabetical
ORDER BY value;
- related, there is no way to control sorting – the only options are arbitrary and alphabetical
- so far, it always estimates 50 output rows;
- when using it for DML, in many cases you will get a table spool (for Hallowe'en protection);
NULLinput leads to an empty result;- there is no way to push down predicates, like eliminating duplicates or empty strings due to consecutive delimiters;
- there is no way to perform operations against the output values until after the fact (for example, many splitting functions perform
LTRIM/RTRIMor explicit conversions for you –STRING_SPLITspits back all the ugly, such as leading spaces).
So with those limitations out in the open, we can move on to some performance testing. Given Microsoft's track record with built-in functions that leverage CLR under the covers (cough FORMAT() cough), I was skeptical about whether this new function could come close to the fastest methods I'd tested to date.
Let's use string splitters to separate comma-separated strings of numbers, this way our new friend JSON can come along and play too. And we'll say that no list can exceed 8,000 characters, so no MAX types are required, and since they're numbers, we don't have to deal with anything exotic like Unicode.
First, let's create our functions, several of which I adapted from the first article above. I left out a couple that I didn't feel would compete; I'll leave it as an exercise to the reader to test those.
Numbers Table
This one again needs some setup, but it can be a pretty small table due to the artificial limitations we're placing:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 8000;
;WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number);
Then the function:
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT [Value] = SUBSTRING(@List, [Number],
CHARINDEX(@Delimiter, @List + @Delimiter, [Number]) - [Number])
FROM dbo.Numbers WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter
);
JSON
Based on an approach first revealed by the storage engine team, I created a similar wrapper around OPENJSON, just note that the delimiter has to be a comma in this case, or you have to do some heavy duty string substitution before passing the value into the native function:
CREATE FUNCTION dbo.SplitStrings_JSON
(
@List varchar(8000),
@Delimiter char(1) -- ignored but made automated testing easier
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) ));
The CHAR(91)/CHAR(93) are just replacing [ and ] respectively due to formatting issues.
XML
CREATE FUNCTION dbo.SplitStrings_XML
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(8000)')
FROM (SELECT x = CONVERT(XML, ''
+ REPLACE(@List, @Delimiter, '')
+ '').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i));
CLR
I once again borrowed Adam Machanic's trusty splitting code from almost seven years ago, even though it supports Unicode, MAX types, and multi-character delimiters (and actually, because I don't want to mess with the function code at all, this limits our input strings to 4,000 characters instead of 8,000):
CREATE FUNCTION dbo.SplitStrings_CLR
(
@List nvarchar(MAX),
@Delimiter nvarchar(255)
)
RETURNS TABLE ( value nvarchar(4000) )
EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
Just for consistency, I put a wrapper around STRING_SPLIT:
CREATE FUNCTION dbo.SplitStrings_Native
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM STRING_SPLIT(@List, @Delimiter));
Source Data & Sanity Check
I created this table to serve as the source of input strings to the functions:
CREATE TABLE dbo.SourceTable
(
RowNum int IDENTITY(1,1) PRIMARY KEY,
StringValue varchar(8000)
);
;WITH x AS
(
SELECT TOP (60000) x = STUFF((SELECT TOP (ABS(o.[object_id] % 20))
',' + CONVERT(varchar(12), c.[object_id]) FROM sys.all_columns AS c
WHERE c.[object_id] < o.[object_id] ORDER BY NEWID() FOR XML PATH(''),
TYPE).value(N'(./text())[1]', N'varchar(8000)'),1,1,'')
FROM sys.all_objects AS o CROSS JOIN sys.all_objects AS o2
ORDER BY NEWID()
)
INSERT dbo.SourceTable(StringValue)
SELECT TOP (50000) x
FROM x WHERE x IS NOT NULL
ORDER BY NEWID();
Just for reference, let's validate that 50,000 rows made it into the table, and check the average length of the string and the average number of elements per string:
SELECT
[Values] = COUNT(*),
AvgStringLength = AVG(1.0*LEN(StringValue)),
AvgElementCount = AVG(1.0*LEN(StringValue)-LEN(REPLACE(StringValue, ',','')))
FROM dbo.SourceTable;
/* result:
Values AvgStringLength AbgElementCount
------ --------------- ---------------
50000 108.476380 8.911840
*/
And finally, let's make sure each function returns the right data for any given RowNum, so we'll just pick one randomly and compare the values obtained through each method. Your results will vary of course.
SELECT f.value
FROM dbo.SourceTable AS s
CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f
WHERE s.RowNum = 37219
ORDER BY f.value;
Sure enough, all the functions work as expected (sorting isn't numeric; remember, the functions output strings):
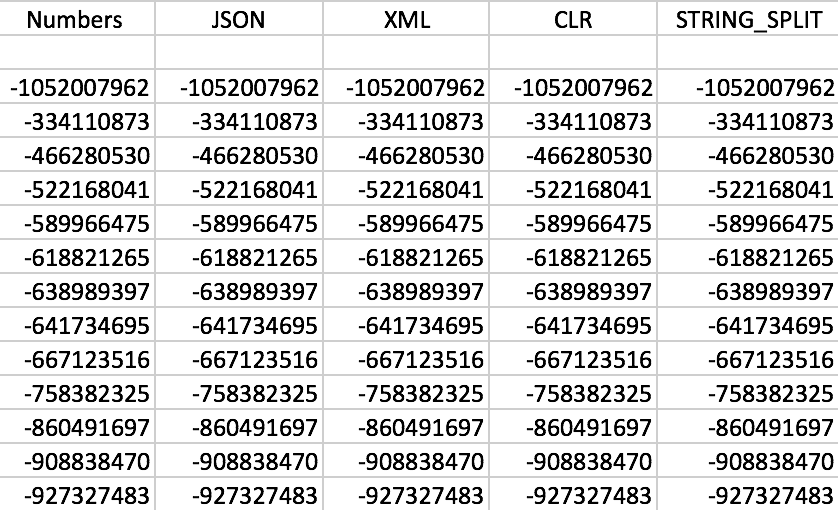 Sample set of output from each of the functions
Sample set of output from each of the functions
Performance Testing
SELECT SYSDATETIME();
GO
DECLARE @x VARCHAR(8000);
SELECT @x = f.value
FROM dbo.SourceTable AS s
CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue,',') AS f;
GO 100
SELECT SYSDATETIME();
I ran the above code 10 times for each method, and averaged the timings for each. And this is where the surprise came in for me. Given the limitations in the native STRING_SPLIT function, my assumption was that it was thrown together quickly, and that performance would lend credence to that. Boy was the result different from what I expected:
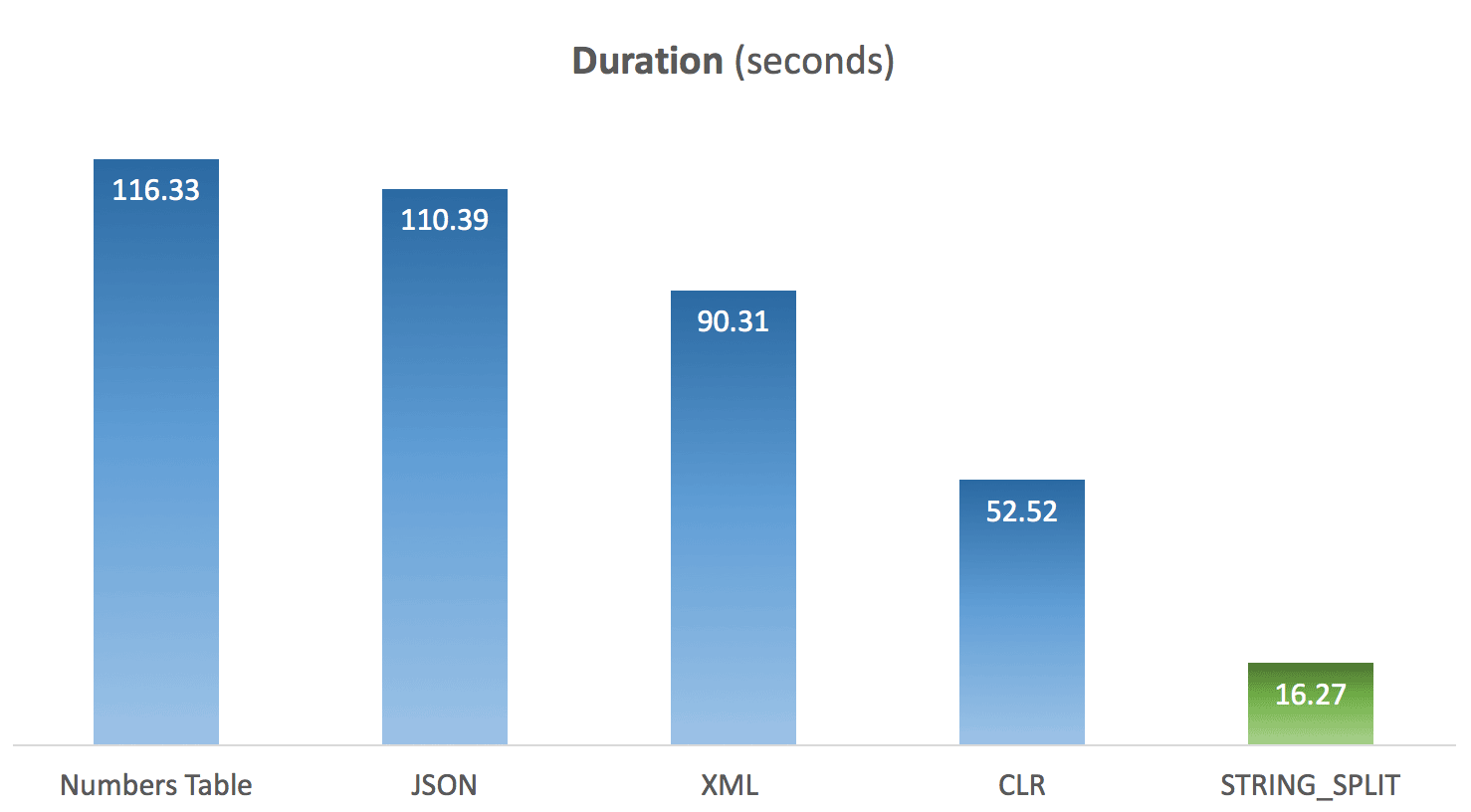 Average duration of STRING_SPLIT compared to other methods
Average duration of STRING_SPLIT compared to other methods
Update 2016-03-20
Based on the question below from Lars, I ran the tests again with a few changes:
- I monitored my instance with SQL Sentry Performance Advisor to capture CPU profile during the test;
- I captured session-level wait stats in between each batch;
- I inserted a delay in between batches so the activity would be visually distinct on the Performance Advisor dashboard.
I created a new table to capture wait stat information:
CREATE TABLE dbo.Timings
(
dt datetime,
test varchar(64),
point varchar(64),
session_id smallint,
wait_type nvarchar(60),
wait_time_ms bigint,
);
Then the code for each test changed to this:
WAITFOR DELAY '00:00:30';
DECLARE @d DATETIME = SYSDATETIME();
INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms)
SELECT @d, test = /* 'method' */, point = 'Start', wait_type, wait_time_ms
FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
GO
DECLARE @x VARCHAR(8000);
SELECT @x = f.value
FROM dbo.SourceTable AS s
CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f
GO 100
DECLARE @d DATETIME = SYSDATETIME();
INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms)
SELECT @d, /* 'method' */, 'End', wait_type, wait_time_ms
FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
I ran the test and then ran the following queries:
-- validate that timings were in same ballpark as previous tests
SELECT test, DATEDIFF(SECOND, MIN(dt), MAX(dt))
FROM dbo.Timings WITH (NOLOCK)
GROUP BY test ORDER BY 2 DESC;
-- determine window to apply to Performance Advisor dashboard
SELECT MIN(dt), MAX(dt) FROM dbo.Timings;
-- get wait stats registered for each session
SELECT test, wait_type, delta FROM
(
SELECT f.test, rn = RANK() OVER (PARTITION BY f.point ORDER BY f.dt),
f.wait_type, delta = f.wait_time_ms - COALESCE(s.wait_time_ms, 0)
FROM dbo.Timings AS f
LEFT OUTER JOIN dbo.Timings AS s
ON s.test = f.test
AND s.wait_type = f.wait_type
AND s.point = 'Start'
WHERE f.point = 'End'
) AS x
WHERE delta > 0
ORDER BY rn, delta DESC;
From the first query, the timings remained consistent with previous tests (I'd chart them again but that wouldn't reveal anything new).
From the second query, I was able to highlight this range on the Performance Advisor dashboard, and from there it was easy to identify each batch:
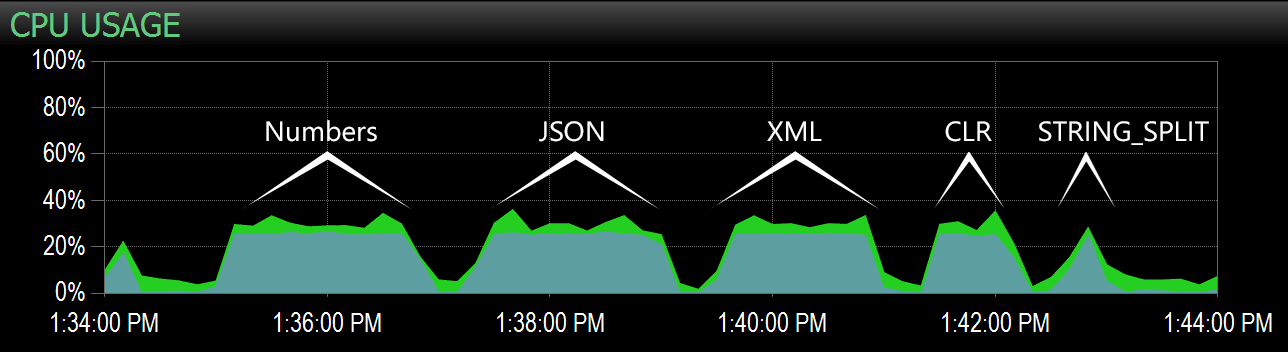 Batches captured on the CPU chart on the Performance Advisor dashboard
Batches captured on the CPU chart on the Performance Advisor dashboard
Clearly, all of the methods *except* STRING_SPLIT pegged a single core for the duration of the test (this is a quad-core machine, and CPU was steadily at 25%). It is likely that Lars was insinuating below that STRING_SPLIT is faster at the cost of hammering the CPU, but it doesn't appear that this is the case.
Finally, from the third query, I was able to see the following wait stats accruing after each batch:
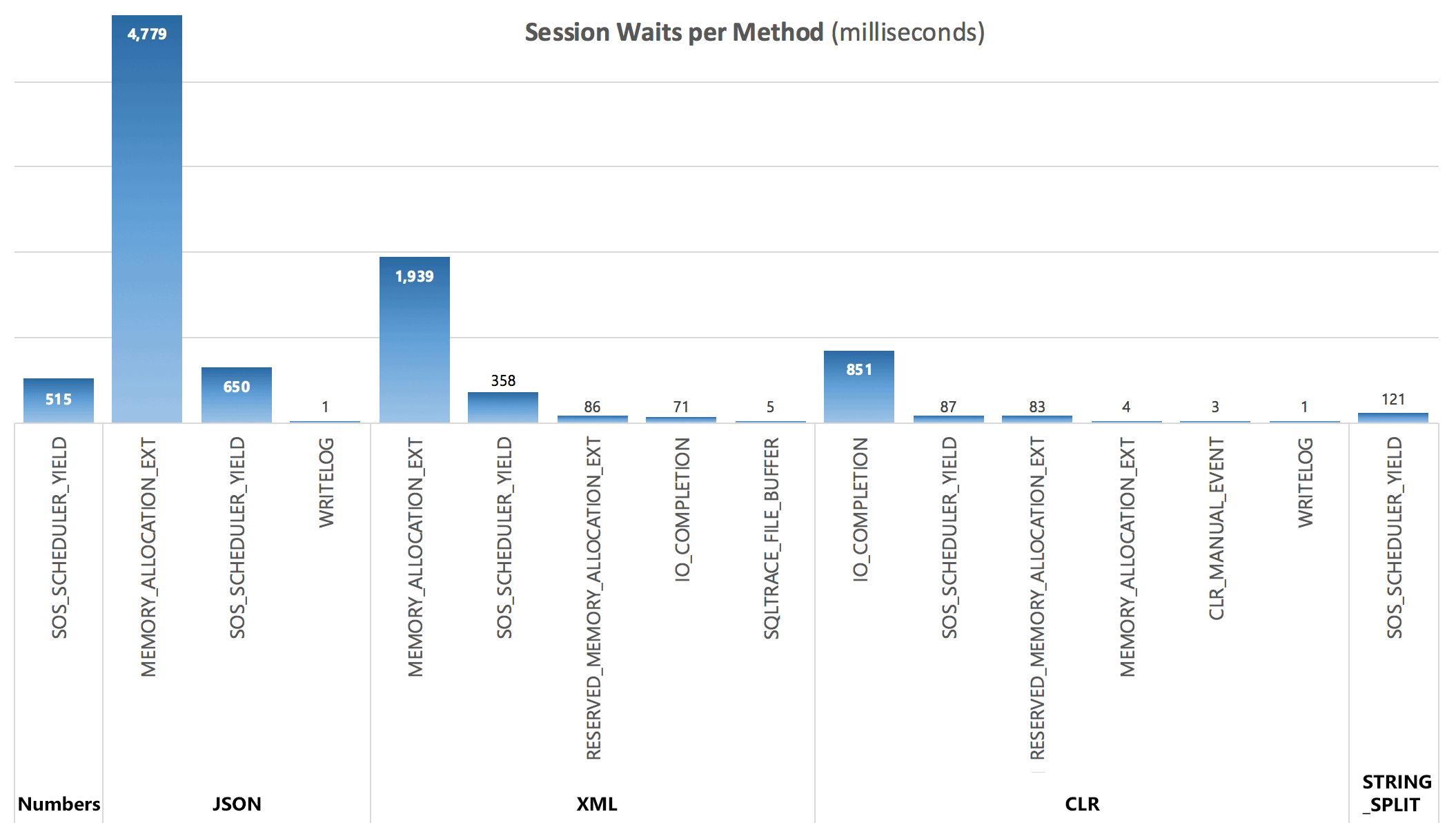 Per-Session Waits, in milliseconds
Per-Session Waits, in milliseconds
The waits captured by the DMV do not fully explain the duration of the queries, but they do serve to show where additional waits are incurred.
Conclusion
While custom CLR still shows a huge advantage over traditional T-SQL approaches, and using JSON for this functionality appears to be nothing more than a novelty, STRING_SPLIT was the clear winner - by a mile. So, if you just need to split a string and can deal with all of its limitations, it looks like this is a much more viable option than I would have expected. Hopefully in future builds we'll see additional functionality, such as an output column indicating the ordinal position of each element, the ability to filter out duplicates and empty strings, and multi-character delimiters.
I address multiple comments below in two follow-up posts:



It is important to note that the XML and JSON approaches do not work with certain classes of input such as "" and '<'.
Besides that, the tests and reasoning performed in this article are expert level and a great community service.
It might be interesting to see where CLR and STRING_SPLIT spend their time using PerfView. The call stacks sometime give rise to additional optimizations.
Yes, true, one of the secret reasons I I chose a sequence of integers instead of real strings. :-)
The XML approach works well including with XML reserved chars if the source strings are encoded using FOR XML before REPLACE(string, separator, xml elements). I used many times bellow approach:
The performance is affected by that FOR XML but there are no issues generated by those chars.
Very interesting
Could you please share the amount of CPU consumed by these 5 methods ?
Are they the same or are something relevant lurking in the shadows? Say: the engine is simply better at executing over multiple CPU's with the (new) build in function or something similar?
I was wondering about this just the other day — thanks! Indeed surprising results.
How does it estimate the data size when joined to another (or multiple) split function? The link below is a write up of a CLR Based split implementation. Does the 2016 do a 'better' job with data estimates? (unfortunately i don't have hte ability to install the RC yet).
http://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and.html
STRING_SPLIT is indeed very fast, however also slow as hell when working with temporary table (unless it get fixed in a future build).
SELECT f.value
INTO #test
FROM dbo.SourceTable AS s
CROSS APPLY string_split(s.StringValue, ',') AS f
Will be WAY slower than SQL CLR solution (15x and more!).
You're right, for that specific use case, the native solution is way slower.
I looked into waits to see what was happening. JSON and STRING_SPLIT() took about 10 seconds each, they accumulated nearly 25 seconds in latch waits, while the XML, CLR, and Numbers versions accumulated almost nothing there. So it seems like some kind of parallelism issue.
You should find that the CLR and STRING_SPLIT() methods are much closer together in performance if you add OPTION (MAXDOP 1) to inhibit parallelism. In this case I get ~900ms for CLR and ~1300ms for STRING_SPLIT(). And the plan for STRING_SPLIT() is a lot simpler (missing a spool and a sort that exist in the CLR plan). CLR is of course even faster if you only turn off parallelism for STRING_SPLIT().
(And again, I only found this to be true when using SELECT INTO #temp. Usually I try to *avoid* the cost of materializing intermediate result sets unless I have a specific reason to do so.)
How do these functions compare with table-valued parameters?
Hi Doug, don't know, it's on my list…
As a long time participator in the running contest to write the fastest sql server string splitter, the fact that its perf when loading into a table (a very common technique) is very disappointing.
Here is my simple benchmark I built. Simply loading 100000 strings containing 20 elements each of about 20-30 elements and having them be split and the result saved into a table (temp or not it doesn't matter)
I compared the fastest CLR func, the fastest t-sql function, and the native function.
Results were unfortunate. The string_split function took nearly as long as the t-sql version, and the clr function was about 5 times faster.
https://gist.github.com/mburbea/52b3f7ecba78dfe515d663a672b4fd5b#file-string_split_perf_into_table_is_poor-sql
I am using this to split the strings, a dynamic sql. It is fast enough for my needs and I didn't see it among on the options over the internet.
select @databases=’select ”’+replace(@databases,’,’,”’ union all select ”’)+””
exec(@databases)
I don't know how fast it is in comparison with others but for a string of 50k is under 50ms
What do you think about this method
declare @databases nvarchar(max)
set @databases=’a,b,c,d’
select @databases=’select ”’+replace(@databases,’,’,”’ union all select ”’)+””
exec(@databases)
No, I don't like the dynamic SQL approach very much, simply because what if someone passes in this:
And even if you go to great lengths to "cleanse" that input string, validate that the databases exist, ensure that the executing user has insufficient permissions on other tables, and so on, I don't see what advantage this approach has over passing 'a,b,c,d' into STRING_SPLIT().
Hello Aaron, thanks a lot for your reply and your time, I understood your point and indeed this is very dangerous. But why to not insert another replace char there and replace ' with nothing to avoid bad things, your code will become a simple select. Of course there are words like – don't – that will be broke but it will still work.
select @string ='select "'+replace(replace(@string,"","),',',"' union all select "')+""
select 'a' union all select 'b' union all select 'c' union all select 'd;
update dbo.employees set salary*=2;
delete dbo.auditLog;
select foo'
What I tried to convey is that this approach at least in my mind is easier to understand and write and it is doing the job, maybe not 100% in 100% of the cases but it is quite closed.
Does anyone know why a column indicating the position of the value in the sequence was not included in the resulting table?
For example, SELECT value FROM STRING_SPLIT('Lorem ipsum dolor sit amet.', ' ') would instead return….
Position Value
——— ——–
1 Lorem
2 Ipsum
3 dolor
…etc…
It is very useful for a variety of reasons, so its omission seems strange….
This function was introduced late in the 2016 dev cycle and by the time they got that feedback it was too late. We've been asking for it to be augmented, but I'm not holding my breath. In order to avoid backward compatibility issues, they could only introduce a new output column by either creating a new function, making the function accept a third optional argument, or adding an option like WITH (ORDERED_OUTPUT). I don't see any of those happening in 2017, but you should vote (and more importantly, comment, stating your use case) on this Connect item, where Microsoft says:
"Thanks for the suggestion. This is in our backlog but we cannot confirm when it will be implemented."
Also note this Connect item, a duplicate but with more votes.
I'm a bit late to the party but when it comes to performance I'd propose that the dynamic exec method can't be reliably compared to other split methods. One can compare execution stats across other methods but using exec hides the string parsing overhead in the query parsing step leaving the execution plan to be what looks like a deceptively efficient Constant Scan.
Use of replace being substantially equal in both cases, imperially, it seems unlikely that a dedicated XML parser would be unable to match the performance of the more generic query parser.
Given exec can't be used in a cross apply context the technique can't operate over sets where performance would actually matter so at best it's an extremely niche tool. But even in the case of a CSV parameter I'm not seeing any practical advantage beyond a reader/maintainer not needing understand the very simplest of XML queries. It does achieve that although I would not consider such complete avoidance of the subject to be a useful career move.
When you're measuring time and other runtime metrics, as opposed to just qualitative observations of the execution plan, overhead that impacts performance can't hide.
Thank you for this write up. After parsing through 78,000 rows using the same methods–hands down–split string won.
Can you also do another write up on creating a string from a result set? After 230,000 rows of data I find that the 'STUFF' with FOR xml path("),TYPE).value('.','NVARCHAR(MAX)') was faster by many miles. Unfortunately, these stackoverflow answers don't touch on the cpu costs and efficiency of their suggestions. A write up like that would have saved me a few hours and multiple tests.
https://stackoverflow.com/questions/4819412/convert-sql-server-result-set-into-string
https://stackoverflow.com/questions/5196371/sql-query-concatenating-results-into-one-string
Hi Holly, there is now STRING_AGG() in SQL Server. These posts might be useful:
https://sqlperformance.com/2014/08/t-sql-queries/sql-server-grouped-concatenation
https://sqlperformance.com/2016/01/t-sql-queries/comparing-splitting-concat
https://sqlperformance.com/2016/12/sql-performance/sql-server-v-next-string_agg-performance
https://sqlperformance.com/2017/01/sql-performance/sql-server-v-next-string_agg-performance-part-2
And you're right, often on Stack Overflow you'll find users will upvote/pick as the best answer the one they found easiest to understand, or the first one they tried that worked, rather than the one that's best. And people don't go back and update old answers when new methods, like STRING_AGG(), come along.
Thanks a lot for the write-up
I was looking into an elegant way to extract the first and last substring of a string, trying to avoid the substring/charindex/reverse… etc t-sql extra-long code.
This seems to work well, returning "first" and "last"
SELECT distinct first_value(value) over (order by (select 1)),
last_value(value) over (order by (select 1))
FROM STRING_SPLIT('first b c d e e e e e f g g h i last', ' ')
but… do you know if it is dangerous? So far I have always got good results, but the lack for an explicit row order (or rather, the hacky use of order by (select 1)) puts me a little nervous.
(alternative CHARINDEX('$', $(x_text_x))=0 then $(x_text_x) else SUBSTRING( $(x_text_x) , LEN($(x_text_x)) – CHARINDEX('$',REVERSE($(x_text_x))) + 2 , LEN($(x_text_x)) ) end is so ugly… )
Thanks a lot
While I don't have a counter-example, I don't think it's safe to rely on this, and you're right to be nervous. If order of input is important, you should use the older methods where you build your own UDF that can preserve ordering.
There is a simple solution for using STRING_SPLIT and guarantee the order, but it is highly not recommended for production, from the performance aspect -> only for the sake of the discussion you can check this post with full explanation and "solution":
http://ariely.info/Blog/tabid/83/EntryId/223/T-SQL-Playing-with-STRING_SPLIT-function.aspx