
Maintaining a grouped running MAX (or MIN)
Note: This post was originally published only in our eBook, High Performance Techniques for SQL Server, Volume 3. You can find out about our eBooks here.
One requirement I see occasionally is to have a query returned with orders grouped by customer, showing the max total due seen for any order to date (a "running max"). So imagine these sample rows:
| SalesOrderID | CustomerID | OrderDate | TotalDue |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37.55 |
| 23 | 1 | 2014-01-02 | 45.29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89.84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 2014-01-06 | 45.54 |
| 55 | 1 | 2014-01-07 | 99.24 |
| 62 | 2 | 2014-01-08 | 12.55 |
A few rows of sample data
The desired results from the stated requirements are as follows – in plain terms, sort each customer's orders by date, and list each order. If that is the highest TotalDue value for all orders seen up until that date, print that order's total, otherwise print the highest TotalDue value from all previous orders:
| SalesOrderID | CustomerID | OrderDate | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45.29 | 45.29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45.29 |
| 31 | 1 | 2014-01-07 | 99.24 | 99.24 |
| 32 | 2 | 2014-01-01 | 37.55 | 37.55 |
| 37 | 2 | 2014-01-03 | 24.56 | 37.55 |
| 44 | 2 | 2014-01-04 | 89.84 | 89.84 |
| 55 | 2 | 2014-01-06 | 45.54 | 89.84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89.84 |
Sample desired results
Many people would instinctively want to use a cursor or while loop to accomplish this, but there are several approaches that don't involve these constructs.
Correlated Subquery
This approach seems to be the simplest and most straightforward approach to the problem, but it has been proven time and time again to not scale, since the reads grow exponentially as the table gets larger:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID;
Here is the plan against AdventureWorks2014, using SQL Sentry Plan Explorer:
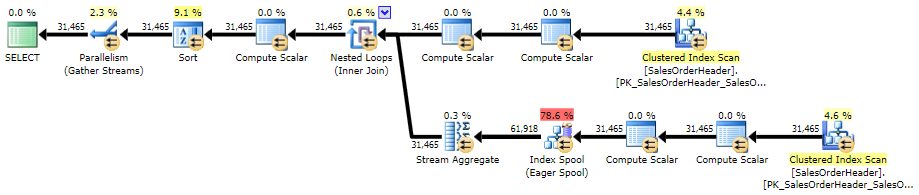 Execution plan for correlated subquery (click to enlarge)
Execution plan for correlated subquery (click to enlarge)
Self-referencing CROSS APPLY
This approach is nearly identical to the Correlated Subquery approach, in terms of syntax, plan shape and performance at scale.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID;
The plan is quite similar to the correlated subquery plan, the only difference being the location of a sort:
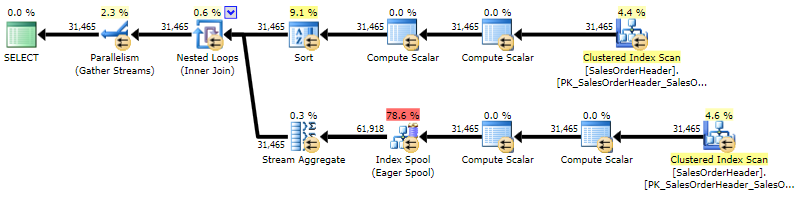 Execution plan for CROSS APPLY (click to enlarge)
Execution plan for CROSS APPLY (click to enlarge)
Recursive CTE
Behind the scenes, this uses loops, but until we actually run it, we can sort of pretend it doesn't (though it is easily the most complicated piece of code I would ever want to write to solve this particular problem):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0);
You can immediately see that the plan is more complex than the previous two, which is not surprising given the more complex query:
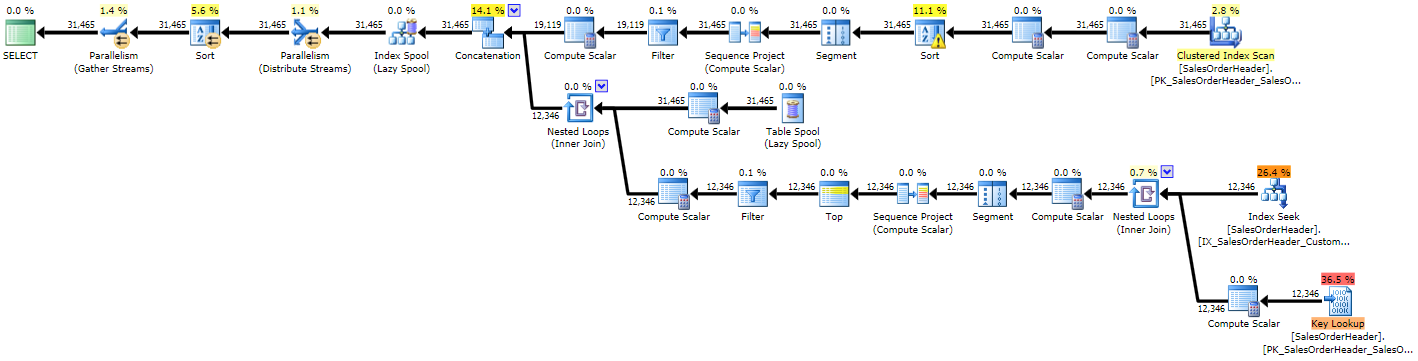 Execution plan for recursive CTE (click to enlarge)
Execution plan for recursive CTE (click to enlarge)
Due to some bad estimates, we see an index seek with an accompanying key lookup that probably should have both been replaced by a single scan, and we also get a sort operation that ultimately needs to spill to tempdb (you can see this in the tooltip if you hover over the sort operator with the warning icon):

MAX() OVER (ROWS UNBOUNDED)
This is a solution only available in SQL Server 2012 and higher, as it uses newly-introduced extensions to window functions.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID;
The plan shows exactly why it scales better than all the others; it only has one clustered index scan operation, as opposed to two (or the bad choice of a scan and a seek + lookup in the case of the recursive CTE):
 Execution plan for MAX() OVER() (click to enlarge)
Execution plan for MAX() OVER() (click to enlarge)
Performance Comparison
The plans certainly lead us to believe that the new MAX() OVER() capability in SQL Server 2012 is a real winner, but how about tangible runtime metrics? Here are how the executions compared:

The first two queries were almost identical; while in this case the CROSS APPLY was better in terms of overall duration by a small margin, the correlated subquery sometimes beats it out by a bit instead. The recursive CTE is substantially slower every single time, and you can see the factors that contribute to that - namely, the bad estimates, the massive amount of reads, the key lookup, and the additional sort operation. And as I've demonstrated before with running totals, the SQL Server 2012 solution is better in almost every aspect.
Conclusion
If you're on SQL Server 2012 or greater, you definitely want to become familiar with all of the extensions to the windowing functions first introduced in SQL Server 2005 - they may give you some pretty serious performance boosts when revisiting code that is still running "the old way." If you want to learn more about some of these new capabilities, I highly recommend Itzik Ben-Gan's book, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
If you're not on SQL Server 2012 yet, in this test at least, you could choose between CROSS APPLY and the correlated subquery. As always, you should test various methods against your data on your hardware.
