
Performance of sys.partitions
This question was posted to #sqlhelp by Jake Manske, and it was brought to my attention by Erik Darling.
I don't recall ever having a performance issue with sys.partitions. My initial thought (echoed by Joey D'Antoni) was that a filter on the data_compression column should avoid the redundant scan, and reduce query runtime by about half. However, this predicate doesn't get pushed down, and the reason why takes a bit of unpacking.
Why is sys.partitions slow?
If you look at the definition for sys.partitions, it is basically what Jake described – a UNION ALL of all the columnstore and rowstore partitions, with THREE explicit references to sys.sysrowsets (abbreviated source here):
CREATE VIEW sys.partitions AS
WITH partitions_columnstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 1 -- Consider only columnstore base indexes
),
partitions_rowstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 0 -- Ignore columnstore base indexes and orphaned rows.
)
SELECT ...cols...
from partitions_rowstore p OUTER APPLY OpenRowset(TABLE ALUCOUNT, p.partition_id, 0, 0, p.object_id) ct
union all
SELECT ...cols...
FROM partitions_columnstore as P1
LEFT JOIN
(SELECT ...cols...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
------- *** ^^^^^^^^^^^^^^ ***
) ...This view seems cobbled together, probably due to backward compatibility concerns. It could surely be rewritten to be more efficient, particularly to only reference the sys.sysrowsets and TABLE ALUCOUNT objects once. But there's not much you or I can do about that right now.
The column cmprlevel comes from sys.sysrowsets (an alias prefix on the column reference would have been helpful). You would hope that a predicate against a column there would logically happen before any OUTER APPLY and could prevent one of the scans, but that's not what happens. Running the following simple query:
SELECT *
FROM sys.partitions AS p
INNER JOIN sys.objects AS o
ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0;Yields the following plan when there are columnstore indexes in the databases (click to enlarge):
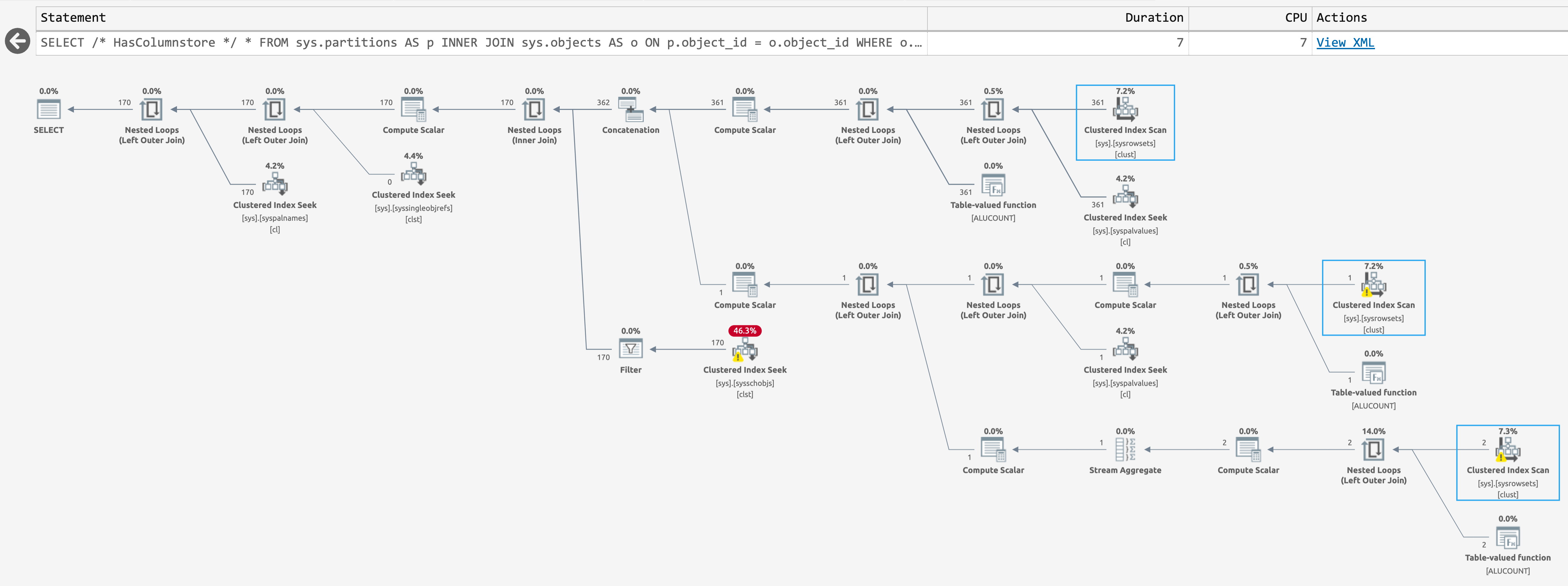 Plan for sys.partitions, with columnstore indexes present
Plan for sys.partitions, with columnstore indexes present
And the following plan when there are not (click to enlarge):
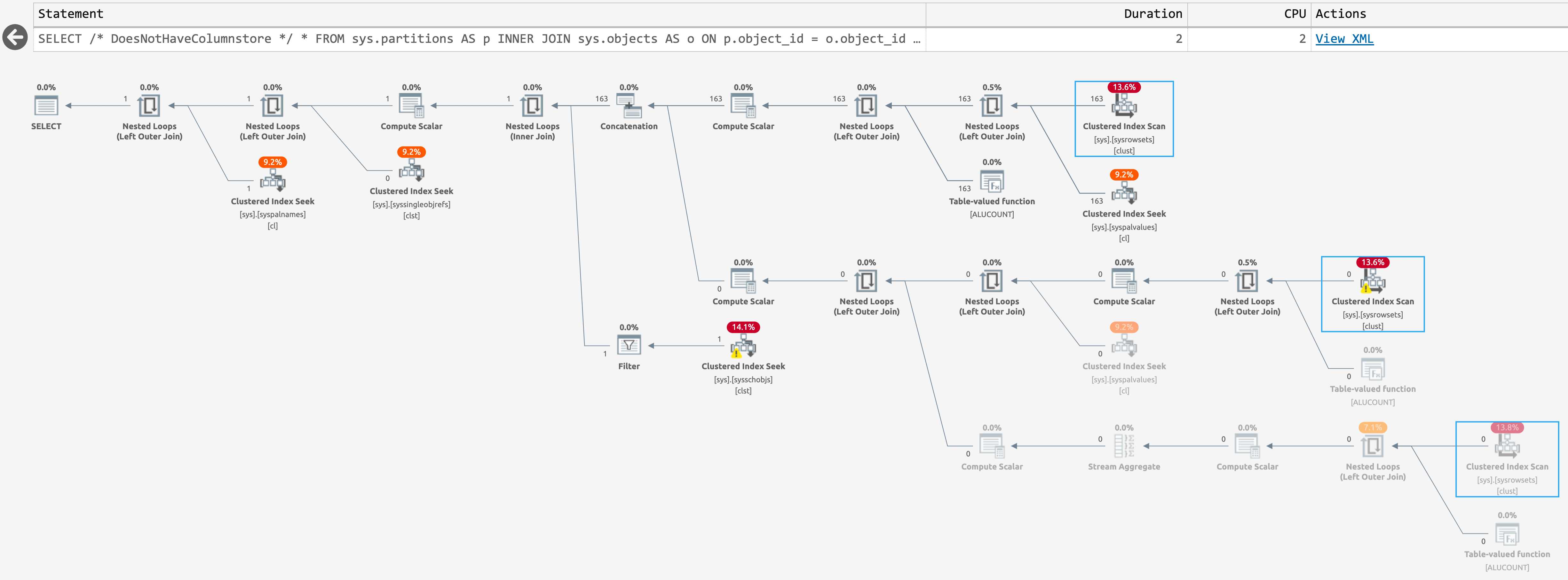 Plan for sys.partitions, with no columnstore indexes present
Plan for sys.partitions, with no columnstore indexes present
These are the same estimated plan, but SentryOne Plan Explorer is able to highlight when an operation is skipped at runtime. This happens for the third scan in the latter case, but I don't know that there's any way to reduce that runtime scan count further; the second scan happens even when the query returns zero rows.
In Jake's case, he has a lot of objects, so performing this scan even twice is noticeable, painful, and one time too many. And quite honestly I don't know if TABLE ALUCOUNT, an internal and undocumented loopback call, has to also scan some of these bigger objects multiple times.
Looking back at the source, I wondered if there was any other predicate that could be passed to the view that could coerce the plan shape, but I really don't think there's anything that could have an impact.
Will another view work?
We could, however, try a different view altogether. I looked for other views that contained references to both sys.sysrowsets and ALUCOUNT, and there are multiple that show up in the list, but only two are promising: sys.internal_partitions and sys.system_internals_partitions.
sys.internal_partitions
I tried sys.internal_partitions first:
SELECT *
FROM sys.internal_partitions AS p
INNER JOIN sys.objects AS o
ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0;But the plan was not much better (click to enlarge):
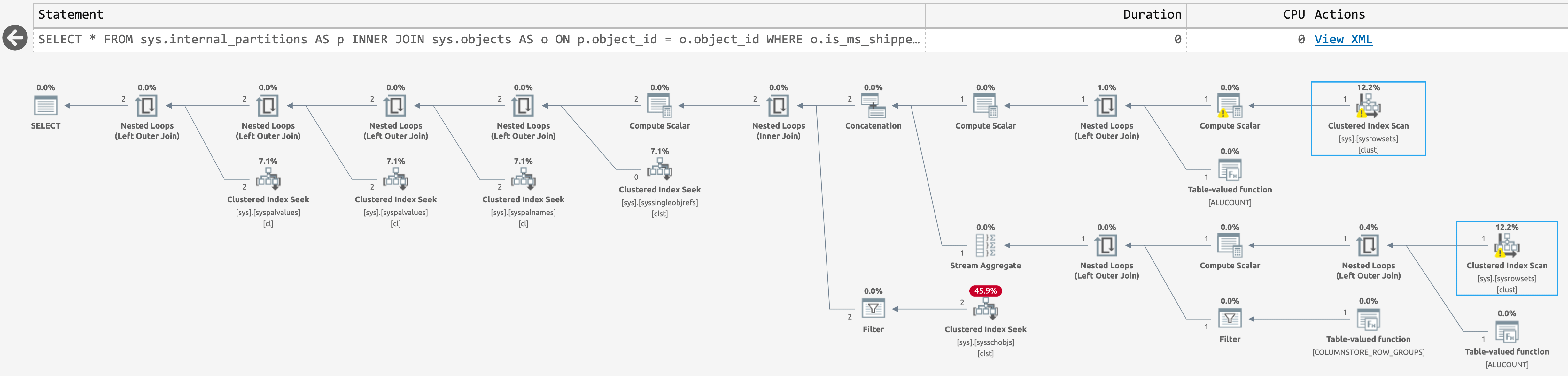 Plan for sys.internal_partitions
Plan for sys.internal_partitions
There are only two scans against sys.sysrowsets this time, but the scans are irrelevant anyway because the query doesn't come close to producing the rows we're interested in. We only see rows for columnstore-related objects (as the documentation states).
sys.system_internals_partitions
Let's try sys.system_internals_partitions. I'm little wary about this, because it's unsupported (see the warning here), but bear with me a moment:
SELECT *
FROM sys.system_internals_partitions AS p
INNER JOIN sys.objects AS o
ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0;In the database with columnstore indexes, there's a scan against sys.sysschobjs, but now only one scan against sys.sysrowsets (click to enlarge):
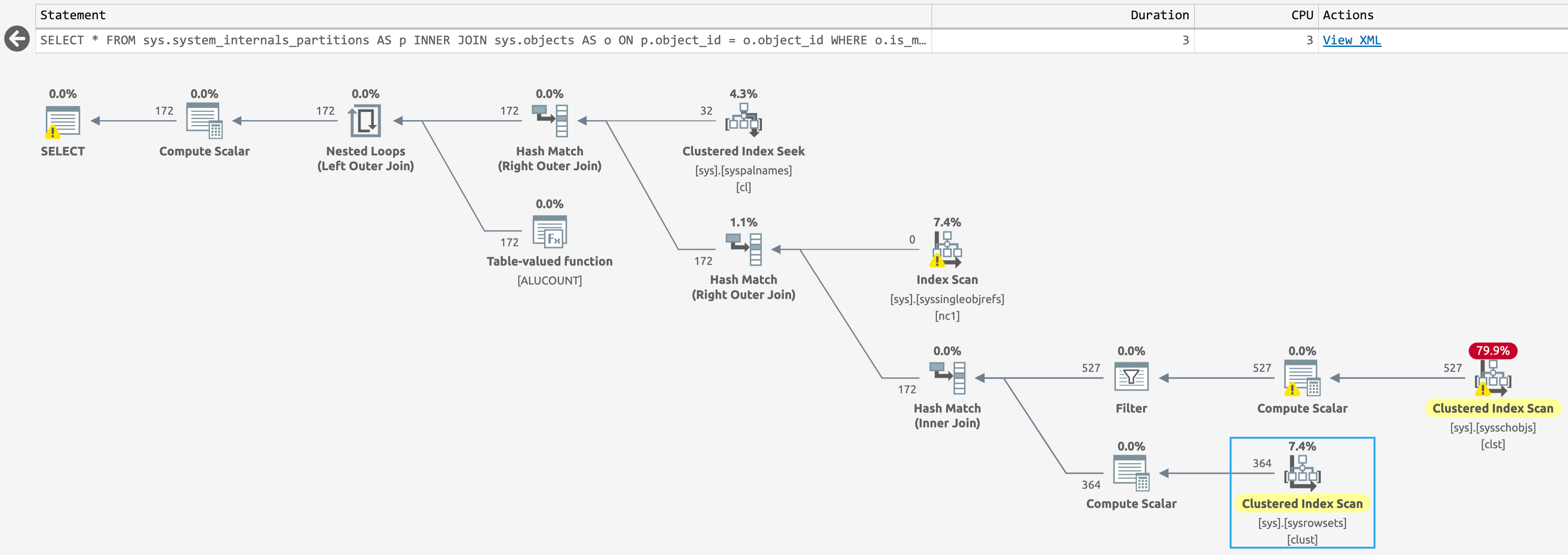 Plan for sys.system_internals_partitions, with columnstore indexes present
Plan for sys.system_internals_partitions, with columnstore indexes present
If we run the same query in the database with no columnstore indexes, the plan is even simpler, with a seek against sys.sysschobjs (click to enlarge):
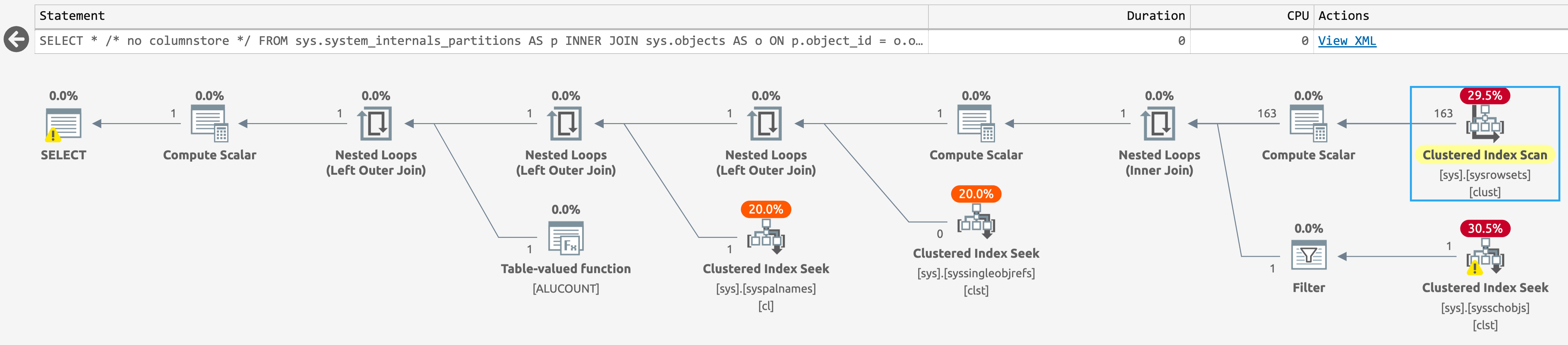 Plan for sys.system_internals_partitions, with no columnstore indexes present
Plan for sys.system_internals_partitions, with no columnstore indexes present
However, this isn't quite what we're after, or at least not quite what Jake was after, because it includes artifacts from columnstore indexes, as well. If we add these filters, the actual output now matches our earlier, much more expensive query:
SELECT *
FROM sys.system_internals_partitions AS p
INNER JOIN sys.objects AS o ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0
AND p.is_columnstore = 0
AND p.is_orphaned = 0;As a bonus, the scan against sys.sysschobjs has become a seek even in the database with columnstore objects. Most of us won't notice that difference, but if you're in a scenario like Jake's, you just might (click to enlarge):
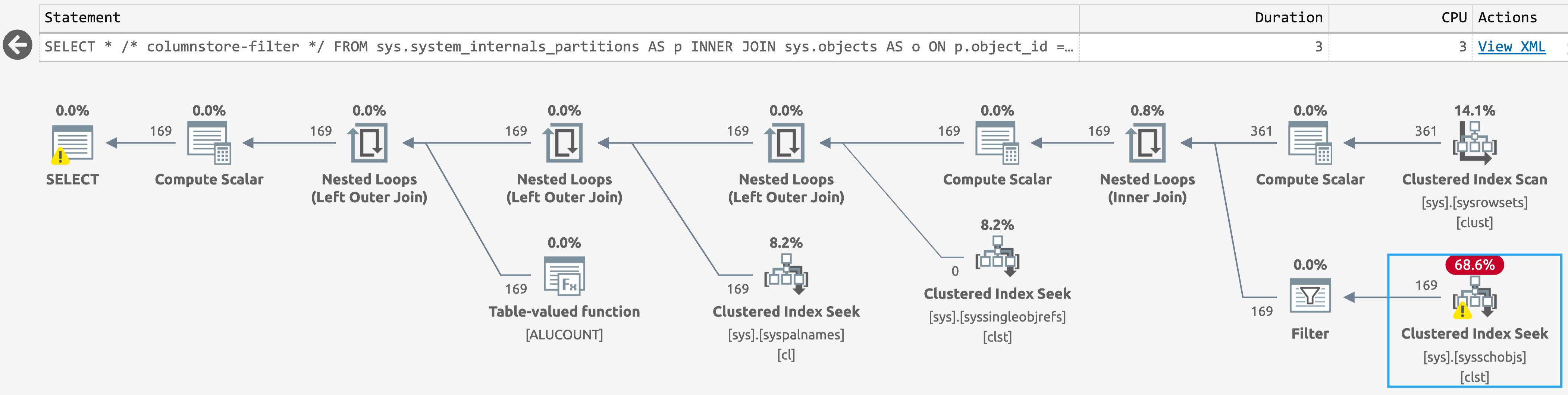 Simpler plan for sys.system_internals_partitions, with additional filters
Simpler plan for sys.system_internals_partitions, with additional filters
sys.system_internals_partitions exposes a different set of columns than sys.partitions (some are completely different, others have new names) so, if you are consuming the output downstream, you'll have to adjust for those. You'll also want to validate that it returns all of the information you want across rowstore, memory-optimized, and columnstore indexes, and don't forget about those pesky heaps. And, finally, be ready for leaving out the s in internals many, many times.
Conclusion
As I mentioned above, this system view is not officially supported, so its functionality may change at any time; it could also be moved under the Dedicated Administrator Connection (DAC), or removed from the product altogether. Feel free to use this approach if sys.partitions is not working well for you but, please, make sure you have a backup plan. And make sure it is documented as something you regression test when you start testing future versions of SQL Server, or after you upgrade, just in case.

Ideally there would be some way to get partition_id if you have object_id and index_id that would not result in the scan of sysrowsets.
Once you have partition_id you can use that to access sys.partitions and avoid those scans.
Nice article! I haven't run into the issue described in the article, but also hadn't really bothered to compare the plans of sys.partitions vs. the other system dmvs. Thanks.
On a related note, I have run into blocking issues in the past when trying to query sys.partitions (and friends) while DDL operations were in progress (a large index build, for example), regardless of isolation of the query. As Aaron has noted in a past article, the system DMVs (or at least system functions) don't seem to totally pushdown the isolation level–perhaps that is the case also with ALUCOUNT also.
In testing, I found that including the [rows] column (or using *) in your query, which triggers the call to ALUCOUNT, is in fact the culprit. If you comment out/remove the [rows] column from your query, the blocking disappears (and a quick look shows the plan also gets much nicer to boot).
I believe it, but didn't try it, because I bet the 90% use case is getting ballpark rowcounts. :-)
It may not be a huge gain, but inserting sys.partitions into a temp table seems to help too – it definitely helps if you have tons of partitions or you're trying to join to several dmv's.
drop table if exists #partitions;
select *
into #partitions
from sys.partitions p;
select *
from #partitions as p
inner join sys.objects as o
on p.object_id = o.object_id
where o.is_ms_shipped = 0;
Great article! I have been shying away from sys.objects in cases like this because according to some books about SQL performance that "sys.objects shows the (approximate) number of rows in the partition." so it is not always %100 accurate. I would love to hear your input about this
I assume you mean sys.partitions, not sys.objects.
I can give some input, but it may or may not be useful depending on your goals. How accurate does your count need to be? How accurate can it possibly be? sys.partitions (and sys.dm_db_partition_stats, which I didn't investigate this time) are fairly accurate except for in-flight transactions. This means it can be off by a little if there are updates/deletes etc. currently happening to the data. Do you want to take those into account? Why? You can always use NOLOCK and manually count all the rows, but this is fraught with other problems – phantoms, double-counting, etc. because of the way the data is read. So this isn't 100% accurate either.
If you want a more reliable, "accurate" count for a busy table, meaning you lock the table and count all the rows while not allowing any changes, how long will that count be good for? If you lock a busy table for counting, all those inserts/deletes will be waiting for you. Guess what happens as soon as you're done counting and release your locks? Your count in this case is 100% accurate, but only at the moment your count has finished. Any queued-up or subsequent transactions immediately render your count something less than 100% accurate. So what value did it have being accurate at a single point in time, but no longer accurate 30 seconds later? This is like knowing at 3:42 PM what the stock price was at 11:37 AM. It's interesting, but not very valuable – the trend and the ballpark are far more valuable than the specifics at the time you checked, IMHO.
If the table isn't busy, and so no transactions will mess up your count, then sys.partitions is pretty darn accurate.
I talked about this several years ago: https://sqlperformance.com/2014/10/t-sql-queries/bad-habits-count-the-hard-way
The original requirement was to return the compression type for an index partition. The following does that with a single seek on
sys.rowsets:SELECT TOP (1) P.data_compression_desc FROM sys.partitions AS P WHERE P.[partition_id] = ( SELECT TOP (1) DDPS.[partition_id] FROM sys.dm_db_partition_stats AS DDPS WHERE DDPS.[object_id] = @objectid AND DDPS.index_id = @indexid AND DDPS.partition_number = 1 );