
Are You Sorted? Tips Concerning T-SQL Window Ordering
A supporting index can potentially help avoid the need for explicit sorting in the query plan when optimizing T-SQL queries involving window functions. By a supporting index, I mean one with the window partitioning and ordering elements as the index key, and the rest of the columns that appear in the query as the index included columns. I often refer to such an indexing pattern as a POC index as an acronym for partitioning, ordering, and covering. Naturally, if a partitioning or ordering element doesn’t appear in the window function, you omit that part from the index definition.
But what about queries involving multiple window functions with different ordering needs? Similarly, what if other elements in the query besides window functions also require arranging input data as ordered in the plan, such as a presentation ORDER BY clause? These can result in different parts of the plan needing to process the input data in different orders.
In such circumstances, you’ll typically accept explicit sorting is unavoidable in the plan. You may find the syntactical arrangement of expressions in the query can affect how many explicit sort operators you get in the plan. By following some basic tips you can sometimes reduce the number of explicit sort operators, which can, of course, have a major impact on the performance of the query.
Environment for Demos
In my examples, I’ll use the sample database PerformanceV5. You can download the source code to create and populate this database here.
I ran all the examples on SQL Server® 2019 Developer, where batch-mode on rowstore is available.
In this article, I want to focus on tips having to do with the potential of the window function’s calculation in the plan to rely on ordered input data without requiring an extra explicit sort activity in the plan. This is relevant when the optimizer uses a serial or parallel row-mode treatment of window functions, and when using a serial batch-mode Window Aggregate operator.
SQL Server doesn't currently support an efficient combination of a parallel order-preserving input prior to a parallel batch-mode Window Aggregate operator. So, to use a parallel batch-mode Window Aggregate operator, the optimizer has to inject an intermediary parallel batch-mode Sort operator, even when the input is already preordered.
For simplicity’s sake, you can prevent parallelism in all examples shown in this article. To achieve this without needing to add a hint to all queries, and without setting a server-wide configuration option, you can set the database scoped configuration option MAXDOP to 1, like so:
USE PerformanceV5;
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;Remember to set it back to 0 after you’re done testing the examples in this article. I’ll remind you at the end.
Alternatively, you can prevent parallelism at the session level with the undocumented DBCC OPTIMIZER_WHATIF command, like so:
DBCC OPTIMIZER_WHATIF(CPUs, 1);To reset the option when you’re done, invoke it again with the value 0 as the number of CPUs.
When you’re done trying all of the examples in this article with parallelism disabled, I recommend enabling parallelism and trying all examples again to see what changes.
Tips 1 and 2
Before I start with the tips, let’s first look at a simple example with a window function designed to benefit from a supporting index.
Consider the following query, which I’ll refer to as Query 1:
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders;Don’t worry about the fact that the example is contrived. There’s no good business reason to compute a running total of order IDs—this table is decently sized with 1MM rows, and I wanted to show a simple example with a common window function such as one that applies a running total computation.
Following the POC indexing scheme, you create the following index to support the query:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);The plan for this query is shown in Figure 1.
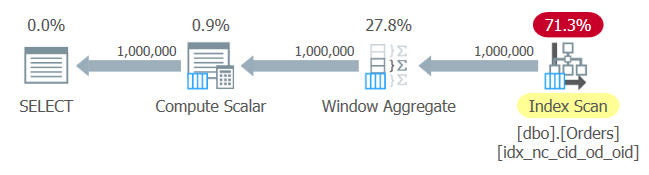 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
No surprises here. The plan applies an index order scan of the index you just created, providing the data ordered to the Window Aggregate operator, without the need for explicit sorting.
Next, consider the following query, which involves multiple window functions with different ordering needs, as well as a presentation ORDER BY clause:
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
ORDER BY custid, orderid;I’ll refer to this query as Query 2. The plan for this query is shown in Figure 2.
 Figure 2: Plan for Query 2
Figure 2: Plan for Query 2
Notice there are four Sort operators in the plan.
If you analyze the various window functions and presentation ordering needs, you’ll find there are three distinct ordering needs:
- custid, orderdate, orderid
- orderid
- custid, orderid
Given one of them (the first in the list above) can be supported by the index you created earlier, you would expect to see only two sorts in the plan. So, why does the plan have four sorts? It looks like SQL Server doesn’t try to be too sophisticated with rearranging the processing order of the functions in the plan to minimize sorts. It processes the functions in the plan in the order they appear in the query. That’s at least the case for the first occurrence of each distinct ordering need, but I’ll elaborate on this shortly.
You can remove the need for some of the sorts in the plan by applying the following two simple practices:
Tip 1: If you have an index to support some of the window functions in the query, specify those first.
Tip 2: If the query involves window functions with the same ordering need as the presentation ordering in the query, specify those functions last.
Following these tips, you rearrange the appearance order of the window functions in the query like so:
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
ORDER BY custid, orderid;I’ll refer to this query as Query 3. The plan for this query is shown in Figure 3.
 Figure 3: Plan for Query 3
Figure 3: Plan for Query 3
As you can see, the plan now has only two sorts.
Tip 3
SQL Server doesn’t try to be too sophisticated in rearranging the processing order of window functions in an attempt to minimize sorts in the plan. However, it’s capable of a certain simple rearrangement. It scans the window functions based on appearance order in the query and each time it detects a new distinct ordering need, it looks ahead for additional window functions with the same ordering need and if it finds those, it groups them together with the first occurrence. In some cases, it can even use the same operator to compute multiple window functions.
Consider the following query as an example:
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2
FROM dbo.Orders
ORDER BY custid, orderid;I’ll refer to this query as Query 4. The plan for this query is shown in Figure 4.
 Figure 4: Plan for Query 4
Figure 4: Plan for Query 4
Window functions with the same ordering needs aren’t grouped together in the query. However, there are still only two sorts in the plan. This is because what counts in terms of processing order in the plan is the first occurrence of each distinct ordering need. This leads me to the third tip.
Tip 3: Make sure to follow tips 1 and 2 for the first occurrence of each distinct ordering need. Subsequent occurrences of the same ordering need, even if nonadjacent, are identified and grouped together with the first.
Tips 4 and 5
Suppose you want to return columns resulting from windowed calculations in a certain left-to-right order in the output. But what if the order isn’t the same as the order that will minimize sorts in the plan?
For example, suppose you want the same result as the one produced by Query 2 in terms of left-to-right column order in the output (column order: other cols, sum2, sum1, sum3), but you’d rather have the same plan like the one you got for Query 3 (column order: other cols, sum1, sum3, sum2), which got two sorts instead of four.
That’s perfectly doable if you’re familiar with the fourth tip.
Tip 4: The aforementioned recommendations apply to appearance order of window functions in the code, even if within a named table expression such as a CTE or view, and even if the outer query returns the columns in a different order than in the named table expression. Therefore, if you need to return columns in a certain order in the output, and it’s different from the optimal order in terms of minimizing sorts in the plan, follow the tips in terms of appearance order within a named table expression, and return the columns in the outer query in the desired output order.
The following query, which I’ll refer to as Query 5, illustrates this technique:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid;The plan for this query is shown in Figure 5.
 Figure 5: Plan for Query 5
Figure 5: Plan for Query 5
You still get only two sorts in the plan despite the fact that the column order in the output is: other cols, sum2, sum1, sum3, like in Query 2.
One caveat to this trick with the named table expression is if your columns in the table expression aren’t referenced by the outer query, they are excluded from the plan and therefore don’t count.
Consider the following query, which I’ll refer to as Query 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid;Here all table expression columns are referenced by the outer query, so optimization happens based on the first distinct occurrence of each ordering need within the table expression:
- max1: custid, orderdate, orderid
- max3: orderid
- max2: custid, orderid
This results in a plan with only two sorts as shown in Figure 6.
 Figure 6: Plan for Query 6
Figure 6: Plan for Query 6
Now change only the outer query by removing the references to max2, max1, max3, avg2, avg1 and avg3, like so:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid;I’ll refer to this query as Query 7. The computations of max1, max3, max2, avg1, avg3, and avg2 in the table expression are irrelevant to the outer query so they are excluded. The remaining computations involving window functions in the table expression, which are relevant to the outer query, are those of sum2, sum1, and sum3. Unfortunately, they do not appear in the table expression in optimal order in terms of minimizing sorts. As you can see in the plan for this query as shown in Figure 7, there are four sorts.
 Figure 7: Plan for Query 7
Figure 7: Plan for Query 7
If you’re thinking it’s unlikely you will have columns in the inner query you won’t refer to in the outer query, think views. Each time you query a view, you might be interested in a different subset of the columns. With this in mind, the fifth tip could help in reducing sorts in the plan.
Tip 5: In the inner query of a named table expression like a CTE or view, group all window functions with the same ordering needs together, and follow tips 1 and 2 in the order of the groups of functions.
The following code implements a view based on this recommendation:
CREATE OR ALTER VIEW dbo.MyView
AS
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders;
GONow query the view requesting only the windowed result columns sum2, sum1, and sum3, in this order:
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM dbo.MyView
ORDER BY custid, orderid;I’ll refer to this query as Query 8. You get the plan shown in Figure 8 with only two sorts.
 Figure 8: Plan for Query 8
Figure 8: Plan for Query 8
Tip 6
When you have a query with multiple window functions with multiple distinct ordering needs, the common wisdom is you can support only one of them with preordered data via an index. This is the case even when all window functions have respective supporting indexes.
Let me demonstrate this. Recall earlier when you created the index idx_nc_cid_od_oid, which can support window functions needing the data ordered by custid, orderdate, orderid, such as the following expression:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)Suppose, in addition to this window function, you also need the following window function in the same query:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)This window function would benefit from the following index:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);The following query, which I’ll refer to as Query 9, invokes both window functions:
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders;The plan for this query is shown in Figure 9.
 Figure 9: Plan for Query 9
Figure 9: Plan for Query 9
I get the following time stats for this query on my machine, with results discarded in SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
As explained earlier, SQL Server scans the windowed expressions in order of appearance in the query and figures it can support the first with an ordered scan of the index idx_nc_cid_od_oid. But then it adds a Sort operator to the plan to order the data like the second window function needs. This means the plan has N log N scaling. It doesn’t consider using the index idx_nc_cid_oid to support the second window function. You’re probably thinking it can’t, but try to think a bit outside of the box. Could you not compute each of the window functions based on its respective index order and then join the results? Theoretically, you can, and depending on the size of the data, availability of indexing, and other resources available, the join version could sometimes do better. SQL Server doesn’t consider this approach, but you certainly can implement it by writing the join yourself, like so:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid;I’ll refer to this query as Query 10. The plan for this query is shown in Figure 10.
 Figure 10: Plan for Query 10
Figure 10: Plan for Query 10
The plan uses ordered scans of the two indexes with no explicit sorting whatsoever, computes the window functions, and uses a hash join to join the results. This plan scales linearly compared to the previous one which has N log N scaling.
I get the following time stats for this query on my machine (again with results discarded in SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
To recap, here’s our sixth tip.
Tip 6: When you have multiple window functions with multiple distinct ordering needs, and you’re able to support all of them with indexes, try a join version and compare its performance to the query without the join.
Cleanup
If you disabled parallelism by setting the database scoped configuration option MAXDOP to 1, reenable parallelism by setting it to 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;If you used the undocumented session option DBCC OPTIMIZER_WHATIF with the CPUs option set to 1, reenable parallelism by setting it to 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);You can retry all examples with parallelism enabled if you like.
Use the following code to clean up the new indexes you created:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders;
DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;And the following code to remove the view:
DROP VIEW IF EXISTS dbo.MyView;Follow the Tips to Minimize Number of Sorts
Window functions need to process the input data ordered. Indexing can help in eliminating sorting in the plan, but normally only for one distinct ordering need. Queries with multiple ordering needs typically involve some sorts in their plans. However, by following certain tips, you can minimize the number of sorts needed. Here’s a summary of the tips I mentioned in this article:
- Tip 1: If you have an index to support some of the window functions in the query, specify those first.
- Tip 2: If the query involves window functions with the same ordering need as the presentation ordering in the query, specify those functions last.
- Tip 3: Make sure to follow tips 1 and 2 for the first occurrence of each distinct ordering need. Subsequent occurrences of the same ordering need, even if nonadjacent, are identified and grouped together with the first.
- Tip 4: The aforementioned recommendations apply to appearance order of window functions in the code, even if within a named table expression such as a CTE or view, and even if the outer query returns the columns in a different order than in the named table expression. Therefore, if you need to return columns in a certain order in the output, and it’s different from the optimal order in terms of minimizing sorts in the plan, follow the tips in terms of appearance order within a named table expression, and return the columns in the outer query in the desired output order.
- Tip 5: In the inner query of a named table expression like a CTE or view, group all window functions with the same ordering needs together, and follow tips 1 and 2 in the order of the groups of functions.
- Tip 6: When you have multiple window functions with multiple distinct ordering needs, and you’re able to support all of them with indexes, try a join version and compare its performance to the query without the join.

Great Tips ;) will you publish all articles on this website to the book?
Thanks begin.ho!
As for your question, books and articles tend to have different focus, breadth and depth.
i have printed all your articles ;)
as they are really amazing and teach me a lot
thank you again, Itzik. you are a great sql mentor
Thanks begin.ho!
i am wodering, as we know, the all "select" calculate at the same time (the order of select elements should not be a matter). why you change the order can make the peformance better?
Thanks for this great article. Definitely actionable information here!
>"Before I start with the tips, let’s first look at a simple example with a window function designed to benefit from a supp class="border indent shadow orting index."
I think you have an HTML issue with this line.
begin.ho, the set-based treatment of the expressions in the SELECT list is relevant at the conceptual level. You get the same meaning/result irrespective of order. This article's focus is about optimization aspects, not logical meaning.
Mark, thanks for spotting this! Should be fixed now.
I always enjoy reading and learning from your posts. Thank you.
There is a typo in the initial creation of dbo.MyView.
SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders;
should by
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders;
Cheers
Fixed, nice catch, thanks!
No way to correct the post…"Should by" should be — "Should be"
Love typos :)
LOL
Hi Itzik,
Thanks for the tips. It's interesting how you notice those dependencies, do you remember a case you worked on when it happened somewhat randomly and then you dissected it, or did you specifically target this particular issue and refined to get to the end conclusion?
Hi Kamil,
Some years ago I targeted this specific area when I was researching optimization of window functions.
Recently when working on solutions for the demand versus supply challenge I noticed my first solution had too many sorts, and was able to reduce those by applying these techniques. Then the idea to write an article on the topic was born since I figured that these techniques can be valuable to others.
A specific SQL problem:
Is there a way generating many thousand lottery tickets ( for examples five distinct number on each ticket between 1 and 90 ) without using WHILE ?
My simple solution (using WHILE) for 20 thousands lottery tickets:
declare @ticket int = 1;
while @ticket <= 20000
begin
select top 5 n as lottery_number from dbo.GetNums(1,90) order by CHECKSUM(newid());
set @ticket += 1;
end
go
This above solution is very slow.
My second solution is fast, but a very complicated one with several steps, because there can be not unique numbers on certain tickets:
drop table if exists #tmp;
with step1 as
(
select abs(CHECKSUM(newid())) % 90 +1 as v from dbo.GetNums(1,150000)
)
select v, ntile(150000/5) over (order by (select null)) as ticket into #tmp from step1;
go
— index creation for accelerating next step
create index tmp_index on #tmp(ticket,v);
go
— in #tmp table there can be tickets, on which the five numbers ( between 1 .. 90) are not unique
— selecting 20 000 tickets with only unique numbers:
with step3 as
(
select v, ticket, DENSE_RANK() over (partition by ticket order by v) as densNo from #tmp
)
select top (20000*5) ticket, v
from step3 where ticket in ( select ticket from step3 group by ticket having max(densNo)=5 )
order by ticket, v
go
So is there a fast and also simple solution for this problem ?
Thank Itzik.
I like your SQL books and articles.
I collected all your books, and read them with pleasure.
István Szabó from Budapest, Hungary
Same problem, but with small corrections in solutions, and giving execution times in my home computer (i3 1125, SQL server Express 2019)
——————
— 1. solution
drop table if exists szi.lotto;
create table szi.lotto(ticket int, v tinyint);
go
declare @n int = 100000
declare @ticket int = 1
while @ticket <= @n
begin
insert into szi.lotto(ticket, v)
select top 5 @ticket, n as lottery_number from dbo.GetNums(1,90) order by CHECKSUM(newid())
set @ticket += 1
end
go
— 17 seconds
——————
— 2. solution
drop table if exists szi.lotto;
create table szi.lotto(ticket int, v tinyint);
go
declare @n int = 100000
drop table if exists #tmp;
— Generating 40% more random numbers , instead of 5*@n, there will be 7 * @n
with step1 as
(
select abs(CHECKSUM(newid())) % 90 +1 as v from dbo.GetNums(1, @n*7)
)
select v, ntile(@n*7 /5) over (order by (select null)) as ticket into #tmp from step1;
— index creation for accelerating next step
create index tmp_index on #tmp(ticket,v);
— in #tmp table there can be tickets, on which the five numbers ( between 1 .. 90) are not unique
— selecting 20 000 tickets with only unique numbers:
with step3 as
(
select v, ticket, DENSE_RANK() over (partition by ticket order by v) as densNo from #tmp
)
insert into szi.lotto(ticket, v)
select top (@n*5) ticket, v
from step3 where ticket in ( select ticket from step3 group by ticket having max(densNo)=5 )
order by ticket, v
go
— 2 seconds, about eight times faster …
Hi Szabó,
You can do this with CROSS APPLY, but there's a bit of trickiness to this. You need a correlated element from the left table involved in the lateral derived table so that it won't transform to a CROSS JOIN. Here's an example where I involve such an element in the random ordering expression:
SELECT T.n AS ticket, A.v FROM dbo.GetNums(1, 100000) AS T CROSS APPLY (SELECT TOP (5) L.n AS v FROM dbo.GetNums(1, 90) AS L ORDER BY ABS(CHECKSUM(NEWID())) - T.n) AS A;Finishes in 2 seconds on my machine.
Cheers,
Itzik
Thank a lot, Itzik.
I also tried with CROSS APPLY, OUTER APPLY , but without success …
Occured the same tickets one after the other.
You are one of the best in T-SQL !
and your explanations are excellent.