
Observer Overhead and Wait Type Symptoms
Many people use wait statistics as part of their overall performance troubleshooting methodology, as do I, so the question I wanted to explore in this post is around wait types associated with observer overhead. By observer overhead, I mean the impact to SQL Server workload throughput caused by SQL Profiler, Server-side traces or Extended Event sessions. For more on the subject of observer overhead, see the following two posts from my colleague Jonathan Kehayias:
- Measuring “Observer Overhead” of SQL Trace vs. Extended Events
- Impact of the query_post_execution_showplan Extended Event in SQL Server 2012
So in this post I would like to walk through a few variations of observer overhead and see if we can find consistent wait types associated with the measured degradation. There are a variety of ways that SQL Server users implement tracing in their production environments, so your results may vary, but I did want to cover a few broad categories and report back on what I found:
- SQL Profiler session usage
- Server-side trace usage
- Server-side trace usage, writing to a slow I/O path
- Extended Events usage with a ring buffer target
- Extended Events usage with a file target
- Extended Events usage with a file target on a slow I/O path
- Extended Events usage with a file target on a slow I/O path with no event loss
You can likely think up other variations on the theme and I invite you to share any interesting findings regarding observer overhead and wait stats as a comment in this post.
Baseline
For the test, I used a VMware virtual machine with four vCPUs and 4GB of RAM. My virtual machine guest was on OCZ Vertex SSDs. The operating system was Windows Server 2008 R2 Enterprise and the version of SQL Server is 2012, SP1 CU4.
As for the “workload” I’m using a read-only query in a loop against the 2008 Credit sample database, set to GO 10,000,000 times.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000I’m also executing this query via 16 concurrent sessions. The end result on my test system is 100% CPU utilization across all vCPUs on the virtual guest and an average of 14,492 batch requests per second over a 2 minute period.
Regarding the event tracing, in each test I used Showplan XML Statistics Profile for the SQL Profiler and Server-side trace tests – and query_post_execution_showplan for Extended Event sessions. Execution plan events are very expensive, which is precisely why I chose them so that I could see if under extreme circumstances whether or not I could derive wait type themes.
For testing wait type accumulation over a test period, I used the following query. Nothing fancy – just clearing the stats, waiting 2 minutes and then collecting the top 10 wait accumulations for the SQL Server instance over the degradation test period:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC;Notice I’m not filtering out background wait types that are typically filtered out, and this is because I didn’t want to eliminate something that is normally benign – but in this circumstance actually points to a real area to investigate further.
SQL Profiler Session
The following table shows the before-and-after batch requests per second when enabling a local SQL Profiler trace tracking Showplan XML Statistics Profile (running on the same VM as the SQL Server instance):
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Session Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 1,416 |
You can see that the SQL Profiler trace causes a significant drop in throughput.
As for accumulated wait time over that same period, the top wait types were as follows (as with the rest of the tests in this article, I did a few test runs and the output was generally consistent):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67,142 | 1,149,824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237,003 |
| SLEEP_TASK | 313 | 180,449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120,086 |
| LAZYWRITER_SLEEP | 120 | 120,059 |
| DIRTY_PAGE_POLL | 1,198 | 120,038 |
| HADR_WORK_QUEUE | 12 | 120,015 |
| LOGMGR_QUEUE | 937 | 120,011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,006 |
The wait type that jumps out to me is TRACEWRITE – which is defined by Books Online as a wait type that “occurs when the SQL Trace rowset trace provider waits for either a free buffer or a buffer with events to process”. The rest of the wait types look like standard background wait types that one would typically filter out of your result set. What’s more, I talked about a similar issue with over-tracing in an article back in 2011 called Observer overhead – the perils of too much tracing – so I was familiar with this wait type sometimes properly pointing to observer overhead issues. Now in that particular case I blogged about, it wasn’t SQL Profiler, but another application using the rowset trace provider (inefficiently).
Server-Side Trace
That was for SQL Profiler, but what about server-side trace overhead? The following table shows the before-and-after batch requests per second when enabling a local server-side trace writing to a file:
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 4,015 |
The top wait types were as follows (I did a few test runs and the output was consistent):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237,015 |
| SLEEP_TASK | 253 | 180,871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,046 |
| HADR_WORK_QUEUE | 12 | 120,042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,021 |
| XE_DISPATCHER_WAIT | 3 | 120,006 |
| WAITFOR | 1 | 120,000 |
| LOGMGR_QUEUE | 931 | 119,993 |
| DIRTY_PAGE_POLL | 1,193 | 119,958 |
| XE_TIMER_EVENT | 55 | 119,954 |
This time we don’t see TRACEWRITE (we’re using a file provider now) and the other trace-related wait type, the undocumented SQLTRACE_INCREMENTAL_FLUSH_SLEEP climbed up – but in comparison to the first test, has very similar accumulated wait time (120,046 vs. 120,006) – and my colleague Erin Stellato (@erinstellato) talked about this particular wait type in her post Figuring Out When Wait Statistics Were Last Cleared. So looking at the other wait types, none are jumping out as a reliable red flag.
Server-Side Trace writing to a slow I/O path
What if we put the server-side trace file on slow disk? The following table shows the before-and-after batch requests per second when enabling a local server-side trace that writes to a file on a USB stick:
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 260 |
As we can see – the performance is significantly degraded – even compared to the previous test.
The top wait types were as follows:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351,174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2,273 | 299,995 |
| SLEEP_TASK | 240 | 194,264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181,458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125,007 |
| LAZYWRITER_SLEEP | 63 | 124,437 |
| LOGMGR_QUEUE | 941 | 120,559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120,516 |
| WAITFOR | 1 | 120,515 |
| DIRTY_PAGE_POLL | 1,204 | 120,513 |
One wait type that jumps out for this test is the undocumented SQLTRACE_FILE_BUFFER. Not much documented on this one, but based on the name, we can make an educated guess (especially given this particular test’s configuration).
Extended Events to the ring buffer target
Next let’s review the findings for Extended Event session equivalents. I used the following session definition:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER
ADD EVENT sqlserver.query_post_execution_showplan,
ADD TARGET package0.ring_buffer(SET max_events_limit=(1000))
WITH (STARTUP_STATE=ON);
GOThe following table shows the before-and-after batch requests per second when enabling an XE session with a ring buffer target (capturing the query_post_execution_showplan event):
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 4,737 |
The top wait types were as follows:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299,992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237,006 |
| SLEEP_TASK | 240 | 181,739 |
| LAZYWRITER_SLEEP | 120 | 120,219 |
| HADR_WORK_QUEUE | 12 | 120,038 |
| DIRTY_PAGE_POLL | 1,198 | 120,035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,011 |
| LOGMGR_QUEUE | 936 | 120,008 |
| WAITFOR | 1 | 120,001 |
Nothing jumped out as XE-related, only background task “noise”.
Extended Events to a file target
What about changing the session to use a file target instead of a ring buffer target? The following table shows the before-and-after batch requests per second when enabling an XE session with a file target instead of a ring buffer target:
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 4,299 |
The top wait types were as follows:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2,103 | 299,996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237,003 |
| SLEEP_TASK | 253 | 180,663 |
| LAZYWRITER_SLEEP | 120 | 120,187 |
| HADR_WORK_QUEUE | 12 | 120,029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,011 |
| WAITFOR | 1 | 120,001 |
| XE_TIMER_EVENT | 59 | 119,966 |
| LOGMGR_QUEUE | 935 | 119,957 |
Nothing, with the exception of XE_TIMER_EVENT, jumped out as XE-related. Bob Ward’s Wait Type Repository refers this one as safe to ignore unless there was something possible wrong – but realistically would you notice this usually-benign wait type if it was in 9th place on your system during a performance degradation? And what if you’re already filtering it out because of its normally benign nature?
Extended Events to a slow I/O path file target
Now what if I put the file on a slow I/O path? The following table shows the before-and-after batch requests per second when enabling an XE session with a file target on a USB stick:
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 4,386 |
The top wait types were as follows:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237,046 |
| SLEEP_TASK | 253 | 180,719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120,427 |
| LAZYWRITER_SLEEP | 120 | 120,190 |
| HADR_WORK_QUEUE | 12 | 120,025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,011 |
| WAITFOR | 1 | 120,002 |
| DIRTY_PAGE_POLL | 1,197 | 119,977 |
| XE_TIMER_EVENT | 59 | 119,949 |
Again, nothing XE-related jumping out except for the XE_TIMER_EVENT.
Extended Events to a slow I/O path file target, no event loss
The following table shows the before-and-after batch requests per second when enabling an XE session with a file target on a USB stick, but this time without allowing event loss (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – which is not recommended and you’ll see in the results why that might be:
| Baseline Batch Requests per Second (2 minute average) |
SQL Profiler Batch Requests per Second (2 minute average) |
|---|---|
| 14,492 | 539 |
The top wait types were as follows:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8,773 | 1,707,845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237,003 |
| SLEEP_TASK | 337 | 180,446 |
| LAZYWRITER_SLEEP | 120 | 120,032 |
| DIRTY_PAGE_POLL | 1,198 | 120,026 |
| HADR_WORK_QUEUE | 12 | 120,009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,006 |
| WAITFOR | 1 | 120,000 |
| XE_TIMER_EVENT | 59 | 119,944 |
With the extreme throughput reduction, we see XE_BUFFERMGR_FREEBUF_EVENT jump to the number one position on our accumulated wait time results. This one is documented in Books Online, and Microsoft tells us that this event is associated with XE sessions configured for no event loss, and where all buffers in the session are full.
Observer Impact
Wait types aside, it was interesting to note what impact each observation method had on our workload's ability to process batch requests:
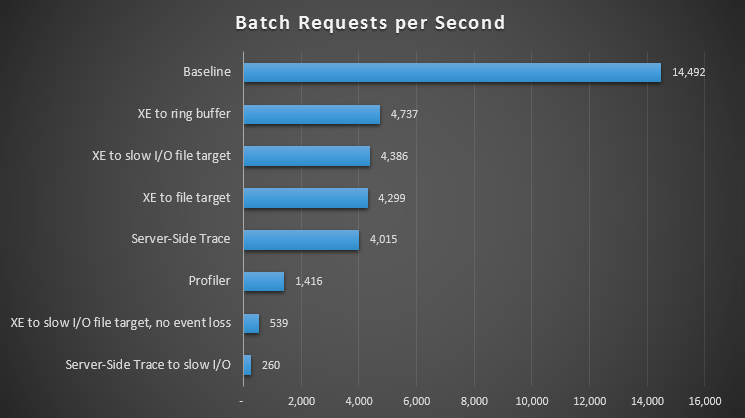
Impact of different observation methods on batch requests per second
For all approaches, there was a significant – but not shocking – hit compared to our baseline (no observation); the most pain, however, was felt when using Profiler, when using Server-Side Trace to a slow I/O path, or Extended Events to a file target on a slow I/O path – but only when configured for no event loss. With event loss, this setup actually performed on par with a file target to a fast I/O path, presumably because it was able to drop a lot more events.
Summary
I didn’t test every possible scenario and there certainly are other interesting combinations (not to mention different behaviors based on SQL Server version), but the key conclusion I take away from this exploration is that you cannot always rely on an obvious wait type accumulation pointer when facing an observer overhead scenario. Based on the tests in this post, only three out of seven scenarios manifested a specific wait type that could potentially help point you in the right direction. Even then – these tests were on a controlled system – and oftentimes people filter out the aforementioned wait types as benign background types – so you might not see them at all.
Given this, what can you do? For performance degradation without clear or obvious symptoms, I recommend widening the scope to ask about traces and XE sessions (as an aside – I also recommend widening your scope if the system is virtualized or may have incorrect power options). For example, as part of troubleshooting a system, check sys.[traces] and sys.[dm_xe_sessions] to see if anything is running on the system that is unexpected. It is an extra layer to what you need to worry about, but doing a few quick validations may save you a significant amount of time.
11 thoughts on “Observer Overhead and Wait Type Symptoms”
Comments are closed.

The problem with wait stats is that they show you how long SQL Server was doing *nothing*. What you want to know, though, is how long it was doing *something* (and what). They especially do not show you CPU time and IO durations.
Programmers would never use such methods. They would use a profiler. SQL Server does not have such a thing.
That's why interpreting waits is hard and unreliable.
Wait stats are very useful for pointing to a variety of different problem-areas (for further investigation) – both at the SQL Server instance and task level (or even session level via XE). Per your CPU and IO comment – they are more limited for high CPU scenarios I agree, but I do find them useful as an initial pointer for I/O issues (for example – finding average overall latency for PAGEIOLATCH waits (or even at the task level for sys.dm_os_waiting_tasks).
"Programmers would never use such methods"
That's why DBAs have a lot of work cleaning up shit of programmers, but that's maybe a little personal frustration..
May I remind you that what matters is response time: not just CPU time nor just wait time. At least for users and customers I run into.
Since response time is those two added up: they both matter. In this particular case what Joe shows for the 'slow' examples, are the waits that are relevant to the slow performance, and maybe some background/async waits happening.
On the other hand, you are right about CPU: the fact that tracing makes this test running slower can indeed very likely be attributed to CPU overhead of the tracing method itself. And there you have a point: (CPU) profiling would show that. SQL Server itself has no CPU profiler, that is true, but there are many tools available on the OS level that can help here: XPerf, kernrate, Vtune, CodeAnalyst. In combination with sqlserver debug symbols of course.
Interpreting waits is not hard nor unreliable: you have to add CPU time to the mix, and know what waits matter: which ones are in the 'path' of your response time.
I mostly agree with you. Waits *are* useful. What I complain about is that you can't find out about CPU (like you said) and that you need to decode the waits to find out what matters. I have found this to be not straight forward at all. Lots of experience required to spot patterns and conditions. You can't just take the top waits because there are waits that fall under the "nothing being done" category. You want the "something being done" waits.
I agree that response time is important. That's why I would like to see what the total batch execution time (which is easy to find out) is comprised of (unable to find out). That is the information that you want. Waits are one or two steps removed from that.
I also found perfview to be a great tool for that. You can even find out how much time is spent decoding compressed rows, doing calculations, doing index seeks and so on. I just wish there was a higher-level equivalent.
Good stuff. I pay a lot of attention to observer overhead after two early mistakes of mine: 1) stored procedures I wrote to capture SQL plans of heavy hitters pushed most other database contents out of bpool cache, ratcheting up physical IO and tanking performance. 2) An investigation into heavy tlog use in a simple recovery mode database with fn_dblog delayed log file truncation, contributing to the tlog filling to its max size.
Strange that in these examples "extended events to a slow IO path file target" showed a higher average batches/sec at 4386 than "extended events to a file target" at 4,299. Was the file target sharing a LUN with database file(s) or the TLOG of the test database? Or, was it on the OS disk? Or sharing a LUN with system database files?
Thanks for the feedback.
Per your question – the "extended events to a file target" was to the same volume as the data and log files – and overall VMware guest disk was all on one path – vs. the slow IO path which was to a separate path. My initial thoughts were that the numbers are close enough to make me wonder if the difference is statistically significant. But yes, in advance of testing I would not have anticipated these results. I think a few more test iterations or isolated paths may show differences.
Yep, if that's the setup there is a high likelihood that IO path overload was responsible for the "slow path" beating the "regular path". Remember that typical IO LUN max queue depth is 32. And that 32 is AFTER demotion by the HBA. If your HBA is set to 512k max xfer size (the default), and SQL Server issues 16 outstanding 1 mb IOs concurrently – it becomes 32 512k IOs due to splitting at the HBA driver level. If another IO is submitted to the LUN while those 32 are outstanding, disk IO gets throttled. QLogic HBAs are especially punitive. That's why I've been on the warpath lately about making sure folks at least evaluate their options for increasing max xfer size – QLogic and Emulex both allow up to 2 mb max xfer size now. And Emulex allows up to 4 mb max xfer size. This especially benefits backup IO… but other IO during high concurrency can also benefit – especially if it means avoiding a QFULL.
Nice post. Another convincing graph to refrain from using Profiler :)
Interestingly, when I did some benchmarks on this myself, ring bugger turned out to be imposing more overhead than then file target.
Which in tun states again, that in the end every system behaves a little different. – Still, the differences for XE and SQLTrace are too big and by nature/architecture. :-)
Nice post.
Can i please ask, should i be worries if the top %wait type on my sql 2012 box is the SP_SERVER_DIAGNOSTICS_SLEEP wait type?
I can see that the system_health extended event logging feature is turned on so i am guessing thats what is triggering these
wait events.
Kind regards,
Matt
Thanks Matt,
This is a benign wait type. And you are correct that the system_health event session includes a capture of sp_server_diagnostics.
Joe