
Making the Case for INSTEAD OF Triggers – Part 1
Last year, I posted a tip called Improve SQL Server Efficiency by Switching to INSTEAD OF Triggers.
The big reason I tend to favor an INSTEAD OF trigger, particularly in cases where I expect a lot of business logic violations, is that it seems intuitive that it would be cheaper to prevent an action altogether, than to go ahead and perform it (and log it!), only to use an AFTER trigger to delete the offending rows (or roll back the entire operation). The results shown in that tip demonstrated that this was, in fact, the case – and I suspect they would be even more pronounced with more non-clustered indexes affected by the operation.
However, that was on a slow disk, and on an early CTP of SQL Server 2014. In preparing a slide for a new presentation I'll be doing this year on triggers, I found that on a more recent build of SQL Server 2014 – combined with updated hardware – it was a bit trickier to demonstrate the same delta in performance between an AFTER and INSTEAD OF trigger. So I set out to discover why, even though I immediately knew this was going to be more work than I've ever done for a single slide.
One thing I want to mention is that triggers can use tempdb in different ways, and this might account for some of these differences. An AFTER trigger uses the version store for the inserted and deleted pseudo-tables, while an INSTEAD OF trigger makes a copy of this data in an internal worktable. The difference is subtle, but worth pointing out.
The Variables
I am going to test various scenarios, including:
- Three different triggers:
- An AFTER trigger that deletes specific rows that fail
- An AFTER trigger that rolls back the whole transaction if any row fails
- An INSTEAD OF trigger that only inserts the rows that pass
- Different recovery models and snapshot isolation settings:
- FULL with SNAPSHOT enabled
- FULL with SNAPSHOT disabled
- SIMPLE with SNAPSHOT enabled
- SIMPLE with SNAPSHOT disabled
- Different disk layouts*:
- Data on SSD, log on 7200 RPM HDD
- Data on SSD, log on SSD
- Data on 7200 RPM HDD, log on SSD
- Data on 7200 RPM HDD, log on 7200 RPM HDD
- Different failure rates:
- 10%, 25%, and 50% failure rate across:
- Single batch insert of 20,000 rows
- 10 batches of 2,000 rows
- 100 batches of 200 rows
- 1,000 batches of 20 rows
- 20,000 singleton inserts
*
tempdbis a single data file on a slow, 7200 RPM disk. This is intentional and meant to amplify any bottlenecks caused by the various uses oftempdb. I plan to revisit this test at some point whentempdbis on a faster SSD. - 10%, 25%, and 50% failure rate across:
Okay, TL;DR Already!
If you just want to know the results, skip down. Everything in the middle is just background and an explanation of how I set up and ran the tests. I am not heart-broken that not everyone will be interested in all of the minutiae.
The Scenario
For this particular set of tests, the real-life scenario is one where a user picks a screen name, and the trigger is designed to catch cases where the chosen name violates some rules. For example, it can't be any variation of "ninny-muggins" (you can certainly use your imagination here).
I created a table with 20,000 unique user names:
USE model;
GO
-- 20,000 distinct, good Names
;WITH distinct_Names AS
(
SELECT Name FROM sys.all_columns
UNION
SELECT Name FROM sys.all_objects
)
SELECT TOP (20000) Name
INTO dbo.GoodNamesSource
FROM
(
SELECT Name FROM distinct_Names
UNION
SELECT Name + 'x' FROM distinct_Names
UNION
SELECT Name + 'y' FROM distinct_Names
UNION
SELECT Name + 'z' FROM distinct_Names
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Then I created a table that would be the source for my "naughty names" to check against. In this case it's just ninny-muggins-00001 through ninny-muggins-10000:
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
I created these tables in the model database so that every time I create a database, it would exist locally, and I plan to create a lot of databases to test the scenario matrix listed above (rather than just change database settings, clear out the log, etc). Please note, if you create objects in model for testing purposes, make sure you delete those objects when you are done.
As an aside, I'm going to intentionally leave key violations and other error handling out of this, making the naïve assumption that the chosen name is checked for uniqueness long before the insert is ever attempted, but within the same transaction (just like the check against the naughty name table could have been made in advance).
To support this, I also created the following three nearly identical tables in model, for test isolation purposes:
USE model;
GO
-- AFTER (rollback)
CREATE TABLE dbo.UserNames_After_Rollback
(
UserID INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(255) NOT NULL UNIQUE,
DateCreated DATE NOT NULL DEFAULT SYSDATETIME()
);
CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name);
-- AFTER (delete)
CREATE TABLE dbo.UserNames_After_Delete
(
UserID INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(255) NOT NULL UNIQUE,
DateCreated DATE NOT NULL DEFAULT SYSDATETIME()
);
CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name);
-- INSTEAD
CREATE TABLE dbo.UserNames_Instead
(
UserID INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(255) NOT NULL UNIQUE,
DateCreated DATE NOT NULL DEFAULT SYSDATETIME()
);
CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name);
GO
And the following three triggers, one for each table:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO
You would probably want to consider additional handling to notify the user that their choice was rolled back or ignored – but this, too, is left out for simplicity.
The Test Setup
I created sample data representing the three failure rates I wanted to test, changing 10 percent to 25 and then 50, and adding these tables, too, to model:
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^
Each table has 20,000 rows, with a different mix of names that will pass and fail, and the row number column makes it easy to divide the data up into different batch sizes for different tests, but with repeatable failure rates for all of the tests.
Of course we need a place to capture the results. I chose to use a separate database for this, running each test multiple times, simply capturing duration.
CREATE DATABASE ControlDB;
GO
USE ControlDB;
GO
CREATE TABLE dbo.Tests
(
TestID INT,
DiskLayout VARCHAR(15),
RecoveryModel VARCHAR(6),
TriggerType VARCHAR(14),
[snapshot] VARCHAR(3),
FailureRate INT,
[sql] NVARCHAR(MAX)
);
CREATE TABLE dbo.TestResults
(
TestID INT,
BatchDescription VARCHAR(15),
Duration INT
);
I populated the dbo.Tests table with the following script, so that I could execute different portions to set up the four databases to match the current test parameters. Note that D:\ is an SSD, while G:\ is a 7200 RPM disk:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-)
Then it was simple to run all of the tests multiple times:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
On my system this took close to 6 hours, so be prepared to let this run its course uninterrupted. Also, make sure you don't have any active connections or query windows open against the model database, otherwise you may get this error when the script attempts to create a database:
Could not obtain exclusive lock on database 'model'. Retry the operation later.
Results
There are many data points to look at (and all queries used to derive the data are referenced in the Appendix). Keep in mind that every average duration denoted here is over 10 tests and is inserting a total of 100,000 rows into the destination table.
Graph 1 - Overall Aggregates
The first graph shows overall aggregates (average duration) for the different variables in isolation (so *all* tests using an AFTER trigger that deletes, *all* tests using an AFTER trigger that rolls back, etc).
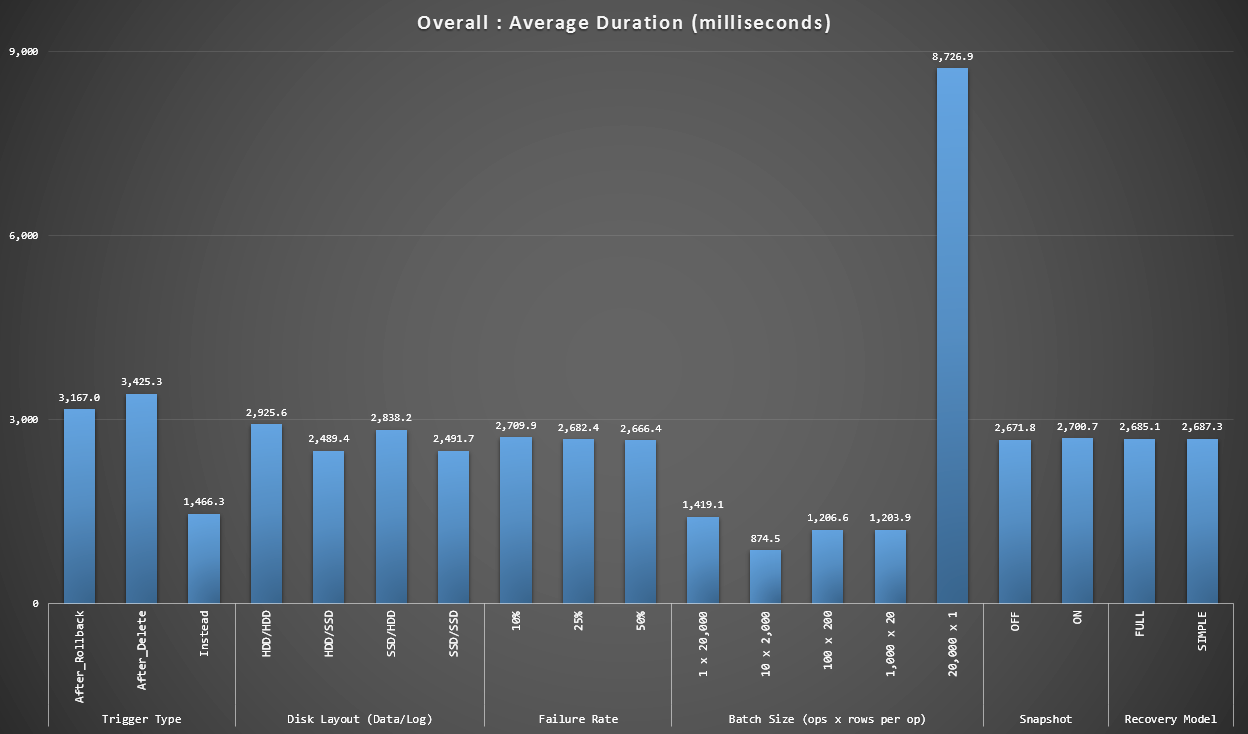
Average duration, in milliseconds, for each variable in isolation
A few things jump out at us immediately:
- The INSTEAD OF trigger here is twice as fast as both AFTER triggers.
- Having the transaction log on SSD made a bit of a difference. Location of the data file much less so.
- The batch of 20,000 singleton inserts was 7-8x slower than any other batch distribution.
- The single batch insert of 20,000 rows was slower than any of the non-singleton distributions.
- Failure rate, snapshot isolation and recovery model had little if any impact on performance.
Graph 2 - Best 10 Overall
This graph shows the fastest 10 results when every variable is considered. These are all INSTEAD OF triggers where the largest percentage of rows fail (50%). Surprisingly, the fastest (though not by a lot) had both data and log on the same HDD (not SSD). There is a mix of disk layouts and recovery models here, but all 10 had snapshot isolation enabled, and the top 7 results all involved the 10 x 2,000 row batch size.
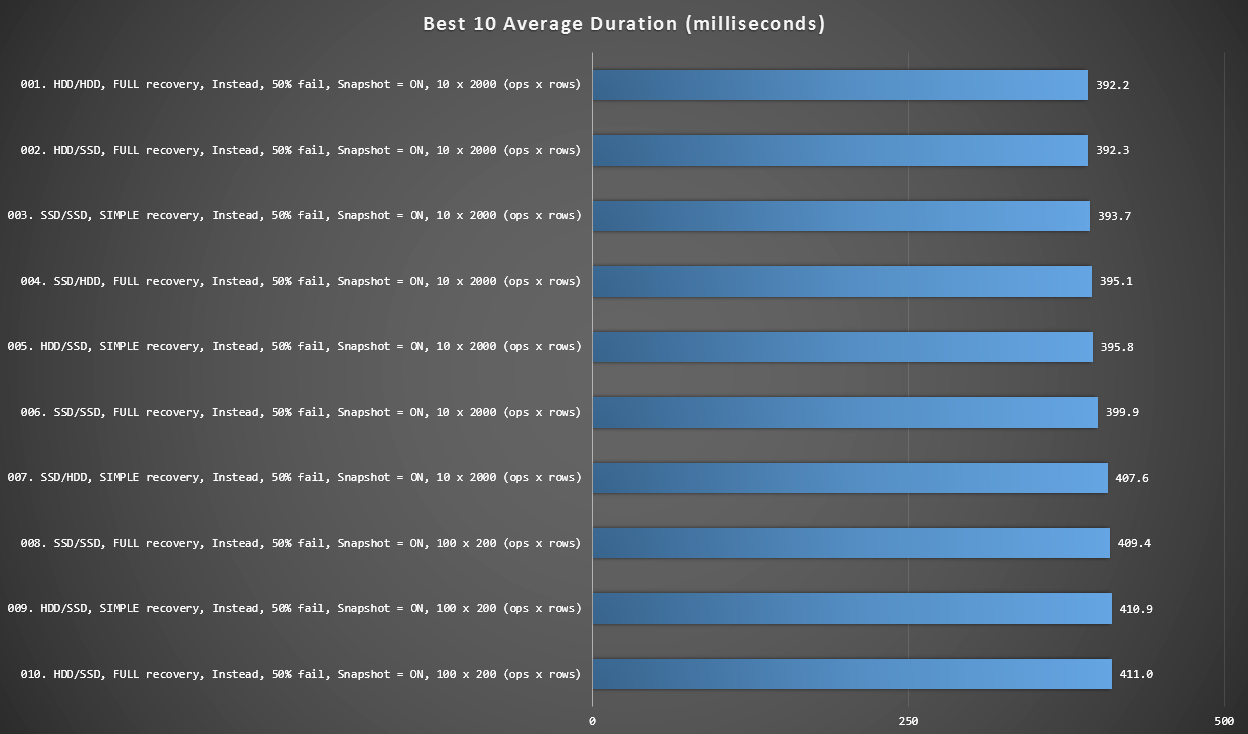
Best 10 durations, in milliseconds, considering every variable
The fastest AFTER trigger - a ROLLBACK variant with 10% failure rate in the 100 x 200 row batch size - came in at position #144 (806 ms).
Graph 3 - Worst 10 Overall
This graph shows the slowest 10 results when every variable is considered; all are AFTER variants, all involve the 20,000 singleton inserts, and all have data and log on the same slow HDD.
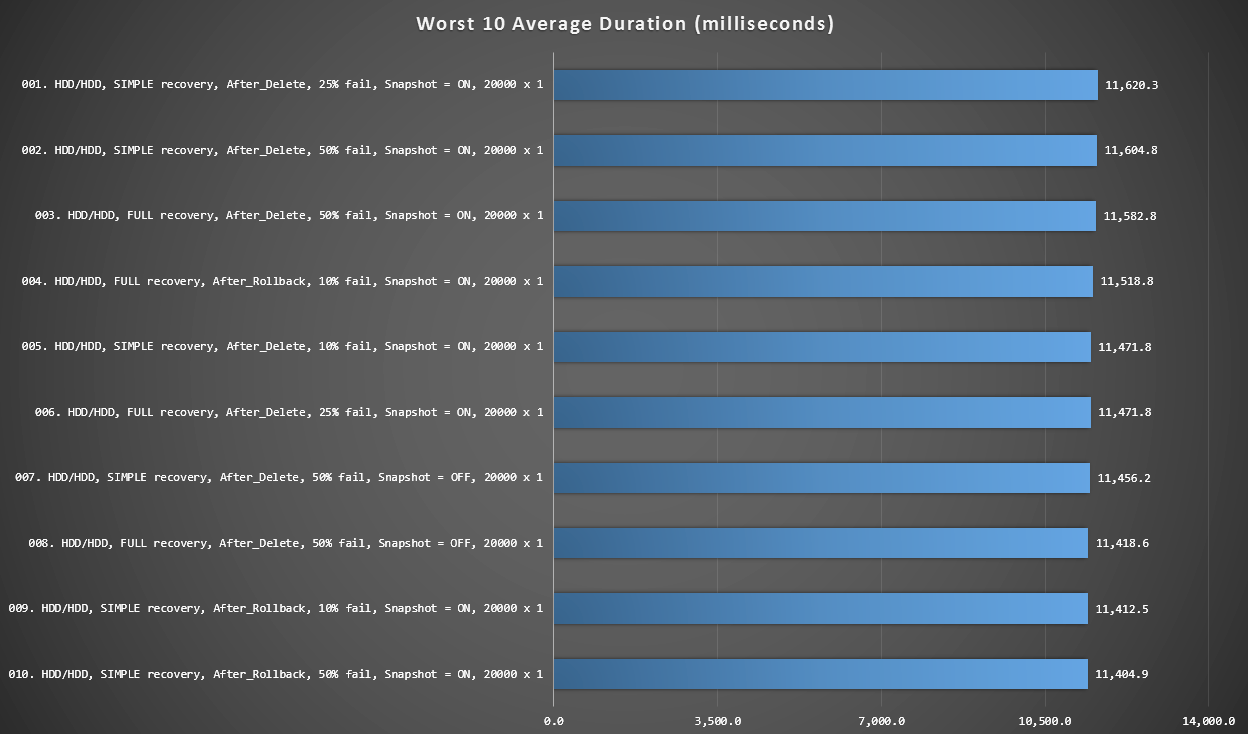
Worst 10 durations, in milliseconds, considering every variable
The slowest INSTEAD OF test was in position #97, at 5,680 ms - a 20,000 singleton insert test where 10% fail. It is interesting also to observe that not one single AFTER trigger using the 20,000 singleton insert batch size fared better - in fact the 96th worst result was an AFTER (delete) test that came in at 10,219 ms - almost double the next slowest result.
Graph 4 - Log Disk Type, Singleton Inserts
The graphs above give us a rough idea of the biggest pain points, but they are either too zoomed in or not zoomed in enough. This graph filters down to data based on reality: in most cases this type of operation is going to be a singleton insert. I thought I would break it down by failure rate and the type of disk the log is on, but only look at rows where the batch is made up of 20,000 individual inserts.
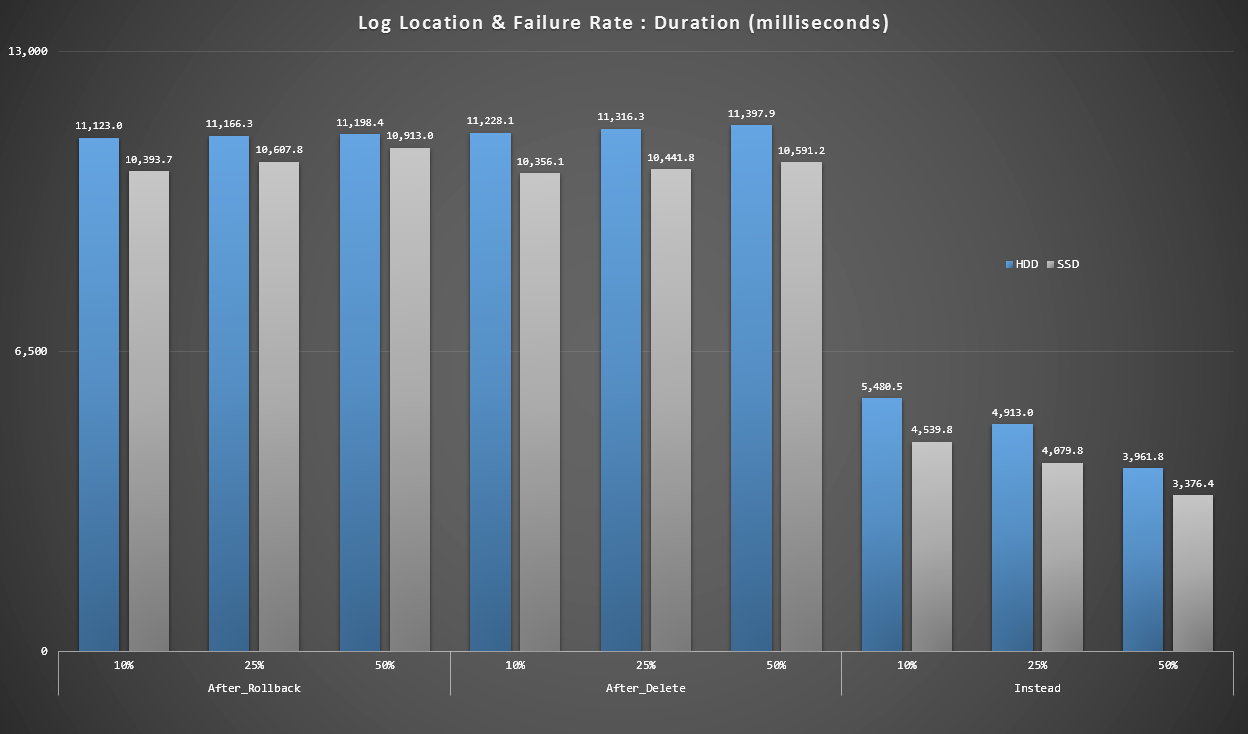
Duration, in milliseconds, grouped by failure rate and log location, for 20,000 individual inserts
Here we see that all of the AFTER triggers average in the 10-11 second range (depending on log location), while all of the INSTEAD OF triggers are well below the 6 second mark.
Conclusion
So far, it seems clear to me that the INSTEAD OF trigger is a winner in most cases - in some cases more so than others (for example, as the failure rate goes up). Other factors, such as recovery model, seem to have much less impact on overall performance.
If you have other ideas for how to break the data down, or would like a copy of the data to perform your own slicing and dicing, please let me know. If you'd like help setting this environment up so you can run your own tests, I can help with that too.
While this test shows that INSTEAD OF triggers are definitely worth considering, it isn't the whole story. I literally slapped these triggers together using the logic that I thought made the most sense for each scenario, but trigger code - like any T-SQL statement - can be tuned for optimal plans. In a follow-up post, I'll take a look at a potential optimization that may make the AFTER trigger more competitive.
Appendix
Queries used for the Results section:
Graph 1 - Overall Aggregates
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0)
FROM dbo.TestResults AS r
INNER JOIN dbo.Loops AS l
ON r.LoopID = l.LoopID
GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop);
SELECT t.IsSnapshot, AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
GROUP BY t.IsSnapshot;
SELECT t.RecoveryModel, AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
GROUP BY t.RecoveryModel;
SELECT t.DiskLayout, AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
GROUP BY t.DiskLayout;
SELECT t.TriggerType, AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
GROUP BY t.TriggerType;
SELECT t.FailureRate, AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
GROUP BY t.FailureRate;
Graph 2 & 3 - Best & Worst 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp;
Graph 4 - Log Disk Type, Singleton Inserts
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;
1 thought on “Making the Case for INSTEAD OF Triggers – Part 1”
Comments are closed.

you may want to consider the following article from one of your colleagues:
https://sqlperformance.com/2015/09/sql-plan/instead-of-triggers