
Readable Secondaries on a Budget
Availability Groups, introduced in SQL Server 2012, represent a fundamental shift in the way we think about both high availability and disaster recovery for our databases. One of the great things made possible here is offloading read-only operations to a secondary replica, so that the primary read/write instance is not bothered by pesky things like end user reporting. Setting this up is not simple, but is a whole lot easier and more maintainable than previous solutions (raise your hand if you liked setting up mirroring and snapshots, and all the perpetual maintenance involved with that).
People get very excited when they hear about Availability Groups. Then reality hits: the feature requires the Enterprise Edition of SQL Server (as of SQL Server 2014, anyway). Enterprise Edition is expensive, especially if you have a lot of cores, and especially since the elimination of CAL-based licensing (unless you were grandfathered in from 2008 R2, in which case you are limited to the first 20 cores). It also requires Windows Server Failover Clustering (WSFC), a complication not just for demonstrating the technology on a laptop, but also requiring the Enterprise Edition of Windows, a domain controller, and a whole bunch of configuration to support clustering. And there are new requirements around Software Assurance, too; an added cost if you want your standby instances to be compliant.
Some customers can't justify the price. Others see the value, but simply can't afford it. So what are these users to do?
Your New Hero: Log Shipping
Log shipping has been around for ages. It's simple and it just works. Almost always. And aside from bypassing the licensing costs and configuration hurdles presented by Availability Groups, it can also avoid the 14-byte penalty that Paul Randal (@PaulRandal) talked about in this week's SQLskills Insider newsletter (October 13, 2014).
One of the challenges people have with using the log shipped copy as a readable secondary, though, is that you have to kick all the current users out in order to apply any new logs – so either you have users getting annoyed because they are repeatedly disrupted from running queries, or you have users getting annoyed because their data is stale. This is because people limit themselves to a single readable secondary.
It doesn't have to be that way; I think there is a graceful solution here, and while it might require a lot more leg work up front than, say, turning on Availability Groups, it will surely be an attractive option for some.
Basically, we can set up a number of secondaries, where we will log ship and make just one of them the "active" secondary, using a round-robin approach. The job that ships the logs knows which one is currently active, so it only restores new logs to the "next" server using the WITH STANDBY option. The reporting application uses the same information to determine at runtime what the connection string should be for the next report the user runs. When the next log backup is ready, everything shifts by one, and the instance that will now become the new readable secondary gets restored using WITH STANDBY.
To keep the model uncomplicated, let's say we have four instances that serve as readable secondaries, and we take log backups every 15 minutes. At any one time, we'll have one active secondary in standby mode, with data no older than 15 minutes old, and three secondaries in standby mode that aren't servicing new queries (but may still be returning results for older queries).
This will work best if no queries are expected to last longer than 45 minutes. (You may need to adjust these cycles depending on the nature of your read-only operations, how many concurrent users are running longer queries, and whether it is ever possible to disrupt users by kicking everyone out.)
It will also work best if consecutive queries run by the same user can change their connection string (this is logic that will need to be in the application, though you could use synonyms or views depending on the architecture), and contain different data that has changed in the meantime (just like if they were querying the live, constantly-changing database).
With all of these assumptions in mind, here is an illustrative sequence of events for the first 75 minutes of our implementation:
| time | events | visual |
|---|---|---|
| 12:00 (t0) |
|
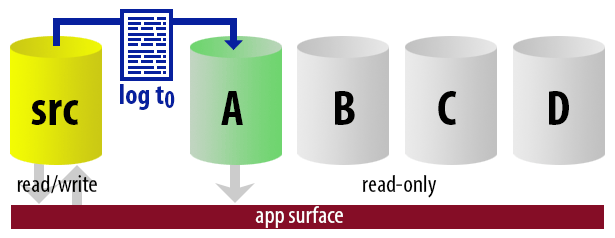 |
| 12:15 (t1) |
|
 |
| 12:30 (t2) |
|
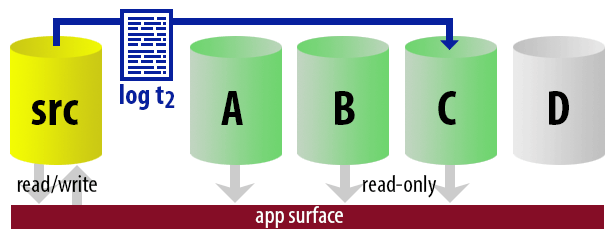 |
| 12:45 (t3) |
|
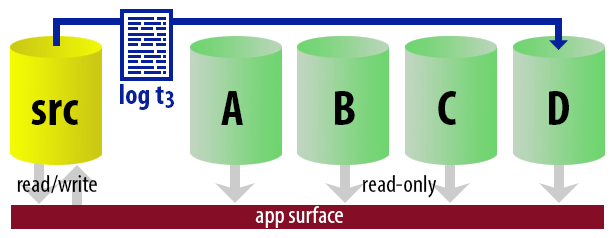 |
| 13:00 (t4) |
|
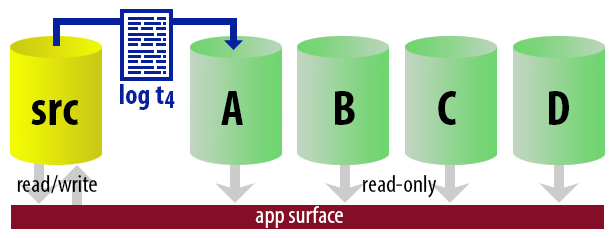 |
That may seem simple enough; writing the code to handle all that is a little more daunting. A rough outline:
- On the primary server (I'll call it
BOSS), create a database. Before even thinking about going any further, turn on Trace Flag 3226 to prevent successful backup messages from littering SQL Server's error log. - On
BOSS, add a linked server for each secondary (I'll call themPEON1->PEON4). - Somewhere accessible to all servers, create a file share to store database/log backups, and ensure the service accounts for each instance have read/write access. Also, each secondary instance needs to have a location specified for the standby file.
- In a separate utility database (or MSDB, if you prefer), create tables that will hold configuration information about the database(s), all of the secondaries, and log backup and restore history.
- Create stored procedures that will back up the database and restore to the secondaries
WITH NORECOVERY, and then apply one logWITH STANDBY, and mark one instance as the current standby secondary. These procedures can also be used to re-initialize the whole log shipping setup in the event anything goes wrong. - Create a job that will run every 15 minutes, to perform the tasks described above:
- backup the log
- determine which secondary to apply any unapplied log backups to
- restore those logs with the appropriate settings
- Create a stored procedure (and/or a view?) that will tell the calling application(s) which secondary they should use for any new read-only queries.
- Create a cleanup procedure to clear out log backup history for logs that have been applied to all secondaries (and perhaps also to move or purge the files themselves).
- Augment the solution with robust error handling and notifications.
Step 1 – create a database
My primary instance is Standard Edition, named .\BOSS. On that instance I create a simple database with one table:
USE [master];
GO
CREATE DATABASE UserData;
GO
ALTER DATABASE UserData SET RECOVERY FULL;
GO
USE UserData;
GO
CREATE TABLE dbo.LastUpdate(EventTime DATETIME2);
INSERT dbo.LastUpdate(EventTime) SELECT SYSDATETIME();
Then I create a SQL Server Agent job that merely updates that timestamp every minute:
UPDATE UserData.dbo.LastUpdate SET EventTime = SYSDATETIME();
That just creates the initial database and simulates activity, allowing us to validate how the log shipping task rotates through each of the readable secondaries. I want to state explicitly that the point of this exercise is not to stress test log shipping or to prove how much volume we can punch through; that is a different exercise altogether.
Step 2 – add linked servers
I have four secondary Express Edition instances named .\PEON1, .\PEON2, .\PEON3, and .\PEON4. So I ran this code four times, changing @s each time:
USE [master];
GO
DECLARE @s NVARCHAR(128) = N'.\PEON1', -- repeat for .\PEON2, .\PEON3, .\PEON4
@t NVARCHAR(128) = N'true';
EXEC [master].dbo.sp_addlinkedserver @server = @s, @srvproduct = N'SQL Server';
EXEC [master].dbo.sp_addlinkedsrvlogin @rmtsrvname = @s, @useself = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'collation compatible', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'data access', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc out', @optvalue = @t;
Step 3 – validate file share(s)
In my case, all 5 instances are on the same server, so I just created a folder for each instance: C:\temp\Peon1\, C:\temp\Peon2\, and so on. Remember that if your secondaries are on different servers, the location should be relative to that server, but still be accessible from the primary (so typically a UNC path would be used). You should validate that each instance can write to that share, and you should also validate that each instance can write to the location specified for the standby file (I used the same folders for standby). You can validate this by backing up a small database from each instance to each of its specified locations – don't proceed until this works.
Step 4 – create tables
I decided to place this data in msdb, but I don't really have any strong feelings for or against creating a separate database. The first table I need is the one that holds information about the database(s) I am going to be log shipping:
CREATE TABLE dbo.PMAG_Databases
(
DatabaseName SYSNAME,
LogBackupFrequency_Minutes SMALLINT NOT NULL DEFAULT (15),
CONSTRAINT PK_DBS PRIMARY KEY(DatabaseName)
);
GO
INSERT dbo.PMAG_Databases(DatabaseName) SELECT N'UserData';
(If you're curious about the naming scheme, PMAG stands for "Poor Man's Availability Groups.")
Another table required is one to hold information about the secondaries, including their individual folders and their current status in the log shipping sequence.
CREATE TABLE dbo.PMAG_Secondaries
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
CommonFolder VARCHAR(512) NOT NULL,
DataFolder VARCHAR(512) NOT NULL,
LogFolder VARCHAR(512) NOT NULL,
StandByLocation VARCHAR(512) NOT NULL,
IsCurrentStandby BIT NOT NULL DEFAULT 0,
CONSTRAINT PK_Sec PRIMARY KEY(DatabaseName, ServerInstance),
CONSTRAINT FK_Sec_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName)
);
If you want to backup from the source server locally, and have the secondaries restore remotely, or vice versa, you can split CommonFolder into two columns (BackupFolder and RestoreFolder), and make relevant changes in the code (there won't be that many).
Since I can populate this table based at least partially on the information in sys.servers – taking advantage of the fact that the data / log and other folders are named after the instance names:
INSERT dbo.PMAG_Secondaries
(
DatabaseName,
ServerInstance,
CommonFolder,
DataFolder,
LogFolder,
StandByLocation
)
SELECT
DatabaseName = N'UserData',
ServerInstance = name,
CommonFolder = 'C:\temp\Peon' + RIGHT(name, 1) + '\',
DataFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
LogFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
StandByLocation = 'C:\temp\Peon' + RIGHT(name, 1) + '\'
FROM sys.servers
WHERE name LIKE N'.\PEON[1-4]';
I also need a table to track individual log backups (not just the last one), because in many cases I'll need to restore multiple log files in a sequence. I can get this information from msdb.dbo.backupset, but it is much more complicated to get things like the location – and I may not have control over other jobs which may clean up backup history.
CREATE TABLE dbo.PMAG_LogBackupHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT NOT NULL,
Location VARCHAR(2000) NOT NULL,
BackupTime DATETIME NOT NULL DEFAULT SYSDATETIME(),
CONSTRAINT PK_LBH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LBH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LBH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
);
You might think it is wasteful to store a row for each secondary, and to store the location of every backup, but this is for future-proofing – to handle the case where you move the CommonFolder for any secondary.
And finally a history of log restores so, at any point, I can see which logs have been restored and where, and the restore job can be sure to only restore logs that haven't already been restored:
CREATE TABLE dbo.PMAG_LogRestoreHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT,
RestoreTime DATETIME,
CONSTRAINT PK_LRH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LRH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LRH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
);
Step 5 – initialize secondaries
We need a stored procedure that will generate a backup file (and mirror it to any locations required by different instances), and we will also restore one log to each secondary to put them all in standby. At this point they will all be available for read-only queries, but only one will be the "current" standby at any one time. This is the stored procedure that will handle both full and transaction log backups; when a full backup is requested, and @init is set to 1, it automatically re-initializes log shipping.
CREATE PROCEDURE [dbo].[PMAG_Backup]
@dbname SYSNAME,
@type CHAR(3) = 'bak', -- or 'trn'
@init BIT = 0 -- only used with 'bak'
AS
BEGIN
SET NOCOUNT ON;
-- generate a filename pattern
DECLARE @now DATETIME = SYSDATETIME();
DECLARE @fn NVARCHAR(256) = @dbname + N'_' + CONVERT(CHAR(8), @now, 112)
+ RIGHT(REPLICATE('0',6) + CONVERT(VARCHAR(32), DATEDIFF(SECOND,
CONVERT(DATE, @now), @now)), 6) + N'.' + @type;
-- generate a backup command with MIRROR TO for each distinct CommonFolder
DECLARE @sql NVARCHAR(MAX) = N'BACKUP'
+ CASE @type WHEN 'bak' THEN N' DATABASE ' ELSE N' LOG ' END
+ QUOTENAME(@dbname) + '
' + STUFF(
(SELECT DISTINCT CHAR(13) + CHAR(10) + N' MIRROR TO DISK = '''
+ s.CommonFolder + @fn + ''''
FROM dbo.PMAG_Secondaries AS s
WHERE s.DatabaseName = @dbname
FOR XML PATH(''), TYPE).value(N'.[1]',N'nvarchar(max)'),1,9,N'') + N'
WITH NAME = N''' + @dbname + CASE @type
WHEN 'bak' THEN N'_PMAGFull' ELSE N'_PMAGLog' END
+ ''', INIT, FORMAT' + CASE WHEN LEFT(CONVERT(NVARCHAR(128),
SERVERPROPERTY(N'Edition')), 3) IN (N'Dev', N'Ent')
THEN N', COMPRESSION;' ELSE N';' END;
EXEC [master].sys.sp_executesql @sql;
IF @type = 'bak' AND @init = 1 -- initialize log shipping
BEGIN
EXEC dbo.PMAG_InitializeSecondaries @dbname = @dbname, @fn = @fn;
END
IF @type = 'trn'
BEGIN
-- record the fact that we backed up a log
INSERT dbo.PMAG_LogBackupHistory
(
DatabaseName,
ServerInstance,
BackupSetID,
Location
)
SELECT
DatabaseName = @dbname,
ServerInstance = s.ServerInstance,
BackupSetID = MAX(b.backup_set_id),
Location = s.CommonFolder + @fn
FROM msdb.dbo.backupset AS b
CROSS JOIN dbo.PMAG_Secondaries AS s
WHERE b.name = @dbname + N'_PMAGLog'
AND s.DatabaseName = @dbname
GROUP BY s.ServerInstance, s.CommonFolder + @fn;
-- once we've backed up logs,
-- restore them on the next secondary
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname;
END
END
This in turn calls two procedures that you could call separately (but most likely will not). First, the procedure that will initialize the secondaries on first run:
ALTER PROCEDURE dbo.PMAG_InitializeSecondaries
@dbname SYSNAME,
@fn VARCHAR(512)
AS
BEGIN
SET NOCOUNT ON;
-- clear out existing history/settings (since this may be a re-init)
DELETE dbo.PMAG_LogBackupHistory WHERE DatabaseName = @dbname;
DELETE dbo.PMAG_LogRestoreHistory WHERE DatabaseName = @dbname;
UPDATE dbo.PMAG_Secondaries SET IsCurrentStandby = 0
WHERE DatabaseName = @dbname;
DECLARE @sql NVARCHAR(MAX) = N'',
@files NVARCHAR(MAX) = N'';
-- need to know the logical file names - may be more than two
SET @sql = N'SELECT @files = (SELECT N'', MOVE N'''''' + name
+ '''''' TO N''''$'' + CASE [type] WHEN 0 THEN N''df''
WHEN 1 THEN N''lf'' END + ''$''''''
FROM ' + QUOTENAME(@dbname) + '.sys.database_files
WHERE [type] IN (0,1)
FOR XML PATH, TYPE).value(N''.[1]'',N''nvarchar(max)'');';
EXEC master.sys.sp_executesql @sql,
N'@files NVARCHAR(MAX) OUTPUT',
@files = @files OUTPUT;
SET @sql = N'';
-- restore - need physical paths of data/log files for WITH MOVE
-- this can fail, obviously, if those path+names already exist for another db
SELECT @sql += N'EXEC ' + QUOTENAME(ServerInstance)
+ N'.master.sys.sp_executesql N''RESTORE DATABASE ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + CommonFolder + @fn + N'''''' + N' WITH REPLACE,
NORECOVERY' + REPLACE(REPLACE(REPLACE(@files, N'$df$', DataFolder
+ @dbname + N'.mdf'), N'$lf$', LogFolder + @dbname + N'.ldf'), N'''', N'''''')
+ N';'';' + CHAR(13) + CHAR(10)
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = @dbname;
EXEC [master].sys.sp_executesql @sql;
-- backup a log for this database
EXEC dbo.PMAG_Backup @dbname = @dbname, @type = 'trn';
-- restore logs
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname, @PrepareAll = 1;
END
And then the procedure that will restore the logs:
CREATE PROCEDURE dbo.PMAG_RestoreLogs
@dbname SYSNAME,
@PrepareAll BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StandbyInstance SYSNAME,
@CurrentInstance SYSNAME,
@BackupSetID INT,
@Location VARCHAR(512),
@StandByLocation VARCHAR(512),
@sql NVARCHAR(MAX),
@rn INT;
-- get the "next" standby instance
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 0
AND ServerInstance > (SELECT ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandBy = 1);
IF @StandbyInstance IS NULL -- either it was last or a re-init
BEGIN
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries;
END
-- get that instance up and into STANDBY
-- for each log in logbackuphistory not in logrestorehistory:
-- restore, and insert it into logrestorehistory
-- mark the last one as STANDBY
-- if @prepareAll is true, mark all others as NORECOVERY
-- in this case there should be only one, but just in case
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT bh.BackupSetID, s.ServerInstance, bh.Location, s.StandbyLocation,
rn = ROW_NUMBER() OVER (PARTITION BY s.ServerInstance ORDER BY bh.BackupSetID DESC)
FROM dbo.PMAG_LogBackupHistory AS bh
INNER JOIN dbo.PMAG_Secondaries AS s
ON bh.DatabaseName = s.DatabaseName
AND bh.ServerInstance = s.ServerInstance
WHERE s.DatabaseName = @dbname
AND s.ServerInstance = CASE @PrepareAll
WHEN 1 THEN s.ServerInstance ELSE @StandbyInstance END
AND NOT EXISTS
(
SELECT 1 FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE DatabaseName = @dbname
AND ServerInstance = s.ServerInstance
AND BackupSetID = bh.BackupSetID
)
ORDER BY CASE s.ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 2 END, bh.BackupSetID;
OPEN c;
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
WHILE @@FETCH_STATUS -1
BEGIN
-- kick users out - set to single_user then back to multi
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance) + N'.[master].sys.sp_executesql '
+ 'N''IF EXISTS (SELECT 1 FROM sys.databases WHERE name = N'''''
+ @dbname + ''''' AND [state] 1)
BEGIN
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET SINGLE_USER '
+ N'WITH ROLLBACK IMMEDIATE;
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET MULTI_USER;
END;'';';
EXEC [master].sys.sp_executesql @sql;
-- restore the log (in STANDBY if it's the last one):
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance)
+ N'.[master].sys.sp_executesql ' + N'N''RESTORE LOG ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + @Location + N''''' WITH ' + CASE WHEN @rn = 1
AND (@CurrentInstance = @StandbyInstance OR @PrepareAll = 1) THEN
N'STANDBY = N''''' + @StandbyLocation + @dbname + N'.standby''''' ELSE
N'NORECOVERY' END + N';'';';
EXEC [master].sys.sp_executesql @sql;
-- record the fact that we've restored logs
INSERT dbo.PMAG_LogRestoreHistory
(DatabaseName, ServerInstance, BackupSetID, RestoreTime)
SELECT @dbname, @CurrentInstance, @BackupSetID, SYSDATETIME();
-- mark the new standby
IF @rn = 1 AND @CurrentInstance = @StandbyInstance -- this is the new STANDBY
BEGIN
UPDATE dbo.PMAG_Secondaries
SET IsCurrentStandby = CASE ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 0 END
WHERE DatabaseName = @dbname;
END
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
END
CLOSE c; DEALLOCATE c;
END
(I know it's a lot of code, and a lot of cryptic dynamic SQL. I tried to be very liberal with comments; if there is a piece you're having trouble with, please let me know.)
So now, all you have to do to get the system up and running is make two procedure calls:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'bak', @init = 1;
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Now you should see each instance with a standby copy of the database:
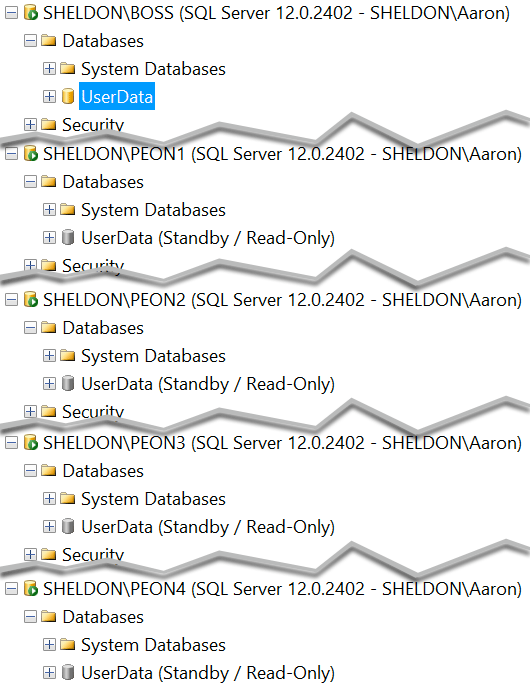
And you can see which one should currently serve as the read-only standby:
SELECT ServerInstance, IsCurrentStandby
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = N'UserData';
Step 6 – create a job that backs up / restores logs
You can put this command in a job you schedule for every 15 minutes:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
This will shift the active secondary every 15 minutes, and its data will be 15 minutes fresher than the previous active secondary. If you have multiple databases on different schedules, you can create multiple jobs, or schedule the job more frequently and check the dbo.PMAG_Databases table for each individual LogBackupFrequency_Minutes value to determine if you should run the backup/restore for that database.
Step 7 – view and procedure to tell application which standby is active
CREATE VIEW dbo.PMAG_ActiveSecondaries
AS
SELECT DatabaseName, ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 1;
GO
CREATE PROCEDURE dbo.PMAG_GetActiveSecondary
@dbname SYSNAME
AS
BEGIN
SET NOCOUNT ON;
SELECT ServerInstance
FROM dbo.PMAG_ActiveSecondaries
WHERE DatabaseName = @dbname;
END
GO
In my case, I also manually created a view unioning across all of the UserData databases so that I could compare the recency of the data on the primary with each secondary.
CREATE VIEW dbo.PMAG_CompareRecency_UserData
AS
WITH x(ServerInstance, EventTime)
AS
(
SELECT @@SERVERNAME, EventTime FROM UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON1', EventTime FROM [.\PEON1].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON2', EventTime FROM [.\PEON2].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON3', EventTime FROM [.\PEON3].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON4', EventTime FROM [.\PEON4].UserData.dbo.LastUpdate
)
SELECT x.ServerInstance, s.IsCurrentStandby, x.EventTime,
Age_Minutes = DATEDIFF(MINUTE, x.EventTime, SYSDATETIME()),
Age_Seconds = DATEDIFF(SECOND, x.EventTime, SYSDATETIME())
FROM x LEFT OUTER JOIN dbo.PMAG_Secondaries AS s
ON s.ServerInstance = x.ServerInstance
AND s.DatabaseName = N'UserData';
GO
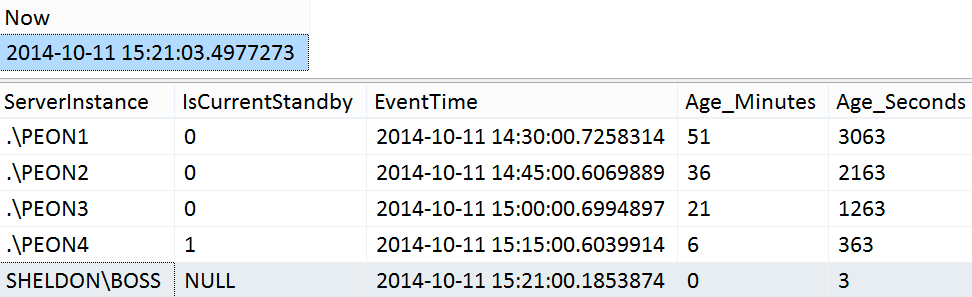
Sample results from the weekend:
SELECT [Now] = SYSDATETIME();
SELECT ServerInstance, IsCurrentStandby, EventTime, Age_Minutes, Age_Seconds
FROM dbo.PMAG_CompareRecency_UserData
ORDER BY Age_Seconds DESC;
Step 8 – cleanup procedure
Cleaning up the log backup and restore history is pretty easy.
CREATE PROCEDURE dbo.PMAG_CleanupHistory
@dbname SYSNAME,
@DaysOld INT = 7
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cutoff INT;
-- this assumes that a log backup either
-- succeeded or failed on all secondaries
SELECT @cutoff = MAX(BackupSetID)
FROM dbo.PMAG_LogBackupHistory AS bh
WHERE DatabaseName = @dbname
AND BackupTime < DATEADD(DAY, -@DaysOld, SYSDATETIME())
AND EXISTS
(
SELECT 1
FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE BackupSetID = bh.BackupSetID
AND DatabaseName = @dbname
AND ServerInstance = bh.ServerInstance
);
DELETE dbo.PMAG_LogRestoreHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
DELETE dbo.PMAG_LogBackupHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
END
GO
Now, you can add that as a step in the existing job, or you can schedule it completely separately or as part of other cleanup routines.
I'll leave cleaning up the file system for another post (and probably a separate mechanism altogether, such as PowerShell or C# - this isn't typically the kind of thing you want T-SQL to do).
Step 9 - augment the solution
It's true that there could be better error handling and other niceties here to make this solution more complete. For now I will leave that as an exercise for the reader, but I plan to look at follow-up posts to detail improvements and refinements to this solution.
Variables and limitations
Note that in my case I used Standard Edition as the primary, and Express Edition for all secondaries. You could go a step further on the budget scale and even use Express Edition as the primary - a lot of people think Express Edition doesn't support log shipping, when in fact it's merely the wizard that wasn't present in versions of Management Studio Express before SQL Server 2012 Service Pack 1. That said, since Express Edition does not support SQL Server Agent, it would be difficult to make it a publisher in this scenario - you would have to configure your own scheduler to call the stored procedures (C# command line app run by Windows Task Scheduler, PowerShell jobs, or SQL Server Agent jobs on yet another instance). To use Express on either end, you would also have to be confident that your data file won't exceed 10GB, and your queries will function fine with the memory, CPU, and feature limitations of that edition. I am by no means suggesting that Express is ideal; I merely used it to demonstrate that it is possible to have very flexible readable secondaries for free (or very close to it).
Also, these separate instances in my scenario all live on the same VM, but it doesn't have to work that way at all - you can spread the instances out across multiple servers; or, you could go the other way, and restore to different copies of the database, with different names, on the same instance. These configurations would require minimal changes to what I've laid out above. And how many databases you restore to, and how often, is completely up to you - though there will be a practical upper bound (where [average query time] > [number of secondaries] x [log backup interval]).
Finally, there are definitely some limitations with this approach. A non-exhaustive list:
- While you can continue to take full backups on your own schedule, the log backups must serve as your only log backup mechanism. If you need to store the log backups for other purposes, you won't be able to back up logs separately from this solution, since they will interfere with the log chain. Instead, you can consider adding additional
MIRROR TOarguments to the existing log backup scripts, if you need to have copies of the logs used elsewhere. - While "Poor Man's Availability Groups" may seem like a clever name, it can also be a bit misleading. This solution certainly lacks many of the HA/DR features of Availability Groups, including failover, automatic page repair, and support in the UI, Extended Events and DMVs. This was only meant to provide the ability for non-Enterprise customers to have an infrastructure that supports multiple readable secondaries.
- I tested this on a very isolated VM system with no concurrency. This is not a complete solution and there are likely dozens of ways this code could be made tighter; as a first step, and to focus on the scaffolding and to show you what's possible, I did not build in bulletproof resiliency. You will need to test it at your scale and with your workload to discover your breaking points, and you will also potentially need to deal with transactions over linked servers (always fun) and automating the re-initialization in the event of a disaster.
The "Insurance Policy"
Log shipping also offers a distinct advantage over many other solutions, including Availability Groups, mirroring and replication: a delayed "insurance policy" as I like to call it. At my previous job, I did this with full backups, but you could easily use log shipping to accomplish the same thing: I simply delayed the restores to one of the secondary instances by 24 hours. This way, I was protected from any client "shooting themselves in the foot" going back to yesterday, and I could get to their data easily on the delayed copy, because it was 24 hours behind. (I implemented this the first time a customer ran a delete without a where clause, then called us in a panic, at which point we had to restore their database to a point in time before the delete - which was both tedious and time consuming.) You could easily adapt this solution to treat one of these instances not as a read-only secondary but rather as an insurance policy. More on that perhaps in another post.
8 thoughts on “Readable Secondaries on a Budget”
Comments are closed.

Aaron,
Awesome post and idea!
You suggest adding some logic so app can figure out what secondary to read from. Changing the app is usually the complex part.
Is there a way to make this work with minimal app changes?
Maybe have one DNS record to always point to the most up to date secondary and keep updating DNS records? (don't know enough about DNS to say this would work.)
Thanks
Mark
Hi Mark, thanks, yes, that could work, assuming that clients get DNS updates propagated quickly enough (you'll need to check with your network/AD folks, and trust but verify), and that each secondary has the same instance and database name (or same port number and database name).
Brilliant idea.
If you used a hardware load balancer, it could detect which one was readable and route users to it automatically. Or you could use software load balancing and repoint the destination server as needed. We used to do this with load balanced cube servers so we could programmatically remove one node at a time and process it without affecting availability.
As Argenis noted via Twitter, Gina Jen, Crystal and I had a couple of reporting dB's replicated with log shipping to ~8 replica servers (roughly 600gb or so in 2007). Worked well. The biggest pain point initially was managing the maintenance and code changes that resulted in huge logs. Great post!
awesome post and idea. thanks for your script who does the trick Aaron!