
Best approaches for grouped running totals
The very first blog post on this site, way back in July of 2012, talked about best approaches for running totals. Since then, I've been asked on multiple occasions how I would approach the problem if the running totals were more complex – specifically, if I needed to calculate running totals for multiple entities – say, each customer's orders.
The original example used a fictitious case of a city issuing speeding tickets; the running total was simply aggregating and keeping a running count of the number of speeding tickets by day (regardless of who the ticket was issued to or how much it was for). A more complex (but practical) example might be aggregating the running total value of speeding tickets, grouped by driver's license, per day. Let's imagine the following table:
CREATE TABLE dbo.SpeedingTickets
(
IncidentID INT IDENTITY(1,1) PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL
);
CREATE UNIQUE INDEX x
ON dbo.SpeedingTickets(LicenseNumber, IncidentDate)
INCLUDE(TicketAmount);
You might ask, DECIMAL(7,2), really? How fast are these people going? Well, in Canada, for example, it's not all that hard to get a $10,000 speeding fine.
Now, let's populate the table with some sample data. I won't get into all of the specifics here, but this should produce about 6,000 rows representing multiple drivers and multiple ticket amounts over a month-long period:
;WITH TicketAmounts(ID,Value) AS
(
-- 10 arbitrary ticket amounts
SELECT i,p FROM
(
VALUES(1,32.75),(2,75), (3,109),(4,175),(5,295),
(6,68.50),(7,125),(8,145),(9,199),(10,250)
) AS v(i,p)
),
LicenseNumbers(LicenseNumber,[newid]) AS
(
-- 1000 random license numbers
SELECT TOP (1000) 7000000 + number, n = NEWID()
FROM [master].dbo.spt_values
WHERE number BETWEEN 1 AND 999999
ORDER BY n
),
JanuaryDates([day]) AS
(
-- every day in January 2014
SELECT TOP (31) DATEADD(DAY, number, '20140101')
FROM [master].dbo.spt_values
WHERE [type] = N'P'
ORDER BY number
),
Tickets(LicenseNumber,[day],s) AS
(
-- match *some* licenses to days they got tickets
SELECT DISTINCT l.LicenseNumber, d.[day], s = RTRIM(l.LicenseNumber)
FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d
WHERE CHECKSUM(NEWID()) % 100 = l.LicenseNumber % 100
AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
OR (RTRIM(l.LicenseNumber+1) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
)
INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)
SELECT t.LicenseNumber, t.[day], ta.Value
FROM Tickets AS t
INNER JOIN TicketAmounts AS ta
ON ta.ID = CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1))
ORDER BY t.[day], t.LicenseNumber;
This might seem a little too involved, but one of the biggest challenges I often have when composing these blog posts is constructing a suitable amount of realistic "random" / arbitrary data. If you have a better method for arbitrary data population, by all means, don't use my mumblings as an example – they're peripheral to the point of this post.
Approaches
There are various ways to solve this problem in T-SQL. Here are seven approaches, along with their associated plans. I've left out techniques like cursors (because they will be undeniably slower) and date-based recursive CTEs (because they depend on contiguous days).
Subquery #1
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND s.IncidentDate < o.IncidentDate
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
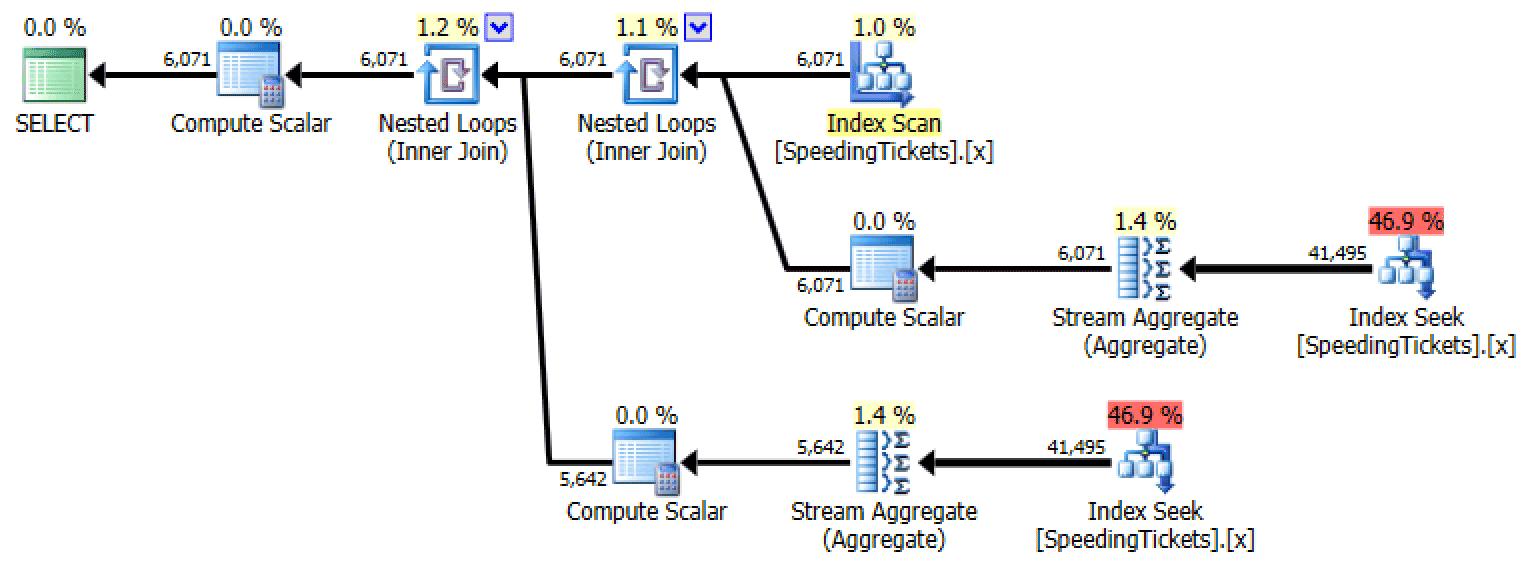
Plan for subquery #1
Subquery #2
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
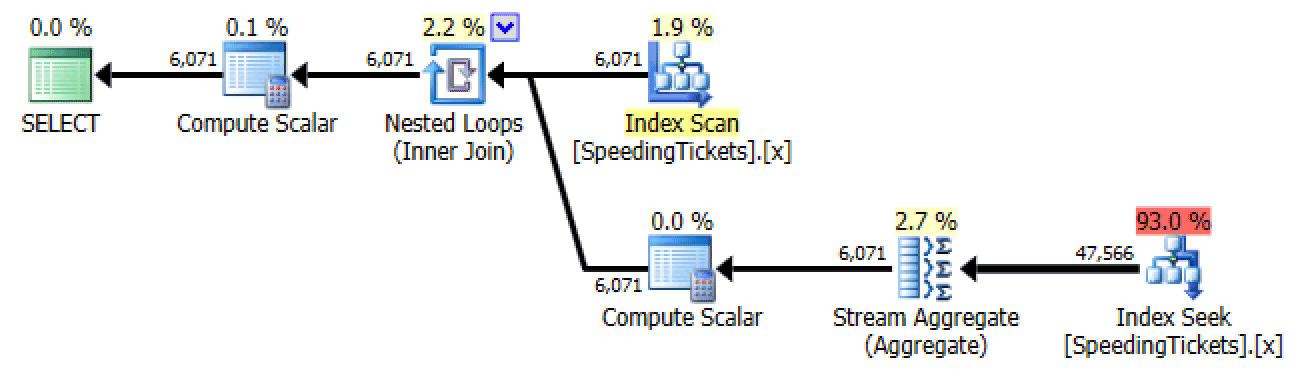
Plan for subquery #2
Self-join
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
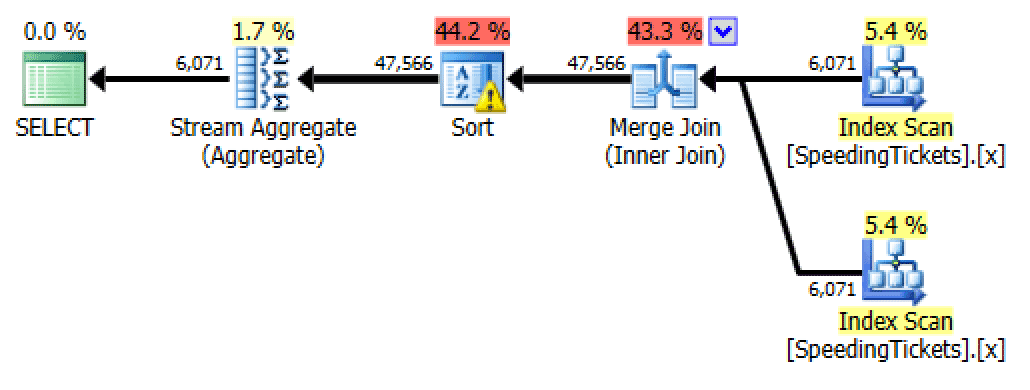
Plan for self-join
Outer apply
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
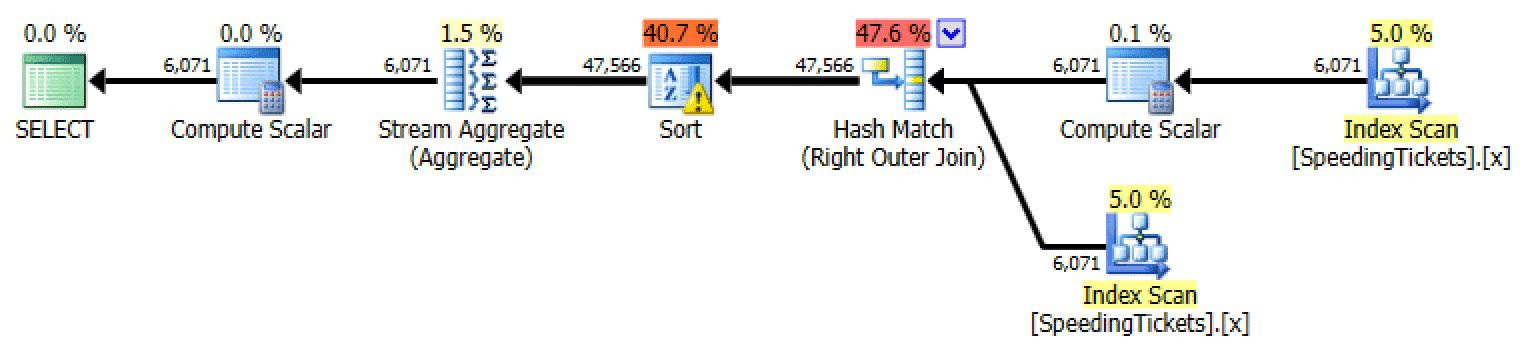
Plan for outer apply
SUM OVER() using RANGE (2012+ only)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Plan for SUM OVER() using RANGE
SUM OVER() using ROWS (2012+ only)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Plan for SUM OVER() using ROWS
Set-based iteration
With credit to Hugo Kornelis (@Hugo_Kornelis) for Chapter #4 in SQL Server MVP Deep Dives Volume #1, this approach combines a set-based approach and a cursor approach.
DECLARE @x TABLE
(
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL,
PRIMARY KEY(LicenseNumber, IncidentDate)
);
INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate)
FROM dbo.SpeedingTickets;
DECLARE @rn INT = 1, @rc INT = 1;
WHILE @rc > 0
BEGIN
SET @rn += 1;
UPDATE [current]
SET RunningTotal = [last].RunningTotal + [current].TicketAmount
FROM @x AS [current]
INNER JOIN @x AS [last]
ON [current].LicenseNumber = [last].LicenseNumber
AND [last].rn = @rn - 1
WHERE [current].rn = @rn;
SET @rc = @@ROWCOUNT;
END
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal
FROM @x
ORDER BY LicenseNumber, IncidentDate;
Due to its nature, this approach produces many identical plans in the process of updating the table variable, all of which are similar to the self-join and outer apply plans, but are able to use a seek:
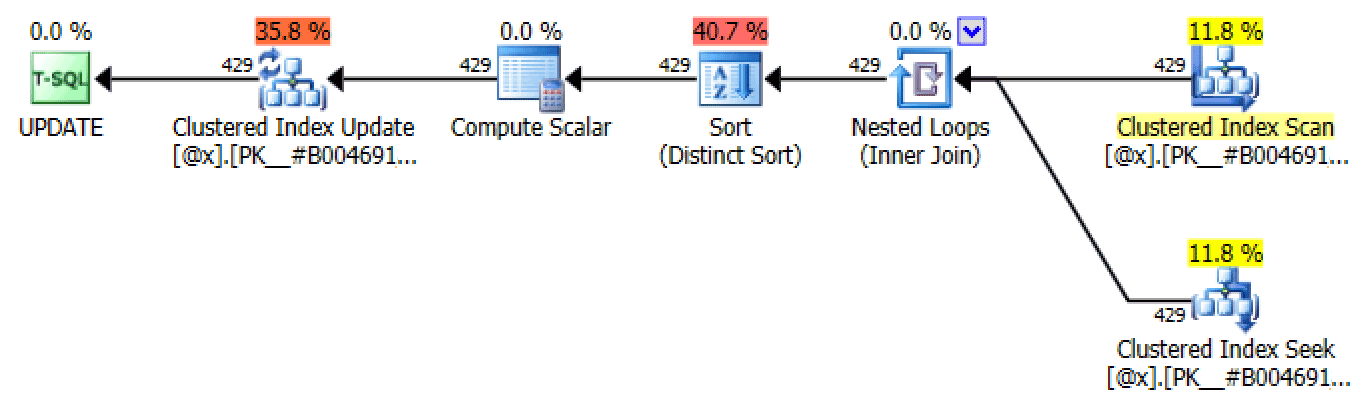
One of many UPDATE plans produced through set-based iteration
The only difference between each plan in each iteration is the row count. Through each successive iteration, the number of rows affected should stay the same or go down, since the number of rows affected at each iteration represents the number of drivers with tickets on that number of days (or, more precisely, the number of days at that "rank").
Performance Results
Here are how the approaches stacked up, as shown by SQL Sentry Plan Explorer, with the exception of the set-based iteration approach which, because it consists of many individual statements, does not represent well when compared to the rest.
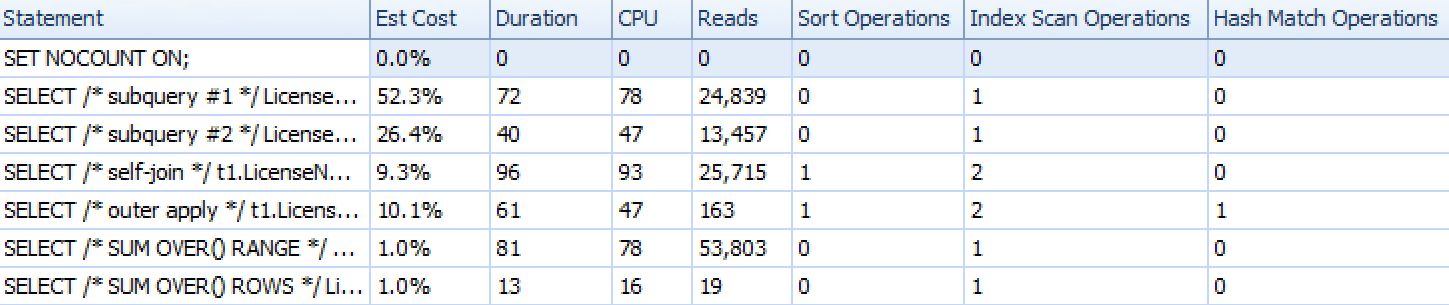
Plan Explorer runtime metrics for six of the seven approaches
In addition to reviewing the plans and comparing runtime metrics in Plan Explorer, I also measured raw runtime in Management Studio. Here are the results of running each query 10 times, keeping in mind that this also includes render time in SSMS:
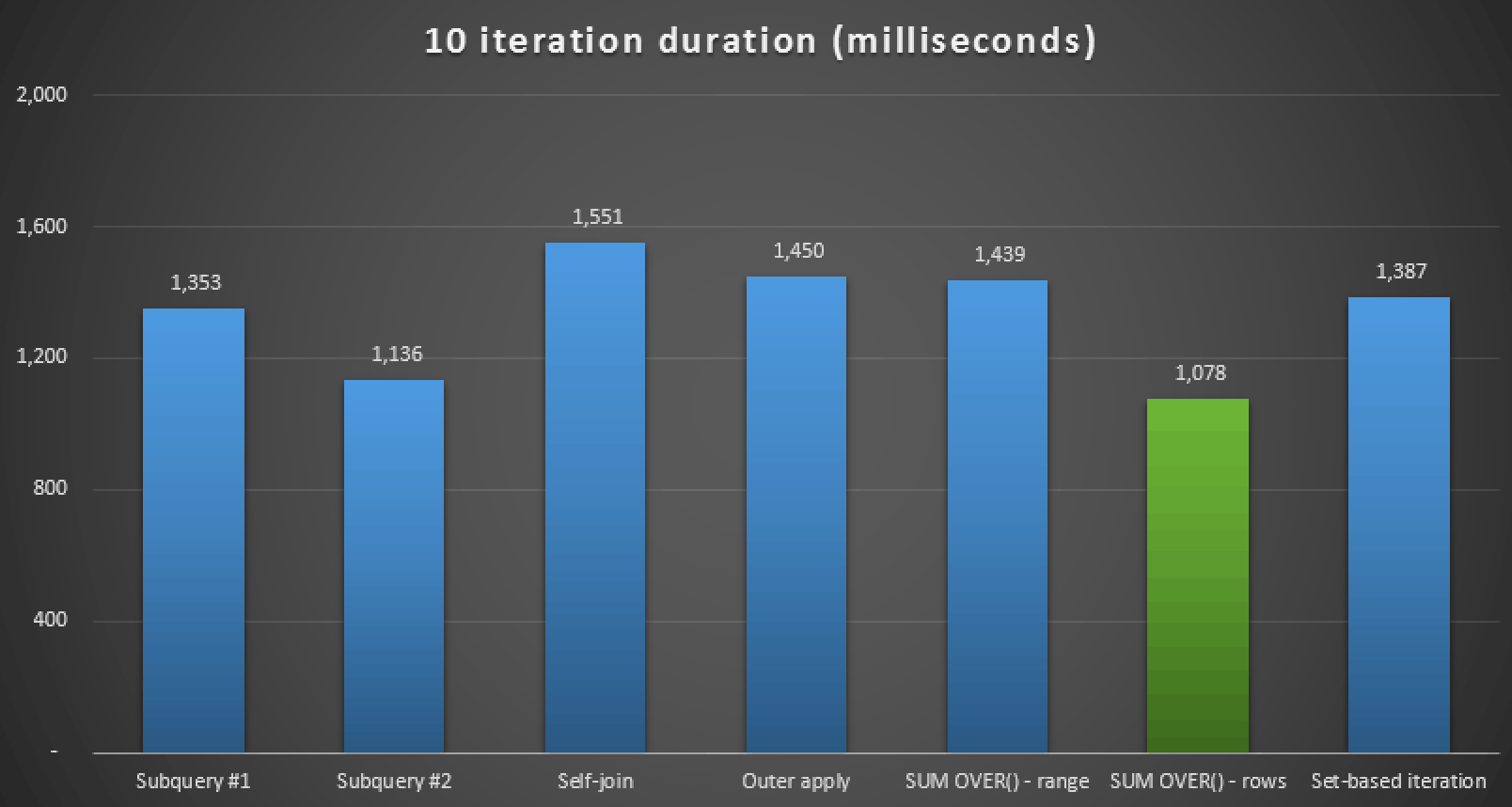
Runtime duration, in milliseconds, for all seven approaches (10 iterations)
So, if you are on SQL Server 2012 or better, the best approach seems to be SUM OVER() using ROWS UNBOUNDED PRECEDING. If you are not on SQL Server 2012, the second subquery approach seemed to be optimal in terms of runtime, in spite of the high number of reads compared to, say, the OUTER APPLY query. In all cases, of course, you should test these approaches, adapted to your schema, against your own system. Your data, indexes, and other factors may lead to a different solution being most optimal in your environment.
Other Complexities
Now, the unique index signifies that any LicenseNumber + IncidentDate combination will contain a single cumulative total, in the event where a specific driver gets multiple tickets on any given day. This business rule helps simplify our logic a little bit, avoiding the need for a tie-breaker to produce deterministic running totals.
If you do have cases where you may have multiple rows for any given LicenseNumber + IncidentDate combination, you can break the tie using another column that helps make the combination unique (obviously the source table would no longer have a unique constraint on those two columns). Note that this is possible even in cases where the DATE column is actually DATETIME - many people assume that date/time values are unique, but this is certainly not always guaranteed, regardless of granularity.
In my case, I could use the IDENTITY column, IncidentID; here is how I would adjust each solution (acknowledging that there may be better ways; just throwing out ideas):
/* --------- subquery #1 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND (s.IncidentDate < o.IncidentDate
-- added this line:
OR (s.IncidentDate = o.IncidentDate AND s.IncidentID < o.IncidentID))
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
/* --------- subquery #2 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
-- added this line:
AND IncidentID <= t.IncidentID
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
/* --------- self-join --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
-- added this line:
AND t1.IncidentID >= t2.IncidentID
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- outer apply --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
-- added this line:
AND IncidentID <= t1.IncidentID
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- SUM() OVER using RANGE --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID RANGE UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- SUM() OVER using ROWS --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- set-based iteration --------- */
DECLARE @x TABLE
(
-- added this column, and made it the PK:
IncidentID INT PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL
);
-- added the additional column to the INSERT/SELECT:
INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID)
-- and added this tie-breaker column ------------------------------^^^^^^^^^^^^
FROM dbo.SpeedingTickets;
-- the rest of the set-based iteration solution remained unchanged
Another complication you may come across is when you're not after the whole table, but rather a subset (say, in this case, the first week of January). You'll have to make adjustments by adding WHERE clauses, and keep those predicates in mind when you have correlated subqueries as well.
6 thoughts on “Best approaches for grouped running totals”
Comments are closed.

VERY NICE SOULUTION
IT WORKED FOR ME
GREAT ………
THANX
Best solution presentation I have ever seen! WOW!!
clear, concise, easy to follow, multiple options, and performance metrics to boot.
Do More!!! This is the Gold Standard for how to instruct other users.
SUM OVER() using ROWS works beautifully when applied to presentation of customer statements with a running balance per branch.
How to use the window function so that the partitioning happens on unsorted dataset? It by default sorts the partitioned column and then applies the aggregation. My requirement is to do regular Cumulative Average as I would do in e.g. Google Sheets at the link below:
https://docs.google.com/spreadsheets/d/15XOfaJTj00VZJ2OyWOSKIW8QdXwdizL-tNUf6Tyj-ks/edit#gid=0
What do you think is computational complexity of Query2? I see O(n^2) so it may not work well for large tables
I didn't test at larger scale, but I would probably lean toward aggregating over smaller sets on a larger table anyway, as opposed to just aggregating over the whole thing. Segmented by primary key, clustering key, partitioning key, etc. could help. If you have a billion rows what use would you have for outputting running totals over the whole billion rows?