
How to Write a Query with Multiple Behaviors
Oftentimes, when we write a stored procedure, we want it to behave in different ways based on user input. Let's look at the following example:
CREATE PROCEDURE
Sales.GetOrders
(
@CustomerID AS INT = NULL ,
@SortOrder AS SYSNAME = N'OrderDate'
)
AS
SELECT TOP (10)
SalesOrderID = SalesOrders.SalesOrderID ,
OrderDate = CAST (SalesOrders.OrderDate AS DATE) ,
OrderStatus = SalesOrders.[Status] ,
CustomerID = SalesOrders.CustomerID ,
OrderTotal = SUM (SalesOrderDetails.LineTotal)
FROM
Sales.SalesOrderHeader AS SalesOrders
INNER JOIN
Sales.SalesOrderDetail AS SalesOrderDetails
ON
SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID
WHERE
SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL
GROUP BY
SalesOrders.SalesOrderID ,
SalesOrders.OrderDate ,
SalesOrders.DueDate ,
SalesOrders.[Status] ,
SalesOrders.CustomerID
ORDER BY
CASE @SortOrder
WHEN N'OrderDate'
THEN SalesOrders.OrderDate
WHEN N'SalesOrderID'
THEN SalesOrders.SalesOrderID
END ASC;
GO
This stored procedure, which I created in the AdventureWorks2017 database, has two parameters: @CustomerID and @SortOrder. The first parameter, @CustomerID, affects the rows to be returned. If a specific customer ID is passed to the stored procedure, then it returns all the orders (top 10) for this customer. Otherwise, if it's NULL, then the stored procedure returns all orders (top 10), regardless of the customer. The second parameter, @SortOrder, determines how the data will be sorted—by OrderDate or by SalesOrderID. Notice that only the first 10 rows will be returned according to the sort order.
So, users can affect the behavior of the query in two ways—which rows to return and how to sort them. To be more precise, there are 4 different behaviors for this query:
- Return the top 10 rows for all customers sorted by OrderDate (the default behavior)
- Return the top 10 rows for a specific customer sorted by OrderDate
- Return the top 10 rows for all customers sorted by SalesOrderID
- Return the top 10 rows for a specific customer sorted by SalesOrderID
Let's test the stored procedure with all 4 options and examine the execution plan and the statistics IO.
Return the Top 10 Rows for All Customers Sorted by OrderDate
The following is the code to execute the stored procedure:
EXECUTE Sales.GetOrders;
GO
Here is the execution plan:
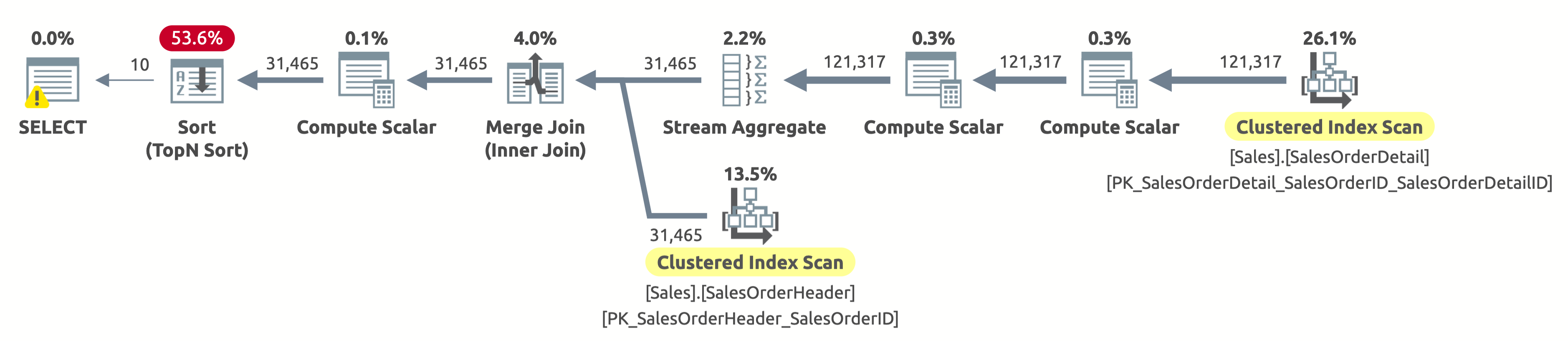
Since we haven't filtered by customer, we need to scan the entire table. The optimizer chose to scan both tables using indexes on SalesOrderID, which allowed for an efficient Stream Aggregate as well as an efficient Merge Join.
If you check the properties of the Clustered Index Scan operator on the Sales.SalesOrderHeader table, you will find the following predicate: [AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID] OR [@CustomerID] IS NULL. The query processor has to evaluate this predicate for each row in the table, which is not very efficient because it will always evaluate to true.
We still need to sort all the data by OrderDate to return the first 10 rows. If there was an index on OrderDate, then the optimizer would have probably used it to scan only the first 10 rows from Sales.SalesOrderHeader, but there is no such index, so the plan seems fine considering the available indexes.
Here is the output of statistics IO:
- Table 'SalesOrderHeader'. Scan count 1, logical reads 689
- Table 'SalesOrderDetail'. Scan count 1, logical reads 1248
If you're asking why there is a warning on the SELECT operator, then it's an excessive grant warning. In this case, it's not because there is a problem in the execution plan, but rather because the query processor requested 1,024KB (which is the minimum by default) and used only 16KB.
Sometimes Plan Caching Isn't Such a Good Idea
Next, we want to test the scenario of returning the top 10 rows for a specific customer sorted by OrderDate. Below is the code:
EXECUTE Sales.GetOrders
@CustomerID = 11006;
GO
The execution plan is exactly the same as before. This time, the plan is very inefficient because it scans both tables only to return 3 orders. There are much better ways to execute this query.
The reason, in this case, is plan caching. The execution plan was generated in the first execution based on the parameter values in that specific execution—a method known as parameter sniffing. That plan was stored in the plan cache for reuse, and, from now on, every call to this stored procedure is going to reuse the same plan.
This is an example where plan caching isn't such a good idea. Because of the nature of this stored procedure, which has 4 different behaviors, we expect to get a different plan for each behavior. But we are stuck with a single plan, which is only good for one of the 4 options, based on the option used in the first execution.
Let's disable plan caching for this stored procedure, just so that we can see the best plan that the optimizer can come up with for each one of the other 3 behaviors. We will do this by adding WITH RECOMPILE to the EXECUTE command.
Return the Top 10 Rows for a Specific Customer Sorted by OrderDate
The following is the code to return the top 10 rows for a specific customer sorted by OrderDate:
EXECUTE Sales.GetOrders
@CustomerID = 11006
WITH
RECOMPILE;
GO
The following is the execution plan:
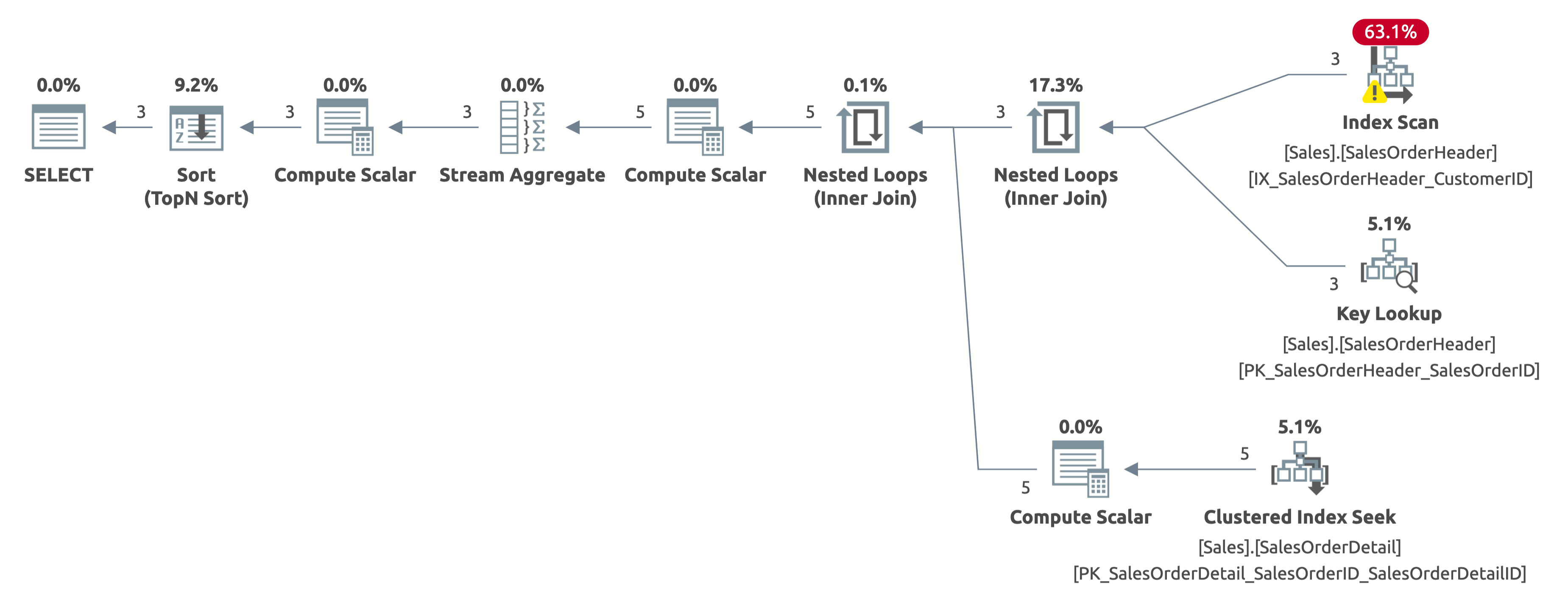
This time, we get a better plan, which uses an index on CustomerID. The optimizer correctly estimates 2.6 rows for CustomerID = 11006 (the actual number is 3). But notice that it performs an index scan instead of an index seek. It can't perform an index seek because it has to evaluate the following predicate for each row in the table: [AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID] OR [@CustomerID] IS NULL.
Here is the output of statistics IO:
- Table 'SalesOrderDetail'. Scan count 3, logical reads 9
- Table 'SalesOrderHeader'. Scan count 1, logical reads 66
Return the Top 10 Rows for All Customers Sorted by SalesOrderID
The following is the code to return the top 10 rows for all customers sorted by SalesOrderID:
EXECUTE Sales.GetOrders
@SortOrder = N'SalesOrderID'
WITH
RECOMPILE;
GO
The following is the execution plan:
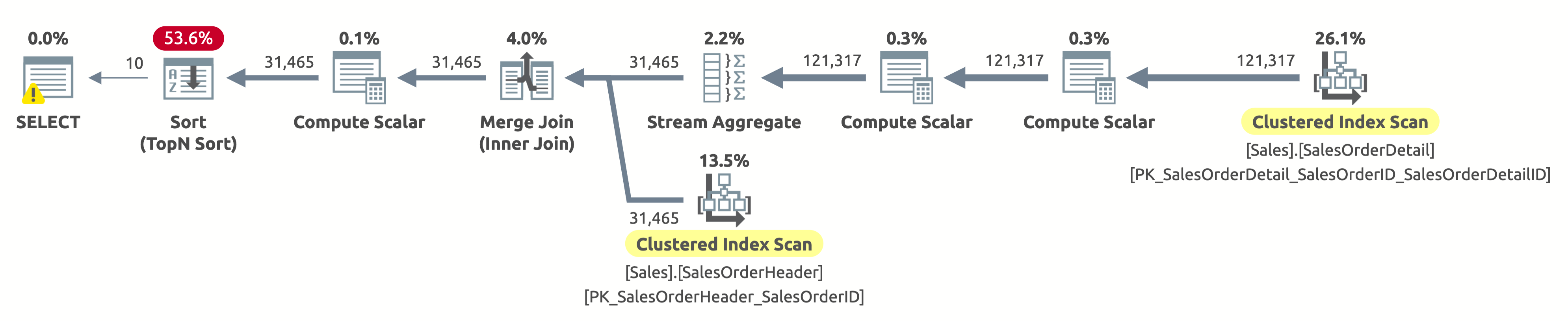
Hey, this is the same execution plan as in the first option. But this time, something is wrong. We already know that the clustered indexes on both tables are sorted by SalesOrderID. We also know that the plan scans both of them in the logical order to retain the sort order (the Ordered property is set to True). The Merge Join operator also retains the sort order. Because we are now asking to sort the result by SalesOrderID, and it is already sorted that way, then why do we have to pay for an expensive Sort operator?
Well, if you check the Sort operator, you will notice that it sorts the data according to Expr1004. And, if you check the Compute Scalar operator to the right of the Sort operator, then you will discover that Expr1004 is as follows:

It's not a pretty sight, I know. This is the expression that we have in the ORDER BY clause of our query. The problem is that the optimizer can't evaluate this expression at compile time, so it has to compute it for each row at runtime, and then sort the entire record set based on that.
The output of statistics IO is just like in the first execution:
- Table 'SalesOrderHeader'. Scan count 1, logical reads 689
- Table 'SalesOrderDetail'. Scan count 1, logical reads 1248
Return the Top 10 Rows for a Specific Customer Sorted by SalesOrderID
The following is the code to return the top 10 rows for a specific customer sorted by SalesOrderID:
EXECUTE Sales.GetOrders
@CustomerID = 11006 ,
@SortOrder = N'SalesOrderID'
WITH
RECOMPILE;
GO
The execution plan is the same as in the second option (return top 10 rows for a specific customer sorted by OrderDate). The plan has the same two problems, which we have mentioned already. The first problem is performing an index scan rather than an index seek due to the expression in the WHERE clause. The second problem is performing an expensive sort due to the expression in the ORDER BY clause.
So, What Should We Do?
Let's remind ourselves first what we are dealing with. We have parameters, which determine the structure of the query. For each combination of parameter values, we get a different query structure. In the case of the @CustomerID parameter, the two different behaviors are NULL or NOT NULL, and they affect the WHERE clause. In the case of the @SortOrder parameter, there are two possible values, and they affect the ORDER BY clause. The result is 4 possible query structures, and we would like to get a different plan for each one.
Then we have two distinct problems. The first is plan caching. There is only a single plan for the stored procedure, and it's going to be generated based on the parameter values in the first execution. The second problem is that even when a new plan is generated, it is not efficient because the optimizer can't evaluate the "dynamic" expressions in the WHERE clause and in the ORDER BY clause at compile time.
We can try to solve these problems in several ways:
- Use a series of IF-ELSE statements
- Split the procedure into separate stored procedures
- Use OPTION (RECOMPILE)
- Generate the query dynamically
Use a Series of IF-ELSE Statements
The idea is simple: instead of the "dynamic" expressions in the WHERE clause and in the ORDER BY clause, we can split the execution into 4 branches using IF-ELSE statements—one branch for each possible behavior.
For example, the following is the code for the first branch:
IF
@CustomerID IS NULL
AND
@SortOrder = N'OrderDate'
BEGIN
SELECT TOP (10)
SalesOrderID = SalesOrders.SalesOrderID ,
OrderDate = CAST (SalesOrders.OrderDate AS DATE) ,
OrderStatus = SalesOrders.[Status] ,
CustomerID = SalesOrders.CustomerID ,
OrderTotal = SUM (SalesOrderDetails.LineTotal)
FROM
Sales.SalesOrderHeader AS SalesOrders
INNER JOIN
Sales.SalesOrderDetail AS SalesOrderDetails
ON
SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID
GROUP BY
SalesOrders.SalesOrderID,
SalesOrders.OrderDate,
SalesOrders.DueDate,
SalesOrders.[Status],
SalesOrders.CustomerID
ORDER BY
SalesOrders.OrderDate ASC;
END;
This approach can help generate better plans, but it has some limitations.
First, the stored procedure becomes quite long, and it's more difficult to write, read, and maintain. And this is when we have only two parameters. If we had 3 parameters, we would have 8 branches. Imagine that you need to add a column to the SELECT clause. You would have to add the column in 8 different queries. It becomes a maintenance nightmare, with a high risk of human error.
Second, we still have the problem of plan caching and parameter sniffing to some extent. This is because in the first execution, the optimizer is going to generate a plan for all 4 queries based on the parameter values in that execution. Let's say that the first execution is going to use the default values for the parameters. Specifically, the value of @CustomerID will be NULL. All queries will be optimized based on that value, including the query with the WHERE clause (SalesOrders.CustomerID = @CustomerID). The optimizer is going to estimate 0 rows for these queries. Now, let's say that the second execution is going to use a non-null value for @CustomerID. The cached plan, which estimates 0 rows, will be used, even though the customer might have lots of orders in the table.
Split the Procedure into Separate Stored Procedures
Instead of 4 branches within the same stored procedure, we can create 4 separate stored procedures, each with the relevant parameters and the corresponding query. Then, we can either rewrite the application to decide which stored procedure to execute according to the desired behaviors. Or, if we want it to be transparent to the application, we can rewrite the original stored procedure to decide which procedure to execute based on the parameter values. We're going to use the same IF-ELSE statements, but instead of executing a query in each branch, we will execute a separate stored procedure.
The advantage is that we solve the plan caching problem because each stored procedure now has its own plan, and the plan for each stored procedure is going to be generated in its first execution based on parameter sniffing.
But we still have the maintenance problem. Some people might say that now it's even worse, because we need to maintain multiple stored procedures. Again, if we increase the number of parameters to 3, we would end up with 8 distinct stored procedures.
Use OPTION (RECOMPILE)
OPTION (RECOMPILE) works like magic. You just have to say the words (or append them to the query), and magic happens. Really, it solves so many problems because it compiles the query at runtime, and it does it for every execution.
But you must be careful because you know what they say: "With great power comes great responsibility." If you use OPTION (RECOMPILE) in a query that is executed very often on a busy OLTP system, then you might kill the system because the server needs to compile and generate a new plan in every execution, using a lot of CPU resources. This is really dangerous. However, if the query is only executed once in a while, let's say once every few minutes, then it's probably safe. But always test the impact in your specific environment.
In our case, assuming we can safely use OPTION (RECOMPILE), all we have to do is add the magic words at the end of our query, as shown below:
ALTER PROCEDURE
Sales.GetOrders
(
@CustomerID AS INT = NULL ,
@SortOrder AS SYSNAME = N'OrderDate'
)
AS
SELECT TOP (10)
SalesOrderID = SalesOrders.SalesOrderID ,
OrderDate = CAST (SalesOrders.OrderDate AS DATE) ,
OrderStatus = SalesOrders.[Status] ,
CustomerID = SalesOrders.CustomerID ,
OrderTotal = SUM (SalesOrderDetails.LineTotal)
FROM
Sales.SalesOrderHeader AS SalesOrders
INNER JOIN
Sales.SalesOrderDetail AS SalesOrderDetails
ON
SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID
WHERE
SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL
GROUP BY
SalesOrders.SalesOrderID ,
SalesOrders.OrderDate ,
SalesOrders.DueDate ,
SalesOrders.[Status] ,
SalesOrders.CustomerID
ORDER BY
CASE @SortOrder
WHEN N'OrderDate'
THEN SalesOrders.OrderDate
WHEN N'SalesOrderID'
THEN SalesOrders.SalesOrderID
END ASC
OPTION
(RECOMPILE);
GO
Now, let’s see the magic in action. For example, the following is the plan for the second behavior:
EXECUTE Sales.GetOrders
@CustomerID = 11006;
GO
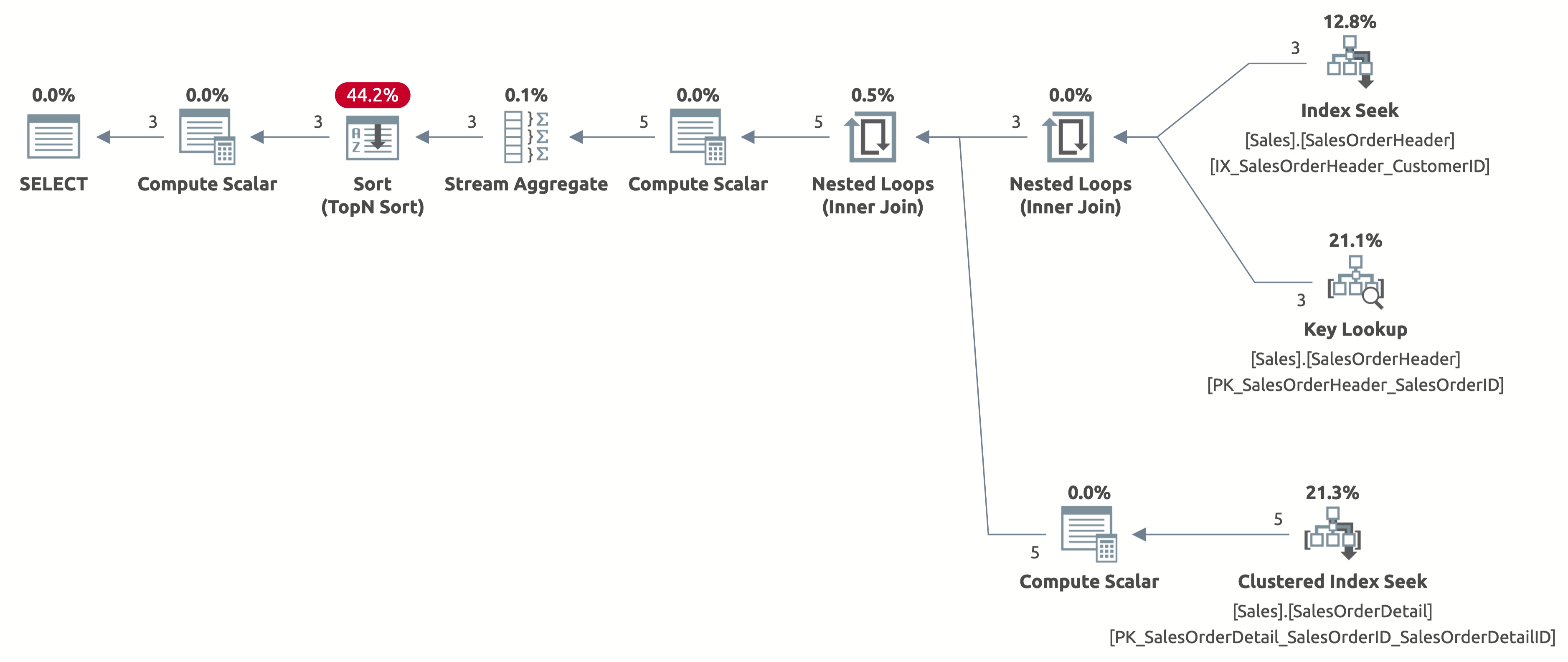
Now we get an efficient index seek with a correct estimation of 2.6 rows. We still need to sort by OrderDate, but now the sort is directly by Order Date, and we don't have to compute the CASE expression in the ORDER BY clause anymore. This is the best plan possible for this query behavior based on the available indexes.
Here is the output of statistics IO:
- Table 'SalesOrderDetail'. Scan count 3, logical reads 9
- Table 'SalesOrderHeader'. Scan count 1, logical reads 11
The reason that OPTION (RECOMPILE) is so efficient in this case is that it solves exactly the two problems we have here. Remember that the first problem is plan caching. OPTION (RECOMPILE) eliminates this problem altogether because it recompiles the query every time. The second problem is the inability of the optimizer to evaluate the complex expression in the WHERE clause and in the ORDER BY clause at compile time. Since OPTION (RECOMPILE) happens at runtime, it solves the problem. Because at runtime, the optimizer has a lot more information compared to compile time, and it makes all the difference.
Now, let’s see what happens when we try the third behavior:
EXECUTE Sales.GetOrders
@SortOrder = N'SalesOrderID';
GO

Houston, we have a problem. The plan still scans both tables entirely and then sorts everything, instead of scanning only the first 10 rows from Sales.SalesOrderHeader and avoiding the sort altogether. What happened?
This is an interesting "case," and it has to do with the CASE expression in the ORDER BY clause. The CASE expression evaluates a list of conditions and returns one of the result expressions. But the result expressions might have different data types. So, what would be the data type of the entire CASE expression? Well, the CASE expression always returns the highest precedence data type. In our case, the column OrderDate has the DATETIME data type, while the column SalesOrderID has the INT data type. The DATETIME data type has a higher precedence, so the CASE expression always returns DATETIME.
This means that if we want to sort by SalesOrderID, the CASE expression needs to first implicitly convert the value of SalesOrderID to DATETIME for each row prior to sorting it. See the Compute Scalar operator to the right of the Sort operator in the plan above? That’s exactly what it does.
This is a problem by itself, and it demonstrates how dangerous it can be to mix different data types in a single CASE expression.
We can work around this problem by rewriting the ORDER BY clause in other ways, but it would make the code even more ugly and difficult to read and maintain. So, I won't go in that direction.
Instead, let's try the next method…
Generate the Query Dynamically
Since our goal is to generate 4 different query structures within a single query, dynamic SQL can be very handy in this case. The idea is to build the query dynamically based on the parameter values. This way, we can build the 4 different query structures in a single code, without having to maintain 4 copies of the query. Each query structure will compile once, when it's first executed, and it will get the best plan because it doesn't contain any complex expressions.
This solution is very similar to the solution with the multiple stored procedures, but instead of maintaining 8 stored procedures for 3 parameters, we only maintain a single code that builds the query dynamically.
I know, dynamic SQL is also ugly and sometimes can be quite difficult to maintain, but I think it's still easier than maintaining multiple stored procedures, and it doesn't scale exponentially as the number of parameters increase.
The following is the code:
ALTER PROCEDURE
Sales.GetOrders
(
@CustomerID AS INT = NULL ,
@SortOrder AS SYSNAME = N'OrderDate'
)
AS
DECLARE
@Command AS NVARCHAR(MAX);
SET @Command =
N'
SELECT TOP (10)
SalesOrderID = SalesOrders.SalesOrderID ,
OrderDate = CAST (SalesOrders.OrderDate AS DATE) ,
OrderStatus = SalesOrders.[Status] ,
CustomerID = SalesOrders.CustomerID ,
OrderTotal = SUM (SalesOrderDetails.LineTotal)
FROM
Sales.SalesOrderHeader AS SalesOrders
INNER JOIN
Sales.SalesOrderDetail AS SalesOrderDetails
ON
SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID
' +
CASE
WHEN @CustomerID IS NULL
THEN N''
ELSE
N'WHERE
SalesOrders.CustomerID = @pCustomerID
'
END +
N'GROUP BY
SalesOrders.SalesOrderID ,
SalesOrders.OrderDate ,
SalesOrders.DueDate ,
SalesOrders.[Status] ,
SalesOrders.CustomerID
ORDER BY
' +
CASE @SortOrder
WHEN N'OrderDate'
THEN N'SalesOrders.OrderDate'
WHEN N'SalesOrderID'
THEN N'SalesOrders.SalesOrderID'
END +
N' ASC;
';
EXECUTE sys.sp_executesql
@stmt = @Command ,
@params = N'@pCustomerID AS INT' ,
@pCustomerID = @CustomerID;
GO
Note that I still use an internal parameter for the Customer ID, and I execute the dynamic code using sys.sp_executesql to pass the parameter value. This is important for two reasons. First, to avoid multiple compilations of the same query structure for different values of @CustomerID. Second, to avoid SQL injection.
If you try to execute the stored procedure now using different parameter values, you will see that each query behavior or query structure gets the best execution plan, and each one of the 4 plans is compiles only once.
As an example, the following is the plan for the third behavior:
EXECUTE Sales.GetOrders
@SortOrder = N'SalesOrderID';
GO

Now, we scan only the first 10 rows from the Sales.SalesOrderHeader table, and we also scan only the first 110 rows from the Sales.SalesOrderDetail table. In addition, there is no Sort operator because the data is already sorted by SalesOrderID.
Here is the output of statistics IO:
- Table 'SalesOrderDetail'. Scan count 1, logical reads 4
- Table 'SalesOrderHeader'. Scan count 1, logical reads 3
Conclusion
When you use parameters to change the structure of your query, don't use complex expressions within the query to derive the expected behavior. In most cases, this will lead to poor performance, and for good reasons. The first reason is that the plan will be generated based on the first execution, and then all subsequent executions will reuse the same plan, which is only appropriate to one query structure. The second reason is that the optimizer is limited in its ability to evaluate those complex expressions at compile time.
There are several ways to overcome these problems, and we examined them in this article. In most cases, the best method would be to build the query dynamically based on the parameter values. That way, each query structure will be compiled once with the best possible plan.
When you build the query using dynamic SQL, make sure to use parameters where appropriate and verify that your code is safe.

one should not forgot to mention this homepage, when writing about stored procedures that can change behaviour:
http://sommarskog.se/dyn-search.html