
The SQL Server Query Store
Benjamin Nevarez is an independent consultant based in Los Angeles, California who specializes in SQL Server query tuning and optimization. He is the author of “SQL Server 2014 Query Tuning & Optimization” and “Inside the SQL Server Query Optimizer” and co-author of “SQL Server 2012 Internals”. With more than 20 years of experience in relational databases, Benjamin has also been a speaker at many SQL Server conferences, including the PASS Summit, SQL Server Connections and SQLBits. Benjamin’s blog can be found at http://www.benjaminnevarez.com and he can also be reached by e-mail at admin at benjaminnevarez dot com and on twitter at @BenjaminNevarez.
Have you ever found a plan regression after a SQL Server upgrade and wanted to know what the previous execution plan was? Have you ever had a query performance problem due to the fact that a query unexpectedly got a new execution plan? At the last PASS Summit, Conor Cunningham uncovered a new SQL Server feature, which can be helpful in solving performance problems related to these and other changes in execution plans.
This feature, called the Query Store, can help you with performance problems related to plan changes and will be available soon on SQL Azure and later on the next version of SQL Server. Although it is expected to be available on the Enterprise Edition of SQL Server, it is not yet known if it will be available on Standard or any other editions. To understand the benefits of the Query Store, let me talk briefly about the query troubleshooting process.
Why is a Query Slow?
Once you have detected that a performance problem is because a query is slow, the next step is to find out why. Obviously not every problem is related to plan changes. There could be multiple reasons why a query that has been performing well is suddenly slow. Sometimes this could be related to blocking or a problem with other system resources. Something else may have changed but the challenge may be to find out what. Many times we don’t have a baseline about system resource usage, query execution statistics or performance history. And usually we have no idea what the old plan was. It may be the case that some change, for example, data, schema or query parameters, made the query processor produce a new plan.
Plan Changes
At the session, Conor used the Picasso Database Query Optimizer Visualizer tool, although didn’t mention it by name, to show why the plans in the same query changed, and explained the fact that different plans could be selected for the same query based on the selectivity of their predicates. He even mentioned that the query optimizer team uses this tool, which was developed by the Indian Institute of Science. An example of the visualization (click to enlarge):
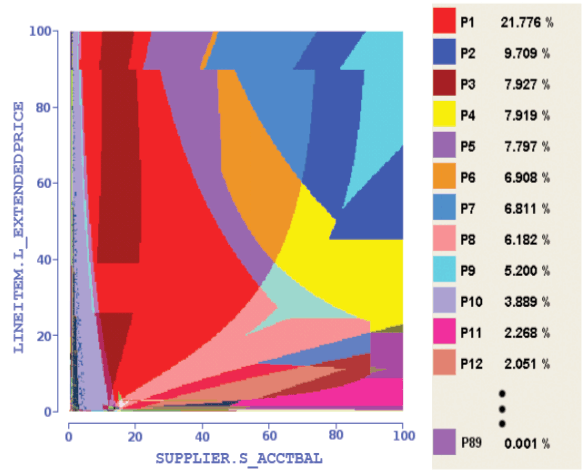 Picasso Database Query Optimizer Visualizer
Picasso Database Query Optimizer Visualizer
Each color in the diagram is a different plan, and each plan is selected based on the selectivity of the predicates. An important fact is when a boundary is crossed in the graph and a different plan is selected, most of the times the cost and performance of both plans should be similar, as the selectivity or estimated number of rows only changed slightly. This could happen for example when a new row is added to a table which qualifies for the used predicate. However, in some cases, mostly due to limitations in the query optimizer cost model in which it is not able to model something correctly, the new plan can have a large performance difference compared to the previous one, creating a problem for your application. By the way, the plans shown on the diagram are the final plan selected by the query optimizer, don’t confuse this with the many alternatives the optimizer has to consider to select only one.
An important fact, in my opinion, which Conor didn’t cover directly, was the change of plans due to regressions after changes on cumulative updates (CUs), service packs, or version upgrades. A major concern that comes to mind with changes inside the query optimizer is plan regressions. The fear of plan regressions has been considered the biggest obstacle to query optimizer improvements. Regressions are problems introduced after a fix has been applied to the query optimizer, and sometimes referred as the classic “two or more wrongs make a right.” This can happen when, for example, two bad estimations, one overestimating a value and the second one underestimating it, cancel each other out, luckily giving a good estimate. Correcting only one of these values may now lead to a bad estimation which may negatively impact the choice of plan selection, causing a regression.
What Does the Query Store Do?
Conor mentioned the Query Store performs and can help with the following:
- Store the history of query plans in the system;
- Capture the performance of each query plan over time;
- Identify queries that have “gotten slower recently”;
- Allow you to force plans quickly; and,
- Make sure this works across server restarts, upgrades, and query recompiles.
So this feature not only stores the plans and related query performance information, but can also help you to easily force an old query plan, which in many cases can solve a performance problem.
How to Use the Query Store
You need to enable the Query Store by using the ALTER DATABASE CURRENT SET QUERY_STORE = ON; statement. I tried it in my current SQL Azure subscription, but the statement returned an error as it seems that the feature is not available yet. I contacted Conor and he told me that the feature will be available soon.
Once the Query Store is enabled, it will start collecting the plans and query performance data and you can analyze that data by looking at the Query Store tables. I can currently see those tables on SQL Azure but, since I was not able to enable the Query Store, the catalogs returned no data.
You can analyze the information collected either proactively to understand the query performance changes in your application, or retroactively in case you have a performance problem. Once you identify the problem you can use traditional query tuning techniques to try to fix the problem, or you can use the sp_query_store_force_plan stored procedure to force a previous plan. The plan has to be captured in the Query Store to be forced, which obviously means it is a valid plan (at least when it was collected; more on that later) and it was generated by the query optimizer before. To force a plan you need the plan_id, available in the sys.query_store_plan catalog. Once you look at the different metrics stored, which are very similar to what is stored for example in sys.dm_exec_query_stats, you can make the decision to optimize for a specific metric, like CPU, I/O, etc. Then you can simply use a statement like this:
EXEC sys.sp_query_store_force_plan @query_id = 1, @plan_id = 1;
This is telling SQL Server to force plan 1 on query 1. Technically you could do the same thing using a plan guide, but it would be more complicated and you would have to manually collect and find the required plan in the first place.
How Does the Query Store Work?
Actually forcing a plan uses plan guides in the background. Conor mentioned that “when you compile a query, we implicitly add a USE PLAN hint with the fragment of the XML plan associated with that statement.” So you no longer need to use a plan guide anymore. Also keep in mind that, same as using a plan guide, it is not guaranteed to have exactly the forced plan but at least something similar to it. For a reminder of how plan guides work take a look at this article. In addition, you should be aware that there are some cases where forcing a plan does not work, a typical example being when the schema has changed, i.e. if a stored plan uses an index but the index no longer exists. In this case SQL Server can not force the plan, will perform a normal optimization and it will record the fact that the forcing the plan operation failed in the sys.query_store_plan catalog.
Architecture
Every time SQL Server compiles or executes a query, a message is sent to the Query Store. This is shown next.
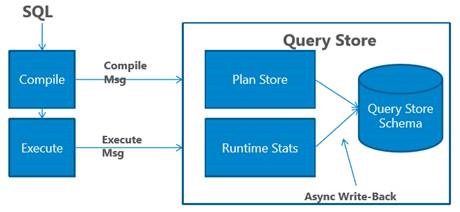 Query Store Workflow Overview
Query Store Workflow Overview
The compile and execution information is kept in memory first and then saved to disk, depending on the Query Store configuration (the data is aggregated according to the INTERVAL_LENGTH_MINUTES parameter, which defaults to one hour, and flushed to disk according to the DATA_FLUSH_INTERVAL_SECONDS parameter). The data can also be flushed to disk if there is memory pressure on the system. In any case you will be able to access all of the data, both in memory and disk, when you run the sys.query_store_runtime_stats catalog.
Catalogs
The collected data is persisted on disk and stored in the user database where the Query Store is enabled (and settings are stored in sys.database_query_store_options. The Query Store catalogs are:
sys.query_store_query_text |
Query text information |
sys.query_store_query |
Query text plus the used plan affecting SET options |
sys.query_store_plan |
Execution plans, including history |
sys.query_store_runtime_stats |
Query runtime statistics |
sys.query_store_runtime_stats_interval |
Start and end time for intervals |
sys.query_context_settings |
Query context settings information |
Query Store views
Runtime statistics capture a whole slew of metrics, including the average, last, min, max, and standard deviation. Here is the full set of columns for sys.query_store_runtime_stats:
runtime_stats_id |
plan_id |
runtime_stats_interval_id |
||
execution_type |
execution_type_desc |
first_execution_time |
last_execution_time |
count_executions |
avg_duration |
last_duration |
min_duration |
max_duration |
stdev_duration |
avg_cpu_time |
last_cpu_time |
min_cpu_time |
max_cpu_time |
stdev_cpu_time |
avg_logical_io_reads |
last_logical_io_reads |
min_logical_io_reads |
max_logical_io_reads |
stdev_logical_io_reads |
avg_logical_io_writes |
last_logical_io_writes |
min_logical_io_writes |
max_logical_io_writes |
stdev_logical_io_writes |
avg_physical_io_reads |
last_physical_io_reads |
min_physical_io_reads |
max_physical_io_reads |
stdev_physical_io_reads |
avg_clr_time |
last_clr_time |
min_clr_time |
max_clr_time |
stdev_clr_time |
avg_dop |
last_dop |
min_dop |
max_dop |
stdev_dop |
avg_query_max_used_memory |
last_query_max_used_memory |
min_query_max_used_memory |
max_query_max_used_memory |
stdev_query_max_used_memory |
avg_rowcount |
last_rowcount |
min_rowcount |
max_rowcount |
stdev_rowcount |
Columns in sys.query_store_runtime_stats
This data is only captured when query execution ends. The Query Store also considers the query's SET options, which can impact the choice of an execution plan, as they affect things like the results of evaluating constant expressions during the optimization process. I cover this topic in a previous post.
Conclusion
This will definitely be a great feature and something I’d like to try as soon as possible (by the way, Conor’s demo shows “SQL Server 15 CTP1” but those bits are not publicly available). The Query Store can be useful for upgrades which could be a CU, service pack, or SQL Server version, as you can analyze the information collected by the Query Store before and after to see if any query has regressed. (And if the feature is available in lower editions, you could even do this in a SKU upgrade scenario.) Knowing this can help you to take some specific action depending on the problem, and one of those solutions could be to force the previous plan as explained before.
10 thoughts on “The SQL Server Query Store”
Comments are closed.

Although I like the deployment model of "always the freshest bits"
I dread the day new features will be Cloud-first, Azure-only
forcing us into the cloud.
Hi George, cloud-first is already what's happening – Query Store, row-level security, data masking, and others I can't quite disclose just yet. This makes some great business sense – not only in terms of dog-fooding (a feature better be ready before they roll it out to their own, production Azure servers) but also because broad cloud deployments are much more automated and controlled than you or I upgrading our own servers. Now they don't have to wait for people to proceed with their own upgrades before *lots* of people have access to the feature, can try it out and give feedback, etc. So you will continue seeing the service get some features before they are ever made available in the box, primarily because you can't buy a new version of the box every time they ship a new feature. Feature development simply doesn't line up nicely with the release cycle, which is driven by the business side, not the engineering side.
On the plus side, I have not heard any indication that any feature will ever be cloud-only. And of course some features will continue to be box-first (a forthcoming example, I predict, will be stretch tables) or box-only (In-Memory OLTP). Another plus to cloud-first is you can try out new features with very minimal investment and before you could ever put them onto even a staging or QA server in your own environment.
I really don't think they are forcing us into the cloud. But they are definitely trying to make it more compelling.
Benjamin,
Do you know if adhoc queries plan will be stored in the query store? Will there be a limit to the size and/or number of plans stored in the Query Store. We are having to trim our plan cache because of many 1 use adhoc plans getting stored.
Thanks
Chris
Chris,
Have you tried the “optimize for ad hoc workloads” configuration option instead, to help alleviate the plan cache problem? Regarding the Query Store, the data will be saved on disk and we will be able to set the size limit of the data collected. Conor mentioned that there will also be admission policies to control what is collected, for example to ignore cheap queries like ad hoc queries, in addition to cleanup policies to delete only specific data.
Regards,
Ben
Benjamin,
We do have that set. I was at Connor's session in Seattle but could not remember the exact details of the store.
Thanks
Chris
At SQLSAT Austin, for which editions would be supported, he said he couldn't say, but that"you should be enthusiastic". Also, the video of the session is at http://usergroup.tv/videos/query-store-a-new-sql-query-tuning-feature