
Sometimes you CAN upsize a column in-place
Last year, Andy Mallon blogged about upsizing a column from int to bigint with no downtime. (Why this isn't a metadata-only operation in modern versions of SQL Server is beyond me, but that's another post.)
Usually when we deal with this issue, they are wide and massive tables (in both row count and sheer size), and the column we need to change is the only/leading column in the clustering key. There are typically other complications involved as well – inbound foreign key constraints, lots of non-clustered indexes, and a busy database that is ultra-sensitive to log activity (because it is involved in Change Tracking, replication, Availability Groups, or all three).
For this reason, we need to take an approach like Andy outlined, where we build a shadow table with the new schema, create triggers to keep both copies in sync, and then batch/backfill at that team's own pace until they are ready to swap in the copy as the real deal.
But I'm lazy!
There are some cases where you can change the column directly, if you can afford a small window of downtime/blocking, and it becomes a much simpler operation. Last week one such case emerged, with a table over 1TB, but only 100K rows. Almost all of the data was off-row (LOB), they could afford a small window of downtime if needed, and they were planning to disable Change Tracking and reconfigure it anyway. Confident that re-creating the clustered PK would not have to touch the LOB data (much), I suggested that this might be a case where we can just apply the change directly.
In an isolated scenario (no inbound foreign keys, no additional indexes, no activities depending on the log reader, and no concerns about concurrency), I threw together some tests to see, in a vacuum, what this change would require in terms of duration and impact to the transaction log. The main question I didn't know how to answer in advance was, "What is the incremental cost of updating tables in-place when there are large amounts of non-key data?"
I'm going to try to pack a lot into one post here. I did a lot of testing, and it's all kind of related, even if not all test scenarios apply to you. Please bear with me.
The tables
I created 6 tables, including a baseline that only had the key column, one table with 4K stored in-row, and then four tables each with a varchar(max) column populated with varying amounts of string data (4K, 16K, 64K, and 256K).
CREATE TABLE dbo.withJustId
(
id int NOT NULL,
CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withoutLob
(
id int NOT NULL,
extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob004
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob016
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)),
CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob064
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)),
CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob256
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)),
CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id)
);
I filled each with 100,000 rows:
INSERT dbo.withJustId (id)
SELECT TOP (100000) id = ROW_NUMBER() OVER (ORDER BY c1.name)
FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects;
INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId;
INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;
INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;
INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId;
INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
I acknowledge the above is unrealistic; how often do we have a table that is just an identifier + LOB data? I ran the tests again with these additional four columns to give the non-LOB data pages a little more real-world substance:
fill1 char(320) NOT NULL DEFAULT ('x'),
count1 int NOT NULL DEFAULT (0),
count2 int NOT NULL DEFAULT (0),
dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
These tables are only slightly bigger in terms of overall size, but the proportional increase in the amount of non-LOB data (not illustrated in this chart) is the big but hidden difference:
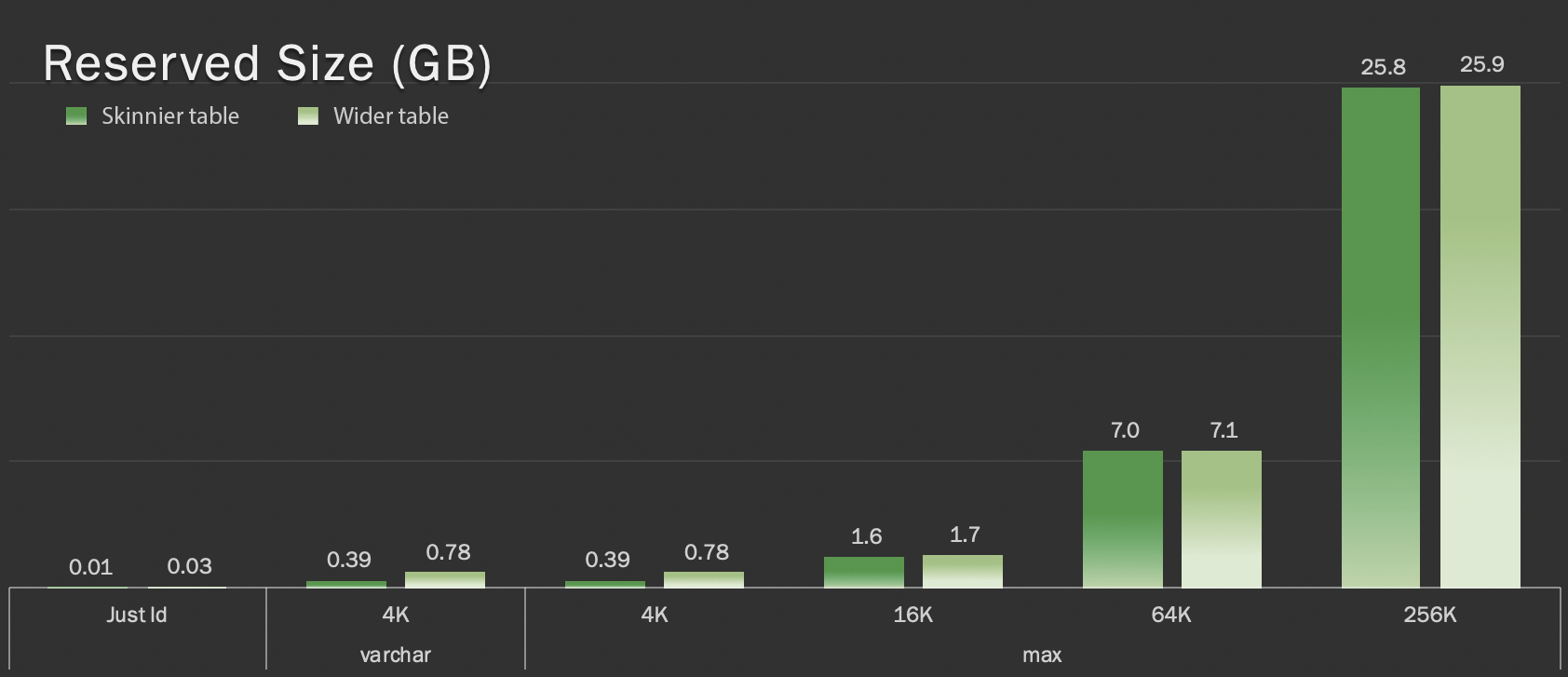 Reserved size of tables, in GB
Reserved size of tables, in GB
The tests
Then I timed and collected log data for each of these operations (with and without ONLINE = ON) against each variation of the table:
ALTER TABLE dbo. DROP CONSTRAINT pk_;
ALTER TABLE dbo. ALTER COLUMN id bigint NOT NULL; -- WITH (ONLINE = ON);
ALTER TABLE dbo. ADD CONSTRAINT pk_ PRIMARY KEY CLUSTERED (id);
In reality, I used dynamic SQL to generate all these tests, so that I wasn't manually fiddling with scripts before each test.
In another post, I'll share the dynamic SQL I used to generate those tests, and collect the timings at each step.
For comparison, I also tested Andy's method (albeit without batching, and only on the skinny version of the table):
CREATE TABLE dbo._copy ( id bigint NOT NULL
-- <, extradata column when relevant >
CONSTRAINT pk_copy_ PRIMARY KEY CLUSTERED (id));
INSERT dbo._copy SELECT * FROM dbo.;
EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';
EXEC sys.sp_rename N'dbo._copy', N'dbo.', N'OBJECT';
I skipped the wider tables here; I didn't want to introduce the complexity of coding and measuring batch operations. The obvious pain point here is that, unlike changing the column in-place, with the shadow method you have to copy every single byte of that LOB data. Batching can minimize the large impact of trying to do that in a single transaction, but all that shuffling will eventually have to be redone downstream. Batching at the source can't completely control how much that will hurt at the destination.
The results
The first results I'm going to show are just the average durations for in-place alters, for all 12 table configurations, and with and without ONLINE = ON:
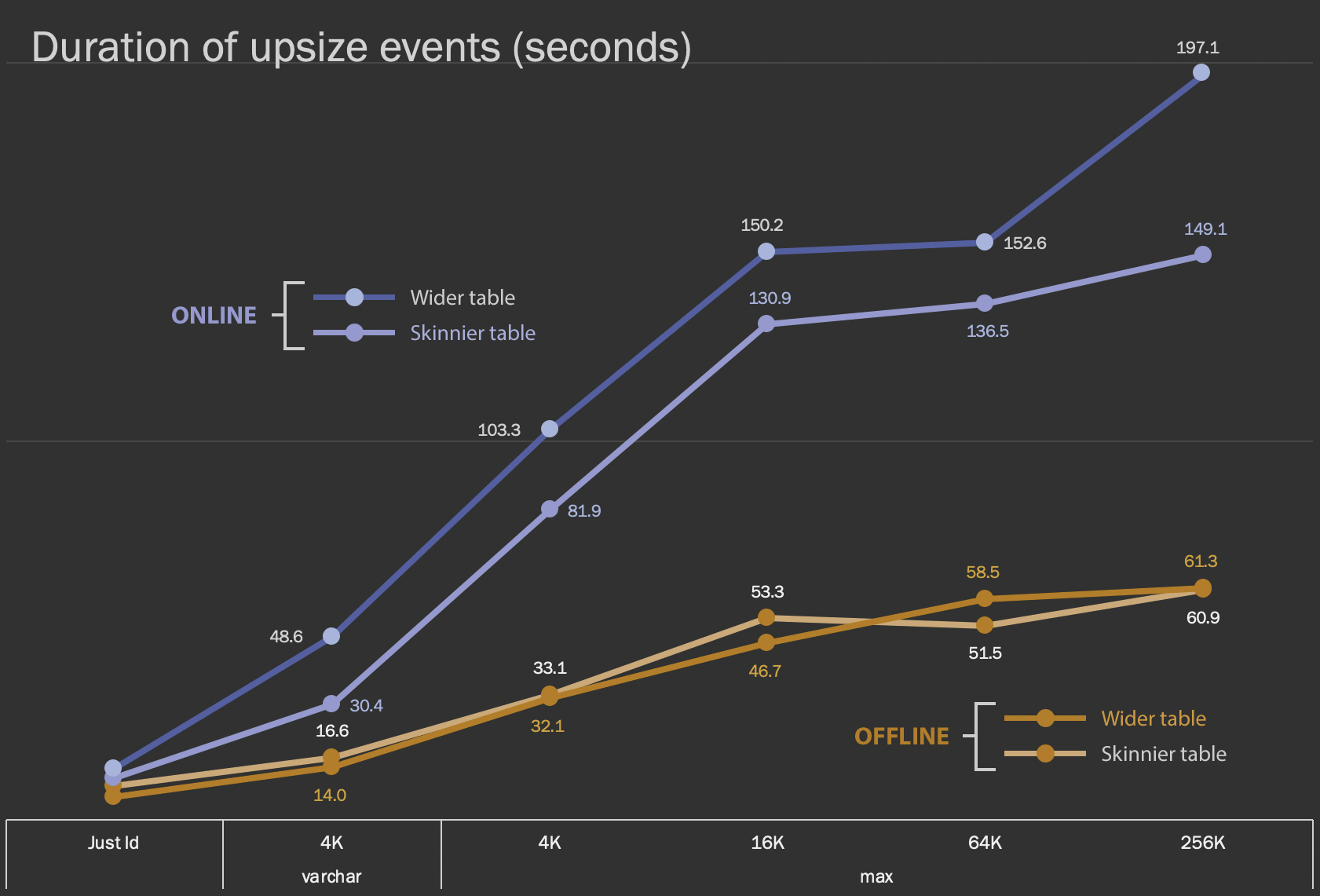 Duration, in seconds, of altering the column in-place
Duration, in seconds, of altering the column in-place
Performing this as an online operation takes more time (200 seconds in the worst case), but doesn't block users. It does appear to increase alongside size, but not quite linearly. Performing this operation offline causes blocking, but is much quicker, and doesn't change quite as drastically as the table gets bigger (even at the largest size, this still happened in about a minute).
Comparing these in-place operations to the swap and drop operation is difficult using a line chart because of the massive difference in scale. Instead I'm going to show a horizontal bar chart for the duration involved with each table configuration. When the re-create is faster, I'll paint that row's background green; when it is slower (or falls between the offline and online methods), I probably don't need to, but I'll paint that row's background red.
| LOB size | Approach | Table config | Duration (seconds) | ||
|---|---|---|---|
| Just Id | ALTER Offline | Skinnier table (10 MB) | |
| Wider table (30 MB) | |||
| ALTER Online | Skinnier table | ||
| Wider table | |||
| Recreate | Skinnier table | ||
| varchar 4K | Offline | Skinnier table (390 MB) | |
| Wider table (780 MB) | |||
| Online | Skinnier table | ||
| Wider table | |||
| Recreate | Skinnier table | ||
| max 4k | Offline | Skinnier table (390 MB) | |
| Wider table (780 MB) | |||
| Online | Skinnier table | ||
| Wider table | |||
| Recreate | Skinnier table | ||
| max 16k | Offline | Skinnier table (1.6 GB) | |
| Wider table (1.7 GB) | |||
| Online | Skinnier table | ||
| Wider table | |||
| Recreate | Skinnier table | ||
| max 64k | Offline | Skinnier table (7.0 GB) | |
| Wider table (7.1 GB) | |||
| Online | Skinnier table | ||
| Wider table | |||
| Recreate | Skinnier table | ||
| max 256k | Offline | Skinnier table (25.8 GB) | |
| Wider table (25.9 GB) | |||
| Online | Skinnier table | ||
| Wider table | |||
| Recreate | Skinnier table | ||
This is an unfair shake at Andy's method, because – in the real world – you would not be performing that entire operation in one shot. I didn't show transaction log usage here for brevity, but it would be easier to control that through batching in a side-by-side operation as well. While his approach requires more work up front, it is a lot safer in terms of downtime and/or blocking. But you can see in cases where you have a lot of off-row data and can afford a brief outage, that altering the column directly is a lot less painful. "Too large to change in-place" is subjective and can produce different results depending on what "large" means. Before committing to an approach, it might make sense to test the change against a reasonable copy, because the in-place operation might represent an acceptable trade-off.
Conclusion
I did not write this to argue with Andy. The approach in the original post is sound, 100% reliable, and we use it all the time. When brute force is valued over surgical precision, though, and especially if you can take a slice of downtime, there can be value in the simpler approach for certain table shapes.
