
Considerations Around Column Order in Indexes and Sorts
When users request data from a system, they usually like to see it in a specific order… even when they're returning thousands of rows. As many DBAs and developers know, ORDER BY can introduce havoc into a query plan, because it requires the data to be sorted. This can sometimes require a SORT operator as part of query execution, which can be a costly operation, particularly if estimates are off and it spills to disk. In an ideal world, the data is already sorted thanks to an index (indexes and sorts are very complementary). We often talk about creating a covering index to satisfy a query – so that the optimizer doesn't have to go back to the base table or clustered index to get additional columns. And you might have heard people say that the order of the columns in the index matters. Have you ever considered how it affects your SORT operations?
Examining ORDER BY and Sorts
We'll start with a fresh copy of the AdventureWorks2014 database on a SQL Server 2014 instance (version 12.0.2000). If we run a simple SELECT query against Sales.SalesOrderHeader with no ORDER BY, we see a plain old Clustered Index Scan (using SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader];
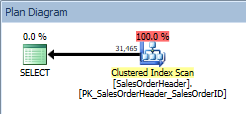 Query with no ORDER BY, clustered index scan
Query with no ORDER BY, clustered index scan
Now let's add an ORDER BY to see how the plan changes:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader]
ORDER BY [CustomerID];
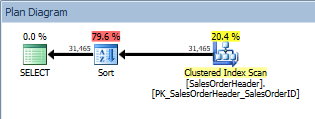 Query with an ORDER BY, clustered index scan and a sort
Query with an ORDER BY, clustered index scan and a sort
In addition to the Clustered Index Scan, we now have a Sort introduced by the optimizer, and its estimated cost is significantly higher than that of the scan. Now, estimated cost is just estimated, and we cannot say with absolutely certainty here that the Sort took 79.6% of the cost of the query. To really understand how expensive the Sort is, we would need to look at IO STATISTICS as well, which is beyond today's goal.
Now if this was a query that was executed frequently in your environment, you would probably consider adding an index to support it. In this case, there is no WHERE clause, we're just retrieving four columns, and ordering by one of them. A logical first attempt at an index would be:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal]
ON [Sales].[SalesOrderHeader](
[CustomerID] ASC)
INCLUDE (
[OrderDate], [SubTotal]);
We'll re-run our query after adding the index which has all the columns we want, and remember that the index has done the work to sort the data. We now see an Index Scan against our new nonclustered index:
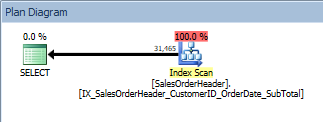 Query with an ORDER BY, the new, nonclustered index is scanned
Query with an ORDER BY, the new, nonclustered index is scanned
This is good news. But what happens if someone alters that query – either because users can specify what columns they want to order by, or because a change was requested of a developer? For example, maybe users want to see the CustomerIDs and SalesOrderIDs in descending order:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader]
ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;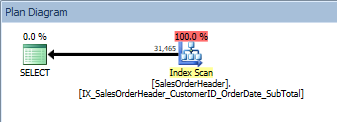 Query with two columns in the ORDER BY, the new, nonclustered index is scanned
Query with two columns in the ORDER BY, the new, nonclustered index is scanned
We have the same plan; no Sort operator was added. If we look at the index using Kimberly Tripp's sp_helpindex (some columns collapsed to save space), we can see why the plan didn't change:
 Output of sp_helpindex
Output of sp_helpindex
The key column for the index is CustomerID, but since SalesOrderID is the key column for the clustered index, it is part of the index key as well, thus the data is sorted by CustomerID, then SalesOrderID. The query requested the data sorted by those two columns, in descending order. The index was created with both columns ascending, but because it's a doubly-linked list, the index can be read backward. You can see this in the Properties pane in Management Studio for the nonclustered index scan operator:
 Properties pane of the nonclustered index scan, showing it was backwards
Properties pane of the nonclustered index scan, showing it was backwards
Great, no issues with that query…but what about this one:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader]
ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;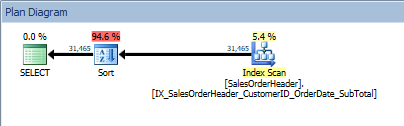 Query with two column in the ORDER BY, and a sort is added
Query with two column in the ORDER BY, and a sort is added
Our SORT operator reappears, because the data coming from the index is not sorted in the order requested. We'll see the same behavior if we sort on one of the included columns:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader]
ORDER BY [CustomerID] ASC, [OrderDate] ASC;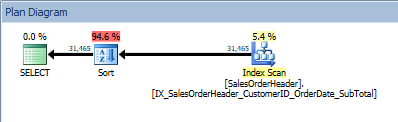 Query with two column in the ORDER BY, and a sort is added
Query with two column in the ORDER BY, and a sort is added
What happens if we (finally) add a predicate, and change our ORDER BY slightly?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader]
WHERE [CustomerID] = 13464
ORDER BY [SalesOrderID];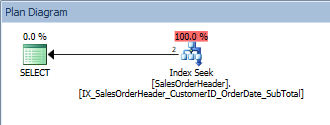 Query with a single predicate and an ORDER BY
Query with a single predicate and an ORDER BY
This query is ok because again, the SalesOrderID is part of the index key. For this one CustomerID, the data is already ordered by SalesOrderID. What if we query for a range of CustomerIDs, sorted by SalesOrderIDs?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader]
WHERE [CustomerID] BETWEEN 13464 AND 13466
ORDER BY [SalesOrderID]; Query with a range of values in the predicate and an ORDER BY
Query with a range of values in the predicate and an ORDER BY
Rats, our SORT is back. The fact that the data is ordered by CustomerID only helps in seeking the index to find that range of values; for the ORDER BY SalesOrderID, the optimizer has to interject the Sort to put the data in the requested order.
Now at this point, you might be wondering why I'm fixated on the Sort operator appearing in query plans. It's because it's expensive. It can be expensive in terms of resources (memory, IO) and/or duration.
Query duration can be affected by a Sort because it is a stop-and-go operation. The entire set of data has to be sorted before the next operation in the plan can occur. If only a few rows of data have to be ordered, that's not such a big deal. If it's thousands or millions of rows? Now we're waiting.
In addition to overall query duration, we also have to think about resource use. Let's take the 31,465 rows we've been working with and push them into a table variable, then run that initial query with the ORDER BY on CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY);
INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM [Sales].[SalesOrderHeader];
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal]
FROM @t
ORDER BY [CustomerID];
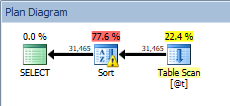 Query against the table variable, with the sort
Query against the table variable, with the sort
Our SORT is back, and this time it has a warning (note the yellow triangle with the exclamation mark). Warnings are not good. If we look at the Properties of the sort, we can see warning, "Operator used tempdb to spill data during execution with spill level 1":
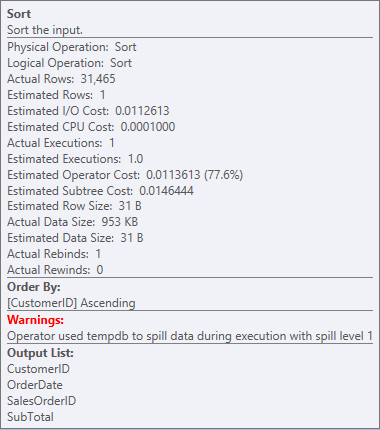 Sort warning
Sort warning
This isn't something I want to see in a plan. The optimizer made an estimate of how much space it would need in memory to sort the data, and it requested that memory. But when it actually had all the data and went to sort it, the engine realized there wasn't enough memory (the optimizer asked for too little!), so the Sort operation spilled. In some cases, this can spill to disk, which means reads and writes – which are slow. Not only are we waiting just to get the data in order, it's even slower because we can't do it all in memory. Why didn't the optimizer ask for enough memory? It had a bad estimate about the data it needed to sort:
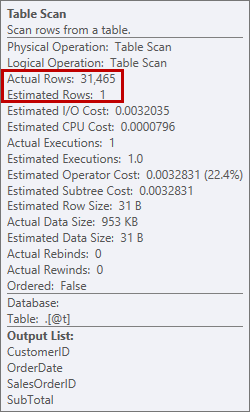 Estimate of 1 row versus actual of 31,465 rows
Estimate of 1 row versus actual of 31,465 rows
In this case I forced a bad estimate by using a table variable. There are known issues with statistics estimates and table variables (Aaron Bertrand has a great post on options for trying to address this), and here, the optimizer believed only 1 row was going to be returned from the table scan, not 31,465.
Options
So what can you, as a DBA or developer, do to avoid SORTs in your query plans? The quick answer is, "Don't order your data." But that's not always realistic. In some cases, you can offload that sorting to the client, or to an application layer – but users still have to wait to sort the data at that layer. In the situations where you cannot alter how the application works, you can start by looking at your indexes.
If you support an application that allows users to run ad-hoc queries, or change the sort order so they can see the data ordered how they want…you're going to have the hardest time (but it isn't a lost cause so don't stop reading yet!). You cannot index for every option. It's inefficient and you will create more problems than you solve. Your best bet here is to talk to the users (I know, sometimes it's scary to leave your corner of the woods, but give it a try). For the queries the users run most often, find out how they typically like to see the data. Yes, you can get this from the plan cache too – you can retrieve queries and plans until your heart's content to see what they're doing. But it's faster to talk to the users. The added benefit is that you can explain why you're asking, and why that idea to "sort on all the columns because I can" isn't such a good one. Knowing is half the battle. If you can spend some time educating your power users, and the users that train new folks, you might be able to do some good.
If you support an application with limited ORDER BY options, then you can do some real analysis. Review what ORDER BY variations exist, determine which combinations are executed most often, and index to support those queries. You probably won't hit every one, but you can still make an impact. You can take it one step further by talking to your developers and educating them on the problem, and how to address it.
Finally, when you're looking at query plans with SORT operations, don't just focus on removing the Sort. Look at where the Sort occurs in the plan. If it happens way on the left of the plan, and is typically a few rows, there may be other areas with a bigger improvement factor on which to focus. The Sort on the left is the pattern we focused on today, but a Sort doesn't always occur because of an ORDER BY. If you see a Sort on the far right of the plan, and there are a lot of rows moving through that part of the plan, you know you've found a good place to start tuning.
